

DeepSeek : la recherche chinoise paradoxalement boostée par les restrictions américaines
Toujours plus profond

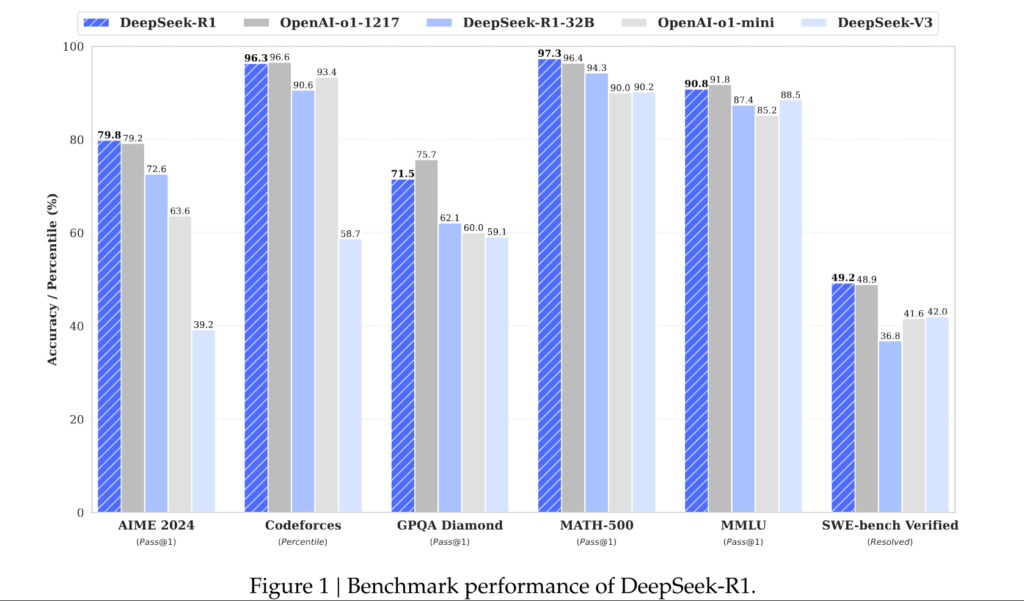
La startup chinoise a sorti son modèle DeepSeek-R1 rivalisant avec o1 d’OpenAI. Si certains doutent des affirmations des chercheurs de l’entreprise, leur rapport technique apporte des indications précises sur les nouveautés pour rendre leur modèle plus efficace.
Ne nous précipitons pas pour dire que la startup chinoise Deepseek a révolutionné le champ des IA génératives jusqu’à penser que l’Intelligence artificielle générale est proche, comme ses chercheurs le suggèrent dans leur rapport technique, reprenant les discours des startups américaines comme OpenAI à leur compte.
Mais ne renvoyons pas non plus d’un revers de la main les prétentions de cette jeune entreprise chinoise, qui vient de faire trembler la bourse américaine et fait craindre aux investisseurs l’éclatement de la bulle spéculative dont bénéficient ses concurrents états-uniens. Comme le modèle o1 d’OpenAI, le modèle DeepSeek-R1 se base sur de l’apprentissage par renforcement à grande échelle.
DeepSeek n’est pas une startup sortie de nulle part, comme le rappellent certains : son laboratoire rassemble plus de 100 chercheurs et elle a mis en ligne 16 articles de recherche en lien avec l’IA générative.
Un rapport technique détaillant l’architecture du modèle
Si certains, comme le CEO de l’entreprise américaine Scale AI, Alexandr Wang, estiment que l’entreprise chinoise ment sur l’efficacité de son modèle, le rapport technique mis en ligne [PDF] donne des indications montrant qu’elle a, de fait, innové dans le domaine.
Celui-ci n’est pas une publication scientifique, et il n’est pas non plus mis en ligne sur une plateforme de prépublication comme arXiv, mais il se révèle beaucoup plus détaillé que ceux de ses concurrents américains comme OpenAI. En parallèle, l’entreprise revendique de publier ainsi le modèle en « open source » le plus puissant du moment, rivalisant dans les benchmarks avec o1 d’OpenAI tout en étant beaucoup moins énergivore.
