[MàJ] Midjourney recrache des images Pixar et d’œuvres protégées, parfois sans qu’on le lui demande
Une série d'artistes français et européens inclus
![[MàJ] Midjourney recrache des images Pixar et d’œuvres protégées, parfois sans qu’on le lui demande](https://next.ink/wp-content/uploads/2024/01/Ia-copyright2.webp "[MàJ] Midjourney recrache des images Pixar et d’œuvres protégées, parfois sans qu’on le lui demande")
En s'appuyant sur les travaux de Reid Southen et Gary Marcus, Next montre que la dernière version de Midjourney produit des images de films, des logos ou des reproductions d'œuvres soumises aux droits d'auteur.
L’histoire peut être racontée de plusieurs manières.
Une version très courte serait de dire : ce matin, chez Next, nous avons demandé au moteur d'intelligence artificielle générative Midjourney de générer une image de « jouets animés » et la machine nous a proposé, toute seule, Wall-E d'une part, Woody et Buzz l’Éclair de Toy Story d'autre part, trois personnages dont les droits appartiennent aux studios Pixar et à Disney, sans que ceux-ci soient cités.

Génération d'une image de "jouet animé" sur Midjourney, par Next.

Génération d'une image de "jouet animé" sur Midjourney, par Next.
Elle nous a aussi très bien réussi cette image de canette siglée.

Image d'une canette siglée de la marque Coca-Cola générée sur Midjourney par Next.
Et maintenant la version longue…
Du point de vue d'une certaine bulle Internet artistique et francophone, on peut la faire commencer dans la nuit du 1er au 2 janvier. Sur Bluesky, l’auteur américain Phil Foglio envoie un message à diverses communautés artistiques : celles des auteurs de webcomics, celle des auteurs de science-fiction, directement à l'éditeur Wizards, qui édite le jeu Magic: the gathering.
Chaque fois, il écrit la même chose : « Les enfants ! Voici un jeu marrant ! On vient de publier une liste de tous les artistes que Midjourney admet avoir récupérés pour former son moteur d'I.A.. Est-ce que vous êtes sur la liste ? (Nous, oui). Est-ce que vous avez un bon avocat ? (Nous, oui). »
La liste en question ? Un PDF intitulé « Exhibit J (Midjourney Name list) », en réalité disponible depuis plusieurs semaines : il fait partie des éléments versés au dossier de la plainte qui oppose l’artiste américaine Sarah Andersen et plusieurs de ses collègues aux éditeurs de modèles d’intelligence artificielle Stable Diffusion (Stability AI) et Midjourney (Midjourney). Et contient les noms de quelque 4 700 artistes dont Midjourney affirme pouvoir reproduire ou chercher, à terme, à permettre de reproduire le style.
Constituée par les propres équipes de Midjourney, la liste a d’abord été partagée sous la forme d’un document Google, dont l’accès est longtemps resté public. Sur X (anciennement Twitter), des internautes partagent des captures de la conversation qui a mené au partage, par le CEO de Midjourney David Holz, du Google Sheets en question.
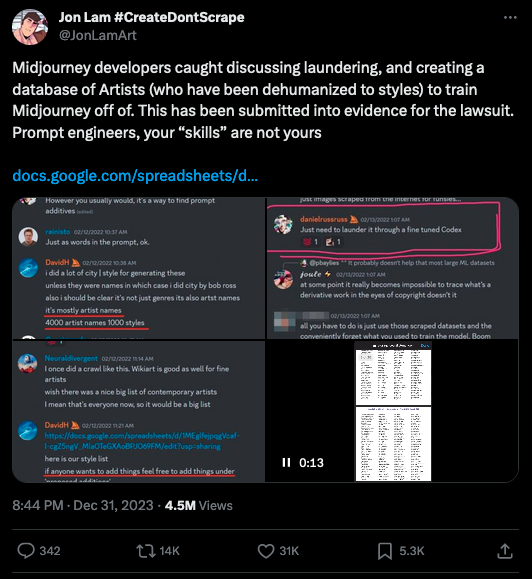
Si l’accès au document d’origine est désormais fermé, celui-ci a été enregistré sur Internet Archive. Et sous la forme d’un PDF, donc, constitué lorsque le collectif d’artistes qui a porté plainte contre Stability AI et Midjourney s’est agrandi et a complété sa plainte, en octobre dernier.
Des street artists et des dessinateurs francophones parmi les inspirations de Midjourney
En fouillant dans ce document, les internautes ont repéré plusieurs noms d’artistes francophones, dont celui du dessinateur Boulet, prévenu tant de fois qu’il en a été réduit à demander aux gens de cesser de l’alerter… tout en précisant qu’il considérait les constructeurs de modèles d'IA générative comme des « parasites sans âmes ».
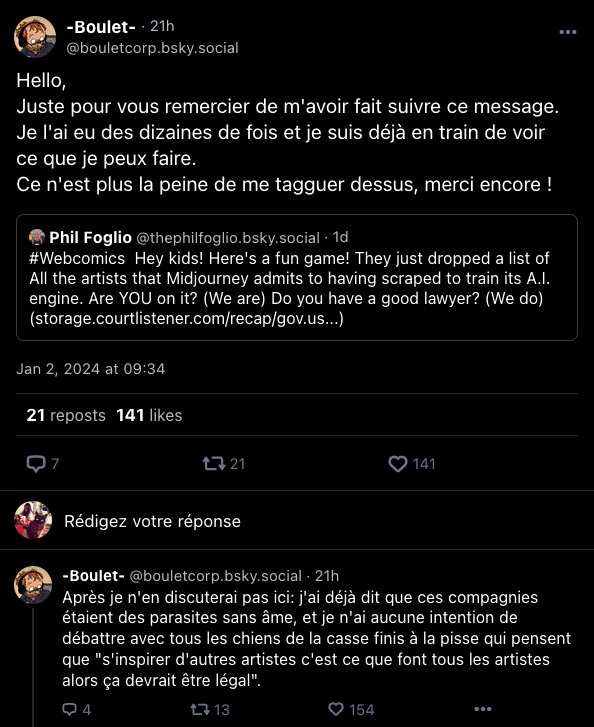
Next l’a contacté, ainsi que plusieurs autres artistes francophones présents dans la liste. Deux street artists ont répondu à l’heure de publier ces lignes : ni C215, ni Jef Aerosol n’avaient conscience d’être cités parmi les inspirations de Midjourney avant que nous ne les alertions.
Le directeur éditorial de Dargaud François le Bescond n'a pu que constater le grand flou juridique qui existe pour le moment, et expliqué : « On reste très vigilant sur ce qu'il se passe, notamment dans le cadre des plaintes déposées aux États-Unis ». Propriétaire des droits sur l'œuvre d'Hergé, la société Tintinimaginatio n'a pas souhaité commenter.

Résultat de tests menés par Next pour générer des images dans le style de Tintin ou des Schtroumpfs.
S’il n’est pas certain que le travail de chaque nom présent dans la liste de Midjourney n'ait directement été utilisé dans l’entraînement du modèle – c’est exactement ce que les plaignants américains devront tenter de prouver avec leurs propres productions face à la justice de leur pays, notamment par rétro-ingénierie –, ce manque d’information n’est pas non plus étonnant.
Auprès de Forbes, en septembre 2022, David Holz avait clairement admis avoir construit le jeu d’entraînement du modèle en récupérant des images partout sur internet. Il avait par ailleurs précisé n’avoir pas cherché à obtenir le consentement de leurs auteurs, car « il n’exist[ait] pas vraiment de manière de récupérer des centaines de millions d’images et de savoir d’où elles viennent. »
- Getty poursuit un éditeur d’algorithme en justice pour violation des droits d’auteurs
- Pas de copyright pour les images générées par l’IA
Des violations des droits d’auteurs toujours plus flagrantes
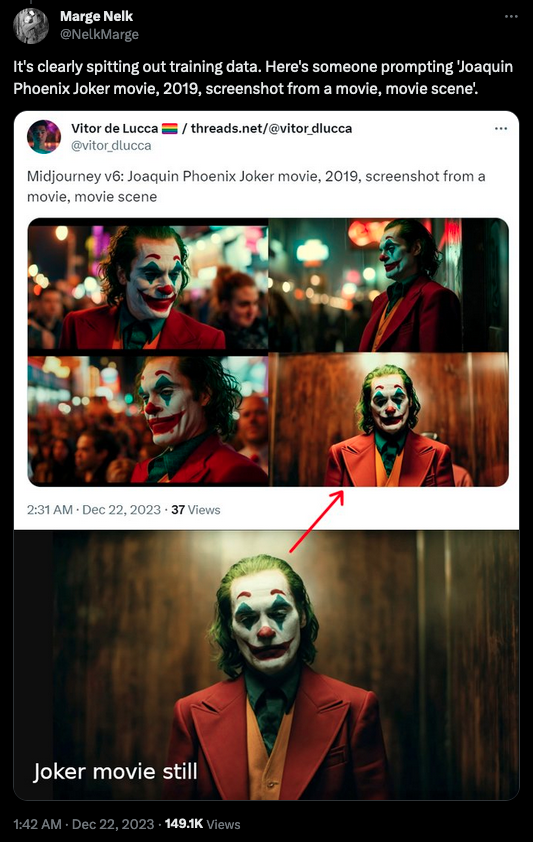
D’un point de vue américain, on peut aussi faire commencer l’affaire à la veille des fêtes de fin d’année. Le 21 décembre, la 6e version du modèle génératif Midjourney est rendue publique. Des internautes démontrent rapidement que l’outil permet de générer des images franchement proches d’œuvres existantes, que ce soit La Joconde de Da Vinci, des styles de films d’animation, voire des images de films, ou des logos de marques comme Mc Donald’s ou Starbucks.
Dans certains cas, la machine produit carrément des générations de signatures d’artistes – une problématique qui avait déjà été relevée dans d’anciennes versions de modèles d'IA génératives, et qui traduit la présence de signatures réelles dans son jeu d'entraînement.

Collage de signatures générées par Midjourney au fil des expérimentations de Next.
Quand l’illustrateur et concept artiste Reid Southen, qui a travaillé sur des films comme Matrix Resurrections, The Hunger Games ou Alien, et pour des studios comme Marvel, Warner Bros ou Paramount, l’apprend, il réalise ses propres tests. Et les montre publiquement sur X (Twitter), une décision qui lui vaut de se faire exclure de son compte Midjourney, quand bien même il en est utilisateur payant, et de voir l’historique de ses productions effacé.
L’affaire attire l’attention du spécialiste de l’intelligence artificielle Gary Marcus, qui considère les tests de Reid Southen comme une expérience de red teaming (techniquement, une bonne pratique de sécurité qui consiste à tester son modèle avant de le rendre public. En pratique, potentiellement problématique pour une entité privée quand c’est un agent externe qui s’y adonne.)
