

[MàJ] Sites d’infos générés par IA : « Notre job, c’est gruger Google » pour faire du fric
Vas-y fonce, on sait jamais, sur un malentendu, ça peut marcher
![[MàJ] Sites d’infos générés par IA : « Notre job, c’est gruger Google » pour faire du fric](https://next.ink/wp-content/uploads/2025/01/Invasion-ia.webp "[MàJ] Sites d’infos générés par IA : « Notre job, c’est gruger Google » pour faire du fric")
7 des 50 principaux sites d’information en français mis en avant par l’algorithme Discover de recommandation de contenus de Google sont générés par IA. Plusieurs le comparent à TikTok et le qualifient de « réseau social de Google », voire à « une drogue » susceptible de « générer une dépendance », au vu des milliers d’euros de chiffre d’affaires engrangés, par jour. Deux d’entre eux seraient même devenus millionnaires grâce à Discover, en trois mois seulement. Suite de notre enquête-fleuve sur les sites d’info générés par IA.
Article mis à jour le 11 juin à 20h20 pour préciser que, depuis janvier, plus de 75 sites « générés par IA » (au moins) ont été mis en avant par l’algorithme de recommandation de contenus Discover de Google en France, et que 15 y ont même figuré dans son Top50, dont 1 pendant 5 mois, 3 pendant 3 mois, 2 pendant 2 mois, & 4 dans son Top25 (dont un pendant 3 mois consécutifs, un autre 2 mois de suite).
Notre enquête sur ces milliers de (soi-disant) sites d’info « en tout ou partie générés par IA » (GenAI) nous a permis d’en identifier plus de 75 ayant « popé » (pour reprendre l’expression consacrée) sur l’algorithme Discover de recommandation de contenus de Google ces dernières semaines. Et ce, sans que Google ne parvienne à endiguer ce qui s’apparente à une véritable pollution médiatique et informationnelle, et quand bien même ces sites ne respectent pourtant pas les règles du moteur de recherche.
- [Récap] Nous avons découvert des milliers de sites d’info générés par IA : tous nos articles
- Sites d’info générés par IA : Google ne respecte pas ses propres règles
Or, non content d’être générés par IA, et d’émaner de professionnels du référencement (SEO) et du marketing numérique, et non de professionnels des médias journalistiques, nombre de ces articles, mis en avant par l’algorithme (et application) Discover « hallucinent » et relaient moult rumeurs et infox’, dont la viralité a valu à certaines d’être reprises par des journalistes dans des médias « grands publics » voire réputés.

À défaut de comprendre ce pourquoi Google en arrive à recommander de tels articles, dont le caractère GenAI saute généralement aux yeux à la simple consultation du titre et de son image d’illustration, nous avons cherché à comprendre pourquoi, et comment, autant de pros du SEO s’étaient lancés à l’assaut de Discover.
La première raison est que Discover, disponible dans l’application Google, est devenu la principale source de trafic vers les sites d’information, et que les gens s’informent de plus en plus sur leurs téléphones portables, comme nous l’avons détaillé dans un précédent article. Les contenus recommandés par Google, dont la consultation ne dure et prend généralement que quelques minutes seulement, y sont personnalisés en fonction du profil et de l’historique de ses utilisateurs.
Ce pourquoi de plus en plus de gens utilisent Discover, sorte de « fast food de l’information » qui ne dit pas son nom (le mot Discover n’apparaît pas dans l’application Google, et n’est connue que des « professionnels de la profession »), pour s’informer ou passer le temps dans les transports en commun, aux toilettes, à la pause clope ou déjeuner.
Nous avons aussi découvert que leurs éditeurs sont doublement incités par Google à « poper » dans Discover, du fait du fonctionnement même de son algorithme de recommandation algorithmique d’une part, et d’autre part de celui de sa régie publicitaire AdSense, qui leur permet d’espérer pouvoir générer plusieurs milliers d’euros de revenus (par jour), voire même de prétendre devenir millionnaire (en trois mois).
Une course à l’audience reposant notamment sur des rumeurs et infox’
« C’est confirmé : tous les virements bancaires seront suspendus en France à partir de cette date ». « C’est terminé pour les billets de banque : ils ne seront désormais plus valables à partir de cette date ». « La nouvelle est tombée : il sera désormais interdit de retirer du liquide en France à partir de cette date ».
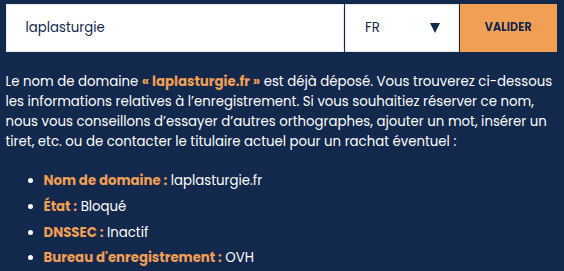
Ces derniers temps, l’algorithme (et application) Discover de recommandation de contenus de Google met de plus en plus souvent en avant des articles relayant de telles rumeurs et infox’ émanant de (soi-disant) sites d’info générés par IA (GenAI), même et y compris en tête de ses résultats. Quelques-uns excellaient d’ailleurs à « poper » sur Discover, tels que laplasturgie.fr ou gre-mag.fr (ils ont depuis tous deux été désactivés).
D’autres laissaient entendre que des mines et gisements d’or, d’uranium, d’hydrogène (entre autres) de plusieurs (dizaines) de milliards d’euros avaient été découverts en France, que le gouvernement allait saisir de l’argent sur les livrets A pour financer l’effort de guerre en Ukraine, qu’il était désormais interdit aux grands-parents d’y déposer de l’argent, ou encore annonçaient (à tort, là encore) la fermeture de magasins Carrefour ou Décathlon, notamment.
Leurs éditeurs se livrent en effet à une véritable course à l’audience, n’hésitant pas à se plagier les uns les autres dès lors qu’un de leurs articles est mis en avant sur Discover. Ils semblent se surveiller les uns les autres, et lorsqu’ils voient qu’un nouveau type d’info commence à « poper » sur Discover, ils s’en inspirent et les plagient, sur leurs différents sites, contribuant à générer encore plus d’articles relayant, notamment, leurs « hallucinations », rumeurs et infox’.
