

Raisonnement des IA génératives : les benchmarks nous désinforment
Pseudo-thermomètres

Des études récentes montrent que les grands modèles de langage ont de bons résultats dans les tests de comparaison car ceux-ci correspondent aux données sur lesquelles ils ont été entrainés. Il suffit d’une petite variation dans le test pour que les performances s’effondrent.
Depuis l’arrivée des grands modèles de langage (large language models, LLM), le débat sur leur capacité de raisonnement oppose les ingénieurs et chercheurs du domaine.
Certains prétendent que ces modèles permettent de créer des intelligences artificielles qui raisonnent, d’autres que ce sont de simples perroquets récitant statistiquement ce qui se trouve dans leurs données d’entrainement.
Les premiers s’appuient sur des tests de raisonnement (benchmarks) pour comparer leurs résultats à ceux de leurs concurrents et de leurs anciennes versions. De mois en mois, ils observent les scores augmenter petit à petit et certains se disent qu’un jour ou l’autre, grâce aux modèles de langage, la machine dépassera les capacités humaines.
Les autres s’appuient notamment sur le principe sur lequel ont été fondés les LLM pour expliquer qu’ils n’utilisent que des modèles de raisonnement qu’ils ont mémorisés à partir de leurs données d’entrainement. Bref, comme le disaient déjà en 2020 Emily Bender, Timnit Gebru, Angelina McMillan-Major et Margaret Mitchell, les LLM ne seraient que des « perroquets stochastiques ».
Problème de fiabilité des mesures
Plusieurs études récentes montrent que les « benchmarks » ne permettent pas de mesurer les capacités de raisonnement de ces modèles, mais plutôt leurs capacités à … répondre de façon fidèle à ces tests. Car les résultats s’effondrent quand les chercheurs leur font passer des tests similaires, mais présentant d’infimes variations.
Prenons, par exemple, l’étude mise en ligne [PDF] sur la plateforme de prepint arXiv par Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio et Mehrdad Farajtabar, chercheurs chez Apple. Ils ont voulu vérifier les performances des différents modèles sur des tâches de raisonnement en mathématiques.
Pour eux, « bien que les performances des LLM sur le GSM8K [l’un des benchmarks d’évaluation de raisonnement mathématique les plus utilisés] se soient considérablement améliorées ces dernières années, il n’est pas certain que leurs capacités de raisonnement mathématique aient réellement progressé, ce qui soulève des questions quant à la fiabilité des mesures rapportées ».
GSM8K a été créé par des chercheurs d’OpenAI en 2021. Comme l’explique Mehrdad Farajtabar, l’un des chercheurs d’Apple et co-auteur de l’article, « lorsque OpenAI a publié GSM8K il y a environ 3 ans, GPT-3 (175B) a obtenu un score de 35 % au test GSM8K. Aujourd’hui, les modèles avec ~3B paramètres dépassent les 85 %, et les plus grands atteignent plus de 95 % ». Mais le doute subsiste sur l’évolution de leurs capacités : « le « raisonnement » du modèle s’est-il vraiment amélioré ? », demande-t-il.
Une version plus dynamique
Ils ont donc créé un autre benchmark, appelé GSM-Symbolic. Celui-ci est similaire à GSM8K, mais ils l’ont rendu plus dynamique. Avec GSM8K, les questions ressemblent à ce que l’on peut voir à gauche de l’image ci-dessous. Les chercheurs d’Apple ont « juste » fait un programme très simple qui change quelques noms de variables dans le texte ainsi que leurs valeurs de façon aléatoire (pseudo-aléatoire, certes, mais ne chipotons pas).

C’est un peu comme quand, à l’école, un enseignant donne des exercices à ses élèves. Pour l’évaluation, il n’utilise pas les mêmes variables. Il ne pourrait pas savoir sinon, en regardant leur copie, s’ils ont compris le raisonnement ou s’ils recopient les mêmes données sans réfléchir. Normalement, si les LLM testés fonctionnent réellement en appliquant un raisonnement, ces quelques changements ne devraient rien changer à leur résultat.
Des performances bien moins bonnes
Conséquence : les résultats ne sont pas bons. D’une part, ils varient assez fortement, comme on peut le voir ci-dessous. En faisant passer une batterie de 50 générations de tests de GSM-Symbolic, les LLM ne sont pas constants, loin de là. Et, pour la plupart, leurs performances moyennes sont en dessous de celles constatées par le benchmark GSM8K (marquée par la ligne pointillée).