Dans sa newsletter, l’expert s’étonne de la réaction de Midjourney. Il considère qu'elle démontre sa « culpabilité ». Il cite, aussi, un ancien employé de Stable AI, Ed Newton-Rex. En ligne, ce dernier encourage les utilisateurs à ne pas se concentrer sur le seul Midjourney, mais bien à vérifier les pratiques de violation des droits d’auteurs de tous les modèles génératifs disponibles.
« Outre tous les exemples de Midjourney v6 générant des images qui sont de claires répliques de films célèbres, il est important de se rappeler que de nombreux modèles d’IA générative reproduisent des travaux sous droits d’auteurs sans que cela soit aussi évident - ils copient les œuvres pendant l'entraînement, et mettent en place des astuces simples pour essayer d'empêcher les utilisateurs de voir des copies évidentes », écrit-il.
Avec les modèles d'IA générative, explique l'avocat en droit du numérique Matthieu Quiniou, le risque en termes de violation de droits d'auteur se situe en deux points : « en entrée, lors de l'entraînement », lorsque le constructeur utilise des œuvres a priori protégées pour construire sa machine. « Dans les modèles à diffusion latente comme Stable Diffusion, la tactique généralement adoptée consiste à rajouter du bruit sur le résultat puis à en enlever, pour que le résultat produit soit théoriquement nouveau. » S'il s'avère qu'il a été entraîné sur les images les plus célèbres de Tintin et Milou, ceci pourrait expliquer que nous n'ayons jamais vu d'image strictement ressemblante, mais en revanche obtenu plusieurs fois la silhouette caractéristique du journaliste et de son chien qui courent

Trois séries de tests de génération d'images sur Midjourney à la recherche du style de Hergé, l'inventeur de Tintin. Bizarrement, le premier résultat a suggéré des dessins ressemblant plus ou moins à Gavroche ou Harry Potter.
L'autre point de risque, continue Matthieu Quiniou, se situe en sortie. « Si l'image qui sort est caractéristique, reconnaissable, on peut tomber dans l'imitation, donc potentiellement dans la contrefaçon. »
Midjourney modifie ses conditions d’utilisation en catastrophe
Mais revenons à notre histoire américaine. Le jour de Noël, Reid Southen est banni une seconde fois par Midjourney, ce qui ne l’empêche pas de publier le résultat de ses expériences. Il réalise par la même occasion que Midjourney a modifié ses conditions d’utilisations dans les jours précédents.
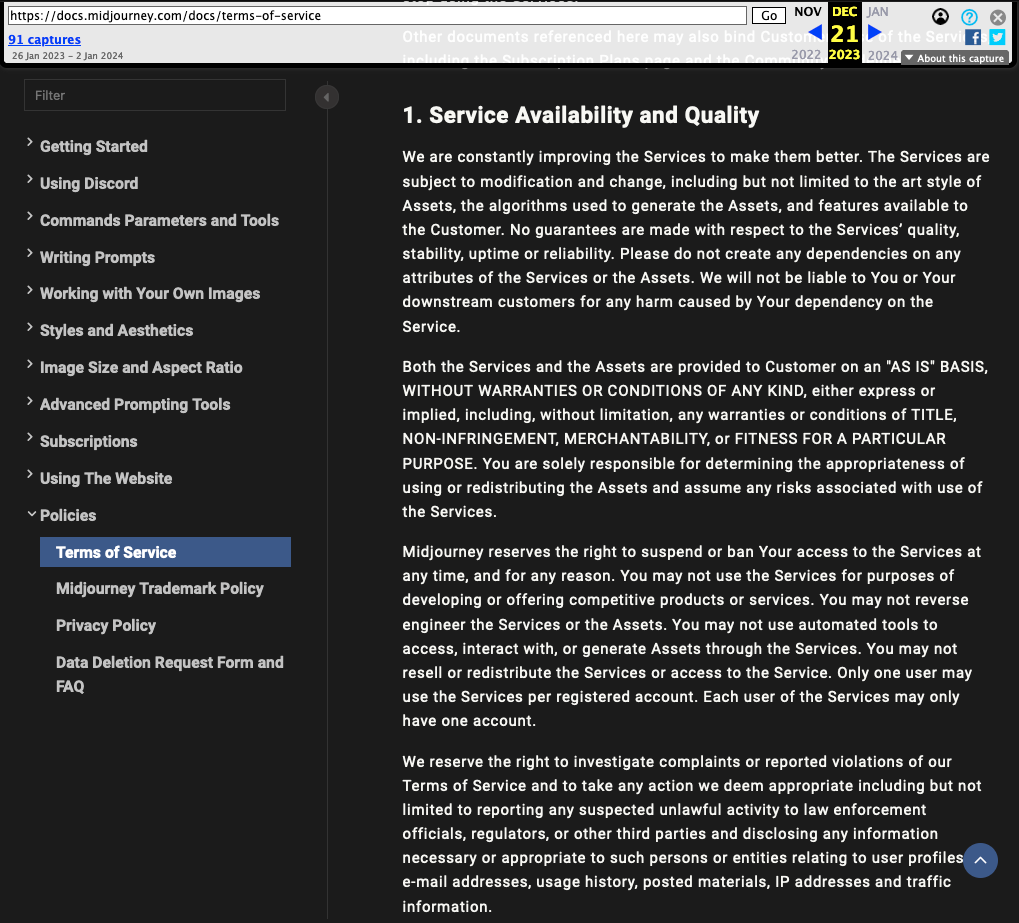
Capture des conditions d'utilisation de Midjourney telles que formulées le 21 décembre 2023.
Entre la sortie de la version 6 de son modèle, le 21 décembre, et la publication des premiers tests utilisateurs, l’entreprise a notamment ajouté un paragraphe pour tenter d’empêcher les usagers de chercher à violer des droits d’auteurs… mais aussi à tenter de prouver que celles-ci ont potentiellement eu lieu lors de l’entraînement du modèle.
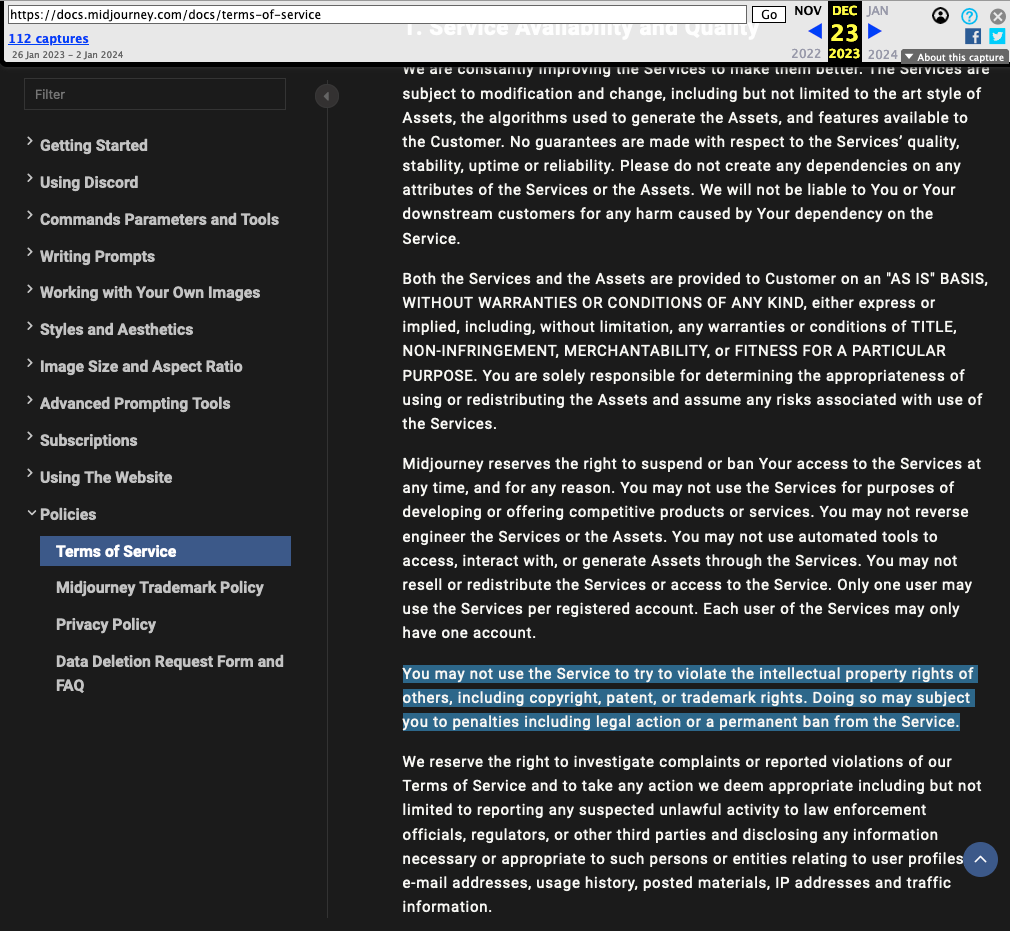
Capture des conditions d'utilisation de Midjourney telles que formulées le 23 décembre 2023.
« Vous ne pouvez pas utiliser le service pour tenter de violer les droits de propriété intellectuelle d'autrui, y compris les droits d'auteur, les brevets ou les droits de marque. Si vous le faites, vous vous exposez à des sanctions, y compris à des poursuites judiciaires ou à une interdiction permanente d'utiliser le service », peut-on désormais y lire.
Cette fouille est par ailleurs l’occasion de constater que l’entreprise emploie, en paragraphe 10, un ton menaçant : « Si vous enfreignez sciemment la propriété intellectuelle de quelqu'un d'autre et que cela nous coûte de l'argent, nous viendrons vous trouver et nous vous réclamerons cet argent. Nous pourrions aussi faire d'autres choses, comme essayer d'obtenir d'un tribunal qu'il vous fasse payer nos frais de justice. Ne le faites pas. »
Une problématique plus large que pour le seul Midjourney
Rapidement, Reid Southen et Gary Marcus s’associent pour enquêter plus loin sur les potentielles violations de droits d’auteurs de différents modèles génératifs. Rendue publique le 27 décembre, la plainte du New-York Times contre Microsoft et Open AI met les deux hommes sur une piste : le document montre que ChatGPT est capable de reproduire, quasiment mot pour mot, des paragraphes entiers d’articles soumis aux droits d’auteurs.

Capture d'écran de la plainte du New-York Times contre Microsoft et OpenAI
Or, pointe Gary Marcus, ces technologies ne le font pas simplement avec du texte : elles sont capables de reproduire, quasiment mot pour mot, certaines des sources qui ont servi à leur entraînement. Et de faire le test avec Dall-E 3, modèle de génération d’images d’OpenAI construit, comme ChatGPT, à partir du modèle GPT-4.
