

Mozilla industrialise la chasse aux bugs dans Firefox avec l’IA
Firefox sous perfusion de Mythos

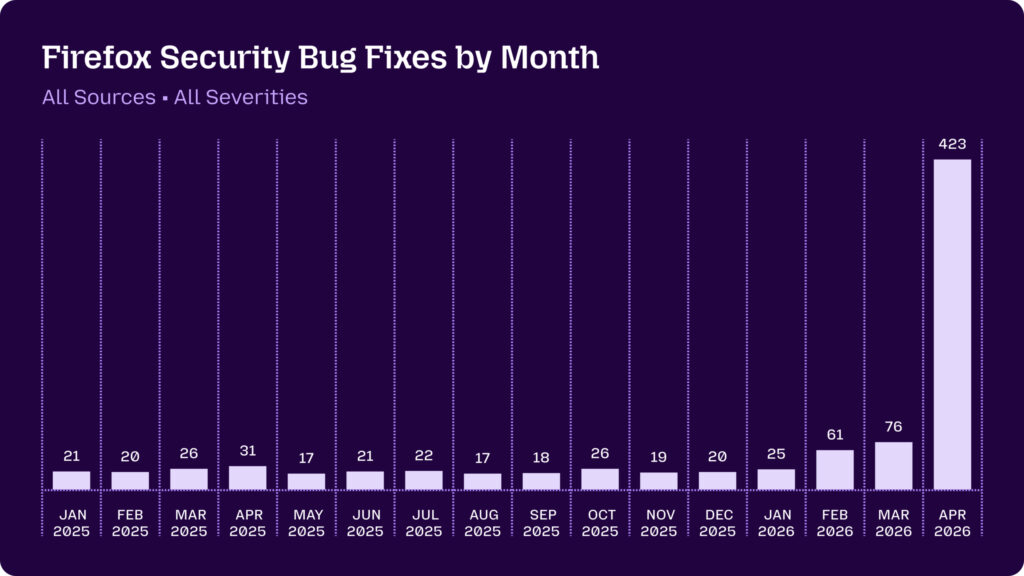
Firefox sert désormais de laboratoire grandeur nature pour éprouver de nouveaux outils de cybersécurité assistés par IA. En avril, Mozilla a corrigé la bagatelle de 423 vulnérabilités, la majorité ayant été débusquée par Mythos.
Mozilla ne tarit décidément pas d’éloges sur les capacités de Mythos à détecter des bugs et des failles de sécurité dans Firefox. En avril, des correctifs ont permis de corriger 423 vulnérabilités : les 271 bugs dans Firefox 150 déjà annoncés qui proviennent des analyses de Mythos, plus 41 bugs signalés par des chercheurs externes, et 111 découverts en interne avec d’autres méthodes. À comparer avec les 76 correctifs du mois de mars.
Une chose a changé dans l’utilisation des LLM par les développeurs de Firefox. Les tests réalisés ces dernières années avec GPT-4 ou Sonnet 3.5 s’avéraient certes prometteurs, mais au bout du compte « le taux élevé de faux positifs les rendait impraticables à grande échelle », écrivent Brian Grinstead, Christian Holler et Frederik Braun de Mozilla. Le mode opératoire était relativement classique : demander au modèle d’analyser du code jugé sensible pour repérer d’éventuelles vulnérabilités.
Des agents qui traquent les bugs
Les modèles agentiques ont changé la donne, soulignent-ils : « Ces systèmes peuvent trouver de véritables bugs et écarter les hypothèses impossibles à reproduire ». Claude Opus 4.6 a permis de mettre au point un « harnais agentique » qui interagit avec l’environnement de développement : il peut exécuter du code, vérifier si la faille existe réellement et générer des cas de test qu’il est possible de reproduire.
En substance, le LLM formule une hypothèse et tente lui-même de la valider. De quoi identifier « une quantité impressionnante de vulnérabilités jusque-là inconnues ». Les ingénieurs de Mozilla ont affiné et ajusté le comportement du modèle, et lorsque les résultats ont été jugés suffisamment bons, ils ont parallélisé les tâches sur plusieurs machines virtuelles éphémères.
Le LLM n’est qu’une partie de ce Meccano de sécurité. L’infrastructure au complet inclut aussi la gestion du cycle de vie des vulnérabilités : orchestration, validation, triage, intégration avec d’autres outils internes. Ce « harnais », qui reste très spécifique au projet, peut ensuite fonctionner avec d’autres LLM, comme l’aperçu de Mythos. « Le système devient simultanément meilleur pour repérer des bugs potentiels, créer des cas de test de preuve de concept pour les démontrer, et expliquer précisément leur mécanisme ainsi que leur impact », indique Mozilla.
Ce travail de fond pour créer un pipeline autour des modèles de langage et les capacités accrues de ces derniers ont permis d’accélérer la détection et le développement de correctifs. « Il y a encore quelques mois, les rapports de bugs de sécurité générés par IA envoyés aux projets open source étaient surtout connus pour être du bruit inutile », rappellent les ingénieurs. Trier le bon grain de l’ivraie était chronophage : « il est simple et peu coûteux de demander à un LLM de trouver un « problème » dans du code, mais il est long et coûteux de vérifier puis de répondre à ces signalements. »
Tout a changé avec les nouveaux LLM plus puissants, et l’amélioration des techniques permettant d’exploiter ces modèles. C’est un cas d’usage spécifique pour Firefox qui peut ne pas s’adapter à d’autres organisations.