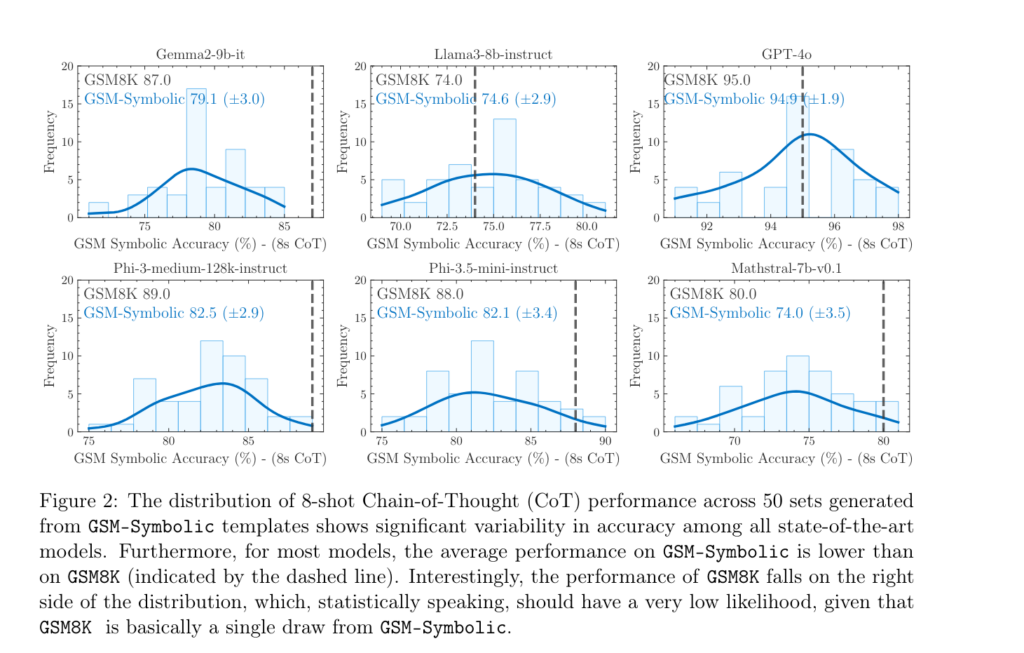
Tous les LLM testés par les chercheurs d’Apple sont touchés, même si certains se débrouillent clairement mieux que d’autres :
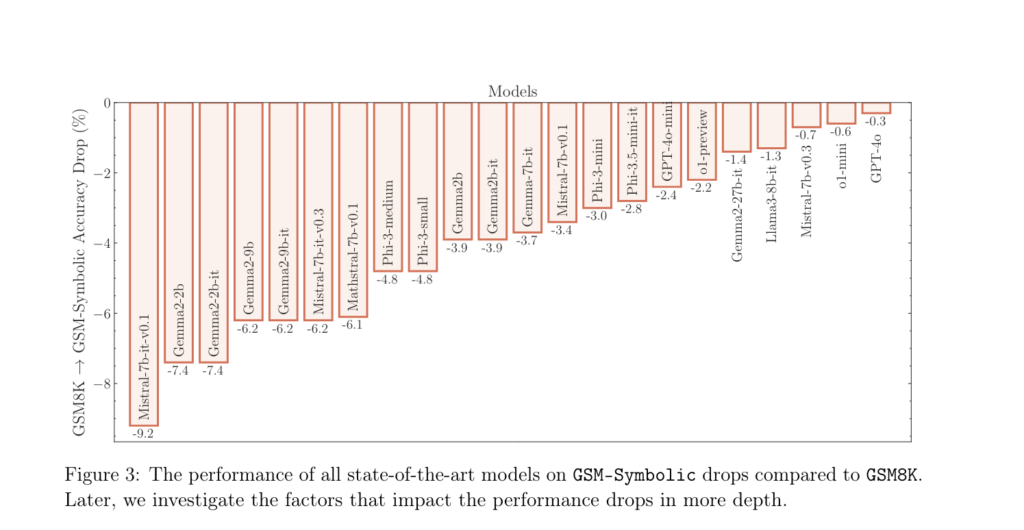
En séparant les deux types de changements qu’ils ont faits (modifications des noms et des valeurs), ils ont pu constater que l’un comme l’autre affectaient les performances. Mais celles-ci baissent le plus fortement quand les valeurs changent dans les énoncés, la combinaison des modifications perturbant encore plus les résultats :
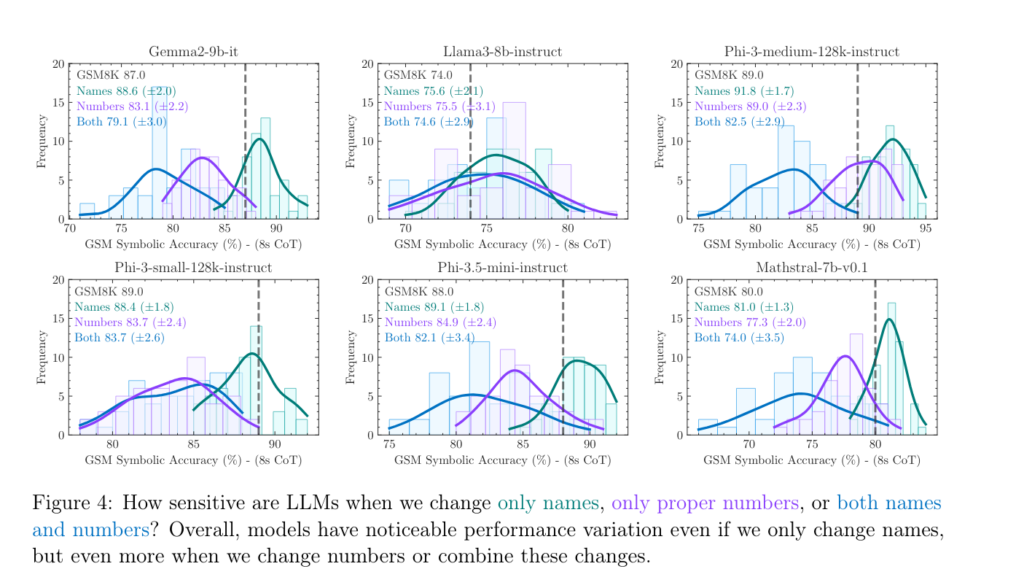
Les chercheurs d’Apple ont créé d’autres variantes de leur benchmark en supprimant ou ajoutant des conditions dans l’énoncé à résoudre.

Et ils constatent que plus l’énoncé est complexe, plus les performances diminuent et la variance augmente.
On peut voir, dans l’exemple suivant, que le simple ajout d’une précision inutile au calcul perturbe complètement la réponse des modèles o1-mini et Llama3-8B :

Les chercheurs expliquent que la majorité des modèles ne tiennent pas compte du sens des ajouts et « les convertissent aveuglément en opérations, ce qui entraîne des erreurs ».
Et là, « les performances des modèles baissent de manière significative […], les modèles les plus récents connaissant une baisse plus importante que les plus anciens » :
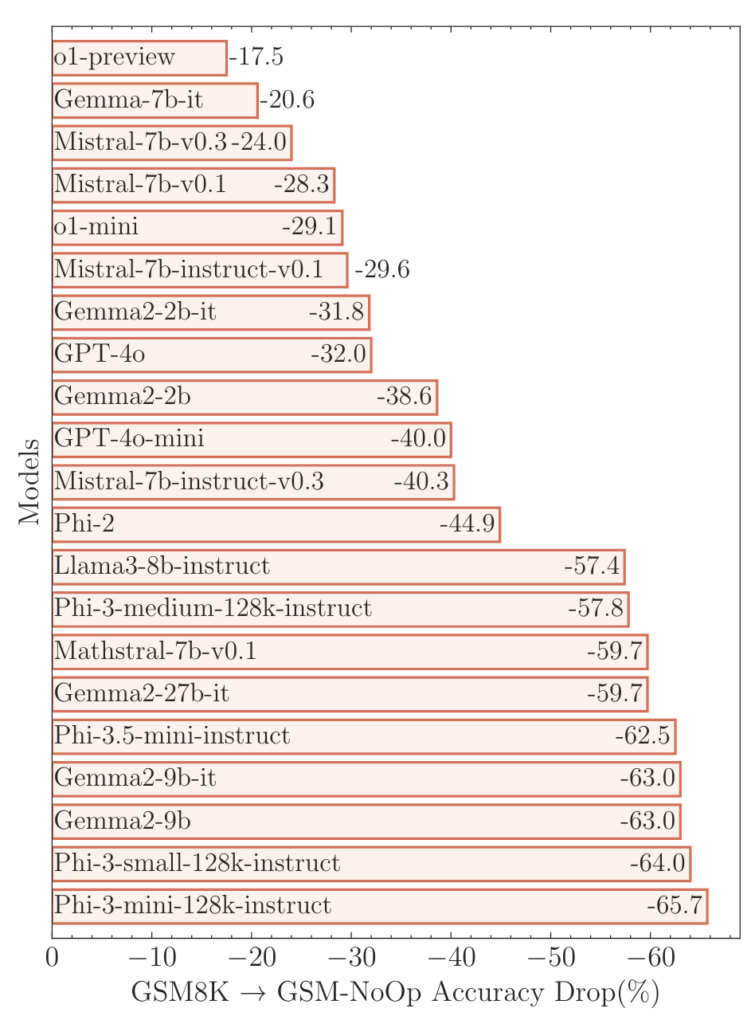
