

Avec Opus 4.8, Claude apprend à dire « je ne sais pas »
La vérité si je mens

Ça n’aura pas traîné : à peine 40 jours après le lancement d’Opus 4.7, Anthropic remet le couvert avec une nouvelle version de son modèle IA le plus avancé (hors Mythos). Opus 4.8 inaugure une nouvelle fonction pour améliorer la prise en charge des requêtes très complexes, réduire les erreurs, ainsi qu’un nouveau mode « fast » pour brûler moins de tokens.
Impossible d’arrêter le feu roulant des nouveaux modèles chez Anthropic. Opus 4.7 remonte au 16 avril, mais il est déjà passé de mode : son successeur, Opus 4.8, a en effet été annoncé par le labo IA. Le modèle apporte des améliorations « modestes mais tangibles », affirme l’entreprise, à commencer par… une plus grande prudence quand il ne sait pas quelque chose.
Plus d’honnêteté, moins de tokens
Selon les testeurs cités par Anthropic, Opus 4.8 se montre plus honnête : il signale plus facilement ses incertitudes, évite les affirmations qui ne sont pas vérifiées et laisse moins passer de bugs sans les mentionner. « Un problème général avec les modèles d’IA, c’est qu’ils tirent parfois des conclusions hâtives, en affirmant avec assurance avoir progressé dans leur travail alors que les preuves sont minces », explique la startup. Elle affirme que le nouveau modèle est « environ quatre fois moins susceptible » de laisser des défauts non signalés dans le code, par rapport à son prédécesseur.
Autre nouveauté : une fonction expérimentale baptisée « dynamic workflows » pour Claude Code. Le modèle est en mesure de gérer de très gros projets logiciels en parallèle, ce qui lui permet de les découper en petits bouts, de lancer des centaines de sous-agents en simultané et de vérifier automatiquement les résultats avant de répondre. Anthropic donne en exemple une migration massive de bases de code contenant « des centaines de milliers de lignes ».
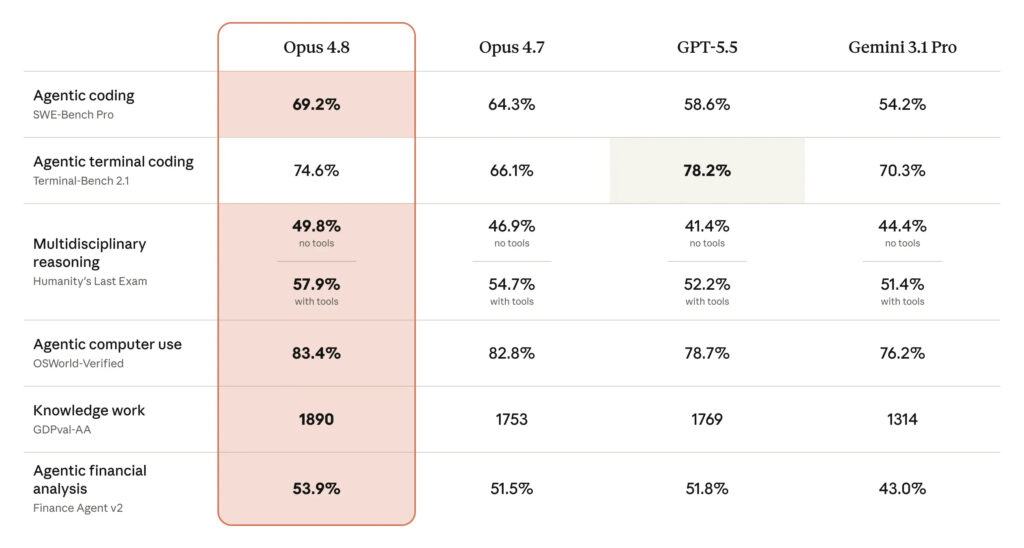
En termes de benchmarks, Opus 4.8 affiche des gains incrémentaux sur la plupart des tests (+ 4,9 points sur SWE-Bench Pro,+ 8,5 points sur Terminal-Bench…). Anthropic ne fait pas de bond spectaculaire ici, mais améliore l’existant par petites touches et maintient sa position sur les tâches agentiques. C’est cohérent avec la stratégie de la startup qui vise d’abord les développeurs et les entreprises : sur SWE-Bench Pro (agents de programmation), Opus 4.8 est loin devant GPT-5.5 et Gemini 3.1 Pro. Le modèle d’OpenAI reste cependant le patron sur Terminal-Bench, qui mesure des tâches très proches d’un vrai environnement développeur.
