Le document concerné a fait l’objet d’un commit dès le 6 janvier dernier, mais c’est ce samedi 11 avril qu’il a émergé sur Hacker News : le dépôt administré par Linus Torvalds et dédié au noyau Linux comporte désormais un fichier coding-assistants.rst qui résume les bonnes pratiques à adopter en matière de recours à l’IA générative dans les contributions.
Ceux qui attendaient soit un blanc-seing, soit une condamnation sans équivoque, en seront pour leurs frais. Ces lignes de conduite ne tranchent pas la question polémique du bien-fondé : elles disposent simplement que le code qui a été produit avec l’assistance de l’IA obéit aux mêmes règles que le code d’extraction exclusivement humaine, et que tout code soumis doit être signé (et donc endossé) par un humain.
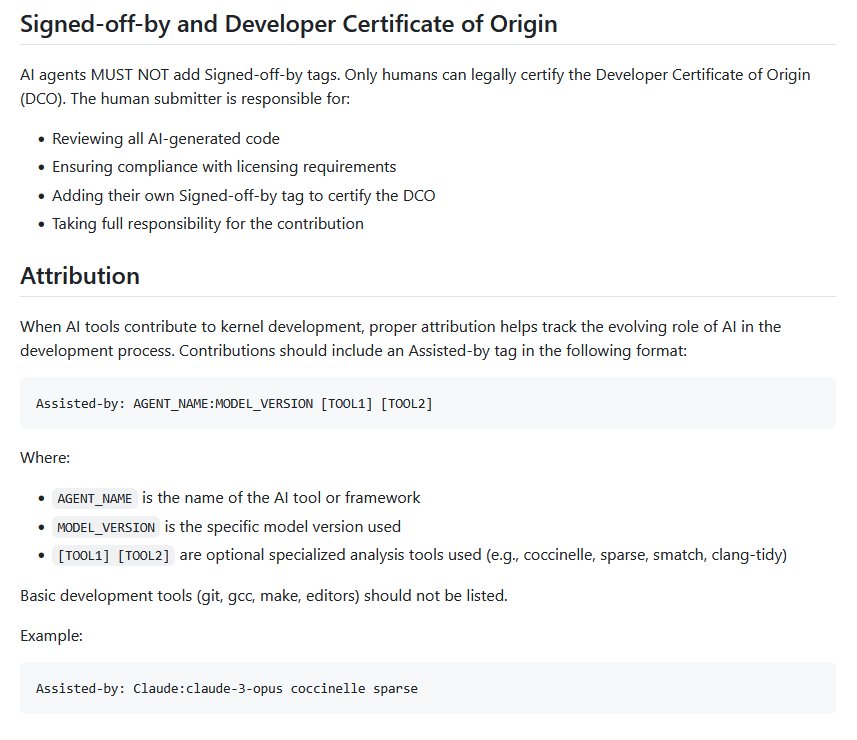
« Seuls les humains peuvent légalement certifier le certificat d’origine du développeur (DCO) », indique le document, selon lequel le développeur assume l’entière responsabilité de sa contribution, et doit donc de ce fait attacher une attention particulière à la vérification de tout code généré par IA, ainsi qu’à la conformité aux exigences de licence, en l’occurrence la GPL 2.0.
La mention explicite du recours à l’IA est encouragée. « Lorsque les outils d’IA contribuent au développement du noyau, une attribution appropriée permet de suivre l’évolution du rôle de l’IA dans le processus de développement ».
« C’est… étonnamment normal ? », réagit un internaute sur Hacker News. La position, qui semble effectivement plutôt consensuelle, rejoint l’attitude manifestée publiquement par Linus Torvalds quant à l’utilisation de l’IA générative dans le code.
Il s’était exprimé sur le sujet fin 2025 à l’occasion de l’édition japonaise de l’Open Source Summit, expliquant détester la hype autour de l’IA, mais reconnaître à l’outil de réelles qualités, notamment pour la maintenance du code. Le créateur de Linux et de Git a lui-même eu recours à la pratique dite du vibe-coding pour un projet tiers (AudioNoise, voir mention explicite en fin de Readme).
Commentaires (13)
Abonnez-vous pour prendre part au débat
Déjà abonné ou lecteur ? Se connecter
Cet article est en accès libre, mais il est le produit d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles d'un média expert
Profitez d'au moins 1 To de stockage pour vos sauvegardes
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousModifié le 13 avril à 09h42
En clair, pour tout ce qui est critique, la compréhension, expertise, et revue humaine est indispensable, que ce soit le noyau Linux ou tout le reste.
J'espère qu'un jour les gens comprendront que codex, claude, kimi, qwen & cie doivent être pris pour des stagiaires dans l'utilisation qui en est faite pour le moment et que polémiquer dessus ne sert à rien sinon brasser de l'air, le problème étant HUMAIN. (Ce n'est pas l'IA qui gère les entreprises qui font des choix merdiques en matière d'embauche de juniors, par exemple.)
Pour autant ils ne sont pas à jeter pour autant et peuvent être ponctuellement très efficaces lorsque bien guidé et que l'alignement avec vos intentions est atteint.
Même pour des choses aussi basiques que du script bash, de l'empaquetage, ça peut être très utile et un vrai gain de temps de travail tout en étant facile à relire.
Ps : et je me répète et je signe à ce sujet, les LLM sont des amplificateurs, le curieux progressera, le flemmard périclitera.
Je n'ai jamais autant appris que depuis que j'y touche. J'ai un TDA (trouble du déficit de l'attention) qui m'a pourrit la vie toute ma scolarité et après avec de grosses difficultés d'apprentissage, et, j'ai passé des années depuis mon adolescence à écumer les forums, lire des infos et retours, et je n'ai jamais autant progressé que depuis que je touche aux LLM.