Un modèle pas si ouvert et une accusation de vol de propriété intellectuelle d’OpenAI
Mais comme le remarque Timnit Gebru, DeepSeek-R1 est loin d’être open source. L’entreprise chinoise a bien décrit l’architecture de son modèle dans son rapport et publié les poids qui en sont issus. Le modèle peut également être utilisé en local après avoir été téléchargé sur Hugging Face. Mais elle n’a publié ni le code, ni les données sur lesquelles elle l’a entrainé et évalué. Des chercheurs de la startup Hugging Face se sont d’ailleurs lancés dans une démarche de reproduction de DeepSeek-R1 pour obtenir un modèle du même type « pleinement ouvert ». Notons que ce projet, nommé Open-R1, n’est pour l’instant que dans sa phase de lancement.
De son côté, le chercheur et co-fondateur de la startup Pleias, Pierre-Carl Langlais, souligne à Next qu’ « une de leur force a quand même été de s’engager dans la science ouverte malgré tout : ils ont publié des papiers détaillés, les poids du modèle. Ça a été une très grosse erreur des entreprises américaines de snober l’open source et ça va leur couter très cher ». Pour lui, DeepSeek-R1 « est quand même le premier modèle de reasoning réellement ouvert et performant ».
Par ailleurs, selon le Financial Times, OpenAI accuse son concurrent chinois d’avoir utilisé un de ses modèles pour entrainer DeepSeek-R1, en employant la distillation. Cette technique permet de « surpasser les grands modèles de langage avec moins de données d’entraînement et des tailles de modèles plus petites » en entrainant un modèle avec les réponses d’un modèle plus grand, comme l’expliquait des chercheurs de Google en 2023 dans la version « pas à pas » de la méthode qu’ils ont créée.
David Sacks, nouveau tsar de l’IA et de la crypto de la Maison Blanche, soulève la possibilité d’un vol présumé de la propriété intellectuelle d’OpenAI. Rappelons qu’OpenAI a aussi été accusé à plusieurs reprises de violation du copyright (ici et là par exemple) pour entrainer ses modèles.
DeepSeek-V3, un modèle de fondation solide sur lequel s’appuyer
Les chercheurs de DeepSeek, eux, amènent dans leur rapport d’autres explications. D’abord, DeepSeek-R1 s’appuie sur un premier modèle de langage DeepSeek-V3 développé par la même startup chinoise, comme leurs noms l’indiquent. DeepSeek-V3 est un modèle de fondation « solide » comme le confirment les chercheurs de Hugging Face impliqués dans le projet Open-R1 : ce modèle de 671 milliards de paramètres utilisant la technique de Mixture of Experts (MoE) est « aussi performant que des poids lourds tels que Sonnet 3.5 et GPT-4o », expliquent-ils.
« La force de ce modèle de base est dans le pré-traitement des données en PDF, ils ont vraiment bossé ça à fond et ça se ressent lorsqu’on interagit avec lui. Il y a vraiment une compréhension nette de la structuration des textes qu’il n’y a pas ailleurs », estime Pierre-Carl Langlais.
Les chercheurs de Hugging Face insistent sur autre chose : « ce qui est particulièrement impressionnant, c’est la rentabilité de son entraînement – seulement 5,5 millions de dollars », expliquent-ils. Pour cela, ils ont modifié la confection des modèles de fondation en utilisant « la prédiction multi-token (MTP), Multi-Head Latent Attention (MLA) et BEAUCOUP (sérieusement, beaucoup) d’optimisation matérielle »,
DeepSeek avait déjà introduit la MLA dans la version v2 de son modèle en juin 2024. Pour le MTP, « l’idée de base, c’est qu’un modèle GPT génère un token à la fois, avec cette technique DeepSeek arrive à générer plusieurs tokens à la suite, c’est aussi une des raisons pour lesquelles ils sont plus rapides », explique Pierre-Carl Langlais.
