

Victime de son succès, Anthropic a testé de supprimer Claude Code de son abonnement Pro
Claude Pro, mais pas trop pro non plus

Anthropic a un sérieux problème sur les bras : trop d’utilisateurs, pas assez de capacités de calcul. La startup a mis en place des mesures de restriction de l’usage et a testé une limitation des plus sévères : supprimer carrément l’accès de Claude Code aux abonnés Pro.
L’engouement envers Claude Code ne faiblit pas, à tel point que le chiffre d’affaires annualisé devrait dépasser les 30 milliards de dollars. Des revenus record qui propulsent encore plus haut l’intérêt des investisseurs, avec une introduction en Bourse qui devrait intervenir cette année.
Claude Code passe pour certains de Pro à Max
Mais l’attrait des utilisateurs pour les solutions IA d’Anthropic, et tout particulièrement Claude Code, s’accompagne aussi d’une crise de croissance. Les capacités de calcul ont du mal à suivre, et ce ne sont pas les accords signés ici et là qui vont améliorer les choses à court terme : encore faut-il construire les centres de données et les équiper, dans un contexte où l’approvisionnement en composants est un véritable coupe-gorge.
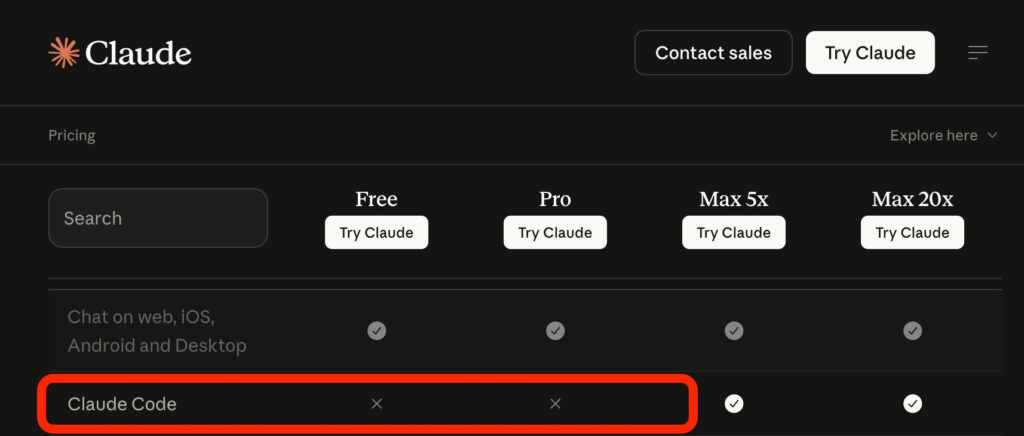
L’entreprise tente donc de maîtriser la demande, et la dernière expérimentation en date ne fait pas que des heureux. Des utilisateurs ont ainsi eu la mauvaise surprise de voir que la grille des bénéfices des abonnements Claude avait supprimé l’accès de Claude Code à la formule Pro (17 dollars par mois). Pour pouvoir utiliser l’outil de génération de code, il faut donc souscrire à la formule Max, à partir de 100 dollars.
Un test et une marche arrière toute d’Anthropic
Les entreprises et les organisations ne sont pas tellement concernées puisqu’elles ont des tarifications spécifiques. Pour les amateurs ou les prosumers en revanche, la pilule est plus difficile à faire passer. Pas de panique (pour l’instant) : il ne s’agit que d’un test concernant 2 % des nouveaux abonnés (rien ne change pour les anciens), a confirmé Amol Avasare, responsable de la croissance chez Anthropic. La liste des fonctions de Claude Pro est d’ailleurs revenue à la normale, l’accès à Claude Code étant de retour. Il ajoute que si quelque chose devait changer, « nous préviendrons les gens bien à l’avance ».
Le dirigeant explique qu’au lancement de la formule Max l’an dernier, elle n’incluait pas Claude Code, que Cowork n’existait pas et que les agents IA qui tournaient durant des heures n’étaient pas encore de la partie. « Max était conçu pour un usage prolongé du chat, voilà tout ». Depuis, Code y est intégré et avec l’avènement d’Opus 4, l’usage a fortement progressé, tandis que les agents comme OpenClaw ont commencé à faire partie des flux de travail au quotidien.
« La manière dont les gens utilisent leur abonnement Claude a fondamentalement changé », observe-t-il, « nos formules actuelles n’ont pas été conçues pour ça ». Avec un engagement en hausse constante, Anthropic a dû faire des ajustements : plafond d’utilisation hebdomadaire, des limites durant les heures de pointe, passage à l’API pour les services tiers… C’est pourquoi l’entreprise cherche de nouvelles manières de partager les capacités de calcul, et en teste certaines.