Pour les chercheurs d’Apple, ces tests de mathématiques assez élémentaires démontrent que les modèles de langage ne raisonnent pas, contrairement à ce que revendiquent souvent les entreprises d’IA générative comme OpenAI. Ils appliqueraient des « correspondances de motifs probabilistes » (probabilistic pattern-matching, en anglais). En gros, leurs résultats reprendraient le motif d’exercices de maths qui se trouvent dans leurs données d’entrainement, sans appliquer aucun raisonnement.
Cet article n’est pas le seul à pointer le problème. Les chercheurs de l’Université de Princeton R. Thomas McCoy, Shuny Yao (qui travaille chez OpenAI), Dan Friedman et Thomas L. Griffiths, ont ainsi publié début octobre un article qui montre « comment les grands modèles de langage sont façonnés par le problème qu’ils sont entrainés à résoudre ».
Plus de difficultés avec les tâches peu fréquentes
Ces chercheurs montrent que, quand on les teste sur des tâches de raisonnements logiques simples, les nouveaux LLM répondent de manière incorrecte et ne sont pas meilleurs que les premiers modèles présentés publiquement.
Ils les ont testés en leur demandant de compter des lettres, d’inverser un article avec un mot dans une phrase, d’utiliser un très simple algorithme de chiffrement (celui du chiffrement par décalage), ou de faire une opération mathématique très simple.

Dans leur conclusion, ils soulignent que, même si des recherches montrent que les modèles de langage peuvent être utilisés dans de nombreux domaines, « nous devons également nous rappeler un fait plus simple : les modèles de langage sont… des modèles de langage ! En d’autres termes, il s’agit de systèmes statistiques de prédiction du mot suivant ».