La brûlure des tokens
Un des changements les plus importants de cette nouvelle livrée est un réglage d’effort dans claude.ai et Cowork. L’utilisateur peut sélectionner le niveau de ressources à consacrer à une réponse : un effort « faible » retournera des réponses moins précises mais le processus de réflexion sera plus rapide et surtout moins coûteux, à l’inverse d’un effort plus élevé. Par défaut, Opus 4.8 est réglé sur un effort élevé, qui offre selon Anthrophic le meilleur équilibre entre « qualité et expérience utilisateur ».
Sur les travaux de code, ce niveau d’effort consomme le même volume de tokens qu’Opus 4.7 par défaut, « mais avec de meilleures performances ». Cette question des tokens est devenu très sensible, Opus 4.7 se montrant très gourmand en la matière. Une critique qui n’a pas échappé à Anthropic : les limites d’utilisation dans Claude Code ont été relevées pour les niveaux d’effort supérieurs.
Toujours dans cette même optique, Anthropic a révisé fortement à la baisse le coût du mode « rapide » pour Opus 4.8, désormais trois fois moins onéreux que son équivalent sur Opus 4.7. Ce mode, qui travaille 2,5 fois plus vite, revient maintenant à 10 dollars par million de tokens en entrée, et 50 dollars par million de tokens en sortie. C’est trois fois moins cher que pour les précédents modèles (30/150 dollars). Les tarifs pour un usage standard d’Opus 4.8 ne changent pas : 5 dollars par million de tokens en entrée, 25 dollars en sortie.
Enfin, fidèle à une stratégie marketing bien rodée, Anthropic fait miroiter le lancement « dans les prochaines semaines » de modèles grand public basés sur Mythos, le fameux LLM tellement balaise qu’il n’est distribué qu’au compte-goutte au travers du projet Glasswing.
L’entreprise explique que le développement de garde-fous avance bien. Ces mécanismes de sécurité seraient nécessaires pour éviter que les capacités de Mythos ne puissent servir aux pirates pour exploiter des failles. Ces nouveautés et cette agitation autour de Mythos est de bon aloi, alors qu’Anthropic s’apprête selon les rumeurs à se lancer en bourse d’ici la fin de l’année, alors même que l’entreprise vient de boucler une nouvelle levée de fonds record.

Commentaires (37)
Abonnez-vous pour prendre part au débat
Déjà abonné ou lecteur ? Se connecter
Cet article est en accès libre, mais il est le produit d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles d'un média expert
Profitez d'au moins 1 To de stockage pour vos sauvegardes
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 29 mai à 09h26
Le 29 mai à 09h26
Le 29 mai à 10h29
Le 29 mai à 11h16
https://www.franceinfo.fr/monde/iran/guerre-entre-les-etats-unis-israel-et-l-iran/quand-donald-trump-menace-de-pulveriser-oman-pays-allie-des-etats-unis_8033450.html
Il est aussi fiable que l’IAgen
Modifié le 29 mai à 09h35
Et il y a un espèce de fan-service qui s'est installé pour Claude parce qu'ils ont été les premiers à proposer quelque chose de vraiment potable pour le développement, pourtant Codex bosse désormais vraiment bien, bien que les modèles 5.4 et 5.5 aient fait enfler les prix et la quantité de tokens sur les limites sur 5H et sur la semaine.
Je suis en train de faire de la recherche en ce moment même sur du code lourd pour comprendre comment lancer n'importe quel jeu via KMS sans compositing/environnement de bureau, et codex bosse sans discontinuer depuis des lustres avec /goal pour effectuer les recherches et tous les tests nécessaires tout en documentant...
Le 29 mai à 10h43
Viser une rentabilité et faire payer le vrai prix d'un service par rapport à ce qu'il coute, c'est plutôt bon pour l'avenir. Surtout quand tout le monde parle de cette fameuse bulle.
Après à l'usage à l'instant T, c'est sur que si un autre service fait mieux sans limite, autant prendre l'autre en tant qu'utilisateur.
Le 29 mai à 19h02
Anthropic a clairement la rentabilité comme but, là où OpenAI s’en fou du budget il faut se placer…
Le 29 mai à 09h30
Dans un monde normal, aucune de ces boites d'AI n'existerai entre aujourd'hui ...
Modifié le 29 mai à 09h33
Comme toute ruée vers l'or, ce sont les fabricants et vendeurs de pelles et de pioches, les grands gagnants, ce site le confirme.
