Le serverless, nouvelle révolution de l’hébergement ? On vous l’explique par l’exemple
if (servers == 0) return {"serverless": false}

En 20 ans, l'hébergement web a connu de nombreuses révolutions. Dernière en date : le serverless. Comme le « Cloud », il s'agit là surtout d'un nom marketing, qui n'a rien à voir avec une solution qui se serait débarrassé des serveurs. Ils sont toujours là. Du coup, dans la pratique, qu'est-ce qui change ?
Au commencement étaient le serveur dédié et les services mutualisés. Au début du web « grand public », c'était en effet les deux manières principales de se faire héberger.
On accédait encore au contenu des sites à travers un serveur FTP, certains poussaient même la folie jusqu'à éditer leurs pages avec le (non) regretté FrontPage de Microsoft ou encore Dreamweaver d'Adobe. À l'époque, changer de prestataire était aisé : il suffisait de déplacer des fichiers d'un serveur à un autre, et au pire de faire un peu de configuration. Notamment pendant les grandes années de PHP.
Derrière le cloud, de petites menottes numériques
Puis, le « cloud » est arrivé, poussé par les grands acteurs américains, avec la promesse d'infrastructures plus flexibles et résilientes, simple à gérer au quotidien. Ils ont en réalité poussé l'analogie de l'hébergeur/propriétaire immobilier à l'extrême. Si certains louent aux étudiants de petites pièces (voir des colocations) avec de nombreux services pour un prix bien supérieur au mètre carré, ils ont fait de même dans l'environnement numérique.
Partis très tôt avec la force de frappe qui est la leur, ils ont rapidement pris le pas en transformant l'écosystème de l'hébergement au niveau mondial. On le voit très bien à travers le poids qu'ils prennent, notamment en France. Jusqu'à réussir à se placer sans problème sur des marchés aussi sensibles que l'hébergement des données de santé.
Et même si la mode est désormais au multi-cloud et aux données réversibles, que l'on peut transférer rapidement d'un service à l'autre, chaque écosystème dispose de ses habitudes et de ses outils qui sont autant de micro-dépendances. Le tout avec une tarification en général assez opaque/complexe. Un point sur lequel le législateur français ne semble pas pressé d'intervenir. La Fiche d'Informations Standardisées (FIS) du cloud, ce n'est pas pour demain !
IaaS, PaaS, SaaS et compagnie
La promesse reste alléchante : trop de monde sur votre site ? Il « scale » (tout comme votre facture), avec une tarification à l'heure, la minute et pourquoi pas la seconde. Publier votre site web ? C'est simple comme un commit au sein d'un dépôt GitHub. Le stockage de données devient objet, passant par des requêtes HTTPS.
Là aussi, avec la promesse d'une performance en toutes circonstances, sans avoir à demander que de nouveaux serveurs soient installés sous 48 h.
Le « Cloud » est ainsi un concept aussi nuageux que son nom, regroupant diverses possibilités, connues par leurs acronymes. Dans ce monde-là, disposer de ses propres serveurs pour y héberger ses données et applications à l'ancienne est connu sous le petit nom d'on-premise. Sinon, on parle d'Infrastructure-as-a-Service (IaaS), de Platform-as-a-Service (PaaS) et de Software-as-a-Service. En passant de l'un à l'autre, vous avez de moins en moins de choses à gérer.

Dans le premier cas, vous louez vos instances à la demande. On ne parle déjà plus de serveurs, puisqu'ils ont été virtualisés. Dans le second, vous ne vous occupez plus de l'OS et de la couche logicielle, juste de déployer vos applications. Dans le dernier, vous louez un simple service en ligne.
Et comme les acteurs proposant ces solutions sont mondiaux, l'accès par les utilisateurs peut se faire au plus proche d'eux. Ces géants n'opèrent en général pas leurs datacenters en direct, mais sont partout.
La modularité, mère du serverless
La montée en puissance du cloud computing s'est accompagnée d'une autre tendance : la plus grande modularité des applications. Que ce soit dans leur conception, avec le trio Angular/React/Vue et Node.js, mais aussi dans l'infrastructure technique qu'elles exploitent. Une application est de plus en plus un ensemble de micro-services, d'API (REST, GraphQL), conteneurisés via Docker, orchestrés à travers Kubernetes et adaptés à la demande des utilisateurs en temps réel.
C'est ce qui a donné naissance au Serverless, ou Function-as-a-Service (FaaS). Une pratique qui n'est pas nouvelle puisque le premier grand fournisseur de service cloud (CSP) à l'avoir proposé est AWS avec Lambda fin 2014. L'idée était de pousser le concept du SaaS jusqu'au développeur : il ne s'occupe de rien, juste de publier son code.
Il sera exécuté à la demande, sur un ensemble de machines plus ou moins puissantes. Toujours fonctionnel, même si la charge augmente. La facturation se fait au temps d'exécution par pouillème de centimes et par tranches de 100 ms. Il n'y a pas d'OS à choisir, pas d'instance ou de sécurité à configurer. Idéal pour un service par requêtes ou une API qui « juste marche ». C'est notamment pour cela qu'AWS le fait travailler conjointement avec son API Gateway.