Une mécanique que nous avions déjà décrite dans notre article au sujet d’une « rumeur », hallucinée par des sites GenAI puis amplifiée par des journalistes et médias, avançant que les voitures de plus de 10 ans devraient prochainement faire l’objet d’un contrôle technique annuel.
Depuis, ce type d’emballements médiatiques autour de rumeurs et d’infox générées par IA, mais néanmoins reprises par des journalistes et médias, n’a fait que s’accélérer. Et de plus en plus de journalistes et médias se retrouvent, eux aussi, à devoir y consacrer des articles de fact-checking, pour les démentir.
Jusqu’à cent mille dollars par mois pour dix millions de visiteurs
Le service CheckNews de Libération s’est plus particulièrement penché sur les nombreux articles que ces sites ont récemment consacrés à la fermeture de dizaines de magasins Décathlon, Darty, NOZ, Leroy-Merlin, La Halle ou Carrefour, au point que certains responsables d’entre eux, et syndicats d’employés, ont dû démentir ces rumeurs auprès de leurs propres salariés, et clients.
L’émission « C’est pas vrai ?! » d’ici (ex-France Bleu) avait déjà relevé que plusieurs de ces soi-disant sites d’informations « au nom étrange » et « entièrement construits et alimentés par une IA », dont Danahair.fr, Mididelices.fr, ou encore Laplasturgie.fr avaient relayé ces infox dans des articles « signés par des journalistes imaginaires » (les trois sites ont depuis été désactivés).
Et ce, parce que les sites qui « popent » sur Discover « peuvent gagner jusqu’à cent mille dollars par mois pour dix millions de visiteurs, selon une simulation de revenus réalisée par Google », soulignait la radio, évoquant les publicités (Google) omniprésentes sur ces sites : « Plus ces pages sont vues, plus elles génèrent de l’argent. Il faut donc attirer l’internaute avec des titres racoleurs ».
Interrogée par La Voix du Nord, l’Association française pour le nommage Internet en coopération (AFNIC), chargée de gérer les noms de domaine en .fr, explique que les noms de domaine attribués à ces sites « font actuellement l’objet d’une procédure de justification, c’est-à-dire d’une vérification des données du titulaire ». Deux d’entre eux indiquaient d’ailleurs encore récemment « État : bloqué ».
Pendant cette procédure, ces noms de domaine sont « gelés », précise l’AFNIC : « aucune opération administrative (comme une modification des informations du titulaire ou un transfert) n’est possible, sans pour autant que le domaine soit techniquement inactif ». D’après La Voix du Nord, le signalement de ces vérifications ne viendrait pas de Décathlon, qui n’aurait pas non plus porté plainte.
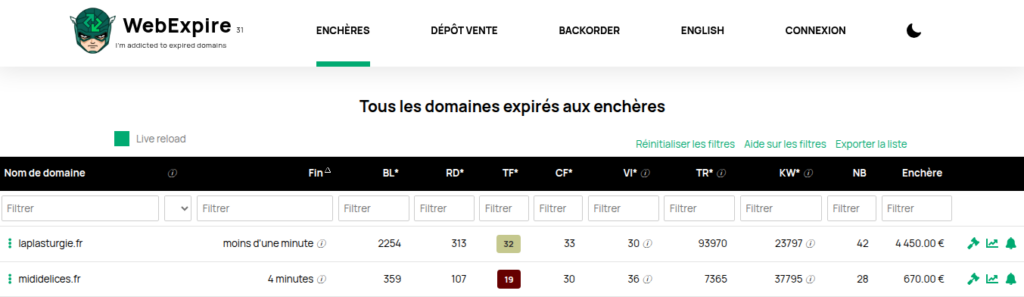
Les deux noms de domaine ont depuis été rachetés. Mis aux enchères 50 €, mididelices.fr a été vendu 880 €. Mis aux enchères à 100 €, laplasturgie.fr a de son côté été adjugé 4 450 €.
« Le maître de la désinformation via une diffusion industrielle de fake news »
Interrogé par CheckNews, l’un des éditeurs de ces sites accuse une figure bien connue des professionnels du marketing numérique et du référencement (SEO) français, Julien Jimenez, d‘être à l’origine de nombre de ces « fake news ». Au point d’être devenu « le maître de la désinformation via une diffusion industrielle de fake news sur ses propres réseaux de sites », qui lui assurerait « un salaire mensuel à six chiffres », avance le service de fact-checking de Libération :
« Quand l’une de ses fausses informations prend de l’ampleur dans l’actualité nationale, il n’hésite pas à trafiquer la date de son article pour donner l’illusion qu’il n’a fait que “reprendre” l’information, et non la diffuser en premier. »
Le Journal du Net avait raconté, en février 2024, les déboires de Julien Jimenez, après la liquidation de ses entreprises de SEO Korleon’Biz et NextLevel, « entachée de dettes et de soupçons de gestion douteuse ».
À l’instar d’une bonne partie des professionnels du « black hat » SEO, dont le modèle économique repose en tout ou partie sur le fait de pouvoir « hacker » les algorithmes des moteurs de recherche en général, et de Google en particulier, il s’est depuis lancé dans le business des sites d’infos GenAI, et serait à la tête d’un réseau de plusieurs dizaines voire centaines de sites « générés par IA », dont franchementbien.fr et atelier-de-france.fr qui, après avoir « popé » sur Discover, ont depuis eux aussi été désactivés.
Contacté par CheckNews, Google lui a répondu avoir procédé à la modération de plusieurs d‘entre eux, dont LaPlasturgie.fr :
« Le règlement de Discover relatif au contenu interdit le contenu trompeur, manipulé et mensonger. Bien que nous ne commentions pas les sites spécifiques, nous prenons les mesures appropriées lorsque nous constatons des violations de nos règles. »
« Comme lors de notre précédente enquête, il aura pourtant fallu que des journalistes humains signalent ces sites indésirables pour que la modération de ces énigmatiques systèmes anti-spam s’opère », conclut de son côté CheckNews.
Et ce, alors que nous relevions déjà, début avril, que l’algorithme de recommandation de contenus Discover de Google promouvait (au moins) une quarantaine de sites générés par IA (GenAI), dont plusieurs relaient rumeurs et infox, au mépris des propres règles du moteur de recherche et de la régie publicitaire de Google.