Ils tirent de leurs résultats que « les modèles de langage ont plus de difficultés avec les tâches peu fréquentes qu’avec les tâches fréquentes, même lorsqu’on compare deux tâches qui semblent aussi complexes pour un humain ». Ils ajoutent que ces modèles « ont plus de difficultés avec les exemples dont les réponses sont peu probables qu’avec ceux dont les réponses sont très probables, même lorsque la tâche est déterministe ».

Commentaires (33)
Le 25/10/2024 à 11h01
Si possible, je vote pour qu'il soit ouvert à tout le monde, pas seulement aux abonnés
Le 25/10/2024 à 11h59
D'ailleurs merci beaucoup pour cela à l'équipe de Next
Le 25/10/2024 à 12h02
Modifié le 25/10/2024 à 15h03
Le 26/10/2024 à 10h26
Le 27/10/2024 à 09h05
Le 27/10/2024 à 10h52
Le 27/10/2024 à 13h25
Le 27/10/2024 à 14h07
Qui va s’occuper de détecter les cancers pendant ce temps là ?
Un peu de cohérence Freddo, merde.
Le 27/10/2024 à 21h29
L'IA sert à détecter des cancers.
Les promoteurs de l'IA qui utilisent les mêmes méthodes que les industriels du tabac.
Le tabac qui donne le cancer.
Mais bien sûr ! l'IA a été créé par les industriels du tabac pour permettre de dépister les futurs cancers et ainsi vendre du service autour ! #noussachons
Le 27/10/2024 à 21h49
Le 28/10/2024 à 07h40
« Qui va modérer le modérateur ❓ »
Nous attendons vos réponses écrites exclusivement en emojis pour le cours de la semaine prochaine.