Le serverless se répand partout
Amazon n'est bien entendu pas le seul acteur sur ce marché. En près de six ans, son initiative en a inspiré d'autres : les Functions de Google, Microsoft ou Netlify, les Workers (Bounded/Unbound) de CloudFlare. En France, Scaleway vient de sauter le pas en mettant en place son offre Serverless en bêta. Elle est gratuite pendant cette phase d'essai et assure, comme d'autres, une compatibilité avec AWS Lambda pour faciliter la migration vers son service.
D'anciens employés du CSP ont d'ailleurs fondé Koyeb, une startup qui veut devenir une sorte d'IFTTT du cloud, permettant un usage serverless multi-cloud. Vous pouvez ainsi récupérer des données chez l'un, les traiter chez l'autre puis stocker le résultat chez un troisième. Le tout avec un catalogue de fonctions clé en main.
De quoi éviter d'avoir à louer constamment des serveurs lorsque ce n'est pas nécessaire, ce qui peut avoir du sens au sein d'une architecture complète. Mais le serverless ne sera pas la réponse à tout et doit être utilisé avec raison. Car peu coûteux à petite dose, il aura l'effet inverse si vous dimensionnez mal vos besoins.
Dans la pratique, comment ça fonctionne ?
Nous aurons l'occasion de revenir plus en détail sur le serverless et ce qu'il permet dans de prochains articles. Mais pour vous permettre de comprendre de quoi il est question concrètement, nous avons conçu de petits exemples que vous pouvez simplement mettre en place.
Nous avons opté pour l'offre de Scaleway, gratuite et simple à prendre en main. Beta oblige, elle est un peu limitée, mais ce sera suffisant pour notre essai du jour. Une fois dans l'interface, vous devrez créer un espace de nom (namespace). Vous pourrez lui attribuer des variables d'environnement sous la forme d'une clé/valeur. Elles seront accessibles à l'ensemble des fonctions et conteneurs qu'il contiendra.


Nous avons ajouté la suivante au nôtre :
URL : https://api.github.com/repos/microsoft/winget-pkgs/contents/manifests
Elle mène à un fichier au format JSON contenant les manifestes de toutes les applications disponibles à travers l'outil winget de Microsoft, permettant leur installation.
Le namespace dispose d'un point d'entrée (endpoint), une URL sous la forme :
rg.fr-par.scw.cloud/funcscw<nom du namespace><caractères alphanumériques>
Passons maintenant à la création de la fonction elle-même. Celle-ci peut être mise en ligne à travers l'éditeur en ligne, un fichier .zip ou pour aller bien plus loin l'interface CLI Scaleway Serverless installable sous la forme d'un paquet npm. Sa documentation complète et son code source sont disponibles par ici.
Pour cet exemple nous nous contenterons de l'éditeur en ligne. Il faut choisir l'environnement d'exécution de la fonction (runtime) entre NodeJS 8.x/10.x, Python 2.x/3.x et Go (seul le zip est proposé). Django et Ruby on rails peuvent être utilisés à travers les conteneurs, précise Scaleway dans sa documentation. Nous avons opté pour Python 3.
Il faut ensuite choisir le niveau de ressources, correspondant à une quantité de mémoire et une portion de processeur. le nombre d'instances pouvant être déployées au minimum et au maximum, si la fonction est accessible en public ou de manière privée, les variables d'environnement qui lui sont propres, etc.
Par défaut, le déclenchement se fait via un endpoint HTTPS. Mais Scaleway évoque d'autres possibilités : CRON (time-based) qui est déjà disponible, puis plus tard MQTT, sans doute en lien avec son IoT Hub.


L'édition d'une fonction Node.js en ligne et les différents paramètres proposés
La fonction par défaut est la suivante :
def handle(event, context):
return {
"body": {
"message": 'Hello, world',
},
"statusCode": 200,
}
Il s'agit d'une méthode dont le nom est handle (correspondant au nom du handler dans l'interface Scaleway) qui reçoit deux dictionnaires en paramètre : event contenant des détails sur ce qui a déclenché la fonction, où l'on trouve notamment le chemin qui vient compléter l'URL de base (path) ou encore les paramètres et context contenant le nom de la fonction et sa version ainsi que la quantité de mémoire accessible.
Le code est plutôt simple, renvoyant un objet body qui sera affiché dans la page (dans une balise <pre>)avec un statut HTTP 200 indiquant que tout s'est bien passé. On peut par exemple la modifier pour afficher le contenu d'event, context, mais aussi l'URL issue des variables d'environnement :
import json, os
def handle(event, context):
return {
"body": {
"event" : json.dumps(event),
"context" : json.dumps(context),
"envvar" : os.environ["URL"],
},
"statusCode": 200,
}
event et context étant des dictionnaires, on utilise json.dumps() pour les sérialiser et en afficher le contenu sous la forme d'une chaine de caractères (string).