Si les éditeurs de sites GenAI se lancent dans ce type de surenchère, ce n’est pas par appétence pour les infox et les rumeurs. Mais parce qu’ils y sont incités financièrement, par Google : les pics de trafic résultant d’une mention sur Discover se traduisent en effet par des gains publicitaires (émanant généralement de la plateforme AdSense de Google) pouvant aller jusqu’à plusieurs milliers d’euros, par jour.
« L’algorithme de Discover est troué de failles »
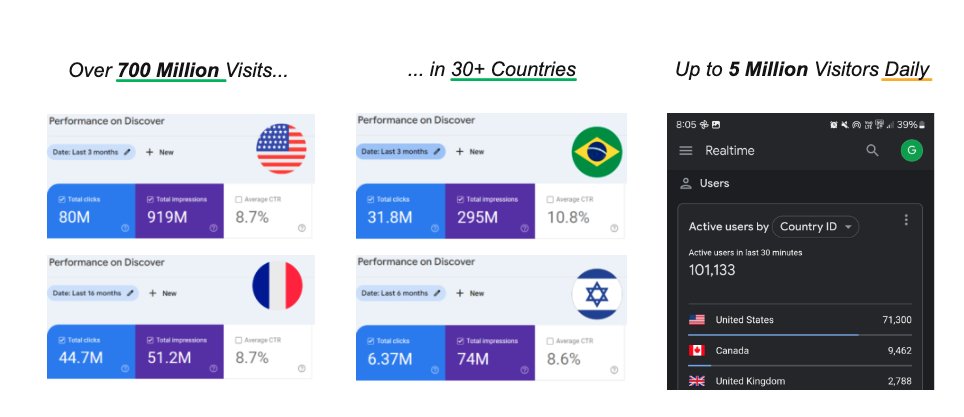
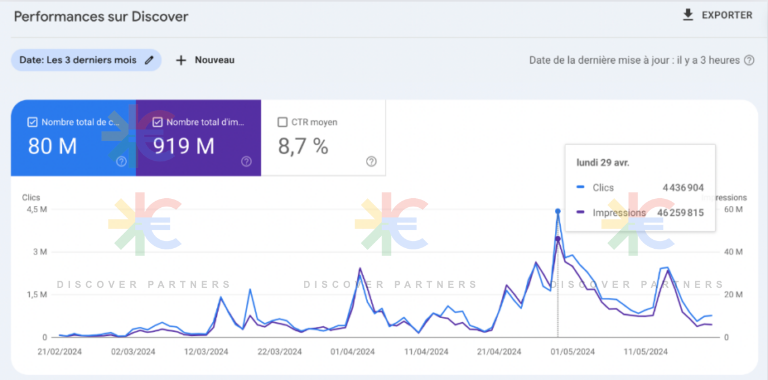
Guilhem C., un professionnel du référencement (SEO) considéré comme l’un des meilleurs spécialistes français de Discover, expliquait l’an passé faire « entre 10 et 100k de CA par mois » depuis 2018 (il a demandé à être anonymisé, ndlr). Et ce, alors que cet éditeur indépendant de 33 ans ne compte qu’un seul employé. Certains de ses sites auraient en effet engrangé plus de 900 millions d’impressions en trois mois, et jusqu’à plus de 5 millions de visiteurs par jour.
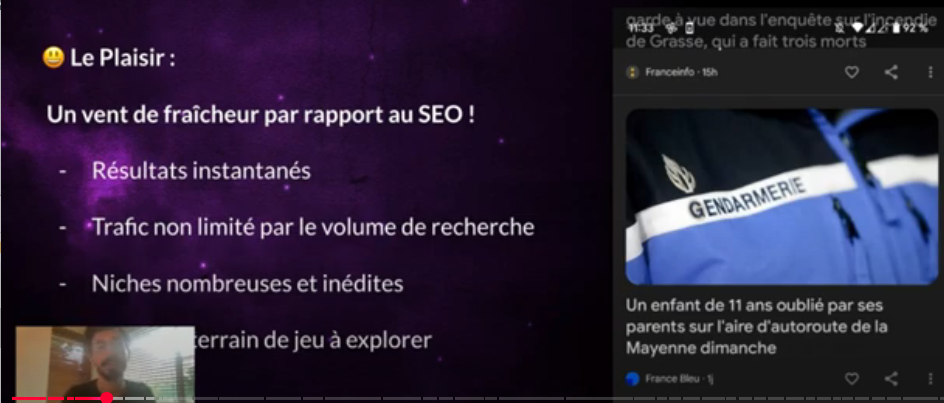
Outre l’aspect financier, il précisait que la première des raisons pour lesquelles il fallait s’intéresser à Discover, c’était le « plaisir » et le « vent de fraicheur » qu’il offrait par rapport au SEO classique, notamment parce que Discover permet de savoir tout de suite « si ça cartonne ou pas », sans devoir attendre plusieurs mois comme c’est le cas avec les pratiques SEO traditionnelles.
En outre, et plutôt que de devoir se focaliser sur les seuls mots-clefs, Discover se concentre sur l’intérêt porté par les internautes à tel ou tel contenu, ce qui permet aussi de « taper » de nouveaux « clusters de niches » et d’offrir « un nouveau terrain de jeu » plus excitant que les éternels comparatifs d’assurances, de plombiers, d’aspirateurs ou d’investissements de type « loi Pinel », entre autres thématiques traditionnellement associées au SEO.
Un exercice d’autant plus excitant que « l’algorithme de Discover est troué de failles », ce qui permet d’ « essayer de trouver de petits hacks » afin d’essayer d’y poper, expliquait Guilhem C. Il prenait pour exemple un article de France Bleu intitulé « Un enfant de 11 ans oublié par ses parents sur l’aire d’autoroute de la Mayenne dimanche » qui, en termes SEO traditionnel, ne contient aucun « mot-clef », mais qui avait fait plus d’un million de vues « juste grâce à Discover », parce que son titre invitait les lecteurs à cliquer sur le lien.
« J’ai vu un article sans contenu texte faire 100 000 visites grâce à Discover »
La deuxième raison qu’il évoquait pour s’intéresser à Discover, c’était l’argent : grâce au trafic généré, il avançait pouvoir engranger plus de 1 000 euros, rien qu’avec AdSense, par jour. Au point de le qualifier de « plus grosse opportunité « SEO » de ces 10 dernières années ».
