

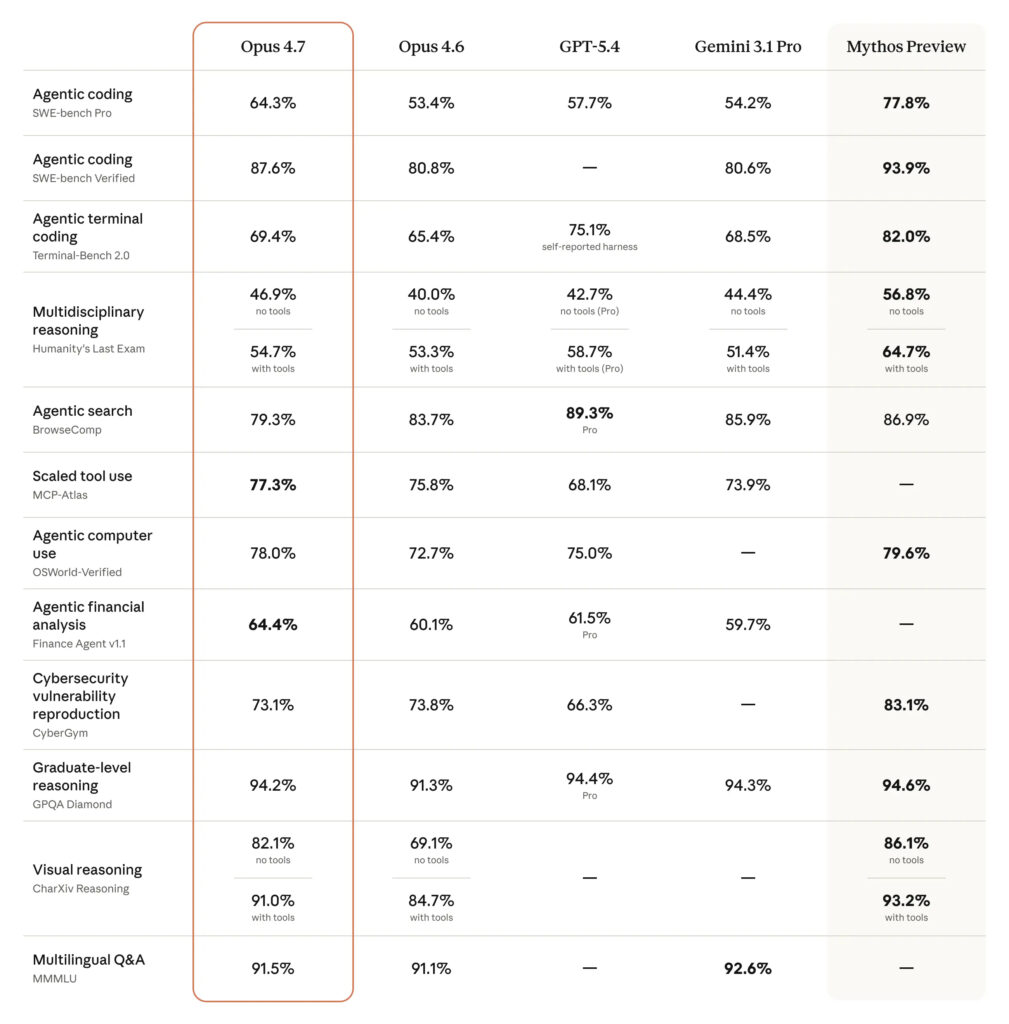
Claude Opus 4.7 : le nouveau modèle d’Anthropic se veut plus performant et plus gourmand
Un effort qui se paie

À chaque jour son grand modèle de langage, ou presque. Anthropic a en effet dévoilé Claude Opus 4.7, son LLM le plus performant (en dehors de Mythos). Des performances qui se paient : le modèle peut se montrer plus gourmand.
Un peu plus de deux mois après Claude Opus 4.6, et une semaine après Mythos, Anthropic a lancé Claude Opus 4.7, présenté comme son modèle IA le plus performant à ce jour… pour le grand public. Mythos détient toujours la couronne du LLM le plus puissant au catalogue d’Anthropic, mais compte tenu de ses capacités en cybersécurité, il n’est déployé qu’au compte-goutte via le projet Glasswing.