Une fois le code modifié, il faut déployer la fonction, ce qui demande quelques dizaines de secondes. Une fois que c'est fait, l'activation peut se faire via l'URL faisant office de point d'entrée. Un bouton de test apparaît alors dans l'interface. Des onglets permettent d'accéder aux paramètres, à la console et aux donnée de monitoring (utilisation CPU, mémoire, nombre de requêtes, latence). Pour vérifier que tout ce passe bien :


Récupérons maintenant le contenu de l'URL pour l'afficher dans la page sous la forme d'un objet avec un décompte du nombre d'applications référencées et la liste complète :
import json, os, urllib.request
def handle(event, context):
with urllib.request.urlopen(os.environ["URL"]) as response:
data = json.loads(response.read())
return {
"body": {
"appsCount": len(data),
"apssList": data,
},
"statusCode": 200,
}
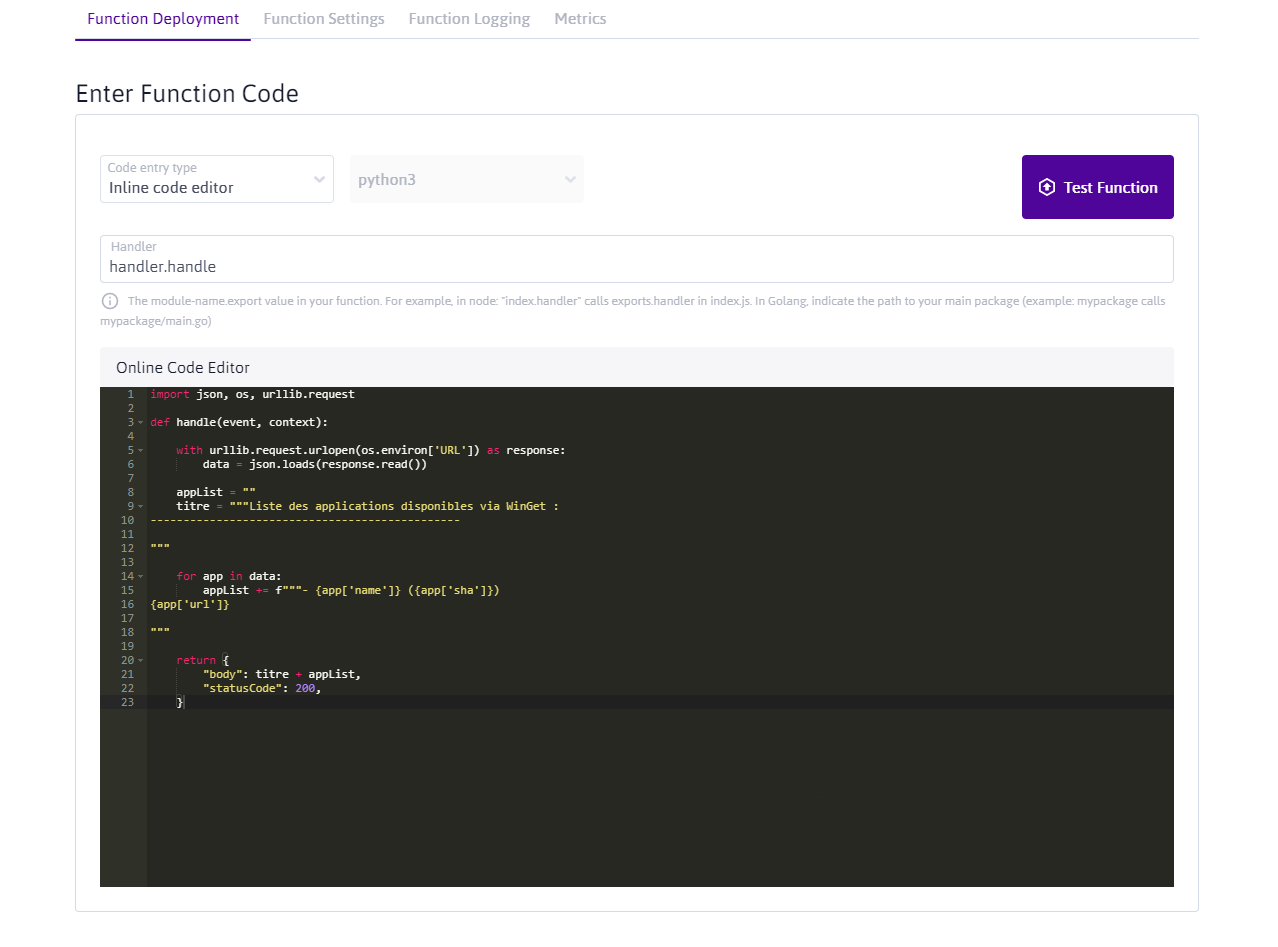
On présente enfin le résultat sous la forme d'un texte mis en forme :
import json, os, urllib.request
def handle(event, context):
with urllib.request.urlopen(os.environ['URL']) as response:
data = json.loads(response.read())
appsList =""
titre ="""Liste des applications disponibles via winget:
-----------------------------------------------
"""
for app in data:
appsList += f"""-{app['name']} ({app['sha']})
{app['url']}
"""
return {
"body": titre + appsList,
"statusCode": 200,
}
Nous n'utilisons pas de code HTML puisque la balise <pre> empêche qu'il ne soit interprété et serve à la mise en forme. Nous avons donc simplement utilisé du texte contenu dans des variables string à triple guillemets permettant de prendre en compte les sauts de ligne. On pourrait faire de même en Markdown par exemple.