L’IA n’écrit pas les correctifs
Brian Grinstead apporte un éclairage intéressant chez TechCrunch. Si l’équipe de Firefox utilise les LLM pour repérer des failles, les correctifs sont toujours écrits par des humains malgré les progrès des outils de développement assistés par IA. « Pour les bugs dont nous parlons dans ce billet, chaque correctif a été écrit par un ingénieur puis relu par un autre », explique-t-il.
Les développeurs demandent tout de même à l’IA de proposer des correctifs pour chaque bug, mais le code qu’elle produit ne peut pas être déployé tel quel. Il sert surtout de base de travail, car « nous n’avons pas constaté que cela pouvait être automatisé ».
Mozilla est suffisamment confiant pour partager 12 bugs corrigés sans attendre les plusieurs mois habituels avant une divulgation publique, « compte tenu du niveau d’intérêt extraordinaire suscité par ce sujet et de l’urgence des mesures à prendre dans l’ensemble de l’écosystème logiciel ». Ces bugs, qui permettent des échappements de sandbox, doivent être combinés à d’autres exploits pour compromettre Firefox.
« Nous n’avons pas encore découvert tous les bugs latents présents dans Firefox, mais nous sommes très satisfaits de la trajectoire actuelle », conclut le billet. La prochaine étape pour Mozilla est d’intégrer le système directement dans la chaîne de développement du navigateur : chaque nouveau correctif envoyé par un développeur pourrait être automatiquement analysé par le pipeline IA, ce qui permettrait de détecter les bugs quasiment au moment où ils sont intégrés dans le code de Firefox.
Sur le sujet de l’impact de l’IA sur le monde de la cybersécurité, illustré notamment par le phénomène médiatique Mythos, voir notre récent dossier :

Commentaires (23)
Abonnez-vous pour prendre part au débat
Déjà abonné ou lecteur ? Se connecter
Cet article est en accès libre, mais il est le produit d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles d'un média expert
Profitez d'au moins 1 To de stockage pour vos sauvegardes
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousModifié le 11 mai à 12h18
l'IAun LLM peut sublimer la compétence, l'intelligence humaine et collective, aussi bien que détruire le flemmard décérébré. C'est un amplificateur.Utilisé en bonne intelligence, l'Open-Source a probablement tout à gagner en la matière.
Et j'ai envie de dire que même le quidam qui produire un POC "sale" parce qu'il aura tout vibecodé et voulait seulement exprimer une vision créative sans avoir toutes les compétences requises, pourra toujours libérer son code et donner envie à des gens compétents de peaufiner un projet unique et original, soit en forkant, soit en reprenant proprement ses grandes lignes.
Le 11 mai à 12h32
Ici Firefox sert de laboratoire, donc il ne doivent payer qu'une infime partie de ce qu'ils devront payer une fois le modèle mise à disposition de tout un chacun.
Le 11 mai à 12h57
Un projet Open-Source n’a pas forcément besoin d’exécuter en permanence des modèles hors de prix pour bénéficier de ces avancées. Il peut utiliser ponctuellement des modèles distants pour certaines tâches critiques, mutualiser les coûts, utiliser des modèles locaux, ou simplement profiter des outils et méthodes qui vont émerger de ces recherches.
Et surtout, il faut comparer le coût à ce qu’il remplace potentiellement, des centaines d’heures humaines de recherche de bugs, d’audit, de reproduction de crashs ou d’analyse de sécurité, bénévoles ou non. Le tout en offrant une sécurité/stabilité accrue pour les utilisateurs finaux, ce qui n'est plus un luxe.
Mozilla montre surtout une direction, celle d'agents capables de vérifier eux-mêmes leurs hypothèses au lieu de produire 95% de faux positifs inutiles comme auparavant.
Mais clairement, oui,, tout le monde ne pourra pas se payer des clusters IA comme Mozilla, mais tout le monde n’a pas non plus les moyens d’avoir une équipe sécurité de haut niveau dédiée à plein temps. Pourtant, les outils, méthodes et connaissances finissent souvent par redescendre progressivement vers l’écosystème Open-Source plus large.
Modifié le 11 mai à 12h46
Ce qui me gène derrière tout ca, c'est qu'on ne connait pas le vrai cout économique.
Je ne parle pas d'emploi.
Je parle de combien en réalité, ça coute d'utiliser les LLM, d'intégrer cela dans la chaine de développement existante et de l'effort humain de correction (je pense que certains ont fait quelques heures sup ce dernier mois).
En un mois ils ont comblé autant que ce qu'ils trouvaient et corrigeaient en presque 2 ans, génial!
Sauf qu'on n'a toujours pas la moindre idée de si c'est rentable.
Si les sociétés de LLM valorisaient correctement le prix de leurs LLM (et non pas des abonnements à 22 dollars le mois).