Gary Marcus obtient rapidement des images clairement tirées de Star Wars et de Bob l’éponge, sans même nommer les œuvres en question.
Si bien que le scientifique en vient à spéculer sur la possibilité qu’OpenAI disparaisse, « WeWork style ». « Ils savaient que les violations de droits d’auteur seraient un problème majeur, ils ont quand même continué. Ça ne jouera pas en leur faveur face à un jury. Ça pourrait même les dévorer. »
Des violations de droits d’auteur encouragées automatiquement ?
Pour avoir l’avis des principaux concernés, Next s'est plongé dans la liste de 4 700 noms produite dans le cadre de la plainte contre Stability AI et Midjourney. Entre Diane Arbus, Walt Disney et Wes Anderson, nous y avons trouvé une palanquée de concept artists qui travaillent dans le monde du cinéma et d'auteurs et autrices en manga. Et puis, en vrac, des noms de sculpteurs, de peintres, de photographes et de cinéastes francophones des deux siècles passés - Henri Matisse, Alain Resnais, Germaine Dulac, Claude Monet, Jean-Luc Godard, Yvonne Mariotte, etc.
Nous y avons trouvé, aussi, beaucoup de dessinateurs de la tradition franco-belge - Hergé, Uderzo, Franquin -, des dessinateurs tout à fait vivants, comme Domitille Collardey ou François Bourgeon, et plusieurs street artists. Parmi ceux que nous avons contactés, Christian Guémy, plus connu sous le nom de C215, et Jean-François Perroy, alias Jef Aerosol, ont chacun témoigné d’ambivalences face aux prouesses technologiques des modèles génératifs.
Auprès de Next, C215 explique avoir appris que son travail pouvait être plus ou moins repris par ces outils parce qu’on l’a « alerté, sur les réseaux sociaux ». Midjourney ne l’avait pas contacté. Pour l'avocat Matthieu Quiniou, le droit européen n'aide pas tellement, sur ce point : la directive 2019 sur la fouille du texte et des données a offert un avantage aux éditeurs d'intelligence artificielle en matière de récupération d'informations et d'œuvres.
Mais C215 explique que, dans un sens, « c’est presque une satisfaction. C'est un quasi-marqueur de notoriété », de se retrouver ainsi repris, cité, par la machine ou les usagers. Ce que ces technologies produisent, est-ce, pour autant, de l’art ? Non, estime-t-il : « l’art, c’est proprement humain. » Et pour lui, être un artiste, « c’est créer du nouveau, de l’inattendu, de l’accidentel. » Si des internautes cherchent du « succédané » de ses productions, « que voulez-vous que j’y fasse ? », interroge-t-il.
La copie, l’imitation, le plagiat, « c’est un débat vieux comme l’antiquité, dans le monde artistique ». Et pour le moment, l’artiste considère la version intelligence artificielle de l’affaire « plutôt anecdotique. C’est un gadget. » Ce qui ne signifie pas, souligne-t-il, qu’il faut jeter ces machines. Il faut les approcher « avec nuance ».
Jef Aerosol, lui, découvre le phénomène. Comme C215, il pointe le fait que l’imitation, l’emprunt ou la copie font partie intégrante du cours artistique. Ce qui l’étonne, c’est plutôt que, sans le coup de fil de Next, il n’aurait « jamais su » que son nom figurait dans la feuille de style de Midjourney.
Quelle limite fixe-t-il à la reprise des œuvres ? Du haut de ses 67 ans, l’artiste détaille : « ma carrière est bien installée, je ne suis pas procédurier. Je n’ai jamais engagé de poursuites, sauf s’il y a vraiment une volonté commerciale, pour vendre des t-shirts, des objets dérivés, par exemple, des choses que je ne fais pas du tout. »
Dans le cas du principal modèle génératif qui nous occupe, il faut payer un abonnement pour créer et produire des images. Est-ce un motif de poursuites ? Jef Aerosol a demandé à voir les images produites pour se faire un avis. Nous lui avons transmis plusieurs tests, dont celui ci-dessous, inspiré par l'un de ses pochoirs.

Génération d'images de peinture au pochoir d'un garçon assis de dos, dans le style de Jef Aerosol, réalisée par Next avec Midjourney.
Chez Dargaud, qui a édité plusieurs ouvrages de Lefred-Thouron, dont le nom figure dans la liste de Midjourney, François Le Bescond évoque encore une fois la « vigilance » de la maison d'édition comme des auteurs sur l'éventuelle reprise d'œuvres existantes. En matière de création, précise-t-il, « on refuse absolument d'éditer des œuvres réalisées à partir d'intelligence artificielle, car cela va à l'encontre même de notre métier ». Hors travail de documentation, interdiction de recourir à un modèle génératif : « nous avons ajouté des clauses sur le sujet dans nos contrats »
Matthieu Quiniou, lui, réitère : « si, en sortie, le résultat est reconnaissable, quand on fait "à la manière de" sans avoir demandé les droits à l'auteur, on produit de la contrefaçon. » En cas de besoin, il indique d'ailleurs que les artistes français peuvent tout à fait agir en contrefaçon, « en se rapprochant de leur société d'auteur, par exemple : l'ADAGP [société des auteurs dans les arts graphiques et plastiques, ndlr] se positionne pas mal sur le sujet. »
En matière de droits d’auteur, après une année 2023 chargée en plaintes déposées aux États-Unis contre les principaux éditeurs de modèles génératifs, le changement d’année aura été riche en nouveaux rebondissements. Dans de prochains articles, nous plongerons plus avant dans les documentations disponibles des modèles poursuivis.
Contactés par Next, Midjourney et plusieurs autres parties impliquées n'ont pas répondu à l'heure de publier. Nous mettrons l'article à jour le cas échéant.
Vous même utilisez Midjourney ou un autre modèle génératif et vous avez réussi à générer des images particulièrement proches du style d’un artiste francophone ? Vous travaillez à construire ou améliorer des modèles génératifs et souhaitez en discuter ? Écrivez-nous, en commentaire ou par mail.
Mise à jour le 04.01.2024 : ajout des deux citations de François Le Bescond (Dargaud)
Commentaires (107)
Le 03/01/2024 à 17h56
Le 03/01/2024 à 18h50
J'avais essayé de demander un portrait d'un homme derrière une femme, le visage proche, les deux en maillot, en train de bailler et ça avait été rejeté.
Le 03/01/2024 à 23h05
Le 03/01/2024 à 17h58
Le 03/01/2024 à 18h01
Modifié le 03/01/2024 à 18h14
Le 04/01/2024 à 13h55
Le 03/01/2024 à 18h46
Le 04/01/2024 à 09h00
Le 03/01/2024 à 18h56
casque d'asterix
cadre de la glace titi
reflet de batman
dessin de rantanplan
coiffure de super-sayan
visage de mario
brin de blé (qui remplace la clope car çépabienlaklop! bouh!) de lucky-luke
carapace de tortue géniale
queue de pikachu
jambe de spiderman
pc de Flock
me manque quoi que j'ai pas trouvé?
les bras? les post-it?
Modifié le 03/01/2024 à 19h45
On peut ajouter le bras d'un Simpson, la main de la Chose des 4 fantastiques (ou le gant de Thanos ?), L'homme de Vitruve, Terminator et Wall-E sur les post-it si je vois clair
Modifié le 03/01/2024 à 19h09
Exemple au hasard : style Hayao Miyazaki.
Perso c'est un cas d'usage que je n'apprécie pas.
Sinon pour les signatures, de nombreux modèles entraînés à partir de ceux de SD n'arrêtent pas d'en produire c'est une horreur. La plupart des modèles chinois sont entraînés comme ça et malgré "watermark" ou encore "artist signature" en prompt negatif, ils en recrachent. Généralement ce genre de modèle je le trash direct.
Le 03/01/2024 à 19h18
Après, Square-Enix a surfé sur la blockchain et les NFT, donc à voir si c'est juste une lubie par effet de mode ou une intention réelle.
Le 03/01/2024 à 21h14
Le problème c'est quand tu lui demandes réellement de créer depuis rien, car il n'y a pas de rien, il y a un référentiel, comme nous d'ailleurs.
Et quand on doit dessiner un humain, on a en tête des centaines milliers de variantes différentes, qu'on analyse depuis des décennies en mouvement et en 3D pour définir ce qu'on considère comme une caractéristique d'un humain. L'IA a même pas 1% de ça en stock, et en plus c'est pas du random, c'est une version de l'humain telle qu'on a souhaité "figer" sur une représentation. Rien que le fait qu'on sourit sur la plupart des photos, ça fait dire que c'est impossible d'avoir un jeu de données assez grand et assez représentatif pour se mesurer à un humain.
Le 04/01/2024 à 09h07
Pour le second point, la diversité des poses, mouvements, formes, etc, est déjà pas mal collectée par les jeux de donnée mais c'est surtout via des LoRA qu'on peut assister la production d'image plus spécialisée. D'ailleurs c'est même une des techniques de ML utilisées dans le cadre de l'entraînement des modèles de génération d'image basées sur la manifold hypothesis. Par exemple, un visage a de très grande chances d'être constitué de deux yeux, un nez et une bouche. C'est déjà un guide de base utilisé par le modèle.
L'autre élément qui aide beaucoup, c'est le ControlNet qui permet de guider le modèle dans la production souhaitée en lui fournissant l'attendu (ça peut être une autre image).
Le 03/01/2024 à 19h46
Je me dis que peut-être qu'au lieu de blâmer les IA génératives, il faudrait peut-être blâmer les lois qui donne des droits d'auteurs à des gens qui ne sont pas les auteurs... Aujourd'hui, le moindre mot ou le moindre assemblage de 2 pixels est breveté... Donc bon...
Pour le texte du NY Time, si ca se trouve, il a été en partie généré par une IA, et légèrement reformulé à la main. Donc c'est pas choquant qu'une IA ressorte le même texte qu'il trouve, étrangement, bien.
Aussi, le style "Jef Aerosol", c'est quasiment un nom commun pour désigner ce style, que ce fameux Jef n'a pas inventé. C'est juste comme ca qu'on l'appelle. Si ca arrange tout le monde, on a cas appeler ca le style ForceRouge, promis je n'irais pas réclamer de droit d'auteur...
Donc demander un dessin de robot dans le style de Jef Aerosol, ce n'est pour moi, pas du plagia.
Le 04/01/2024 à 10h43
Moi j'appelle ça tempête dans un verre d'eau. Si je demande un copain qui dessine bien un "Tintin", dois-je attaqué comté Faber Castell, Caran d'Ache, ou encore Derwent ?
l' "IA" se "rappelle" de l'historique de la conversation ou du prompt, dans le cas du "toys story" est-on sûre que dans le prompt précédent il n'y en avait aucune référence ?