Nous obtenons ainsi une fonction qui lit le contenu d'un fichier JSON depuis une URL passée en variable d'environnement, le traiter, mettre en forme le résultat et l'afficher dans le navigateur. Bien entendu, l'exemple donné est trivial et il est possible d'aller bien plus loin avec les fonctions serverless.

Le code modifié et le résultat obtenu
On peut leur passer des paramètres, agir différemment selon le chemin entré dans l'URL. On pourrait imaginer un service vérifiant que tel ou tel site est actif ou non, un autre qui récupèrerait une image pour la traiter puis la renvoyer, etc. L'important est ici d'avoir réussi à obtenir un résultat fonctionnel et accessible en ligne avec quelques lignes de Python, sans avoir à gérer de serveur et où l'on ne paiera que pour les requêtes effectuées.
L'avenir ? Rendez-vous dans dix ans pour en faire le bilan.
Commentaires (60)
Le 07/08/2020 à 15h53
C’est moi ou tous le monde va perdre en connaissance, ce qui risque de créer des dépendances encore plus grandes ?
Le 07/08/2020 à 15h58
C’est toujours une question de rapport entre le besoin et les moyens. Est-ce qu’une startup a besoin de gérer l’ensemble de son infrasctructure en propre et en dur, de monopoliser sur capex là-dessus, de multiplier les sysops pour espérer ne pas se faire trouer ou est-ce qu’elle doit déporter un minimum ? Cela peut venir avec le temps, mais ce n’est pas forcément le plus adapté à toutes les structures.
Le problème se pose aussi autrement comme je le dis dans le papier. Tu peux très bien utiliser du serverless pour certains besoins, pour porter une API ou l’accès à des micro-services par exemple, tout en ayant des services on-premise pour d’autres besoins où ce n’est pas la scalabilité à la seconde qui t’importe.
Rien n’est jamais tout blanc ou tout noir. Parfois on prend le bus. Ce n’est pas pour ça qu’on ne conduit plus.
Le 07/08/2020 à 16h14
de nos jours on distingue 2 approches “serveless”:
FaaS:
KaaS ou Managed Container Services:
Scaleway Serverless que je ne pratique pas semble faire le grand écart entre les 2.
Le 07/08/2020 à 16h24
j’me sens un vieux crouton à gérer mon serveur à la main et maintenir une pile LAMP
Le 07/08/2020 à 16h26
Dans la pratique c’est déjà le cas : les grandes entreprises sous traitent déjà leurs DSI depuis longtemps si bien que la compétence interne s’est perdue au fil des années (perso je suis chez des clients qui n’ont quasi plus de compétence infra en interne, pas de DBA, pas d’ingé système, tout est externalisé en TME). Ce n’est donc qu’une évolution du modèle d’externalisation de l’IT et des couches pour lesquelles une entreprise qui n’a pas forcément d’intérêt à payer des compétences internes mais aussi les frais qui vont derrière ira sous traiter.
Comme le dit David, tout est une question de relation avec le besoin.
Sinon un petit article complémentaire à ce sujet pourra être par rapport à l’Infrastructure as Code ou encore au GitOps qui se généralise pas mal aussi. Les applications et environnements ne sont plus que des fichiers de configs versionnés par un gestionnaire de sources, les actions se faisant par des commits et push sur ceux-ci et derrière l’automatisation se charge de faire sa magie. C’est notamment les sujets sur lesquels je travaille avec la possibilité de faire pop des instances applicatives à la volée (peu importe leur mode d’hébergement), gérer leurs montées de versions et maintenances le tout en se reposant sur du code versionné par Git (typiquement de l’Ansible). Dans notre cas nous avons justement pas mal d’applications historiquement hébergés en mode “lourd” (stand alone sur une VM notamment) ou même sous forme de dockers (mais plus en mode image tomcat + webapp, donc sans exploiter l’intérêt des containers) qui sont en train de se transformer dans ce modèle.
Le 07/08/2020 à 16h28
Ah ben à l’heure où tu peux foutre du HTML statique généré en local dans du S3… #Teasing
En cours ;)
Le 07/08/2020 à 16h29
Sur mon dédié que j’ai chez OVH j’ai préféré l’approche Proxmox et monter plusieurs VM répondant à mes diverses besoins plutôt qu’une machine qui gère tout comme je faisais avant. Et surtout ça me permet de tester des trucs sur une VM sans niquer ma prod perso
Le 07/08/2020 à 16h32
J’ai quand même du mal à voir le KaaS comme du serverless, on tombe plus dans l’Infrastructure as Code comme dit au dessus non ? Chez Scaleway en tous cas c’est plutôt la pile K8S qui gère ça que serverless où c’est du pur FaaS (même l’option conteneur qui n’existe apparemment que pour gérer des couches logicielles différentes de celles proposées clé en main.