Ces dernier ont un potentiel fantastique pour tous ceux qui ne sont pas neurotypiques et n'alimentent pas leur paresse intellectuelle.
Le 13 avril à 10h58
Mais à mon avis le problème principal de l'IA est qu'elle ne dira jamais "Je ne sais pas, débrouilles-toi".
Quand elle est mise dans une situation où elle ne trouve plus d'existant pertinent, elle va commencer à inventer, halluciner. J'ai vécu ça sur du debug kernel linux sur des points précis, mais aussi sur des commandes en CLI de proxmox où elle m'a sorti des trucs qui existaient pas et n'ont jamais existé.
A un moment, il faut savoir trouver le moment où il faut lâcher l'IA et retourner lire le code, la conf ou autre et ...bah faire soit-même.
D'ailleurs une question que je me pose: Actuellement, l'IA est utilisé pour faire des fichiers de conf & du code (pour moi). Mais à un moment, qu'est-ce qui va empêcher un agent de prendre un prompt & de sortir un binaire, voire une micro-VM complète prête à lancer avec tout le code binaire dedans, complètement obfusqué.
Par exemple pour un site web , on peux imaginer l'IA pondre une VM purement binaire, sans Apache/Nginx, sans linux & autres SSH à configurer, juste la VM & le site statique avec aucune dépendance à aucun code tiers (en tous cas officiellement).
L'étape du "langage interprété" ou même compilé c'est une facilité humaine, mais est-ce que l'IA en a vraiment besoin ?
Et pour le modifier, facile, on re-demande à l'IA de re-fabriquer la VM entière avec nos modifs.
=> Avec ça plus besoin de chef de projets, de prestataires, de codeurs, rien. Le "client" pourra créer son site web tout seul par itérations, il faut juste qu'il sache lancer une VM sur un hyperviseur.
Perso j'aimerais pas vivre dans ce type de monde mais dès à présent ça parait presque faisable techniquement, non ?
Le 13 avril à 12h01
Le 14 avril à 16h34
Le 13 avril à 11h21
Ça donne l'illusion de facilité, mais si on creuse un peu, on se rend souvent compte que ça reste un outil à utiliser avec précaution, pas de miracles.
En tout cas, c'est vraiment fascinant, quand je voie des projets comme Caveman pour économiser des tokens, on a encore énormément de chose à découvrir et à apprendre. Beaucoup de de potentiel en bon comme en mauvais.
Le 13 avril à 11h58
Le vrai débat qui fait polémique est le moment où tu laisses l'IA prendre elle même les décisions. Par ex accepter les merge request automatiquement faites par un agent IA. AMHA, à ce moment, l'humain perd le contrôle, le code gagne en complexité tellement vite que plus aucun humain ne pourra le comprendre, et donc fin de partie pour l'être humain.
Donc comme ces clarifications de règles, oui aux nouveaux outils, mais en contrôlant leur usage.
Le 16 avril à 23h08
Le "compromis infini" et son nivellement par le bas.
Le 17 avril à 09h37
L'IA n'ayant pas encore démontré sa capacité à auto-évaluer ses compétences (tournure de phrase politiquement correcte pour dire "se trouve sur le pic «prétentieux-petit-con» du graphique que la légende attribue à Dunning Kruger") ça ne s'appelle pas du nivellement par le bas, mais simplement du bon sens.
Le 13 avril à 09h41
Si usage de l'IA il y a; est-ce que l'auteur reste légalement le propriétaire du code produit par l'IA. A plus forte raison parce que cela vient d'un autre (ou inspiré par). L'œuvre de l'esprit doit être produite par un humain par définition. Ça risque d'être compliqué.
Avec des trucs comme ça dans l'actu plus ou moins récente :
(cela ne parle pas du code spécifiquement mais ce sont les même principes)
Modifié le 13 avril à 09h47
En outre, le code est supposément revu par un être-humain qui va le diriger et y mettre son grain de sel, et de toute façon derrière le LLM ne fait rien seul, c'est l'Humain qui engage l'action et a une vision globale patiemment décrite du projet concerné par ledit code. Ça reste une œuvre de l'esprit humain, le LLM n'est qu'un outil comme un autre. Des outils automatisent largement le développement également comme sur Unreal Engine, pourtant la paternité du code source ne pose aucunement question.
Le 13 avril à 10h51
En plus, l'article de loi cité dispose que :Ce n'est pas forcément applicable à du code qui à mon avis ne rentre pas dans la catégorie literary work.
Il y a la première question de l'œuvre de l'esprit et de l'IA qui fait que suivant les pays, c'est une œuvre pouvant être protégée ou non.
Le code produit pourrait donc être sans licence possible (même pas GPL V2). Est-ce que ce code est compatible avec la GPL V2, ? Il faudrait trancher officiellement. J'aurais tendance à dire oui dans l'esprit : n'étant pas protégé, il correspond à toutes les clauses, mais sans licence sur ce code, rien n'obligerait à le redistribuer ! C'est un paradoxe.
La seconde question est celle d'un code qui serait une contrefaçon de code existant qui ne serait pas sous une licence compatible GPL V2 parce qu'il ressortirait un code protégé. C'est ici un risque d'inclure un tel code dans du logiciel GPL V2 et ça semble difficile pour un humain de détecter ce cas.
Le 13 avril à 12h08
Haaaaaa, je voulais pas casser le moral, mais bon...
Le 13 avril à 10h16
Dans les équipes avec lesquelles je travaille, j'essaie de les sensibiliser et des les amener à prendre un peu de recul et de méthodologie dans leur usage de l'IA pour produire du code :
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?