Une innovation due aux restrictions américaines
Mais, leur recherche sur l’optimisation matérielle qui permet l’efficacité de leur modèle doit sans doute beaucoup au fait qu’ils aient notamment dû faire face à un manque de puces H100 de NVIDIA à cause du blocus américain. Mais impossible de savoir ce qu’il en est exactement, d’autant que la Chine est très discrète sur le sujet. Elle ne participe par exemple plus au classement Top500 mis à jour deux fois par an.
Ils se sont donc posé la question de comment faire sans et ont élaboré une architecture capable d’entrainer le modèle sur des puces NVIDIA H800. « C’est comme des puces H100 mais seulement, elles sont bridées, notamment dans la connexion entre les GPU », nous détaille Pierre-Carl Langlais. « Concrètement, lorsqu’on fait des entrainements de modèles à grande échelle, on connecte beaucoup de GPU », ajoute-t-il, « en utilisant Jean Zay pour entrainer notre modèle à Pleias, nous avons connecté 192 GPU. Et il y a un gros enjeu d’ingénierie sur ce sujet ».
En utilisant des H800, il est donc beaucoup plus difficile d’échanger des données d’un GPU à l’autre. « Du coup, DeepSeek a travaillé sur l’échange de données entre les GPU en allant à très bas niveau et ont réussi à optimiser considérablement l’inférence, c’est-à-dire, le temps mis pour générer les tokens ».
Raisonnement sur la meilleure réponse générée
Ensuite, comme o1, DeepSeek-R1 utilise l’apprentissage par renforcement (reinforcement learning, en anglais) pour améliorer ses réponses et y ajoute une couche de raisonnement (reasoning, en anglais). « Avec le reinforcement learning, le modèle va générer deux réponses et on va prendre la meilleure. Avec le reinforcement learning with reasoning, on demande au modèle de justifier pourquoi il arrive à tel résultat et de changer la justification jusqu’à ce qu’il tombe sur un bon résultat », simplifie Pierre Carl Langlais, « c’est extrêmement pratique pour tout ce qui est mathématique ».
« Ce qui est assez révolutionnaire, c’est qu’ils ont demandé ensuite au modèle de s’évaluer lui-même. Le modèle génère plein d’essais, un peu comme un étudiant qui pratique. Après, il évalue ce qu’il a fait et dit si c’est bon ou pas et une boucle d’amélioration est créée, un peu comme ce qu’avait fait DeepMind avec AlphaGo en l’entrainant contre lui-même », nous explique le chercheur, qui suppose qu’OpenAI a fait la même chose pour o1, sans qu’on puisse le savoir puisque l’entreprise américaine n’a pas publié sa recherche.
« On se rend compte que cette méthode est généraliste et on peut se servir du modèle aussi bien pour des maths que pour de l’écriture créative ou de la traduction », conclut Pierre Carl Langlais.
En fait, l’entreprise chinoise a sorti deux versions de son modèle se basant sur l’apprentissage par renforcement : DeepSeek-R1-Zero et DeepSeek-R1.
DeepSeek-R1-Zero, qui s’adresse plus au milieu de la recherche, ne s’appuie pas du tout sur du réglage fin supervisé (supervised fine-tuning, SFT) mais seulement sur ce nouveau système. « C’est un modèle qui fonctionne mais qui est assez bizarre car les chaines de raisonnement sont un peu contre-intuitives », commente Pierre-Carl Langlais, « ce qui rappelle encore AlphaGo. D’un point de vue recherche, c’est peut être ce qui est plus prometteur ». DeepSeek-R1 est plus hybride et utilise plusieurs phases de reinforcement learning et de SFT.