Ne pas oublier n'ont plus que la législation Française, pourtant très protectrice sur la propriété intellectuelle, permet le droit à la citation et à la caricature.
C'est d'ailleurs ceci qui permet au site d'y faire apparaitre les illustrations, et à notre Flock National d'avoir pu faire ce subper pôt pourri. :-)
Le 04/01/2024 à 11h30
Modifié le 04/01/2024 à 11h34
Quant au droit à la citation: même en France il y a une distinction avec le plagiat. Or à partir du moment où le produit issu de ce service est une oeuvre d'un auteur produite sans référence voire avec la signature dudit auteur, on rentre clairement dans le plagiat.
Edit: grillé
Le 07/01/2024 à 22h19
ON LE PAIE pour que cette entreprise s'enrichisse !
si votre copain dessine bien du tintin pour ensuite le vendre à la FNAC, y aurait un procès des plus légitimes CONTRE votre copain, la FNAC ,et peut être vous pour complicité
vous comprenez la différence entre "chez soi avec mon pote, rholalal on dessine" et "on fait un commerce sur le dos de la notoriété d'un artiste reconnu, ha et les droits de diffusion ? ben on s'en tape !"
Le 08/01/2024 à 08h46
Ne pas confondre outils de productions et producteurs.
Midjourney, sans action d'un utilisateur sur son prompt ne produit rien ne communique rien.
Le 08/01/2024 à 09h01
Différence minime mais ô combien importante dans le cas qui nous intéresse ici.
Le 08/01/2024 à 09h06
Je donne quand même un dernier exemple vu que c'est l'épqoue des stages de 3èmes.
Un stagiaire et une photocopieuse. Si son maitre de stage lui fait photocopier des choses, le responsable c'est le stagiaire ou son maître ?
Le 08/01/2024 à 09h40
Mais cette comparaison me semble déjà beaucoup plus pertinente que le photocopieur ou photoshop. Avec le comparatif IA/Stagiaire, se pose la question de l'intermédiaire humain / pas humain.
Le 08/01/2024 à 09h48
Parce que là, j'ai un batch en cours de production avec le seul prompt disponible dans l'article ("animated toy"), et les résultats sont intéressants avec Stable Diffusion (je posterai ça une fois fini).
Mais si on veut rester d'une manière plus générale, le débat est peu ou prou le même que celui de l'impression 3D qui faisait hurler à la contrefaçon de masse.
Le 04/01/2024 à 01h20
L'artiste à une reconnaissance de son œuvre, comme souligné ici.
À l'inverse, un profit sur le travail d'un autre grâce à ces outils... perso je râlerais.
"Jef Aerosol a demandé à voir les images produites pour se faire un avis. Nous lui avons transmis plusieurs tests, dont celui ci-dessous, inspiré par l’un de ses pochoirs."
Qu'a t'il répondu ?
Le 04/01/2024 à 11h39
Modifié le 07/01/2024 à 22h24
on paie un ABONNEMENT EN VRAI SOUS DU REEL
et c'est géré par une entreprise qui a pour but de faire du profit
c'est évidemment sous la coupe des lois de droits d'auteurs etc.
-
et moi même j'ai utilisé midjourney, je vois pleinement la puissance des modèles stable diffusion et autres outils, mais je vais pas cracher pour autant sur les droits Légitimes et Justes des auteurs dont a volé le travail sans même pas les prévenir, pour entrainer ces fabuleux modèles et ensuite en faire un profit !
-
si on entraine une ia pour faire du peyo à la cool pour chez soi, okay, amusons nous, zéro soucis, apprenons la technologie.
mais si vous faites un COMMERCE sur l'exploitation issues du travail d'autrui vous devez avoir l'AUTORISATION d'autrui et/ou cracher du fric pour lui/elle !
Le 08/01/2024 à 17h02
J'ai remplacé midjourney par adobe dans votre réflexion, et la conclusion devrait être la même et pourtant personne n'attaque adobe.
Car ce que adobe commercialise est un outil et nous le résultat de cet outil.
Idem pour Midjourney.
Modifié le 04/01/2024 à 05h55
L'exemple sur Joker, y'a rien d'étonnant ! Cette image à du être tagguée partout avec quasi les mêmes exacts mots que ceux utilisés dans le prompt ! Pourquoi il irait faire autre chose ? On le lui demande !
En plus, et ils l'avouent, ils n'avait aucun moyen de savoir si il y a un copyright sur les images bouffées par le moteur, en fait ils n'avaient pas envie de se faire chier vu la quantité engrangée.
Maintenant ils n'ont plus qu'a entrainer à ne pas reproduire certain style, mais je trouve cela dommage. On a bien des artistes spécialisés dans la "reproduction" ! Et des personnes spécialisés pour identifier si c'est un original ou pas ! Reste à avoir la même pour le numérique
Au final le rendu est aussi le reflet de la demande du prompt et c'est rassurant, si on peut maîtriser en étant sur que ce qu'on demande est retranscrit.
Moi, je ne suis pas artiste ni rien, mais je trouve que tant qu'il y a une signature un quelconque truc qui permet de flagguer que c'est généré par l'IA déjà ça serait rassurant. Puis si ils pouvaient aussi donner une sorte de "liste" des principales images source que l'IA à mixé pour l'obtenir ça serait pas mal.
Visuellement sur les images générées ici y'a rien qui affiche "généré par l'IA" y'a une watermark un truc ? En tout cas je pense que les navigateurs devraient commencer à intégrer des outils pour afficher une info sur les images enfin faire un truc pour nous permettre de savoir si c'est de l'IA ou pas.
Déjà si y'a bien un watermark qu'il nous l'affiche visuellement sans qu'on ai à fouiller la source de l'image. Peut-être un raccourci clavier qui nous permette de vérifier l'info facilement !
D'ailleurs y'a aucune balise
altremplis sur certaines images ici ( la plupart ).Peut-être déjà faudrait-il que le w3c travaille sur l'ajout d'attributs sur les balises images à fin de pouvoir spécifier l'auteur de l'image plus que de devoir s'appuyer sur des descriptions/légendes ( caption ) attachées, rarement, aux images. Et une de copyright.
Et rajouter une sorte d'attribut "source" human/IA
Tiens d'ailleurs, l'IA peut reproduire des images NFT ?
Edit à et je rajoute :
- Merci pour l'article c'est passionnant !
- Flock
Le 04/01/2024 à 09h00
DALL-E chez OpenAI applique un watermark, mais il est parfaitement possible de le supprimer c'est même indiqué dans la FAQ.
D'ailleurs quand on cherche "dall-e wtermark" on est floodé de liens disant comment le supprimer.
Midjourney ne semble pas poser de watermark sur les contenus générés, j'ai rien trouvé qui en parle dans la FAQ et je m'en sers pas, préférant SD en local chez moi.
Mais quel intérêt si personne ne s'en sert ? Je pense que la plupart des personnes qui génèrent du contenu sous copyright (volontairement ou non) s'inquiètent à peu près autant du droit d'auteur que celles qui mettent à dispo des séries TV, films ou albums sur les réseaux de P2P. Non pas forcément par malveillance, mais ne serait-ce que par simple négligence.
Perso j'y suis sensibilisé et j'indique toujours la licence et l'auteur d'une image que j'utiliserais sur bon blog. Tout comme j'indique quand j'ai fait une illustration par IA.
D'ailleurs, au début de mes activités d'écriture de ebooks, je voulais mentionner explicitement dans la page de copyright que la couverture était générée par IA. Sauf que j'ai renoncé à le faire à cause d'une des plateformes de publication : Amazon KDP. Non pas qu'ils interdisent ce matériaux (même s'ils prennent les usuelles pincettes sur le fait que t'es responsable toussa), mais dans la soumission du livre il y a depuis quelques mois un champ demandant si le contenu a été totalement / en partie généré par IA. Ce sur différents aspects : images, texte, traduction.
Dans mon cas, je pouvais cocher la case "image" pour la couverture. Sachant que dans mon usage, je vérifie via Tineye + Google Search Image si l'image produite ne s'approche pas d'une existante. Tout comme je peux cocher la case pour la traduction car je me fais assister de DeepL et son outil Write (basé IA).
Seul hic : on ne peut pas dire que seul un des trois critères est valide et que les autres n'ont pas eut d'assistance de la part d'un outil basé IA. C'est ou tout ou rien. Dans mon cas, c'est totalement à côté de la plaque, donc j'ai fait le choix de dire "non" à ces questions et de ne pas indiquer dans le livre que la couverture a été générée via SD avec tel modèle (ce que je voulais faire). Pourquoi je ne le mentionne pas ? Car Amazon c'est des psychopathes qui peuvent shoot un profil auteur sur un coup de tête, donc j'évite de leur donner des raisons. Dans tous les cas, je reste transparent sur ce point, je poste même régulièrement des samples de test. J'avais proposé de faire un retour d'expérience pratique sur l'usage d'outils basés IA à Next il y a quelques temps d'ailleurs. Incluant une vulgarisation sur comment GPT et Stable Diffusion fonctionnent.
Modifié le 05/01/2024 à 06h16
Et oui pour les balises, biensur y'a aucune obligation mais je pense principalement aux sites journalistiques et autres, musée par ex pour lesquels cela devrait être obligatoire au vu de leur activité et je pense qu'ils sont déjà obligé de mettre ces informations dans les balise image.
Le but serait de réduire la possibilité des personnes qui génèrent ces modèles "d'IA" de dire "c'était impossible de savoir".
Par ex sur le site web du MUCEM, ils utilisent les balises
figureetfigcaptionc'est déjà pas mal mais si il pouvait y avoir une balise pour le nom de l'auteur de façon séparée je pense que ça serait appréciable.Pour ce qui est de ta recherche des images que tu as généré, je trouve l'idée géniale et ça devrait être une bonne pratique !
Même par l'IA, qu'elle vérifie dans sa banque d'image si elle n'est pas trop proche d'une source existante et donc potentiellement en pleine "violation de droit d'auteur". Ou en tout cas l'utilisation à des fins commerciale de l'image générée pourrait conduire à cette "violation de droit d'auteur"
Merci encore pour tes retours :)
Edit: c'est quoi la MAJ de l'article ? Je n'arrive pas à identifier. ça serait cool d'ajouter en fin d'article une phrase pour dire ce qui à été modifié si c'est "important". J'imagine que ce ne sont pas simplementdes corrections orthographiques.Edit2: Ok je viens de lire "Mise à jour le 04.01.2024 : ajout des deux citations de François Le Bescond (Dargaud)" je deviens parano j'ai pourtant bien cru ne rien avoir vu écrit... Il est trop tôt
Le 05/01/2024 à 09h16
Cela reste possible de filtrer les productions, mais il faut qu'il soit implémenté et utilisé. Dans les cas des modèles gérés par une seule entreprise, ça reste une possibilité (comme GitHub Copilot qui peut filtrer le code proche de celui sous license libre, c'est une option du service) au même titre qu'il y a déjà des filtres pour s'assurer que le résultat n'est pas porno/violent/gore/toussa sur DALL-E ou Midjourney (même si ça reste imparfait).