« Je remercie Google tous les jours pour cette tonne de trafic qu’il m’amène sur un plateau », expliquait-il dans un autre podcast. Car si d’ordinaire les professionnels du SEO doivent attendre qu’un internaute tape certains mots-clefs dans un moteur de recherche, puis clique sur le bon lien – ce qui représente plusieurs barrières à l’entrée –, Discover est « queryless » (sans requête), recommandant des contenus en fonction des préférences supposées des internautes, sans qu’ils aient fait d’autre que d’accéder à l’interface dédiée.
Dans une autre vidéo datant d’août 2023, Guilhem C. expliquait avoir découvert Discover par hasard, en constatant un pic de trafic sur l’un des noms de domaine « expirés » qu’il avait racheté parce qu’il avait auparavant été référencé sur Google News (ce qui augure, généralement, d’une meilleure réputation, d’un meilleur référencement, et donc aussi d’un trafic plus important).
Cherchant à comprendre l’origine de ce pic de trafic, il découvrit que l’un de ses articles avait d’abord été partagé sur un gros groupe Facebook, où il avait généré beaucoup d’interactions, avant d’être recommandé sur l’application Discover.
Pour lui, « l’algorithme de Discover est plus proche de celui de TikTok que de celui de Google Search, parce qu’il va se baser sur le comportement des internautes, l’engagement, plus que sur les mots-clefs de la page », au point d’avoir « déjà vu un article sans contenu texte faire 100 000 visites grâce à Discover ». Sans pour autant comprendre pourquoi l’algorithme de recommandation de contenus de Google aurait ainsi promu un article « sans contenu texte », sinon que son titre et son image d’illustration semble avoir suffi à attirer le chaland.
« Le contenu, on s’en bat les couilles en fait »
Discover, « c’est un peu un algorithme à la TikTok. Plus tu vas naviguer sur des outils Google, que ce soit sur ton téléphone avec Chrome ou avec tes recherches Google et YouTube, mieux il va te comprendre », expliquait elle aussi à Abondance Valérie Verpoest dans une interview croisée de trois professionnels du SEO ciblant l’algorithme de Google avec des articles générés par IA.
Pour autant, précisait David « NinjaLinker » Dragesco, « Le contenu en soi, je persiste à dire que c’est vraiment secondaire ». Pour ce professionnel du SEO et du rachat de noms de domaines expirés, dont 80 % du chiffre d’affaires repose sur un outil de création de contenus générés par IA, « ce qui fait la différence sur Google Discover, c’est le titre et l’image ».
« Le titre et l’image sont les deux éléments les plus déterminants pour générer du trafic sur Discover, bien plus que le contenu lui-même », souligne d’ailleurs Abondance dans un quizz consacré à Discover.
Dragesco, qui se targuait il y a 6 mois d’éditer « plus de 150 sites » présents sur Google News et Discover, expliquait dans une masterclass à ce sujet que ses sites étaient « full IA », qu’il avait amassé beaucoup de datas au sujet de Discover, et qu’il s’était créé un « ChatGPT Discover », pour « utiliser de la data pour régurgiter de la data ». Il reconnaissait pour autant que seuls 10 % de ses sites généraient vraiment des revenus.
Si les journalistes cherchent à identifier des informations « d’intérêt public », susceptibles d’intéresser leurs lecteurs, à les vérifier, de sorte de proposer des articles leur permettant de les contextualiser, David Dragesco avance pour sa part que « le contenu, on s’en bat les couilles en fait ».
Suite à une erreur dans son logiciel de génération de contenus par IA, l’un de ses sites avait, en effet, publié un article dont le titre portait sur l’astrologie, mais dont le contenu expliquait de son côté comment réparer de la tuyauterie avec du bicarbonate de soude. Il n’en avait pas moins « popé » sur Discover, et enregistré 45 000 visites en un jour seulement : « Le titre et l’image donnaient envie de cliquer, mais le contenu n’avait rien à voir ».
Tout comme Guilhem C., il se souvient lui aussi d’avoir cliqué sur le lien d’un article qu’il avait vu « poper » sur Discover, et découvert que l’éditeur du site n’y avait pas encore publié de contenu, la page se bornant à afficher : « content is coming », ce qui n’avait pourtant pas empêcher, là encore, l’algorithme de Google de le recommander.
Dragesco reconnaissait cela dit qu’il fallait quand même « agencer » les contenus générés par IA, parce que les gens risqueraient d’indiquer à Discover qu’ils ne sont « pas intéressés », et donc d’envoyer un signal négatif à l’algorithme de Google.
D’après lui, le plus important, ce n’est pas la qualité ni la pertinence du contenu, mais le fait qu’il génère des réactions, qu’il fasse le buzz, ce pourquoi, expliquait-il, les contenus apparaîtraient souvent sur Discover 24 à 48 heures après leur publication initiale.
Pour y figurer, ils devraient en effet avoir d’ores et déjà commencé à générer des interactions quitte, pour cela, à acheter du trafic, des Google Ads, et bien évidemment en envoyant des pushs sur les réseaux sociaux, pour que Google « ait l’impression » qu’il génère du trafic, « comme si mon article il buzze », d’autant que Discover est « aussi un peu le réseau social de Google ».
Ce pourquoi il se focalise, aussi, sur les noms de domaines expirés ayant précédemment été référencés sur Google News, au motif qu’il lui est arrivé d’en racheter un qui, trois semaines plus tard, lui avait permis d’engranger 100 000 visites, du fait de sa réputation préalablement engrangée.
« J’ai fait des journées à 3 500 - 4 000 euros »
Pour lui, le principal inconvénient de Discover, c’est qu’il serait « pire que le pump and dump de la crypto », cette technique visant à manipuler le cours d’un cryptoactif acheté à bas prix afin d’en gonfler artificiellement la valeur (le pump), puis de revendre (dump) les actions surcotées quand suffisamment de gogos sont tombés dans le piège.
L’un de ses sites aurait, par exemple, réussi à enregistrer jusqu’à 950 000 pages vues en une seule journée, lui permettant de générer 3 750 euros. Son meilleur mois lui aurait par ailleurs permis d’engranger 67 000 euros de chiffre d’affaires. Au prix toutefois d’efforts constants, précisait-il, « quand tu commences à rentrer dans Discover, tu n’as plus de retour en arrière, tu ne peux plus prendre de week-end ou de semaines de vacances, parce que si tu arrêtes, Google peut te dégager ».
