Repérée par plusieurs utilisateurs du réseau social, une case dans les paramètres de X/Twitter permet à l’entreprise d’utiliser les tweets et autres interactions pour l’entrainement de son IA Grok. L’information se trouve sur la page du « Help Center » de X depuis mai dernier, mais l’entreprise avait été plutôt discrète sur le sujet.
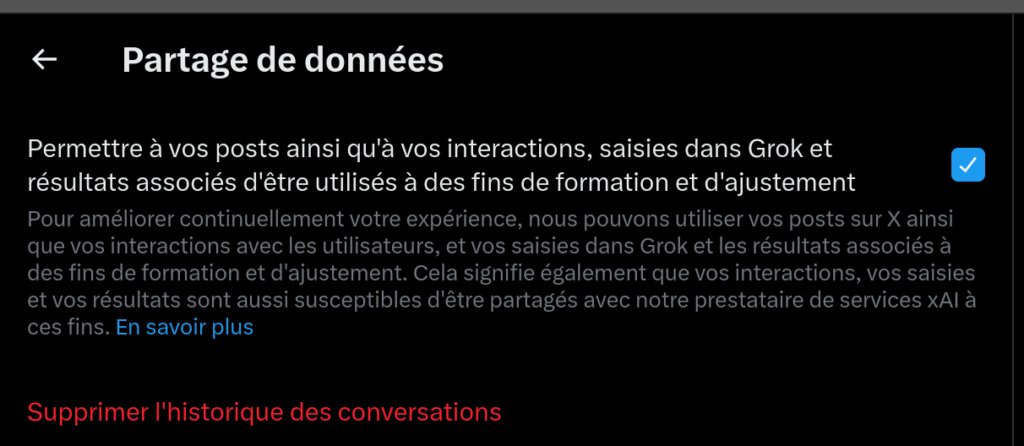
Ce paramètre est accessible via ce lien web (mais pas sur l’application mobile), et la case est cochée par défaut (opt-out).
En juin dernier, Meta avait mis en pause son projet de nouvelle politique de confidentialité des données qui lui permettait, elle aussi, d’entrainer ses modèles de langage avec les données de ses utilisateurs.
L’entreprise avait, elle, pris soin d’informer ses utilisateurs par un message mais sa procédure d’opt-out était beaucoup plus complexe puisqu’il fallait remplir un formulaire en expliquant pourquoi on s’opposait à l’utilisation de ses données. En outre, Meta n’assurait pas pour autant en tenir compte.
Commentaires (23)
Abonnez-vous pour prendre part au débat
Déjà abonné ou lecteur ? Se connecter
Cet article est en accès libre, mais il est le produit d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles d'un média expert
Profitez d'au moins 1 To de stockage pour vos sauvegardes
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 26/07/2024 à 13h22
Le 26/07/2024 à 17h40
Modifié le 27/07/2024 à 19h43
"USER: Peux tu me dires comment faire la conf de mon haproxy?
IA: Démerdes toi tout seul!"
Modifié le 26/07/2024 à 13h53
Je n'aime pas trop l'utilisation de "vous"/"vos" dans un Tweet : c'est un indicateur de putaclic, la recherche d'une émotion, d'un affect du lecteur.
-> je trouve les reformulations "les tweets" ou "les tweets de ses utilisateurs" marcheraient aussi bien en étant plus factuelles.
Le 26/07/2024 à 14h29
je cherche une source fiable mais y aurait un truc bizarre avec certains comptes certifiés qui seraient exclus.
Le 26/07/2024 à 15h07
J'espère que Musk restera droit dans ses bottes: toutes les conversations sont au même niveau, même celles basées sur des fake news.
On va être sur de la bonne source d'informations à destination d'une partie bien définie de la population.
Le 26/07/2024 à 16h34
Le 26/07/2024 à 18h35
Le 29/07/2024 à 09h47
J'ai hâte de voir Grok sortir des fakenews avec des fautes d'orthographe grotesques.
Le 26/07/2024 à 18h10
Cela me semble pas très RGPD compatible.
En tous cas, cette pratique me fait halluciner.
Le 26/07/2024 à 18h16
Le 26/07/2024 à 18h49
Je suppose que X et Meta partent du principe qu'un post utilisateur n'est pas a priori une donnée personnelle (même si elle peut éventuellement l'être). Dans le cas contraire, un consentement explicite en opt-in me parait effectivement obligatoire.
Quoi qu'il en soit, cela n'empêche pas cette pratique d'être abjecte.
Le 26/07/2024 à 19h38
Donc cela ne peut être de l'opt-in par défaut.