Opus 4.7 est « moins capable » que Mythos, admet l’entreprise. Le modèle intègre en effet des garde-fous capables de détecter et de bloquer automatiquement les requêtes liées à « des usages de cybersécurité interdits ou à haut risque ». Si les modèles de classe Mythos ont vocation à être diffusés à grande échelle, il faudra pour le moment faire avec Opus, dont cette version 4.7 est maintenant disponible pour tous les utilisateurs de Claude, ainsi que dans l’API.
Gare aux tokens
Claude Opus 4.7 promet une vision améliorée avec la prise en charge d’images d’une résolution maximale de 2 576 pixels de long ou 3,75 mégapixels (à comparer avec le maximum précédent qui était de 1 568 px/1,15 mpx). Le modèle devrait donc être en mesure de mieux détecter les objets et mieux comprendre les documents et captures d’écran.
Par ailleurs, les coordonnées renvoyées correspondent directement aux pixels de l’image d’origine. Plus besoin de conversion comme par le passé, les positions peuvent être immédiatement exploitées. Cela peut être utile pour, par exemple, cliquer sur un bouton dans une interface graphique ou tout simplement pointer précisément sur un élément comme un texte ou un graphique.
Autre changement : un nouveau niveau d’effort « extra high » (xhigh) qui se positionne entre les paliers « high » et « max ». Anthropic recommande de basculer Claude en xhigh pour tout ce qui est programmation et agents autonomes, et high pour tous les cas d’usage sensibles à la qualité du raisonnement.
Les calculs IA coûtent cher, aussi bien pour Anthropic que pour les utilisateurs. Avoir sous la main des options supplémentaires pour contrôler son budget est donc indispensable, d’où ce niveau xhigh. C’est d’autant plus important qu’Opus 4.7 inaugure un nouveau tokenizer qui découpe le texte différemment : un même texte peut générer jusqu’à 35 % de tokens en plus qu’avant. Utiliser ce modèle est donc susceptible de coûter plus cher ou de faire atteindre plus vite les limites de son abonnement.
Pour justifier cette inflation, Anthropic affirme que son nouveau découpage est plus efficace et qu’il permet au modèle de mieux comprendre certains contenus. Opus 4.7 réfléchit aussi davantage quand le niveau d’effort est élevé, notamment dans des contextes agentiques : la fiabilité s’améliore sur les requêtes complexes, mais le modèle dépense aussi davantage de tokens.
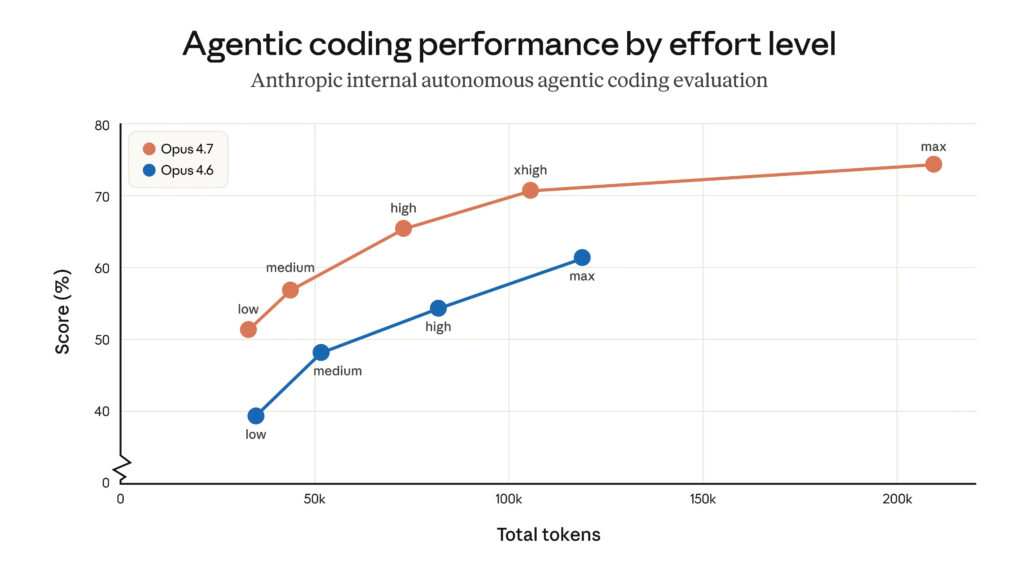
Sur une évaluation interne dédiée au code, l’utilisation des tokens s’améliore « à tous les niveaux ». En pratique, Opus 4.7 consomme souvent davantage de tokens, mais il atteint des scores nettement supérieurs. À effort équivalent, le modèle semble donc obtenir de meilleurs résultats, quitte à « dépenser » davantage.