« Le revers de la médaille », soulignait-il, c’est que depuis des mois, il ne faisait plus que 100 euros par jour, le fait de « poper » sur Discover ne durant souvent que quelques jours voire semaines seulement, comme il l’explique aussi à Abondance :
« Ça peut arriver dans un moment où parfois t’es en plein boom, tout fonctionne nickel et du jour au lendemain, sans savoir pourquoi, ton site en 24 - 48 heures, tu divises ton trafic par 8 ou même par 100. C’est-à-dire que tu faisais 100 000 de trafic, le lendemain tu te retrouves avec 100 visites. Moi ça m’est arrivé. C’est très dur. Tu passes de 1 200 - 1 500 euros la journée à 15 ou 20 euros, ça fait très mal. Comme je dis souvent, c’est pire que le pump & dump de la cryptomonnaie. Tu as un ascenseur émotionnel assez élevé. »
« C’est comme la roulette russe », ajoutait-il, soulignant que cela arrive aussi à des médias bien installés, qui peuvent eux aussi passer de 2 millions de clics à 20 000 seulement, sans comprendre pourquoi, quand bien même ils connaissent et interagissent avec des employés et responsables de Google.
« J’ai fait des journées à 3 500 - 4 000 euros, quand tu commences ta journée et que tu as déjà fait 1 500 euros, tu perds un peu la notion de l’argent », expliquait-il dans une autre vidéo intitulée « Google Discover 2024 : comment exploiter les failles pour générer jusqu’à 10 000 € / mois ? ».
Il y précisait avoir, lui aussi, découvert Discover par hasard, après qu’un article au sujet d’un climatiseur USB Lidl publié sur l’un de ses noms de domaine « expirés » GNews ait été recommandé par Discover en pleine canicule, quand bien même son contenu était « dégueulasse » et avait été « scrapé automatiquement ».
Dragesco y avançait aussi qu’un site disposant d’un trafic SEO de 1 000 visites par jour pouvait espérer en obtenir 10 000 s’il parvenait à être référencé par Google News, et 100 000 s’il popait sur Discover. Ce qui expliquerait, également, pourquoi tant de professionnels du SEO se sont eux aussi lancés sur ce créneau, Plusieurs d’entre-eux, dont Guilhem C., ont d’ailleurs lancé des formations dédiées à Discover, qu’ils promeuvent sur les réseaux sociaux en se vantant des revenus record qu’ils auraient généré grâce à l’outil.
« Millionnaires », en trois mois, grâce à une faille de l’algorithme Discover
Dans un autre podcast, Guilhem C. revendique de son côté avoir fait jusqu’à 70 000 euros de chiffre d’affaires par jour, « juste sur AdSense, avec Discover », mais également 2 millions d’euros de chiffres d’affaires, en 3 mois seulement, après être rentré dans le top 1000 des sites les plus visités au monde. Il relevait à ce titre que Discover est aussi et surtout une « vache à lait » pour Google, bien plus que pour les pros du SEO, puisqu’il perçoit des commissions sur toutes ces publicités.
Une autre figure des pros du SEO, Nicolas G. (qui nous a demandé d’anonymiser son nom, ndlr), de l’agence Tremplin numérique, était revenu plus en détail sur ce qu’il qualifia de « l’un des plus gros braquages de l’année » dans une autre vidéo, expliquant comment il était devenu millionnaire, au point d’ « acheter cash un petit appartement à Dubai », grâce à Discover et Guilhem C.
Nicolas G. avait en effet acheté sa formation Discover, mais pas eu le temps de la suivre en détail. Or, l’un des modèles économiques de Guilhem C. est de proposer aux propriétaires de noms de domaine « expirés » de s’occuper de leur stratégie Discover, en échange d’un partage à 50/50 de leurs revenus publicitaires. Nicolas G. lui aurait alors proposé un partenariat sur un nom de domaine qu’il avait racheté 1 200 €, parce qu’il avait précédemment, et lui aussi, « ranké sur GNews »
Or, l’un des articles optimisés pour Discover par Guilhem C., décliné plusieurs fois au vu de son succès sur le site en question, leur aurait permis de connaître des pics journaliers de 4 à 5 millions de visites, générant des « records à 60 000 € sur AdSense par jour », « jusqu’à ce que Google lance une action manuelle pour spam » après qu’ils aient engrangé 2 millions d’euros de publicités.
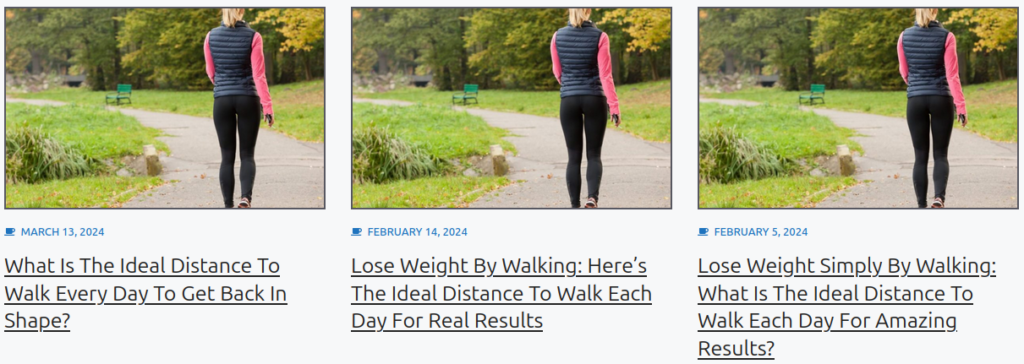
L’article, qu’il avait refusé de mentionner mais que nous avons retrouvé, n’avait en tant que tel rien d’exceptionnel. Il expliquait quelle était la distance idéale de marche à pied à effectuer au quotidien pour espérer perdre un peu de poids.
Sauf que la photo d’illustration montrait une femme avec ce qui ressemblait à… une cigarette : « on a du recevoir 3 à 400 mails de gens : vous vous foutez de notre gueule ? Et donc il passaient plus de temps sur l’article, et donc pour Discover c’était un plus : plus les internautes restent, plus on ranke ! »
Et ce, quand bien même une version haute définition de la photo en question indique qu’il s’agit en fait du cordon blanc de son écouteur, connecté à son téléphone portable, ce que permettent de vérifier les autres photographies de la jeune femme.