Le chercheur insiste sur le fait que les laboratoires chinois comme DeepSeek ou Alibaba itèrent assez vite et « sortent un ou deux papiers par mois et des modèles tout le temps. Ils ont aussi la meilleure organisation pour entrainer des modèles avec vraiment un laboratoire financé par un hedge fund sans avoir de levée de fonds à faire et des projets commerciaux à sortir ».
Rappelons quand même que DeepSeek est une entreprise chinoise, ce qui a des répercussions sur la génération de ses modèles puisqu’on peut constater une censure concernant les sujets de Taïwan, de la répression de la place de Tian’Anmen en 1989 ou Xi Jinping.

Commentaires (22)
Le 29/01/2025 à 16h21
Le 30/01/2025 à 07h07
"Quand nous utilisons la propriété intellectuelle des artistes et auteurs sans autorisation pour entraîner nos modèles, c'est du Fair Use.
Quand DeepSeek utilise notre propriété intellectuelle sans autorisation pour entraîner ses modèles, c'est du vol! Inacceptable et illégal !"
Le 29/01/2025 à 16h58
Pas de problème on va faire plus de trous pour trouver du petrole plutôt que de réfléchir à consommer moins sans perdre en qualité.
Les américains voient l'arrivée de Trump et des milliardaires de la tech comme une bénédiction pour leur économie. En fait c'est une fuite en avant d'un système en fin de vie qui finira par se crasher en plein vol.
Anticiper les pénuries à venir, en optimisant au maximum les besoins énergétiques voire en modifiant les process, ce n'est pas une perte de temps ni d'argent, mais une vision d'avenir.
Le 29/01/2025 à 17h41
Le 29/01/2025 à 20h19
Le 30/01/2025 à 06h50
On remarquera qu'à chaque fois que l’État manque de fond pour faire quelque chose, le premier et seul réflexe est toujours de chercher quelque chose de plus à taxer. Il n'y a jamais personne pour essayer de chercher comment faire aussi bien pour moins cher.
Le 30/01/2025 à 08h48
La baisse des recettes fiscales de l'état n'a jamais été aussi haut.
La preuve ? Le CAC40 a fait les meilleurs résultats de dividendes, l'hôpital public n'a plus de moyens pour soigner la population, et l'éducation nationale n'a plus les moyens de mettre des profs en face des élèves dans des conditions matérielles correctes.
Les taxes d'un état doivent servir de moyens de réallouer, répartir les richesses crées à tout le pays, suivant les besoins.
Sinon on finira comme en Californie avec des régies publiques de l'eau qui ont été privatisés et dont l'eau s'est raréfiée pour les habitants (et pour les feux). Ou encore pour les pompiers privés qui sont intervenus chez ceux qui en avaient les moyens.
Et encore les assurances habitations , et les assurances maladie qui décident qui doit vivre ou mourir suivant les moyens.
Le 30/01/2025 à 09h25
Le 04/02/2025 à 15h47
Aucun rapport avec le fait qu'on dépense 380 milliards/an pour les retraites (en 2023), plus de 200 pour la santé, et moins de 90 pour l'éducation et la recherche (éduc nat 63 milliards, ESR 26.6) ? Je ne sais pas si tu te rends compte qu'on est passé de 337 milliards pour les retraites en 2021 à 380 en 2023 (+43 milliards juste l'augmentation, soit 1.5x le budget total de l'ESR).
Le problème est multi facteurs et tient avant tout à un principe directeur qui est celui de prendre des décisions qui vont toujours à contresens de ce qu'il faudrait faire.
Le 05/02/2025 à 22h48
Ça ne devrait pas être dans le budget de l'état, à la base, se sont des cotisations salariales et patronales, mis en commun et réparties entre les cotisant, et les cotisés, point.
Sauf que l'état à voulu faire des cadeaux aux entreprises, en faisant des exonérations de cotisations.
Sauf qu'il fallait compenser, ils n'allaient pas couper comme ça les retraites.
Et pour compenser, l'état a utilisé quoi? Les revenus de la TVA.
Ensuite tu parles de hausse de l'enveloppe des retraites entre 2 périodes.