Afin de faire passer la pilule, Claude Opus 4.7 peut garder en mémoire jusqu’à 1 million de tokens pour une seule requête sans surcoût spécifique. Le modèle est donc en capacité de traiter beaucoup plus d’informations d’un coup, sans impact financier supplémentaire.
Quel budget pour quelle tâche ?
Pour aider les utilisateurs à ne pas exploser leur plafond de dépenses, Opus 4.7 inaugure (en bêta) une fonction « budget de tâche ». Il s’agit d’une enveloppe d’un volume minimal de 20 000 tokens, que le modèle peut dépenser en temps réel : il adapte son travail pour aller au bout de la boucle agentique complète, ce qui inclut la réflexion, les appels et les résultats d’outils, ainsi que la réponse finale. Il s’en sert comme compteur décroissant pour prioriser les tâches à mesure de la consommation du budget alloué.
Attention : un budget trop restrictif poussera Opus 4.7 à traiter la tâche de manière moins approfondie. Il pourra même tout simplement refuser de s’en charger. Anthropic recommande d’expérimenter avec différents budgets en fonction de l’usage. Cette nouveauté diffère de « max_tokens », une limite fixe par requête sur les tokens générés. Les budgets sont une limite indicative sur l’ensemble de la boucle de travail.
Le pilotage du modèle avec l’API est simplifié. Exit les paramètres classiques (« temperature », « top_p »…), le contrôle se veut plus global pour réduire la complexité, mais aussi reprendre la main sur le comportement du modèle. « Utilisez les budgets pour inciter le modèle à s’auto-réguler, et la limite fixe de tokens comme plafond strict pour maîtriser la consommation », résume Anthropic. Un guide est en ligne pour épauler les utilisateurs dans la migration depuis Opus 4.6.

Commentaires (9)
Abonnez-vous pour prendre part au débat
Déjà abonné ou lecteur ? Se connecter
Cet article est en accès libre, mais il est le produit d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles d'un média expert
Profitez d'au moins 1 To de stockage pour vos sauvegardes
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 17 avril à 09h58
Le 17 avril à 10h21
Le 18 avril à 09h03
Le 17 avril à 11h13
Le 17 avril à 15h04
Le 18 avril à 00h38
Le 18 avril à 10h17
Pendant ce temps, Next, il y a déjà 6 mois
Le 18 avril à 09h01
Le 18 avril à 09h09
RTK Token Savings (Global Scope)
════════════════════════════════════════════════════════════
Total commands: 819
Input tokens: 6.6M
Output tokens: 183.4K
Tokens saved: 6.4M (97.2%)
Total exec time: 4m23s (avg 321ms)
Efficiency meter: ███████████████████████░ 97.2%
[warn] No hook installed — run
rtk init -gfor automatic token savingsBy Command
───────────────────────────────────────────────────────────────────────
# Command Count Saved Avg% Time Impact
───────────────────────────────────────────────────────────────────────
1. rtk git diff 87 6.4M 30.5% 36ms ██████████
2. rtk git status 137 10.2K 65.0% 31ms ░░░░░░░░░░
3. rtk git commit 88 3.8K 97.1% 43ms ░░░░░░░░░░
4. rtk git log -5 31 3.0K 20.3% 14ms ░░░░░░░░░░
5. rtk git push 106 2.6K 90.7% 1.4s ░░░░░░░░░░
6. rtk git add .gitignor... 2 974 97.5% 83ms ░░░░░░░░░░
7. rtk git diff src/serv... 1 874 21.8% 27ms ░░░░░░░░░░
8. rtk git log -3 10 845 24.8% 15ms ░░░░░░░░░░
9. rtk git add .env.exam... 1 764 98.7% 83ms ░░░░░░░░░░
───────────────────────────────────────────────────────────────────────
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?