Dans le cas de Stable Diffusion, c'est mort, clairement car le produit est open source et de nombreux modèles spécialisés existent.
Dans un précédent article, j'avais dit que pour moi c'est un non sens de chercher à répondre à toutes ces problématiques par la technologie. Il est utopique d'imaginer qu'on pourrait gérer au sein de la technologie ce que l'IA est capable de produire ou non, car c'est du même acabit que de considérer que C++ ne doit pas produire de malwares, ou encore plus simpliste, dire qu'un couteau ne doit pas être capable de trancher de chair humaine.
C'est d'autant plus illusoire que de nombreux modèles sont entraînés spécialement pour reproduire un style, cf l'exemple que j'ai donné en #5.
Le 07/01/2024 à 22h30
"
parce que l'entreprise n'a jamais eu le droit de faire cela.
elle n'avait pas le droit de prendre des images sous droits pour entrainer son ia.
l'illégalité est déjà en germe là : l'ENTRAINEMENT sur des oeuvres SANS autorisation.
Midjourney avant tentait de se défendre en disant "meuuh non on a pas entrainé sur des images de film Warner"
mais progressivement, à force de bien maitriser les prompts et manifestement encore plus facilement depuis laversion 6, on peut obtenir des images quasi identiques à des images pré-existantes
cela n'est pas une coïncidence. C'est qu'on arrive à faire sortir du modèle des images de son JEU D'ENTRAINEMENT à peine bruitée. Ce qui PROUVE que OUI, ça a été entrainé, SANS AUTORISATION DONC, sur des images de WARNER, ici le film "Le joker".
Cela on a réussi à le reproduire avec aussi des auteurs de bds, etc.
Ce qui était avant considéré impossible (y a 2 ans en gros) : que le jeu de donnée qui a servi à entrainer puisse être ressortie par l'IA (elle est censée bruiter pour toujours inventer une image inédite) est en fait relativement facile
c'est une mauvaise nouvelle pour les entreprises qui vendent l'usage de modèle génératifs : car ça permet de trouver sur QUOI ça a été entrainé
et donc de dire... "hé dis donc... tu vas payer mon travail, mec... ou tu vas expurger ton modèle de mon travail, ouais mec.. je m'en fous si tu vas devoir réentrainer ton ia sans mon travail pendant 400h"
Le 04/01/2024 à 08h52
Le 04/01/2024 à 09h27
Le 04/01/2024 à 10h05
Le 04/01/2024 à 11h53
C'est le genre d'informations qui manque généralement dans vos articles quand ils relatent les expériences des autres (et c'est normal que ça manque parce que vous n'avez pas l'information).
Les 2 premières images on l'air de correspondre à une même demande : "animated toys" sans autre contexte, ai-je bien compris ?
Quel était le prompt pour la cannette de soda ?
Remarque : Wall-E n'est pas un jouet en réalité, donc l'image sortie est mauvaise par rapport à la demande.
Je comprends mieux les personnages sortis de Toy Story qui eux correspondent bien à la définition et auxquels penseraient aussi un humain sur une telle demande.
Le 04/01/2024 à 14h08
Quand au reste c'est encore un combat de luddite. Les artistes cherchent absolument à tirer profit de cette industrialisation mais ils n'en ont pas plus le droit qu'eux-même n'ont jamais rien reversé à leurs inspirations qui les ont construit. Les LLM ne sont que des outils qui permettent de démocratiser la création, en imitant parfois si c'est ce qui est recherché, mais aussi en combinant et créant de nouveaux styles comme cela à toujours été le cas. L'art évoluant en s'appuyant les uns sur les autres.
Le 04/01/2024 à 14h55
Et pour imiter, il faut connaitre l'original. Encore une fois, gagner de l'argent par l'utilisation sans accord de la création des autres. Quand on parle de musiques (ou d'humoriste), il y a rarement débat.
Le 04/01/2024 à 15h02
Pareil, connaître les œuvres originales n'est pas une violation de droit, c'est son utilisation qui est sujet au copyrights.
L'outil ne viole rien, c'est ce qui est produit avec qui peut l'être.
Le 05/01/2024 à 08h03
On peut légitimement penser que le droit doit évoluer, mais en l’état, ils sont plutôt du mauvais côté.
De jurisprudence constante, la mise à disposition sur un site web constitue une diffusion. Midjourney diffuse sans autorisation des contenus soumis au droit d’auteur. Je souhaite bon courage à leurs avocats…
Le 07/01/2024 à 22h42
or, déjà , il existe qu'une entreprise qui a le droit de faire une exploitation commerciale du logo coca cola, c'est... coca cola !
ici, Midjourney aurait du de base expurger son jeu de donnée de toute image avec le logo coca cola
moi je pourrais entrainer ma propre ia avec des photos avec logo pepsi et coca, et ça serait pas grave si c'était qu'à usage privé que je ne distribue pas
mais ici c'est MIDJOURNEY, une entreprise COMMERCIALE, qui a sciemment entrainé SON IA, avec un jeu de donnée que MIDJOURNEY a constitué ELLE MEME dans un but précis : COMMERCIALISER un SERVICE
c'est donc du commerce
et une exploitation d'un logo sous droit des marques et auteur
SANS accord
et cela SUFFIT pour que ça puisse être illégal.
-
on a pas besoin de débattre des ia, de si c'est pondu à la sortie ou pas, c'est le seul fait qu'il est prouvable quele jeu de donnée de Midjourney a été constituée avec des images dont Midjourney n'avait pas les droits. Ici le logo de coca cola (évidemment que coca cola ne vous autorise pas sans échange de gros cheques)
ailleurs c'est le travail du dessinateur Boulet qui a été utilisé pour entrainer
etc
etc
le seul fait d'avoir mis dans le jeu de donnée d'entrainement est DÉJÀ un problème juridique.
Le 08/01/2024 à 19h05
Non, ça ne marche pas comme ça.
Absolument pas. Renseignes-toi sur le fair use. C'est un vieux débat qui a déjà eu lieu sur le crawling et tout un tas de NTIC et qui a été clos.
Le 08/01/2024 à 19h48
Il est difficile ici de parler de fair use. Dans le cas des moteurs de recherche par exemple, c'est du fair use, car chacun y trouve son compte : le moteur enrichie son indexe, et la cible est référencée (donc trouvable).
Ici, on est dans une nouvelle zone, une zone grise, à la frontière entre tout ce qui était connue jusqu'à présent. On peut faire beaucoup d'analogie, mais il y a toujours le détail qui vient mettre un grain de sable dans l'engrenage.
On aimerait qu'il soit simple d'apporter une réponse, et que tout soit blanc ou noir. Mais ce n'est pas le cas ici. La problématique des oeuvres dérivées (car pour moi, c'est de cela donc cela se rapproche le plus) est délicate, car placer le curseur sur ce qu'est une nouvelle oeuvre, un plagiat, une inspiration, une caricature, etc... c'est extrêmement compliqué.
J'ai juste envie de prendre l'exemple des oeuvres sous licences CC-BY-NC-SA par exemple. On a le droit de les modifier, de les partager, mais pas d'en tirer profiter (que ce soit de l'oeuvre original ou de la modification). Une IA génératrice qui ressort une oeuvre inspirée d'une oeuvre sous licence CC-BY-NC-SA, respecte-t-elle la licence ? Où se situe la limite ? Réponse : il n'y a pas de réponse toute faite.
Surtout que la notion d'exploitation commerciale peut être très vague : pour certaines licence, cela ne va concerner que la vente directe. Pour d'autre, la vente de tout service incluant, de près ou de loin, la présence de l'oeuvre.
En bref, c'est un véritable bordel car derrière chaque notion, chaque terme, il peut y avoir mille interprétations différentes, et répondre à la question du droit d'auteur, cela va nécessiter de répondre à de multiples questions, qui n'acceptent pas une réponse simple :
- qu'est-ce qu'une exploitation commerciale ?
- qu'est-ce qu'une oeuvre dérivée ?
- où commence l'inspiration et où se termine le plagiat ?
- quelle est la part de responsabilité de l'utilisateur et celle de l'éditeur de l'outil ?
- où se situe la limite du fair use ?
- quid des droits moraux ?
Quand on voit que des procès d'un ayant droit à un autre, peuvent prendre des années (par exemple, le célèbre cas de scrat, dont le procès initial a débuté en 2003 pour être clos en... 2022 !
Alors on peut dire tout ce que l'on veut, sauf que c'est simple. Cela ne l'était déjà pas avant les IA génératrice. La situation étant encore plus floue qu'avant, cela ne peut être que plus compliquée encore...
Le 09/01/2024 à 12h54
Le 04/01/2024 à 15h29
Le 04/01/2024 à 17h58
De la même manière que tu as pas le droit de vendre des casquettes Pikachu sans autorisation de la Pokémon Company, tu as pas le droit de vendre des images de personnages de Toy Story, même si c'est un algo qui a produit l'image plutôt qu'un copiste humain. Or, c'est exactement ce que fait Midjourney, qui est je le rappelle un service commercial.
Je veux bien qu'on soit critique d'une extension excessive du droit d'auteur mais faut pas charrier : s'agissant d'un service commercial, c'est quand même plus que limite de faire du pez avec le travail des autres.
L'inspiration n'est pas la question : ce qui est reproché à Midjourney ici n'est pas de "générer des nouveaux personnages en 3D, dans le style de Pixar" (ça, ce serait de l'inspiration). Il lui est reproché de générer des copies conformes de personnages existants. Ça, c'est du plagiat.
Les seuls qui ont un argument à faire valoir pour moi, c'est Stability AI parce que le modèle est téléchargeable et peut être exécuté en local : on pourrait estimer que c'est celui qui fait tourner le modèle sur sa machine qui est responsable de la contrefaçon. Mais Midjourney, vu qu'ils font tourner eux-même leur modèle, ils ont pas d'excuse. Dall-E non plus.
Le 05/01/2024 à 05h10
C'est un outil.
Modifié le 05/01/2024 à 08h21
Le 05/01/2024 à 20h47
À part pour stable-diffusion exécuté en local sur ton PC, faut pas oublier que c'est pas toi qui possède l'outil et fabrique les contrefaçons : c'est Midjourney, Stability AI et OpenAI qui les fabriquent sur leurs machines, et ensuite te les transmettent. Ce qui en soi représente d'ailleurs probablement une contrefaçon, en tant que "reproduction, représentation ou diffusion, par quelque moyen que ce soit, d'une oeuvre de l'esprit en violation des droits de l'auteur".