C’est notamment pour ça qu’on a commencé à parler de Multipass côté NXi (histoire d’introduire le sujet en douceur
Le 07/08/2020 à 17h48
Le KaaS c’est pas du tout du serverless.
Faut voir Kubernetes comme un genre PaaS un peu moins “opinionated” qu’un PaaS classique, dans le sens où les objets que tu crée dedans sont standards. C’est pas pour rien que OpenShift, le PaaS de Redhat, a tout jeté en v2 pour passer sur Kubernetes en v3. C’est un PaaS.
Le KaaS, c’est ni plus ni moins qu’un Kubernetes qu’on installe pour toi
Le 07/08/2020 à 18h05
Article intéressant, mais de mon point de vue, il manque des trucs : avoir les exemples de scripts, c’est cool, mais ce serait pas mal de montrer les résultats également.
Par ailleurs, comment ces scripts sont exécutés ?
Ca veux dire qu’en faisant une requête GET, ça déclenche le script ?
Vous dites utiliser du Python, mais dans la capture, c’est écrit “runtime: node8”.
Vous mentionnez MQTT, sans faire de définition.
Bref, tout ça pour dire, c’est un sujet complexe, et laisser des zones pas claires, c’est pas idéal pour aider à la compréhension.
Je juge pas, hein, je sais que c’est pas évident non plus. Je pense juste qu’un poil plus de formalisme pourrait aider tout le monde :)
Le 07/08/2020 à 18h18
C’est bien un pti’ rappel, j’aborde un peu cet univers en ce moment. Je pensais que ça allait parler d’IPFS, je sais pas ou ça en est ces choses là…
Le 07/08/2020 à 18h51
Je ne pense pas que les gens vont perdre en connaissances, par contre ils vont perdre l’occasion de gagner en compétences…
Le 07/08/2020 à 19h30
Mmm, étrange de mettre des choses comme Fargate et EKS dans le même groupe. D’accord, ça exécute des conteneurs, mais Fargate est serverless (pour l’utilisateur, il n’a pas de machine virtuelle dans son compte) alors que EKS ne l’est pas (les workloads tournent sur des VM dans son compte).
Le 07/08/2020 à 19h39
Oui comme dit, ça passe par une URL, donc il suffit de mettre dans le navigateur pour voir le résultat :) Plus précisément, comme on récupère le type de requête dans les variables d’environnement on peut choisir d’exécuter ou non une action selon les cas (GET/POST par exemple). Mais cela reste juste un article introductif, visant à ce que les lecteurs essaient, je ne suis pas rentré dans tous les détails (ça fait déjà 15k en l’état, le reste du dossier viendra compléter).
La capture montre une possibilité, on en utilise une autre. Comme ça on a les deux sous les yeux ;)
Je le dis souvent, mais 90% de nos papiers pourraient être composés à 90 % de définitions. On met souvent des liens, pas pour tout. Quand il manque un truc : clic droit > rechercher sur le web aide pas mal. On ne remplacera jamais ça par des océans de définitions.
Le 07/08/2020 à 21h00
Notamment pendant les grandes années de PHP.
C’est quoi les grandes années de Php ?
Le 07/08/2020 à 21h11
Si vous vouliez vraiment faire vieux cons, il fallait dire Macromedia.
Le 07/08/2020 à 21h58
Il en faut pour tous les publics
Le 08/08/2020 à 00h50
C’est sympa la petite explication
Le faas c’est sympa pour du code appelé rarement car il y aura toujours une plus grande latence sauf cas particulier et ça coûte plus cher pour le même service si c’est régulier
je vois ça comme un outil pour les demo/présentation ou tu produit un code rapidement pour faire beau et tirer le maximum lors de la négoce
comme ça tu est le premier à montré un truc qui fonctionne
Le 08/08/2020 à 04h55
C’est d’ailleurs sa raison d’être pour les CSP : mieux remplir leurs machines plutôt que de les voir se tourner les pouces une bonne partie de la journée.
Mais sinon, ça se calcule, puis parfois c’est juste un choix architectural d’avoir une brique où tu ne maintiens que le code. Ou d’avoir un script côté serveur mais deporté d’un front statique par exemple.
Le 08/08/2020 à 06h48
Toutes ces fonctions permettent aux devs de se concentrer sur leur métier. L’automatisation et la factorisation sont le propre de l’informatique. Si 99% des gens ont les mêmes besoins, pourquoi ne pas mutualiser ces besoins en un outil ?
De cette façon, les devs se concentrent sur le coeur de métier de leur boîte, et sur l’apport spécifique qu’elles apportent, plutôt que de perdre du temps à remonter à chaque fois les mêmes infras.