Le 28/10/2024 à 08h33
Le 28/10/2024 à 08h48
Pertinent mais impertinent.
Un peu court.
Le 28/10/2024 à 09h05
Le 28/10/2024 à 09h11
Le 28/10/2024 à 11h39
Le 28/10/2024 à 12h43
Le 25/10/2024 à 11h12
Le 25/10/2024 à 11h39
Le 25/10/2024 à 12h22
Vivement que cette bulle se dégonfle...
Le retour sur terre est en train d'arriver avec notamment plusieurs études qui indiquent une possible baisse de productivité et une augmentation du stress quand on implémente l'IA générative en entreprise.
Le 25/10/2024 à 12h38
Le 25/10/2024 à 12h46
Modifié le 25/10/2024 à 13h03
Un résumé du papier sous forme d'article de blog : https://livebench.ai/#/blog
(traduis de l'anglais)
"Présentation de LiveBench : un benchmark pour les LLM (modèles de langage) conçu en tenant compte de la contamination du jeu de test et de l’évaluation objective. Ses caractéristiques sont les suivantes :
LiveBench est conçu pour limiter les risques de contamination potentielle en publiant de nouvelles questions chaque mois, basées sur des ensembles de données récemment publiés, des articles arXiv, des actualités et des résumés de films sur IMDb.
Chaque question dispose de réponses vérifiables et objectives, permettant l’évaluation précise et automatique de questions difficiles, sans recours à un juge IA.
LiveBench comprend actuellement un ensemble de 18 tâches variées réparties dans 6 catégories, et de nouvelles tâches, de difficulté croissante, seront ajoutées au fil du temps.
Modifié le 25/10/2024 à 13h49
Modifié le 25/10/2024 à 13h51
Le 25/10/2024 à 17h36
Modifié le 13 juin à 14h27
snaptube vidmate
Le 25/10/2024 à 18h53
Je ne suis toujours demandé pourquoi on pensait que ça pouvait raisonner ou même donner une réponse fiable.
Le 26/10/2024 à 17h48
En fait, la partie "raisonnement" d'un LLM, c'est dans son analyse sémantique pour justement prédire la bonne suite de tokens avec le mécanisme d'attention qui lui permet d'accorder plus ou moins de valeur aux mots de la phrase.
En dehors de ça, le boulot de GPT reste de poursuivre l'écriture d'un texte en se tenant au contexte. Ses paramètres peuvent influencer sa capacité à "imaginer" (en gros sa part d'aléatoire) et on peut le rendre déterministe si on veut, ou complètement loufoque.
La puissance d'un LLM réside surtout dans sa capacité à traiter, synthétiser et extraire des informations d'un grand corpus de texte. Se contenter de ses données d'entraînement, c'est comme se contenter de nos connaissances jusqu'au Bac et considérer qu'on a rien appris depuis.
Modifié le 25/10/2024 à 20h57
The size of the kiwis on Sunday doesn’t affect the total count, so we can calculate it as follows:
Friday: Oliver picks 44 kiwis.
Saturday: He picks 58 kiwis.
Sunday: He picks double the number he did on Friday, which is 44×2=88 kiwis.
Adding them up:
44+58+88=190
Therefore, Oliver has 190 kiwis in total. The five smaller kiwis are part of the 190
Le 26/10/2024 à 00h31
Bref, le acteurs au cœur du développement de l'IA sont des têtes, des brutes en math pour la plupart j'imagine. Ils le savent très bien.
Que les commerciaux et autres marketeux s'en moquent, je veux bien, mais les développeurs eux sont complices d'une supercherie. Je trouve ça scandaleux.
Sans oublier d'ailleurs que si les tests sont statiques et disponibles à l'avance, l'entraînement d'un modèle pour réussir les tests semblent très simple. Il suffit de fournir toutes les questions avec les réponses. On se demande pourquoi les modèles n'approchent pas tous 100% de réussite. J'ai du louper un truc...
Le 26/10/2024 à 11h35
Je préfère l'expérience pour le coup et évaluer par moi-même les capacités de l'outil. Le reste, c'est de la planche commerciale comme en voit dans à peu près tous les logiciels du marché.
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?