Le 05/01/2024 à 08h35
Le 05/01/2024 à 11h16
Pour moi il ne s'agit pas d'un simple moteur de recherche aveugle, mais d'un outil qui se sert de données aspirées volontairement.
(et d'ailleurs, même les moteurs de recherche sont responsables de ce qu'ils proposent. Outil ou pas, ils doivent empècher la présence de contenus enfreignant le droit d'auteur ou simplement illégaux)
Il suffit de voir que les IA génératives (d'image ou non) évoluent pour éviter la nudité et autres contenus non acceptés.
Comme quoi, quand il veulent ils peuvent éviter le résultat en sortie.
Le 05/01/2024 à 11h41
Contrairement au moteur de recherche qui renvoie vers un site qui transmet l'intégralité d'un œuvre sans son consentement. L'algorithme derrière une IA, ne fait que restitué le résultat d'une opération mathématique suivant les opérateur entrée par un utilisateur.
Ce résultat peut aboutir qui in fine semble être apparenté à une œuvre soumis au droit d'auteur mais elle n'en est pas la copie conforme, et elle n'en revendique rien.
De plus bien que produite et possiblement associable à une œuvre soumise à droit d'autre, c'est bien la communication au public (à titre onéreux ou non) et en revendiquant par l'auteur de la demande fait à l'IA, d'un caractère original de ce rendu qui lui pourrait être éventuellement poursuivi en justice. (plagiat ou citation ou œuvre véritablement original ?)
Le 05/01/2024 à 13h59
Vu que jamais dans les images fournies, les références ou les copyright ne sont donnés, il est un peu facile de ne faire porter la responsabilité qu'aux seuls utilisateurs.
Quant on couple avec cela le fait que le service est un service commercial, je ne vois pas en quoi la responsabilité du "créateur" d'image pourrait être entièrement effacée.
Le 05/01/2024 à 16h33
J'ai demandé à Google image "animated toy" et la 17 ème image est une image correspondant à Toy Story : https://resize-europe1.lanmedia.fr/r/622,311,forcex,center-middle/img/var/europe1/storage/images/europe1/culture/trois-raisons-qui-prouvent-que-toy-story-a-revolutionne-le-film-danimation-3471521/44791538-1-fre-FR/Trois-raisons-qui-prouvent-que-Toy-Story-a-revolutionne-le-film-d-animation.jpg
Les images précédentes sont pour beaucoup des images de jouets de cartoon (dessins animés). Comme animated correspond aussi au sens animé de film d'animation, c'est assez cohérent.
J'en conclus que sans connaissance précise du prompt, il est difficile de conclure, mais avec un prompt très court, on peut probablement tomber sur des jouets de dessin animés ou des jouets animés.
Le créateur de l'image est normalement celui qui fournit le prompt. Mais avec un prompt trop court, on ne maîtrise plus la sortie et il ne sort que des trucs proches des plus "vus" lors de l'entraînement.
Le 05/01/2024 à 19h39
Sur ce point, il y a du oui et du non de mon expérience. Trop contraindre le modèle peut le faire partir en vrille et avoir des résultats éclatés au sol. Il faut éviter des prompts trop gros avec trop d'instructions (typiquement SDXL sur Stable Diffusion a permis de supprimer la ribambelle usuelle des "hdr, best quality", etc) et lui laisser une part de liberté. Après, ça se joue aussi au niveau des paramètres envoyés au modèle.
Bon, là on parle de Midjourney, et perso j'ai jamais utilisé (veux pas faire de truc public comme ça sur Discord, mon usage de SD est privé quant à lui et je choisis quoi partager). Mais vu la doc, il y a quelques params qui permettent de moduler la créativité du modèle. Pas aussi libre et avancé que SD (car ça partirait vite en vrille ou coûterait très cher à faire tourner), mais y'a de quoi s'amuser avec notamment le seed pour réutiliser une base.
Côté DALL-E 3 les paramètres me semblent très limités pour ne pas dire inexistants.
Côté prompt engineering, OpenAI fourni quelques conseils intéressants, tout comme j'avais bien aimé cet article aidant à formuler les prompts pour SDXL.
Le 06/01/2024 à 12h28
Ensuite tu es de parfaite mauvaise foi car tu sais parfaitement que personne ne maitrise l'utilisation de l'historique des prompts dans l'obtention d'un résultat final.
Je résume: peu importe l'historique des prompts, peu importe la terminologie exacte utilisée dans un prompt final à partir du moment où le nom d'un auteur n'a pas été utilisé.
A partir du moment ou cet outil de CREATION d'images n'indique pas clairement à partir de quoi il s'est inspiré, voire si potentiellement l'image finale est très proche d'un original, il y a un problème.
A moins que tu estimes qu'il faille avoir une licence es midjourney pour pouvoir l'utiliser en toute connaissance de cause, l'utilisateur final ne peut pas être responsable des algorithmes utilisées pour CREER une image.
De plus étant vendu comme une IA, le minimum syndical serait de prévenir l'utilisateur que l'image produite peut être soumise à copyright par rapport à tel ou tel auteur.
S'ils ne sont pas capables de faire cela, il faut alors clairement indiquer aux utilisateurs de leurs outils, que ces images CREEES ne peuvent pas être utilisées à des fins commerciales.
Pour finir la comparaison avec Google est complètement ridicule: un moteur de recherche ne crée pas d'image, il fournit une vignette + un lien pour la récupérer sur le site qui l"héberge. Le tout en signalant à chaque fois que chacune de ces images peut être soumise au copyright.
Le 06/01/2024 à 13h25
À la lecture de l'article, il semble que le prompt ait été seulement "animated toy". J'ai demandé confirmation de cela sans réponse. Je me trompe peut-être, mais ce manque d'information rend la réflexion sur ce sujet difficile.
Je viens de voir que Midjourney crée 4 images pour répondre à une demande ( https://docs.midjourney.com/docs/quick-start ). Nous n'avons eu que 2 des images. Je suppose que les 2 autres images n'étaient des œuvres protégées. L'information est donc au minimum partielle et au maximum partiale.
Je n'utilise pas Midjourney et je ne sais pas comment ça fonctionne, mais je comprends que ça s'utilise par un bot sur Discord. Partant de là, il est facile de copier l'historique des prompts. Je n'ai donc pas l'impression qu'il est de mauvaise foi, pas plus que moi qui ait posé la question initialement.
En fonction de la demande, même sans préciser un nom d'auteur, ça ne me surprend pas que dans les 4 images, il y en ait une très proche (possiblement une contrefaçon) de Toy Story si l'on demande des jouets animés.
Tu sais bien que par construction, un outil de ce type passe par une phase d'entraînement mais qu'il ne mémorise pas à quelle image source appartient une partie de ce qu'il a mémorisé. C'est techniquement impossible. Là, c'est toi qui est de mauvaise foi.
Pour être très clair, j'ai l'impression que les outils de ce type qui ressortent quasiment des œuvres protégées ont un problème : à force de vouloir les améliorer, elles mémorisent trop de choses ce qui fait qu'elles deviennent presque un outil de compression et/ou de base de données d'images qu'un outil de création. Il semble que ChatGPT ait le même problème. Ça peut être lié au fait qu'à chaque génération de ces outils, le nombre d'informations mémorisées augmente beaucoup. Et il y a probablement une dérive de ce côté qu'il faudra corriger. Oui, il y a probablement un problème, mais sans information sur comment ces images ont été obtenues, on aura du mal à comprendre dans quel cas il se produit et encore moins d'où il vient.
Ils font tout un tas d'avertissements dans leurs ToS, plutôt pour se protéger, mais ça doit aussi alerter les utilisateurs des risques.
Quant à la comparaison avec Google, c'est moi qui l'ai faite, juste pour montrer que Toy Story ressort assez vite et que si Midjourney sort des images de style différent, ce n'est pas aberrant qu'il en sorte une du style Toy Story pour répondre à animated toy ou un prompt de ce genre. Ça correspond aux images qui ont servi à son entraînement et Google image doit être assez représentatif des images utilisées pour celui-ci. Réfléchir un peu et essayer de comprendre n'a jamais été ridicule à mon avis.
Le 06/01/2024 à 20h44
J'en ai marre de ce comportement.
Le 05/01/2024 à 20h54
Le 05/01/2024 à 12h52
C'est très différent.
Le 05/01/2024 à 20h39
Si tu veux faire une comparaison, qui sera toujours imparfaite mais se rapprochera déjà un peu plus de la situation, c'est comme si tu faisais fabriquer des casquettes Pikachu par une usine, qui sait pertinemment que ni elle, ni toi ne possédez la licence pour faire des casquettes Pikachu. Est-ce que l'usine est au moins complice de la contrefaçon ? À vue de nez je dirais oui, en tout cas en France ce serait a priori de la complicité par fourniture de moyens.
Le 06/01/2024 à 13h18
Le 06/01/2024 à 13h30
Le 10/01/2024 à 18h45
Si tu fais toi-même les calculs statistiques/probabilistes de débruitage de l'image sur une machine distante, la machine distante ne sera vraisemblablement pas coupable de contrefaçon juste parce qu'elle t'a fourni une calculatrice en ligne. Mais là, c'est bien Midjourney qui choisit, seul, de faire les calculs aboutissant au résultat. A priori sans même que tu lui ais donné l'ordre d'arriver à un résultat contrefait (le prompt utilisé étant beaucoup plus générique que cela). Ça va être difficile d'invoquer une "jurisprudence SaaS" dans ce contexte àmha.
Modifié le 08/01/2024 à 13h34
Le 04/01/2024 à 14h12
Le 04/01/2024 à 15h38
Le 04/01/2024 à 15h42
Et oui, il y a du vécu pour un artiste, mais pas seulement basé sur des œuvres, mais ces rencontres, les environnements qu'il a traversés, les problèmes qu'il y a eu. L'IA ne se base que sur des images sans contextes qu'on lui a fait bouffer.
Perso, quand je vois une illustration faite par IA je vois tout de suite ce qui cloche : des dessins toujours imparfaits, car elle fait qu'imiter sans comprendre. Quand tu lui demandes de faire un kimino fleuri, les fleurs ne seront qu'un semblant de fleur de loin. La composition est bancale. Les jointures sont bizarres. Les formes ne suivent pas toujours. Il lui manque juste un semblant de logique et comprendre ce qu'elle fait. On y est pas encore. Ça se voit moins quand on lui demande de style comme l’impressionnisme où ces défauts font presque partie du style.