C’est le même principe que d’utiliser un langage haut niveau plutôt que de l’assembleur. C’est bon d’avoir une idée du fonctionnement interne, mais ce n’est pas pour autant que tu dois savoir le faire au quotidien.
Le maître mot c’est le besoin. Si tu as des applis PHP, que tu n’as pas un nombre de visiteurs gigantesque ou une appli absolument critique, pourquoi tu t’emmerderais avec un système qui se scale tout seul et qui apporte son lot de complexité.
Le 08/08/2020 à 06h51
Et ça m’a rappelé aussi que MS Word permettait aussi de faire des pages Web…. (et le permet toujours il me semble)
frisson dans le dos
D’ailleurs Windows 98 n’avait-il pas une version “express” de Frontpage incluse dans l’OS à la même manière qu’Outlook ? Même à l’époque où le lycéen que j’étais découvrait ceci je trouvais ça lourd et incompréhensible par rapport à mon bouquin “apprendre à faire vos pages web en HTML” acheté chez le libraire du coin (et pas pour les nuls svp !).
Ca dépend aussi du code exécuté, si celui-ci est sur un runtime assez réactif la latence n’est pas si mauvaise (certes ça vaudra jamais la réactivité des composants hébergés sur la même machine vu que l’hébergeur va démarrer l’instance à la demande…). Par contre c’est sûr qu’une vieille JVM poussive qui met 15 plombes à démarrer ça n’a aucun intérêt, elle aura plus sa place dans une webapp je pense.
Après, si la fonction est sollicitée régulièrement l’instance restera active. Si elle est inactive pendant quelques minutes, elle sera arrêtée et le prochain démarrage se fera à froid et donc avec une latence supplémentaire. C’est ce que fait Azure par exemple (et j’imagine les autres gros aussi, mais je n’ai pas d’expérience dessus).
Le 08/08/2020 à 10h01
Je vois certains ce sentir vieux voir en dehors de la tendance actuel.
Comme admin systèmes & réseaux, je n’ai eu que une offre en dev ops, le reste des contact sont uniquement sur des infras classiques.
Ou je suis, c’est l’internalisation des compétences infra comme logiciel.
Il y aura toujours besoin d’informaticien de la vieille école. Les mainframes ne sont pas mort, loin de la. Et quoiqu’il arrive il y a toujours besoin de compétences. Ce n’est pas par parce qu’il y a de nouveau produit, tendance pour ne pas dire mode que le monde de la tech est disruptive.
Le serveless, correspond a des besoins tout comme les offres sas, pas, etc
Merci David pour l’article, ca me fait mieux cette technologie que je ne connais que de nom
Le 08/08/2020 à 11h47
Ah ok. Je pensais que justement, ce genre d’article étaient fait pour que tu nous évites d’avoir à essayer nous même. Tu testes, comme ça, on a pas à le faire :þ
Dans le cas présent, je crois comprendre le fonctionnement des scripts, mais j’ai pas envie de me taper toute la procédure juste pour vérifier si j’ai bien compris. Limite, mettre une balise serait une solution.
Là aussi, en principe, pas de soucis. On demande pas la définition de JSON, ou de Python. Mais dans le cas présent, MQTT, ce terme n’a été utilisé qu’une seule autre fois sur IH (en passant, et sans définition également), et jamais sur NI.
Peut-être que je suis le seul à ne pas connaître ce terme.
Mais bref. Oui, j’ai fait une recherche, et oui, je me suis instruit tout seul.
Le 08/08/2020 à 15h03
Je plussoie, le serveless reste peu employé en prod, la plupart du temps uniquement comme outil de dev / demo pour aller plus vite.
Le 08/08/2020 à 16h17
Je me sens aussi comme un vieux con en lisant cela.
J’ai été perdu dès l’intro, juste après le passage sur le dépôt des fichiers en FTP…
Sinon pour moi, ça fait aussi partie du boulot de dév de comprendre comment ça fonctionne “derrière”, les à-côté. C’est comme ça qu’on m’a formé en tout cas.
Certes c’était chiant de perdre 2h parce que cette p*tain de page d’accueil donnait une erreur 403, mais il fallait réfléchir pour trouver une solution, aller regarder les logs Apache pour voir qu’on s’était loupé sur le vhost, chercher dans la doc, des fora, retester, échouer encore. On râlait, mais c’était formateur. Je veux bien que ça laisse du temps pour que les “dévs fassent du dév”, mais si on s’intéresse plus à tout ce qui tourne autour de la ligne de code, on ne dit pas développeur : on dit pisseur de code.
Ca me fait penser à ceux qui font des trucs sublimes avec un framework, mais sont paumés quand il faut faire la même chose sans le framework. Chez certains de mes clients, c’était même le test d’entretien, et il y a pas mal de monde qui échouait, parce que “ça sert à rien de savoir la méthode native vu que le framework le fait tout seul”.