Discover était également induit en erreur du fait qu’un certain nombre d’internautes passaient plus de temps que de raison sur le site afin, là encore, de se plaindre… d’une seconde boulette : son contenu était en effet constitué d’articles européens traduits en anglais, avec des prix en euros, alors que le site ciblait une audience états-unienne
Or, comme l’explique Abondance dans son quizz sur Discover, le temps passé sur un article (le « watchtime »), et donc la capacité d’un site à maintenir l’attention du lecteur pendant un certain temps, semble constituer un facteur déterminant pour le « ranking de son algorithme.
Et ce, quitte à « introduire du suspense en révélant les infos progressivement », voire à y évoquer des informations de façon suffisamment tarabiscotée pour que l’internaute passe du temps à tenter de comprendre la « promesse » qu’en faisait le titre (« accrocheur ») et l’image (« impactante ») associée.
Nous avons effectivement constaté que les titres de la quasi-totalité des articles GenAI « popant » sur Discover survendent les informations dont il est question. Ce qui est aussi souvent le cas des contenus émanant de sites d’information employant de vrais journalistes, cela dit.
Un pro du SEO avait à ce titre partagé « une astuce Discover qui déchire tout : parlez d’un produit, faites une erreur dans la photo à la une. Les puristes vont se ruer sur votre article pour vous insulter »… et donc passer du temps sur le site, faisant croire à Google que le contenu serait, sinon de qualité, tout du moins engageant.
Guilhem C. lui avait d’ailleurs répondu que cela « marche aussi très bien avec les fautes d’orthographes ou mauvaises photos de personnalités ». Sans pour autant préciser que ce type d’ « astuce » et « bugs » lui aurait permis de devenir millionnaire en seulement trois mois.
Dans la vidéo, Nicolas G. expliquait également qu’il gérait 2 500 noms de domaine, « dont 500 qui génèrent de l’argent, en gros », et en racheter une centaine par mois, « soit 3 par jour » : « on n’a pas le temps de tous les relancer, c’est compliqué, quand on a déjà cinq sites argentins pour éduquer son chien… alors on les revend, ça fait 2 ans déjà qu’on fait ça ».
Discover « génère une dépendance, c’est une drogue »
Clément Pessaux, un autre pro du SEO lui aussi spécialiste de Discover, que nous avions interviewé pour notre article sur cette rumeur générée par IA et relayée par de nombreux médias, estime lui aussi, dans une autre vidéo, que les perspectives de profits générés par Discover peuvent s’avérer délétères :
« Le problème avec Discover, c’est que ça génère énormément d’adrénaline : quand tu as un site qui commence à faire 100 00 ou 200 000 visites par jour, avec 10 000 visiteurs en simultané qui génère entre 200 à 500 euros par jour, multipliés par 30 ça fait 15 000 euros… Ça génère une dépendance, c’est une drogue, il faut le dire, parce que ça génère pas mal d’argent, et quand t’es là-dedans ça devient difficile de lâcher prise, tu deviens mégalo avec ça. »
Une dépendance rendue d’autant plus addictive que « quand tu maîtrises un peu le truc, et que ton site est bien rentré, y’a un côté facile : 5 - 6 articles par jour, avec de l’IA, ça te prend une petite heure maximum, et tu te dis ça va me générer 500 balles, donc c’est le rêve ultime ! C’est pas la semaine de 4 jours, c’est 1 heure par jour, c’est la semaine de 7 heures (parce que c’est 7j/7) ! »
Clément Pessaux soulignait en outre que « Discover, c’est le royaume de l’espionnage : sur Semrush, on regarde ce qui a performé sur mobile, et on présuppose que ça vient de Discover, et tous tes concurrents font ça ». Des plagiats encouragés par le fait que « le duplicate content n’est pas pris en compte par Discover : je peux copier-coller un article, le republier, et faire plus de trafic que la personne que j’ai copiée ! ».
Pour autant, et au vu de l’imprévisibilité de l’algorithme, il estimait cela dit que Discover « doit toujours n’être qu’un revenu complémentaire, ou d’investissement, parce que du jour au lendemain ton site peut disparaître complètement, et les revenus qui vont avec. C’est comme si on voulait gagner au loto tous les jours ».
Une précaution également mise en avant par Dragesco, pour qui « Discover, c’est la cerise sur le gâteau ». Il alerte lui aussi les gens désireux de s’y lancer au sujet de l’importance d’avoir d’autres sources de revenus passifs, de sorte de ne pas dépendre uniquement de l’algorithme de Google.
Dragesco a d’ailleurs lui-même rouvert un club (payant) de rachat de noms de domaines expirés, et lancé une plateforme de vente de liens sur des sites référencés et/ou optimisés pour Google News et Discover, afin de gonfler artificiellement le trafic vers les sites de ses clients, en ciblant notamment des agences d’e-réputation.
Ces spécialistes de Discover s’accordent en outre à considérer que le marché français serait aujourd’hui saturé de pros du SEO tentant de « poper » sur Discover, et préfèrent donc s’attaquer à des marchés de niche, dans d’autres pays et d’autres langues, moins concurrentiels.
« On n’est pas journalistes. Notre job, c’est gruger l’algo pour faire du trafic »
Interrogé par Abondance pour savoir comment il garantissait la véracité des informations partagées dans ses articles générés par IA, et quelles mesures il prenait pour éviter la propagation de contenus trompeurs, David Dragesco rétorquait que « la question, c’est est-ce qu’on travaille de manière éthique, mais on n’est pas des journalistes », ce pourquoi « la véracité de nos informations, ce n’est pas forcément notre prérequis. Notre prérequis, c’est gruger l’algo pour pouvoir faire du trafic » :
« Nous, on est des trouveurs de failles, des filous. […] S’il faut s’adapter pour faire de la véracité, on fera de la véracité. Mais tant qu’il y a ces failles-là, on les exploite. On n’est pas journalistes. Autant les journalistes, eux, ils ont vraiment une conscience. […] Nous, on est des petits éditeurs de sites. Et à l’origine, on est SEO, un peu black hat. Et on est finalement des testeurs d’algorithmes. »
Dans la vidéo expliquant comment Discover pouvait permettre de « générer jusqu’à 10 000 € / mois », Dragesco reconnaissait être « borderline, je ne le cache pas, on sait tous qu’on a tendance à être borderline sur cet aspect contenu, encore plus avec l’IA aujourd’hui puisqu’on n’a même plus besoin d’aller chercher du contenu ».