Le 04/01/2024 à 19h55
Le 04/01/2024 à 17h49
Dessiner dans le style de Peyo, ça peut se considérer comme une simple inspiration, jusqu'à un certain stade du moins. Dessiner des Schtroumpfs, c'est du plagiat. Alors si tu le fais pour toi pour l'accrocher dans ta chambre ça pose pas de soucis, mais si tu le fais dans un contexte commercial pour vendre le résultat tu vas te faire taper sur les doigts et c'est compréhensible.
Le 04/01/2024 à 19h18
C'est très clair dans leurs ToS : https://docs.midjourney.com/docs/terms-of-service
Ils disent clairement que les créations que tu as générées t'appartiennent.
Ils sont très clairs aussi sur le fait que c'est à toi de faire attention à certains points dans leur guidelines. En particulier, c'est à toi de voir si tu utilises une image pour toi-même (usage privé du copiste) ou si tu peux la diffuser au public (ce qui signifie que tu as des droits dessus).
Ce que je dis n'est pas incompatible avec le fait qu'ils aient peut-être eux-mêmes violés une propriété intellectuelle dans leur processus d'entraînement si les images sorties sont trop proches d'images appartenant à d'autres, mais cela reste à démontrer. Ce sera probablement un juge qui tranchera ce sujet et suivant le pays, la décision ne sera pas forcément la même. Et il y a des cas où l'utilisation d'une œuvre dont on n'a pas les droits est licite, là encore, c'est variable suivant le pays.
Par exemple, Next a le droit de publier des images potentiellement sous droit d'auteur comme ici pour illustrer son information.
Le 04/01/2024 à 20h56
Pas sûr que le disclaimer "non mais l'image appartient au commanditaire" suffise à convaincre un juge, d'autant qu'en pratique, aux US au moins, il semble que l'image n'appartienne en fait à personne : d'après la jurisprudence américaine, une image générée par IA ne peut pas être copyrightée.
Le 05/01/2024 à 11h17
Le 05/01/2024 à 12h50
Le 10/01/2024 à 18h47
Le 10/01/2024 à 19h33
En plus, je ne suis pas sûr de ce que tu affirmes. S'ils ont le statut d'hébergeur (je ne sais pas dire si c'est le cas), ils ne sont responsable pénalement que s'ils ne réagissent pas quand on leur indique que l'œuvre appartient à quelqu'un d'autre que celui qui leur a soumise.
Le 17/01/2024 à 05h32
Modifié le 04/01/2024 à 19h26
On en revient au débat de l'utilisation de sample en musique.
Raisonnement non satisfaisant car privilégiant le droit d'auteur, au sens d'aujourd'hui, à la création.
Le 04/01/2024 à 14h50
C'est alors l'utilisateur qui décide d'utiliser un contenu sous copyright.
Le 04/01/2024 à 15h44
Il faut que t'ailles vérifier à chaque image générée....
Le 04/01/2024 à 17h14
Le 04/01/2024 à 18h18
Le 04/01/2024 à 19h09
La date et l'heure de parution de l'original et de la mise à jour devrait apparaître dans le header de l'article.
Le 04/01/2024 à 17h29
Je pense que ceux qui font ça sont le même genre de personne que ceux qui font des fanart, partagé allégrement entre autre sur derpibooru. Hasbro s'est montré laxiste sur ce sujet (pour le mieux, d'a mon opinion)
Je vais regarder ce qu'il est possible d'obtenir avec SDXL-Turbo, l'un des seuls générateur qui tourne résonablement bien sur mon PC tout en ayant des résultat de bonne qualité. En particulier avec la méthode de l'inversion CLIP, mentionné dans une présentation du 37c3 de fin décembre.
Le 04/01/2024 à 18h24
Nintendo s'en fiche que j'aie généré Mario qui joue du trombone sous stable-diffusion pour rigoler et mettre sur mon blog "J'aime les chiptunes". Mais si je commence à vouloir en faire des magnets que je vends sur un stand à Japan-Expo là ça va potentiellement gueuler.
Midjourney et cie. sont par nature commerciaux. Leur utilisation est payante. Pour stable-diffusion je pense que c'est surtout la crainte que certains s'en servent pour des plagiats à usage commercial.
Le 04/01/2024 à 20h50
Le 05/01/2024 à 08h46
Modifié le 05/01/2024 à 09h30
On pourrait rapprocher Midjourney d'une entreprise louant des photocopieurs. Cela permet la (re)production d'oeuvres protégées.
Pour les photocopieurs, la situation est simple : un photocopieur fait ce que l'utilisateur lui dit. C'est l'utilisateur qui est 100% responsable de ce qui est produit, et il ne viendrait à personne aujourd'hui de mettre en cause les loueurs ou vendeurs de photocopieurs de piratage (alors que cela le permet, notamment en ce qui concerne les livres).
Pour midjourney et assimilé, la situation est plus complexe. Car l'utilisateur dit ce qu'il veut, mais les IA génératives font la grande partie du boulot. L'utilisateur n'est plus responsable à 100%. Pire, un utilisateur qui ferait attention pourrait malgré tout se retrouver à être en situation de violation de droit à l"insu de son plein gré".
Je m'arrête là pour l'analogie.
A noter également que l'on parle de 2 types de violations de droits différents :
- lors de l'entrainement : ce n'est pas parce que c'est visionable sur internet (gratuitement ou non) que c'est open bar pour une utilisation par les IA.
- lors de la génération / diffusion
Dans certains commentaires, certains confondent un peu les deux aspects, ce qui peut entrainer quiproquo et incompréhension.
Et si on devait refaire une analogie, pour la phase entrainement, je prendrais les droits voisins pour les moteurs de recherche. Les articles de journaux sont disponibles, et pourtant, en France et en Europe (entre autre, mais je sais qu'il y a d'autres pays qui légifère la dessus), les moteurs de recherche comme Google doivent trouver un accord avec les journaux pour faire apparaitre les articles dans leur résultat de recherche. Certains ont décidé de payer, d'autre de retirer ces résultats de leur recherche. Bien évidemment, c'est une analogie avec ses limitations, mais qui n'est pas sans rappeler pourtant certains aspects.
En guise de conclusion, je pense qu'on est dans une zone grise actuellement, par rapport aux différentes législations. Les IA génératrices, c'est récent. Il n'y a ne serait-ce que 5 ans, c'était quelque chose qui n'existait pas (en tout cas, pas avec les résultats d'aujourd'hui et pas pour le grand public).
Se pose aussi la question des oeuvres "modifiées". A partir de quel moment considère-t-on qu'une oeuvre est une oeuvre dérivée ou une nouvelle création ? La photo du Joker qui illustre l'article montre bien le problème. Car la tendance sur le net (et l'esprit du net), est d'autoriser les nouvelles oeuvres sans droit d'auteur pour les artistes dont on s'inspire du style (je me limite bien aux droits d'auteur et j'exclue donc les droits moraux pour la réutilisation d'un personnage par exemple). Mais on ne fait pas n'importe quoi avec les oeuvres protégées (pas de partage sans l'accord de l'auteur, ni citation généralement)
Il y a de nombreux aspects à étudier et à trancher avec l'avènement des IA génératives. Cela risque d'être assez "flokorique", dans le sens où chaque pays fera sans doute plus ou moins "à sa sauce", et donc on (= ceux qui seront concernés) devrait faire avec ce joli imbroglio juridique, sans compter les risques de procès le temps de l'évolution des législations et de l'établissement de jurisprudence...
[edit] Il faudrait aussi, à mon sens, prendre en compte le % de contenu généré en violation du droit d'auteur :
- % lorsque l'utilisateur demande manifestement un contenu en violation
- % lorsque l'utilisateur n'a rien demandé mais que le contenu généré est en violation
Ce serait 2 indicateurs très intéressant à avoir. Un premier à 5% par exemple signifierait que l'IA génératrice est capable de bloquer 95% des requêtes "manifestement illicites". Un second à 0,002% serait bien différent d'un second à 10% par exemple. C'est important de ne pas se focaliser sur juste le contenu en violation, mais bien tout le contenu pour se faire une idée de la "responsabilité" de l'IA génératrice.
Le 05/01/2024 à 09h23
Le 05/01/2024 à 11h50
La Mise à Jour porte sur quoi ?
Le 05/01/2024 à 13h18
Flock nous a fait un montage très drôle :-)
Cependant, la photo de fond, les photos de portraits le "design" des tubes tout les éléments sont des éléments sous "copyright" à la base. Et la seul mention est la suivant : "Photomontage par Flock d’Einstein et Planck présentant des produits cosmétiques"
Heureusement le droit français laisse le droit de citation et de caricature. Si ce montage avait été rendu par une "IA générative" qu'est-ce qui aurait été dit ?
Le 05/01/2024 à 15h32
Le 08/01/2024 à 11h07
Sans image de comparaison, c'est difficile de répondre à cette question. Voici une image de Wall-E sur le site disney.fr (Pixar a été racheté par Disney en 2006) : https://newsroom.disney.fr/photos/wall-e-jpg-25f5-dc71f.html
En comparant les 2 images, on voit que :
- les bras sont très différents ;
- les chenilles aussi au moins pour les"roues" à l'intérieur des chenilles ;
- l'inscription WALL E est transformée en un truc illisible ;
- la tête/les yeux ont des différences mais sont plus proches que des bras ;
- la carrosserie est assez différente aussi dans les détails, même si ça ressemble globalement.
En fait, je ne sais pas si c'est une contrefaçon ou une inspiration du vrai WALL-E ou bien une inspiration d'un jouet (ou d'une image) lui-même inspiré de WALL-E (on trouve plein de fausses images de Wall-e sur Google image, toutes assez ressemblante).
Là, la ressemblance est bien plus forte que pour Wall-E. Il en est de même pour le dinosaure à droite de l'image.
Par contre, à quoi correspondent les deux personnages de gauche ? Est-ce que ce sont eux aussi des personnages de Toy Story ? Ma connaissance de cette série de films est trop faible pour répondre à la question. Je n'ai vu que le premier il y a très longtemps.
Et si je demande à Google de me retrouver des images proches, j'ai des résultats probants pour les 3 personnages de droite mais je ne tombe sur rien de ressemblant pour les 2 de gauche. Les grosses oreilles roses me font retomber sur l'univers Monsieur Patate, mais ces personnages ne semblent pas venir de là.
Si les lecteurs peuvent m'indiquer d'où viennent ces personnages, ça serait intéressant pour discuter de la seconde image.
Modifié le 10/01/2024 à 18h58
Voir, dans un domaine tangent, ce jugement de la cour de cassation : https://www.nomosparis.com/la-contrefacon-sapprecie-au-regard-des-ressemblances-entre-les-oeuvres-et-non-des-differences/
EDIT: Help comment on fait des liens dans le nouvel éditeur.