Va-t-on dès lors vers une hausse des prix des abonnements, couplée à davantage de restrictions dans les offres ? Ce n’est pas à exclure. Le nouveau modèle de langage Opus 4.7 est d’ailleurs plus gourmand en tokens.
Commentaires (21)
Abonnez-vous pour prendre part au débat
Déjà abonné ou lecteur ? Se connecter
Cet article est en accès libre, mais il est le produit d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles d'un média expert
Profitez d'au moins 1 To de stockage pour vos sauvegardes
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 23 avril à 08h48
Le 28 avril à 16h55
On leur donne ça !
Bon, mais ils le prennent !
On est embêtés !
Coluche
Le 23 avril à 09h35
Dans un futur court terme, Claude, GitHub copilot et compagnie, ils passeront tous à une facturation au token pour essayer d’être éventuellement un peu rentable.
J’adorerais une introduction en bourse de ses boites, elles seraient obligées d’avoir des résultats publics un peu plus clairs sur leur finances.
Le 23 avril à 11h18
Modifié le 23 avril à 10h12
Le 23 avril à 11h16
Maintenant, si les projections de coût de mes activités sur trois ans venait à dépasser un certain seuil, j'investirai directement dans du matériel d'inférence.
Le 23 avril à 11h19
Le 23 avril à 11h47
Je serai prêt à mettre plus mais pas non le coût de l'API qui est totalement hors budget pour ma boite.
Le 23 avril à 11h25
Modifié le 23 avril à 12h43
L'autre option est une cm comme la Framework Ryzen AI 395+ avec 128G de LPDDR5x unifiée, c'est moins évolutif mais ça démarre fort pour un prix très acceptable.
Le 23 avril à 10h22
Le 23 avril à 11h32
Modifié le 26 avril à 15h26
C’est extrêmement frustrant de payer aussi cher pour aussi peu.
C’est d’autant plus frustrant qu’au boulot j’ai un accès illimité à l’API donc je sais de quoi l’outil est capable.
Clairement Anthropic a beaucoup d’avance sur la qualité, Opus bien maîtrisé est une merveille, mais ça coûte bien trop cher.
Le 26 avril à 19h34
Cela dit, au vu du coût de dev et d'exécution des logiciels d'IA et les coûts / limitations de leur offre, je me dis aussi qu'ils sont plutôt réalistes. Là où Microsoft ou Google font comme à l'époque du Cloud et sous vendent le produit pour mieux s'accaparer le marché (tout en l'introduisant au forceps à peu près partout avec le vendor lock qui ira bien).
Le 26 avril à 20h30
Et ces modèles hébergés indépendamment sont nettement moins chers qu’Opus ou même Sonnet.
Anthropic a une petite avance technologique mais soit c’est cette avance qui leur coûte très cher, soit ils ont des problèmes de consommation énergétique non maîtrisée.
Faut pas oublier que Gemma 4 ou Qwen, les versions locales cette fois ci, celles qui tournent sur un mac un peu musclé ou un GPU du marché à 1000-3000€, ont des perfs comparables à Claude de l’an dernier.
Le 26 avril à 20h43
Mais à mon sens, ce n'est pas comparable puisque les hébergeurs se contentent d'héberger et leur matos sert avant tout pour l'inférence. Le plus cher dans l'histoire reste l'entraînement et le fine-tuning et toute la recherche autour qui représentent le gros de l'investissement.
Le 27 avril à 10h41
Modifié le 27 avril à 11h52
Infomaniak (qui n'a que deux data centres) ne propose pas d'entraînement, par exemple.
Un autre indicateur qui me conforte dans l'idée que l'inférence revient moins cher : les offres d'hébergement chat bot / modèle sont largement moins chères que celles de machine learning. La diff vient aussi du fait que pour l'entraînement, les bécanes vont tourner pendant une très longue période là où en inférence, ça varie selon la sollicitation.
Évidemment, plus l'inférence est sollicitée, plus y'a besoin de ressources pour conserver des temps de traitement acceptables.
Le 27 avril à 14h10
J'ai regardé par exemple la grille tarifaire chez OVH, ce sont les mêmes prix pour entraîner/faire tourner un modèle (logique, c'est le même matériel qui est loué), mais c'est (un peu) moins cher pour un accès direct à des modèles mis à disposition par OVH (logique aussi, c'est en mode cloud, ça peut être optimisé par rapport à la loc de matériel).
Le 27 avril à 14h40
Le 27 avril à 15h26
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?