« Par contre », précise celui dont le bandeau de profil, sur LinkedIn, arbore un logo cassé de Google, « s’il y a bien un responsable et quelqu’un à qui on peut s’en prendre dans toute cette histoire de désinformation qu’il peut y avoir, je pense que c’est Google lui-même, très sincèrement. Parce que s’il voulait, il pourrait faire en sorte de faire un meilleur tri, d’améliorer son algo » :
« Parce que si Google voulait vraiment vérifier les informations, ils ont les moyens de déployer des algos de détection de véracité. Mais qu’est-ce qui se passe ? On tourne dans un vase clos où finalement Google gagne de l’argent sur le dos des petits éditeurs comme nous, mais nous on ramasse quoi par rapport à Google ? On ramasse que des miettes. On est là pour ramasser quelques miettes parce qu’on est un peu des filous et on profite de failles de chez Google qu’ils pourraient très clairement patcher. »
14 % du Top 50 de Discover est généré par IA
Le Top 50 de DiscoverSnoop.com des sites d’informations les plus recommandés en France par l’algorithme Discover de Google, en avril, répertorie 6 sites générés par IA, dont laplasturgie.fr (12e, avec 167 publications recommandées sur Discover) et atelier-de-france.fr (38e/142), qui ont donc depuis été désactivés.
À titre de comparaison, cnews.fr y figure à la 14e position, leprogres.fr est 15e, jeuxvideo.com 16e, francebleu.fr 17e, tf1info.fr 18e, sudouest.fr 19e, liberation.fr 20e, 20minutes.fr 23e, marianne.net 25e, ledauphine.com 26e, beinsports.com 27e, laprovence.com 29e, yahoo.com 32e, lavoixdunord.fr 33e et nicematin.com 35e.
En mars, le Top 50 de DiscoverSnoop.com comportait déjà 7 soi-disant sites d’informations générés par IA. Ils n’étaient que cinq en février, et quatre en janvier. Depuis janvier, plus de 75 sites « générés par IA » (au moins) ont été mis en avant par l’algorithme de recommandation de contenus Discover de Google en France.
15 d’entre eux ont même figuré dans le Top50 des sites ayant le plus « popé » sur Discover en France, dont 1 pendant 5 mois, 3 pendant 3 mois, 2 pendant 2 mois, & 4 dans son Top25 (dont un pendant 3 mois consécutifs, un autre 2 mois de suite).
Nous n’en publions pas les noms de domaine pour ne pas risquer d’être accusés de les avoir dénoncés à Google, d’autant que ces sites ne respectent pas ses propres règles, et qu’il se targue pourtant de filtrer 99 % du spam. Comme indiqué dans le tout premier article de notre enquête fleuve, nous ne rendons pas publique l’intégralité de la liste de ces sites, pas plus que celle des entreprises, pour plusieurs autres raisons.
Nous ne voulons pas, d’une part, que cette base de données puisse aider ceux qui voudraient améliorer leurs générateurs d’articles automatisés, et qui se targuent de ne pas être reconnus comme GenAI. Nous ne voulons pas non plus faire de « name and shame » et mettre sur le même plan des auto-entrepreneurs SEO ayant créé quelques sites de façon opportuniste et les entreprises (y compris individuelles) en ayant créé plusieurs dizaines, voire centaines.
Mi-mai, deux autres sites GenAI avaient cela dit explosé sur Discover, au point que leurs infox’ ont d’ores et déjà suscité plusieurs fact-checkings : sfsd.fr, exploité par l’administrateur de laplasturgie.fr (qui figure en 15e position du Top50 de mai, avec 675 articles « recommandés »), et farmitoo.com, qui mentionne Jimenez Julien dans ses mentions légales (et qui figurait en 9e position du classement de mai, avec 296 articles « recommandés »). Ils ont cessé d’apparaître sur Discover depuis début juin.
Contacté il y a 15 jours, Google nous a réclamé plus de précisions sur notre méthodologie, que nous avions résumé dans le tout premier article consacré à l’extension permettant d’être alerté lorsqu’on visite un site que nous avons identifié comme étant, « en tout ou partie », généré par IA, ainsi que dans un article dédié.
Google a accusé réception de nos explications revenant plus en détails sur ladite méthodologie, précisant qu’elles avaient été transmises aux équipes concernées, mais n’a pas encore, par contre, et malgré nos relances, été en mesure de répondre à nos questions. Nous mettrons cet article à jour, ou y consacrerons un nouvel article, en fonction de leurs (éventuelles) réponses.












Commentaires (33)
Le 06/06/2025 à 20h57
pas grand chose à dire à part
Le 06/06/2025 à 22h13
Vu le nombre de personnes qui, entre éthique et pognon, choisissent sans hésitation la deuxième option, il ne faut plus s'étonner de l'état de la planète.
Le 07/06/2025 à 10h40
Le 07/06/2025 à 15h07
Ces aspects ont toujours été secondaires et sont recherchés "si et seulement si" il y a un intérêt financier (ie : prendre des amendes, se faire boycotter etc.) ou pénal (tu vas finir en prison car tu fais du business dans un pays qui défends ses citoyens...).
C'est d'ailleurs ce qui est plus le cocasse dans la volonté de "déréguler" le marché des entreprises, puisque ce sont uniquement les régulations qui font que les entreprises sont "à peu près" respectable des droits de l'Homme...
Le 08/06/2025 à 08h47
Le 09/06/2025 à 09h12
Le 09/06/2025 à 09h08
pour le pire…
ou pour le meilleur (exemple, les lanceurs d'alerte).
Le 06/06/2025 à 22h23
Le 06/06/2025 à 22h34
"Durant toute ma vie, j'ai gagné un max de pognon en générant de la m*rde, en permettant à un max de personnes de la voir et en formant d'autres personnes à faire de même avec mes Masterclass : je suis fier de moi"
Le 07/06/2025 à 15h12
Il y a aussi les leaks sur les influenceurs en convention, qui crache à la gueule de leur "fan" et explose leurs cadeaux en hurlant que ça les dégoutes de recevoir ça de gens aussi moches dans les coulisses...