Le 08/08/2020 à 17h12
Comme dit plus haut, oui ça peut être un besoin, mais ce n’est pas toujours le cas. Comme pour le cloud, l’un des objectifs c’est aussi la scalabilité de l’application sans trop avoir à tout gérer à la main ou même avec des outils maison où tu ne sera pas toujours très efficace.
Surtout qu’une fois de plus, on ne parle pas de mettre toute une app en serverless, mais certaines des briques qui correspondent à ce besoin.
L’exemple des frameworks est assez bon je pense : utiliser des frameworks sans maitriser le langage est une erreur. Penser qu’il faut tout faire en C/ASM parce que c’est “pur” et que là on comprend ce qu’on fait, une autre. Parce que c’est toujours un curseur à placer.
Tu seras toujours dépendant de solutions intermédiaires. Pour certains le drame c’est de se reposer sur du code sans framework, pour d’autre d’utiliser du severless ou du cloud plutôt qu’une infra maison, pour d’autres encore ce sera de ne pas tout faire en WASM ou de ne pas avoir son propre serveur HTTP aux petits oignons, pour d’autres de ne pas tout faire sur une Gentoo aux petits oignons, etc. C’est sans fin.
Mais au final, quand tu es en prod’, tu veux que ça fonctionne, que ça ne te coute pas trois reins, que ça soit flexible quand ta charge l’est, que tu puisses encaisser des pics (sinon tout le monde va se foutre de ta gueule quand tu seras cité dans Capital).
Faire à l’ancienne ou via de nouveaux outils n’est pas une bonne chose en soi. Penser que l’une ou l’autre des solutions est la bonne “parce que mon mindset” non plus. La remise en question des pratiques c’est la base de tout.
Et je pense que n’importe quel DSI qui vante de l’upload de PHP par FTP en 2020 pour de la prod se fait défoncer par son équipe sécurité (et sans doute aussi celle qui doivent gérer tout le process de déploiement ). Pas parce que c’est vieux, mais parce que c’est inadapté aux besoins et au contexte.
). Pas parce que c’est vieux, mais parce que c’est inadapté aux besoins et au contexte.
Le 08/08/2020 à 18h59
Le dev il devra toujours tester son code avant de le livrer, donc il le testera aussi dans ce genre d’environnement d’exécution. Ne serait-ce que pour éviter l’habituel “ça marche sur mon PC”. (parce qu’après on est obligé de cloner son PC et l’envoyer en prod, c’est à cause de ça que Docker est né bordel ! )
)
Dans tous les cas, cet article présente un outil et des possibilités. Le but n’est pas de dire “demain vous devez tous faire ça sans aucune autre alternative possible”, mais de dire que ça existe et ça se développe.
Dans les fait, la base de réflexion doit être : qu’est-ce qu’on veut faire, pour ensuite savoir avec quoi on va le faire. Et non l’erreur classique du “on doit faire ça” sans réfléchir pourquoi. Vous savez, comme les DSI qui disent “on fait du DevOps” en croyant que ça signifie juste avoir un Jenkins/GitLab/Whatever qui publie des artefacts sur un repo.
Ca donne des résultats catastrophiques où j’avais des applis qui étaient livrées sous formes d’images Docker (dont les images de bases ne sont pas mises à jour, tant qu’à faire !!) parce que le client a dit qu’il fallait faire du Docker. Pourquoi ? Parce qu’il fallait faire du Docker. Bah un container Docker Tomcat qui charge le WAR applicatif, installé sur une VM qui ne fait que ça, c’est de la merde. Tout ça parce qu’un jour, quelqu’un a dit “on fait du Docker”.
Bon après je vais pas me plaindre, ça me fait du boulot de réparer ce genre de conneries.
faire et défaire ça fait du chiffre d’affaire
Le 09/08/2020 à 07h52
La conséquence à terme de ce manque de compétence interne ce peut être un HealthHub hébergé chez Microsoft avec toutes les conséquences que cela induit…
Le 09/08/2020 à 09h29
Non, le choix de HDH n’a rien à voir avec le fait que le cloud ou le serverless existent et que certaines DSI l’utilisent au profit de solutions internes. D’ailleurs, le souci du HDH n’est pas tant qu’il ne soit pas géré par un service de l’état.
Le 09/08/2020 à 10h12
Pas tant que ça puisque sans l’article tu n’aurais pas cherché Mais j’ai ajouté quelques liens et captures quand même à l’article
Mais j’ai ajouté quelques liens et captures quand même à l’article 
Le 09/08/2020 à 13h07
Oui c’est pour ca que Java se tourne vers la compilation native avec GraalVM et des frameworks l’exploitant comme Quarkus ou Micronauts car plus trop adaptée pour des archi microservices devant être up scalé / down scalé le plus vite possible avec le moins de conso mémoire possible (plein d’instances qui bouffent plusieurs centaines de Mo de base ca coute sur les infra clouds ^^). Histoire de pas se laisser distance par Node.js / Go sur ces infra modernes.