Le 29 mai à 09h58
Le 29 mai à 10h06
Modifié le 29 mai à 10h21
Blague à part, ça démontre le délire des américains là où l'investissement français et chinois est plus équilibré.
Qu'ils se pètent la gueule, ça nous fera des vacances et du boulot en plus
Le 29 mai à 12h43
Juste pour dire que ce n'est pas forcément un mal ces investissements.
Modifié le 29 mai à 18h18
Le 29 mai à 22h28
Le 29 mai à 22h55
Modifié le 1er juin à 20h54
On n'utilise plus de locomotrices à vapeur et charbon aujourd'hui.
Tu veux dire que les métiers du savoir et de la connaissance n'ont pas de but réel dans l'économie ? Ingénieurs, avocats, médecins, profs etc.
Modifié le 1er juin à 21h50
Le 1er juin à 22h01
Bien sûr que les chemins de fer ont continué à demander des investissements, mais les investissements initiaux n'étaient pas périmés en 3 ans. Que vaudront les GPU dans 3 ans ? Et les TWh dépensés en énergie pour entraîner les modèles, que seront-ils devenus ? Du vent. Un nouveau modèle sort tous les 6 mois.
Le 1er juin à 22h08
https://en.wikipedia.org/wiki/Railway_Mania
https://fr.wikipedia.org/wiki/Krach_de_1847
Qui est réellement demandeur ? Les milliards d'utilisateurs de ces modèles. Il n'y a plus de doute aujourd'hui sur le fait que la demande existe et que les gens sont prêts à payer pour leur utilisation.
Le 3 juin à 17h03
Tu iras expliquer ça à tous les rats qui quittent le navire copilot pour des concurrents (qui finiront par faire pareil et facturer à l'usage).
Modifié le 4 juin à 19h48
Si tout le monde en parle c'est simplement car n'importe qui peut voir à quel point c'est révolutionnaire, peut-être encore plus qu'Internet et le smartphone.
C'est bien la raison pour laquelle ça va causer des problèmes majeurs.
Ceux qui ne l'utilisent pas en payeront aussi le prix (même plus que les autres), tout comme les agriculteurs qui continuaient de travailler la terre avec leur âne ne pouvaient pas se soustraire à la compétition de ceux utilisant des machines agricoles, ou de la même manière que les moines copistes ne pouvaient pas éviter la compétition de l'imprimerie.
Utiliser une machine agricole ou une machine à imprimer n'est pas de la flemme, c'est juste utiliser l'outil le plus adapté pour la tâche à ce moment de l'Histoire.
Le 4 juin à 22h20
Mais t'en sais rien en fait, arrête d'essayer de nous vendre ta came.
Le 3 juin à 16h58
Le 29 mai à 13h44
Le 29 mai à 20h03
*pas que d'ailleurs
Modifié le 29 mai à 10h01
Cette propension à aller dans le sens de l'utilisateur est clairement très pénible et oblige à challenger les réponses. Pour le boulot tech en tout cas, je n'ai pas d'autres utilisations des LLM.
Modifié le 29 mai à 09h40
Le 29 mai à 10h02
Modifié le 29 mai à 10h18
(
Les chat bots, ou l'école des fans 3.0.
Modifié le 29 mai à 11h34
Dans un premier temps je me suis dit "peut-être est-ce mieux que nous construisions des IA dont la directive première soit de nous faire plaisir, histoire d'éviter skynet".
Puis après je me suis souvenu que la littérature fournissait assez d'exemples de comment ça ne marche pas. 2001, Le cycle des robots, La machine s'arrête...
Le 31 mai à 14h03
De même que si tu leur dis de te challenger et de chercher des erreurs, ils se mettent à relever plein de non-erreurs, parfois même en l'admettant à moitié ("Tu as fait ceci au lieu de cela... ce qui est accepté, mais peut être qu'il faudrait faire cela pour ").
Le 29 mai à 20h10
De nos tests (depuis nov 25), j'ai l'impression que c'est un peu moins le cas au fil du temps. Je me demande si Anthropic ne serait pas confronté à des choix à faire en terme de répartition de charge aujourd'hui, réservant la performance à des clients ciblés. Le reste des clients qui augmentent à priori se partageant ce qu'il reste.
Multiplier alors les modèles n'aurait en réalité qu'un objectif marketing?
Le 29 mai à 21h14
Le 30 mai à 09h42
Modifié le 30 mai à 21h54
Modifié le 30 mai à 21h57
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?