Le 09/06/2025 à 11h02
Après on a retenu que certaines phrases. Il dit clairement qu'il n'en a pas rien a faire des gens, mais que pour se faire élire et pouvoir appliquer une bonne politique, ça ne sert a rien de faire l'effort de parler aux gens intelligents avec des argument compliqués, ça ne rapporte pas de voix.
Le 07/06/2025 à 00h02
Modifié le 07/06/2025 à 10h06
Le 07/06/2025 à 22h21
Je veux dire : tu es Google, tu vois que des petits malins ne respectent pas tes règles, tu arrêtes de les payer, fin de l'histoire. Non ?
En plus, double effet kisscool, comme tu mes payent pas, tu récupères leur part de revenus publicitaires et/ou tu fais un geste commercial à tes annonceurs.
Le 07/06/2025 à 06h44
Le 07/06/2025 à 09h10
Le 07/06/2025 à 09h39
Je m'estime heureux d'être hermétique aux "recommandations" de je-ne-sais-qui pour je-ne-sais-quelle-raison. À une époque je trouvais par exemple les listes Steam pertinentes. Puis désormais, elles sont peuplées par des titres en mode "parce que c'est populaire". Et ce malgré avec mis en ignore à peu près tous les jeux de foot qu'il m'a proposé auparavant.
J'en ai donc déduit que les algo sont juste fais par des cons et sont donc à ignorer.
Le 07/06/2025 à 11h18
Mais au final le coupable, c'est Google !
Les mecs profitent du système, ils gagnent peut être quelques millions, mais Google en gagne des centaines !
Google ne changera donc rien à cela et va même étendre le truc puisque Discover doit arriver sur desktop.
Et les perdants sont les annonceurs, c'est eux qui se font racketter.
Et Microsoft n'est pas mieux, allez voir MSN qui reprend les mêmes bouses issues de sites GenAI (tagués comme tel par le plugin Next).
Le 07/06/2025 à 13h22
Ces annonceurs n'ont pas plus de responsabilité que cela, aujourd'hui (même au regard de la publicité mensongère, d'ailleurs). Et ils payent des camions de pognon entier pour être présent sur ces espaces médiatiques. Ils s'en tapent que ce soit des fake news, générée par IA ou pas. Et c'est bien un problème.
Pour eux c'est : Article cliqué = 1 vue. 1 clic sur la pub = 1 vente potentielle.
Je ne suis pas certain que les annonceurs soient rackettés. Ils sont prêt à payer pour être vu. Et il y a forcément un comptable dans la boite qui a fait le rapport dépense pub vs vente. Et ça investi pas mal tant que c'est positif. Après c'est plus ou moins cher suivant la taille de la boite.
C'est comme le risque au procès. Y'a toujours un mec qui calcule l'amende potentielle avant de s'engager.
Alors évidement comme il y a un mec prêt à payer des trains AMTrack entier de tunes. Il y aura toujours un mec en face pour essayer de capter.
Google a une part de responsabilité morale de "checker" pas vraiment légale/pénale. Enfin si on vient les chercher; ils s'en sortiront relativement facilement.
Personnellement, je prône pour une responsabilisation des annonceurs sur le plan pénal directement. A partir de là, ils vont automatiquement forcer les régies (pas que Google) à ne pas diffuser là ou cela pourrai mener à une amende. Idem pour les critères de la publicité mensongère que je trouve trop laxistes.
Le 07/06/2025 à 14h13
En tant qu'annonceur, je n'ai pas envie que mes pubs passent sur un site poubelle (comme sur un site de fachos, de cul, etc.) et là Google le fait, c'est donc Google le responsable et le coupable de A à Z !
Le 07/06/2025 à 15h43
Pour la partie technique c'est le site qui inclue les scripts de Google (pour simplifier) qui va afficher une têtière ou une bannière etc. Et ça Google n'a pas vraiment de moyen de bloquer en avance de phase ou d'incitation à le faire. Tout du moins être prudent.
C'est simple de créer un compte Adsense et de copier / coller le script. Quand ce n'est pas un module WP qui le fait directement. Et évidement les mots clés choisis, pour happer du trafic.
Du fait des problèmes techniques; responsabiliser Google sera plus une impasse qu'autre chose. Ils ont tous les arguments pour éviter la prune.
C'est pour cela que je penche pour que l'annonceur soit plus "responsabilisé". Maintenant je parle des gros. Ceux qui déjeunent avec des boss de Publicis au Fouquets. Pour des plus petits, c'est plus compliqué, j'en convient. Mais tant que l'annonceur ne force pas Google à vérifier d'abord...
Le 07/06/2025 à 22h27
Modifié le 08/06/2025 à 12h13
Le 08/06/2025 à 14h06
Le 09/06/2025 à 13h54
L'argent liquide est fait par la "monnaie" (dans le bordelais pour les pièce à face française). Et une fois une pièce ou un billet mis en circulation. Pas de frais de gestion facturable. Pas de traçage. Obligation de gérer les dépôts en liquide dans les guichets de banque. Et donc de gérer les volumes d'argent dans les caisses de chaque agence et de le transporter quand besoin il y a... sécurité tout ça.
Donc quand Darmanin dit cela, j'entends un PDG de banque qui finance sa campagne pour 2027.
Les paris son ouvert pour 2027. Quoiqu'avec Darmanin je ne prend pas de gros risques.
Le 09/06/2025 à 15h56
"(ou alors il est vraiment...)"
Comme vauquiez il n'est pas gèné de raconter n'importe quoi. Ce qui n'exclue pas ta proposition.
Ce que je voulais souligner, c'est que vu la qualité des discours
irldes politicards il ne faut pas s'étonner que répétée, amplifiée, déformée, n'importe quelle rumeur puisse se propager. Le réseau ne fait qu'accélérer le procesus.Le 09/06/2025 à 17h03
Le 10/06/2025 à 12h48
Le 12/06/2025 à 00h33
Le 13/06/2025 à 08h04
=> J'ai tellement envie de cliquer dessus ! C'est horrible de nous faire subir des choses comme çà
Le 17/06/2025 à 14h17
Le 17/06/2025 à 17h53
Le 17/06/2025 à 20h01
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?