Mais de toute façon ils s'en foutent. Perso j'ai choisi la solution qui me sied le mieux : refuser d'ouvrir un lien qui va vers ces sites.
Même si cela ne sert pas à grand chose puisque les éviter est quasi impossible. Y compris ici avec des saletés d'intégrations dans les articles.
Le 27/07/2024 à 00h49
Après, retirer la mention de l'utilisateur (en gros, "anonymiser") d'un tweet est facile. Il s'agit ici d'entrainer et d'ajuster leur IA. Ce qui importe alors est le contenu, pas les métadonnées.
Encore une fois, cela n'enlève rien au fait que je trouve cette manière de procéder pitoyable. Et je ne cherche pas à les défendre. J'essaie juste de comprendre comment une entité de cette taille et qui est sous surveillance peut se lancer dans ce genre d'initiative alors que le RGPD est entrée en application en Europe depuis 6 ans maintenant et que le moindre écart va être vite sanctionné.
C'est la seule explication "valable" que je vois. On peut voir cela comme une "évolution" des captchas qui ont largement servi à entrainer des modèles d'IA de reconnaissance de texte.
Le 27/07/2024 à 07h59
La routine habituelle.
De l'arbitraire pur, encore et toujours.
Bof. Ils sont installés dans le pays de l'APD qui a les couilles dans un étau (puisque l'économie de son pays dépend des multinationales étrangères) et donc un pouvoir presque nul. Je n'ai pas vérifié, mais je suppose que X est aussi installé en Irlande.
Quand le bâton de la sanction est une matraque en mousse, ça fini forcément en fête du slip.
Plutôt la reconnaissance d'image pour le coup, même si ua début c'était beaucoup du texte.
Encore une belle idée de merde, n'empêche...
J'adore la société vue par le Web n'empêche : tout le monde est un robot par défaut, tout le monde doit être considéré comme mineur par défaut vu que législation l'impose, et tout le monde doit servir de matière première à entraîner des modèles de machine learning. Manque plus que tout le monde qui doit servir à nourrir la population à la fin et on aura terminé la boucle.
Modifié le 27/07/2024 à 10h05
Pour X, qui est déficitaire depuis le rachat par Musk, il faudrait être complètement idiot pour se tirer une telle balle dans le pied (mais bon, presque plus rien ne m'étonne aujourd'hui).
C'est vrai. Sauf que justement le DPC (la CNIL Irlandaise) s'est faite remontée le slip aussi bien en interne (par des institutions irlandaises donc), par ses consoeurs que par l'Europe. la DPC devait embaucher (je ne sais pas où cela en est), mais elle est sous étroite surveillance et ne peut plus êtes aussi laxiste qu'auparavant.
Et après vérification, le siège social de X en Europe semble être à Dublin (donc en Irlande, effectivement).
Au début, et pour le captcha de Google (je passe l'époque du captcha pur et dur qui ne servait que de captcha), on avait des images qui correspondaient notamment à des numéros de rue. En interne, c'était en réalité des images prises de Street View pour pouvoir reconnaitre localiser précisément les numéro dans les rues.
Ensuite, effectivement, on a eu les images (cliquez sur les girafes, ou sélectionnez les images où il y a un feu tricolore). Là encore, en vue d'entrainer des IA à faible coût.
D'ailleurs, rien me prouve que je discute avec un être humain adulte et pas un robot mineur :p Donc en captcha, je t'invite à aller faire un tape m-en 5 avec Ness et à me dire le résultat, ainsi qu'à me donner ton numéro de carte bancaire pour m'assurer que tu es majeur
[edit]
Plus sérieuement, sur la dernière partie, je suis entièrement d'accord avec toi. De mon constat, ce qui détruit vraiment le web, ce sont les réseaux sociaux (enfin surtout l'usage qu'on en fait). Il semble bien loin le web du début des années 2000...
Le 27/07/2024 à 10h42
Non reconnu comme preuve de majorité, un mineur peut en détenir une.
De toute façon tu le connais mon numéro de CB, y'a ton nom marqué sur la mienne.
Ah, ça fallait peut-être pas le dire
Le 27/07/2024 à 11h46
Ouais ben chéri, rend moi ma carte bleue
Le 27/07/2024 à 17h50
Après avoir cherché viteuf, effectivement une expérimentation lancée en avril de cette année.
Débile, un mineur peut en détenir une...
Le 27/07/2024 à 17h59
Le 27/07/2024 à 07h49
Ça valait bien la peine de construire un datacenter de 100k GPU pour ça.
Le 27/07/2024 à 14h21
Modifié le 28/07/2024 à 13h59
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?