Au delà du fait qu'il y a plein de facteurs pour l'expliquer (prise en compte de l'inflation, hausse du nombre de personnes qui sont parti en retraite, hausse du nombre de personnes en retraite avec un très bon salaire, etc, etc)
Bref argument où il n'y a rien a dire...
Pour ce qui est de l'éducation, la recherche et la santé, j'en suis le premier consterné, de ce manque de considération tout court et budgetaire.
On ne mérite que le déclin ou la révolution.
Le 06/02/2025 à 09h27
Est-ce une raison pour détruire l'avenir du pays et de ses jeunes ? Les paramètres ayant changé, il serait peut être utile d'adapter le dispositif. L'inflation a bon dos, comme si les salaires des actifs avaient augmenté en même temps que l'inflation (rien que ce fait dément ce que tu prétends sur le non problème -> les salaires ne suivant pas l'inflation, alors que les pensions si, il y a un problème de financement).
Le 06/02/2025 à 14h16
La mutualisation n'en fait pas un impôt qui pourrait être realloué différemment comme le sont les impôts sur le revenu et la TVA.
Vraiment 😭
Si on part sur ton idée, alors on est d'accord que l'on devrait recevoir en paye le montant super brut? Et que sur ce montant, on devra épargner (ou pas) une partie pour la retraite et la maladie.
Et donc, dans ce cas là, tu m'expliqueras comment le Gvt fera ses exonérations de cotisations ?
Et bien il le transformera en taxes sur ce salaire. Et là, tu les sentiras passer les cadeaux aux entreprises.
Le 06/02/2025 à 16h27
Pas en épargne pour la maladie, tu peux tomber malade n'importe quand. Au passage, ce que tu décris, c'est proche du système aux USA ou en Suisse (en Suisse, c'est obligatoire, mais tu as le choix du prestataire; et ce n'est pas mutualisé, chacun paye pour soi).
Comme il n'y aura pas de cotisation, pourquoi voudrais tu que le gouvernement en exonère les entreprises et les salariés ?
Ne te méprends pas sur ce que je dis : je suis favorable à ce que la retraite et la santé soient mutualisées. Le problème, c'est la façon dont on applique cette mutualisation, et les conséquences que ça a sur l'avenir. Les primes santé à 1000 balles/mois comme en Suisse, merci mais non merci.
Le 06/02/2025 à 16h51
Parce que qu'elles voudront toujours payer moins cher leur main d'oeuvre, tiens.
Donc soit avec l'aide du Gvt en argent public (subvention aux entreprises, ça existe déjà) alimenté par des impôts plus élevés vu qu'on toucherai tous un super brut.
Et non mes 2 points sont différents. Dans l'un c'est géré qu'entre patron et salariés (comme voulu à l'origine en 1945). Dans le 2e, on est tous à la mercie du Gvt et de son parti pris politique...
Le 06/02/2025 à 17h00
Non, tes deux fonctionnements sont les mêmes : un salaire différé, c'est de la capitalisation. La répartition, ce n'est absolument pas ça. Et c'est ça que les Français refusent d'ailleurs souvent de comprendre.
Le 07/02/2025 à 09h00
J'ai sûrement loupé ton point, comme tu ne comprends pas le mien.
Merci du débat.
Le 07/02/2025 à 09h59
Le 07/02/2025 à 11h17
Alors je suis passé sur le smartphone, quand je bosse, je ne le regarde pas du tout. Plus de tentation. 😅
Le 09/02/2025 à 09h44
Je ne réponds sur PC que quand la complexité de la réponse l’exige, ou que j’y suis déjà.
L’avantage (diabolique) du smartphone c’est que tu peux réagir au fil de la journée.
Le 09/02/2025 à 11h49
Le 09/02/2025 à 17h16
Oui pour des sujets légers.
Mais là, le ping pong dans la durée, ça n'est pas tenable.
Pour moi en tout cas.
Le 30/01/2025 à 09h27
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?