Par exemple, je dis une bêtise, mais disons que vu l'usage intensif de tokens... si cela avait couté 200 000 dollars dans le mois ? Est-ce que Mozilla l'aurait fait ?
Vont-ils pouvoir le faire et pendant combien de temps, vu qu'un jour ou l'autre il faudra bien que OpenIA & co récupère plus d'argent qu'ils n'en claquent ?
Modifié le 11 mai à 13h07
Une partie de l’économie des LLM repose encore énormément sur l’investissement massif, les levées de fonds et des stratégies de conquête de marché. On ne connaît pas encore vraiment le coût final stabilisé de tout ça à grande échelle.
Il faut aussi comparer ça au coût réel du développement logiciel moderne. (Équipes sécurité, audits, bug bounty, des mois de recherche, incidents, CVE exploitées, correctifs d’urgence, réputation, maintenance...)
Si un pipeline IA permet à Mozilla de détecter massivement des vulnérabilités avant qu’elles ne deviennent des 0-day exploitées, la rentabilité ne se mesure pas seulement en coût GPU/tokens.
L'autre point important, c'est que les coûts des modèles ne sont pas figés, car le matériel évolue, l’inférence devient plus efficace, les modèles locaux progressent vite, les modèles spécialisés coûtent moins cher, et énormément d’optimisations apparaissent déjà.
Il y a 3 ans, faire tourner un modèle capable de raisonner correctement sur du code relevait quasiment du laboratoire. Aujourd’hui, certains devs font déjà tourner localement des modèles très corrects sur une machine perso bien équipée.
Donc oui, il y a une vraie question économique derrière tout ça. Mais je pense qu’on est encore trop tôt dans la transition pour savoir où l’équilibre final se situera réellement.
Et écologiquement, se posera aussi la question des priorités. Un usage sérieux et professionnel à visée sécuritaire pour les développeurs, me semble être une goutte d'eau dans l'océan génératif superflu des utilisateurs lambda qui discutent avec GPT & cie et leurs demandent de générer des images et vidéos "drôles".
Et là dessus, je considère être un pragmatique, c'est comme le pétrole, je déplore le gaspillage/pollution généralisée, mais je comprends la nécessité de brûler du gazole pour restaurer un écosystème dégradé, plus rapidement, quand on hérite de cette situation, pour tendre vers une compensation positive sur le moyen/long terme.
Le 11 mai à 14h30
À mon avis ça a été vrai à une époque. Mais les modèles open source chinois ont montré que c'était pas si vrai que ça. Dans le sens où les gros modèles open source (ceux qui rivalisent avec Claude Opus comme DeepSeek, Kimi ou Qwen) sont disponibles chez pas mal de providers indépendants (souvent des hébergeurs qui ne produisent pas de LLM.
Ces providers indépendants font tourner les modèles sur leur propre matériel et n'ont aucun intérêt à subventionner le coût du token et pourtant en moyenne le token Qwen coûte en moyenne 6 à 10 fois moins cher que le token Opus pour un résultat à peine inférieur (et encore, pour tester les 2, Opus au taf et les modèles open source pour le perso, je vois pas tant de différence).
Modifié le 11 mai à 18h33
Le 12 mai à 14h17
Le 12 mai à 17h08
Il semble donc logique que, si subvention étatique il y a eu, ça aurait été probablement pour financer l'entraînement et non l'inférence.
Le 12 mai à 18h01
Le 11 mai à 12h42
Le 11 mai à 13h14
Le 11 mai à 13h09
Le 11 mai à 13h35
https://daniel.haxx.se/blog/2026/05/11/mythos-finds-a-curl-vulnerability/
Je ne sais pas combien Anthropic a payé Mozilla, mais j'espère que la somme était rondelette vu la pub que Mozilla leur a fait avec ce truc…
Modifié le 11 mai à 14h46
Curl son job c'est d'envoyer quelques bits à un serveur et stocker le retour dans un buffer. Si curl a une gestion sûre de sa mémoire et notamment de son buffer de retour, ça fait déjà 99% de la sécu (et c'est super hein, vu tout ce que permet de faire curl, c'est un résultat formidable).
Firefox son taf du quotidien c'est d’exécuter du code de provenance inconnue en toute sécurité, c'est littéralement ce qu'il y a de plus exigeant et difficile à faire en terme de sécu.
Le 11 mai à 16h19
Le 12 mai à 03h56
Le 12 mai à 08h25
Beaucoup de bugs auraient donc aussi été découverts de cette façon, ce que Mozilla n’a pas l’air d’avoir fait. Et tout ces bugs ne sont pas « critiques » (contrairement à celles trouvées récemment sur le noyau linux).
Bref, coup marketing d’Anthropic qui a l’air d’avoir réussi sa manoeuvre !
Modifié le 11 mai à 15h31
Edit : je parle bien de rapport de bug non généré par IA
Le 12 mai à 11h54
se retrouvent un peu plus éludées.
La finalité du processus sera d'affirmer haut et fort que l'on (doit) s'en fiche(r).
Le 12 mai à 19h54
Le 12 mai à 20h03
Le 12 mai à 20h31
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?