Modifié le 08/01/2024 à 12h30
animated toy.Les résultats ont été intéressants et vous pouvez les télécharger ici : https://www.swisstransfer.com/d/8ec68a70-da79-4668-9496-e0ab2def5de2 (attention, limité à 250 téléchargements - si la rédaction le souhaite je peux vous envoyer directement les images)
J'ai exécuté en tous 6 batches avec deux modèles à chaque fois : SDXL 1.0 (le modèle de base fourni par Stability AI et entraîné par un dataset fermé fourni par l'organisation à but non lucratif allemande LAION), et CopaxTimless 1.8 qui est mon chouchou du moment. Ce dernier est un checkpoint entraîné à partir du base model de SDXL 1.0.
Dans cette archive, 6 dossiers nommés de la manière suivante :
{used prompt} - {used model}J'ai laissé tous mes paramètres usuels en matière de CFG et Steps. Pour info j'utilise le front InvokeAI
Le résultat obtenu est le suivant :
- animated toy - copax-1.8 : Ici, aucun résultat sous copyright, en tous cas à ma connaissance, pas de personnage de Toy Story ou WALL-E obtenu par mégarde.
- animated toy - sdxl-1.0 : Même chose
Voulant savoir si les deux modèles avaient bel et bien connaissance des personnages de Toy Story ou de WALL-E, j'ai donc lancé des nouveaux lots demandant explicitement cette IP.
- toy story characters - copax-1.8 : Pas de doutes, des images des personnes de Toy Story ont bien fait partie de l'entraînement du modèle car il en a parfaitement la connaissance.
- toy story characters - sdxl-1.0 : Encore mieux, il a quasiment créé une affiche du film et on lit de manière quasi distincte "Disney" (parmi les améliorations de SDXL avaient notamment l'écriture qui était dégueulasse avant). Par contre il ne s'agit pas de l'affiche officielle.
- wall-e robot - copax-1.8 : Ici, le modèle connaît bien le personnage de WALL-E et a su le reproduire moyennant de nombreuses imperfections cela dit.
- wall-e robot - sdxl-1.0 : Même chose sur SDXL
A noter que dans toutes ces images, il y a des personnages qui ne me semblent pas issus de l'univers Toy Story, ce sont probablement des résultats aléatoires imitant le style.
Vous pouvez extraire de tous les PNG les paramètres utilisés sur SD incluant le prompt, ils sont dans les metadata. Sous Linux, la commence
identify -verbosefait le taff.Exemple :
Properties:
date:create: 2024-01-08T08:25:02+00:00
date:modify: 2024-01-06T20:41:55+00:00
date:timestamp: 2024-01-08T11:27:51+00:00
invokeai_metadata: {"generation_mode":"sdxl_txt2img","positive_prompt":"animated toy","negative_prompt":"","width":704,"height":1152,"seed":1161674508,"rand_device":"cpu","cfg_scale":5.5,"steps":50,"scheduler":"dpmpp_2m_sde_k","model":{"model_name":"copaxTimelessxlSDXL1_v8","base_model":"sdxl","model_type":"main"},"vae":{"model_name":"sdxl-1-0-vae-fix","base_model":"sdxl"},"positive_style_prompt":"","negative_style_prompt":""}
Mon impression à chaud est que Midjourney est probablement moins ou trop bien conditionné par rapport à Stable Diffusion. Il génère par inadvertance des choses très spécifiques (ici les personnages de films d'animation via un prompt très générique) ce qui me donne l'idée que les conditions pour le text-to-image sont probablement trop génériques ou alors il a du recevoir un fine-tuning un peu trop orienté. Après c'est de la pure spéculation, et je n'ai pas la prétention de connaître sur le bout des doigts les rouages internes, surtout que Midjourney est complètement fermé là où Stable Diffusion est open source, et mieux documenté sur le Web, malgré le dataset d'entraînement des Base Models non communiqué.
Modifié le 08/01/2024 à 13h23
Comme les téléchargements sont limités, je me suis permis de repartager les infos sur mon instance de Lufi (logiciel open source de partage de fichier). Le lien est disponible ici et valable 1 an : https://file.custom-dev.fr/r/wespF3pM9A#VBrpAO4tyu8J8D7Hh3lgJy2zIDIHSfyvr41Yuk8uGX0=
Mais si cela te pose problème, pas de souci, je peux procéder à sa suppression immédiate.
Le 08/01/2024 à 13h26
Modifié le 08/01/2024 à 13h40
D'abord, il utiliser le tokenizer CLIP développé par OpenAI pour transformer les mots en séquences numériques que l'ordinateur peut lire.
Ensuite, il utilise les embeddings (là aussi issu d'OpenAI) qui permettent de détecter les similarités entre les mots (ex : "une femme qui..", "une madame qui...", deux mots qui veulent dire la même chose de son point de vue).
Enfin, il y a le mécanisme d'attention croisée (Cross Attention) qui permet de faire le lien entre des termes qui se qualifient pour décrire la scène voulue (ex : "des yeux bleus", il associera bien l'objet - yeux - et la couleur - bleus - pour éviter d'avoir une chemise bleue, mais ça peut quand même arriver).
Donc, toujours plus ou moins à chaud et de manière toujours autant spéculative sur Midjourney, il a probablement du faire une interprétation trop générique ou large de "animated toys" selon comment le prompt est traité par le modèle et c'est tombé dans les embranchements qui ont du relier "animated" et "toy" à Toys Story (si je voulais le décrire en anglais, je dirais "an animated movie about toys"), et dans le cas de WALL-E probablement des qualificatifs du dataset relatifs aux jouets dérivés du film.
Modifié le 08/01/2024 à 21h04
Mais bordel que les différents résultats me mettent mal à l'aise... ça me met limite la chaire de poule... C'est limite malsain !
Le 08/01/2024 à 22h10
Je n'ose pas utiliser cet outil sur ma machine de jeux actuelle (une RTX 2070 avec 16GB RAM et un Ryzen 7) de peur d'user ou abîmer la config, ça reste des systèmes encore très perfectibles et j'ai pas envie de cramer une bécane achetée avec les tarifs de 2021...
C'est là l'atout majeur de Stable Diffusion d'ailleurs : il est conçu pour tourner sur du GPU haut de gamme type "consumer" - une config de gamer en gros. Pas besoin d'une ferme de ouf type mineur de bitcoin comme OpenAI exploite chez Azure car il est optimisé pour réduire sa conso. Sur Civitai plusieurs producteurs de modèles donnent d'ailleurs des statistiques de coût d'entraînement. Je crois de mémoire que le modèle que j'aime beaucoup a coûté environ $200 à entraîner. Ce qui est que dalle quand tu compares par exemple au service Azure OpenAI dont l'heure d'entraînement d'un modèle coûte $90.
Avec plus de performances, les résultats peuvent être bien meilleurs grâce à quelques LoRA spécialisés qui corrigent les ratés du modèle de base, des ControlNet, etc. Hélas, dans mon cas, si j'ajoute plus d'un LoRA avec SDXL, OOM Killer dégaine rapidement. Avec SD 1.0 ça passe du tonnerre par contre.
Mais si j'osais une comparaison, je te dirais que quand je fais une session de génération d'images, c'est comme quand je prend en photo un feu d'artifice du 14 juillet. Je repars avec 500 clichés, j'en trash 70%. La génération d'image, c'est pareil pour moi. Parfois l'inpainting ou lui faire retravailler la production à partir de la seed d'une image dont la composition me plait, mais défectueuse niveau rendu, peut donner de meilleurs résultats. Cela dit, s'pas toujours gagné.
Clairement, je trie majoritairement le bon grain de l'ivraie. Quand je tente de produire une couverture pour un livre, j'arrive en général à en garder 3 ou 4 sur une centaine d'itérations. Ce nombre est aussi causé par le fait que je modifie le prompt au fil des générations, donc la file continue de dépiler pendant ce temps et ça tourne par lot de 9 à chaque fois. Je pourrais lui dire de faire un par un, mais la nature même de l'IA générative fait qu'il faut lui la laisser itérer plusieurs fois. On peut avoir de sacrés surprises.
Le 08/01/2024 à 13h55
Lui demander de représenter un gundam en train de faire de la barre fixe (gym) -> en gym il ne connaît que la poutre, qui ici est une discipline féminine. Je n'ai jamais réussi à lui faire sortir un exemple en barre fixe. Des plantages, oui :)
Le 08/01/2024 à 20h42
Le 09/01/2024 à 10h32
Le point 1 est de la com.
Le point 2 correspond assez à ce que je disais sur le sujet : dans l'état des lois actuelles sur la propriété intellectuelle / copyright, l'utilisation de données librement accessibles sur le net semble légale. Les détenteurs de droits peuvent s'opposer à l'utilisation des données ce que permet OpenAI.
Le point 3 laisse supposer que la mémorisation de source est un bug. L'explication me semble plausible : ça apparaît surtout quand le contenu est répété dans les données d'entraînement. Ils travaillent à la correction de cela. Je disais dans un autre commentaire ici (https://next.ink/121934/midjourney-pixar-coca-cola-jef-aerosol-c215-droits-auteurs-copyrigh/#comm-13.19), que ça semblait être un problème à corriger. Il a l'air d'être identifié, une piste trouvée et ils veulent effectivement le corriger. Ça peut aussi expliquer les remontées de l'article que nous commentons.
Le point 4 apporte aussi des informations. Tout d'abord, la régurgitation d'articles du NYT serait surtout sur de vieux articles qui sont disponibles sur de nombreux sites tiers, et comme vu au point 3, cela favorise la mémorisation.
En plus, le NYT aurait travaillé les prompts pour provoquer la régurgitation de ses articles, en particulier en incluant de longs extraits de ses articles et en plus, ils n'ont choisi que des exemples où la régurgitation a réussi. Rien de surprenant de la part d'une des parties au procès.
C'est pour cela que j'insiste sur les prompts sous les articles parlant de ces problèmes : sans les prompts (et la fréquence d'apparition des problèmes maintenant que j'y pense), l'information qui nous est apportée est faible.
On y apprend aussi qu'ils travaillent à bloquer cette régurgitation. Là, je trouve que c'est cacher la poussière sous le tapis. Ça se comprend en terme de protection contre des procès, mais c'est un pis-aller : la vraie solution est de supprimer la mémorisation qui est un phénomène non voulu.
Le 09/01/2024 à 12h11
Pour le coup, c'est même le seul truc qui n'est pas opaque !! Sur ChatGPT il suffit d'utiliser le lien de partage, ou de le screenshot au besoin. Midjourney aucune idée, mais dans la mesure où c'est un serveur discord, ça se sauvegarde aussi.
D'ailleurs, quelqu'un a déjà vérifié si les paramètres du modèle étaient disponibles en metadata dans l'image produite ?
Modifié le 10/01/2024 à 13h49
Une explication du fonctionnement interne de Discord qui lui permet de tenir la charge face à la très grosse communauté engendrée par Midjourney.