Vidéo intéressant sur le sujet : YouTube
YouTube
Le 09/08/2020 à 17h03
Le 10/08/2020 à 00h00
On en fait énormément à mon taff (Lambda chez AWS) : c’est complexe à configurer si on veut les choses proprement. Et ce n’est pas pour des démo/dev mais bien sur des fonctionnalités en prod et se manger du trafic par millier.
Ça permet un coût à l’exécution, scaler à chaud pour absorber des pics de charges, intégrer facilement à d’autres produits (l’article cite APIGateway pour faire suivre des requêtes http - ALB permet aussi de le faire) mais ça sert aussi à réagir à des bus (sqs, sans, un flux bdd DynamoDB, etc.).
Le serverless pour découper une brique fonctionnelle, c’est exactement ce pour quoi elle doit servir.
Perso on utilise le framework Serverless pour déployer facilement sur ces plateformes (AWS mais il le fait pour Google Cloud et Azure). Ça permet de “simplifier” sa mise en place.
Et comme déjà dit : ça ne remplace pas une stack on-premise, mais ça répond à un autre besoin dans un certain contexte.
Le 10/08/2020 à 08h44
Par contre, j’imagine que le bilan énergétique de la chose doit exploser par rapport à une solution interne.
Entre la nécessité d’un client interne, d’un serveur externe, des couts d’énergie pour les échanges de données…, je pense que la facture écologique de ces systèmes doit exploser, un peu à la manière de la musique en streaming.
M’est avis que le réchauffement climatique est pas prêt de s’arrêter.
Le 10/08/2020 à 08h56
Pour ma part sauf exception je pense que le serverless est le hold-up du siècle. Les entreprises ne pourront plus que difficilement sortir leur code et leurs données de ces infra et le jour où AWS décide d’ajouter un zéro à la facture elles seront coincées.
Je préfère m’en tenir éloigné autant que possible. Du IaaS d’accord car on n’est pas trop enfermés, du serverless non.
Le 10/08/2020 à 09h06
J’ai du mal à comprendre la remarque ? En quoi faire du FaaS (qui permet justement de n’utiliser du calcul que lorsque c’est strictement nécessaire) aurait un mauvais bilan énergétique par rapport à n’importe quel serveur qui tournerait H.24 en interne en étant sous exploité ?
Sans parler de la densification que permettent les DC (et les économies/avantages qui en découlent), leur gestion énergétique qui n’a rien à voir à la machine mise en prod par rapport à un serveur en interne, etc. Le problème de la question des bilans énergétiques, ce n’est pas les DC, ce son les avis à l’emporte-pièce.
Le 10/08/2020 à 09h09
Je tiens à ajouter que même hors compilation native, les JVM ne sont pas tant à la ramasse qu’on pourrait le croire, en startup time et empreinte mémoire. En général ce n’est pas tant la JVM le problème, que les surcouches qu’on y met: JEE / SpringBoot avec injections de dépendances etc. Si on prend un framework léger, de type Vert.x, il fait plus que tenir la comparaison avec Node.js en startup time (l’appli node.js n’étant pas non plus compilée faut-il préciser). Alors, c’est vrai que la JVM ça reste tout un tas de classes à charger, et c’est vrai que GraalVM permet à Java de revenir dans la course face aux langages compilés ; mais d’un autre côté, ce qu’on gagne en startup / mémoire, on en perd en optimisations JIT qui permettent parfois de meilleures perfs à chaud.
Bref tout ça pour dire que c’est compliqué :-)
Le 10/08/2020 à 09h39
Et petite précision concernant le temps de démarrage : le passage de 0 workload à 1 (= cold start) est coûteux en effet, et le startup time a son impact. Mais passé ce cap, le scaling de 1 à N est beaucoup moins problématique puisque le load-balancer ne redirigera pas les requêtes vers un workload qui n’est pas encore prêt à les recevoir. Donc, pour un workload qui sera continuellement sollicité, donc jamais dormant, pas de cold start, donc le temps de démarrage n’est pas (trop) un problème.
Le 10/08/2020 à 09h48
Disons qu’il faut que la JVM fasse son warm-up. Après seul un dieu du C peut faire plus rapide tant qu’on ne fait quue du back-end car la JVM bénéficie des instructions de vectorisation du CPU qui ne sont pas nécessairement utilisées lors d’une compilation statique.
Le 10/08/2020 à 09h52
C’est intéressant pour le noob que je suis.
Si j’ai bien compris l’esprit du service, cela consiste à proposer au client la “plate-forme” en dur, avec le maximum de fonctions élémentaires, voire élaborées, reportées dessus, et de lui laisser la partie vraiment “créative” avec des outils les plus simples possibles. Le tout avec une optimisation à la volée de l’utilisation du service en fonction de sa charge.
J’attends de voir les exemples pratiques pour mieux comprendre ce que ça donne IRL, parce que c’est quelque peu nébuleux pour moi, pour l’instant, point de vue applications. À suivre…
Le 10/08/2020 à 10h14
Interessant en effet. Merci pour l’article !
Le 10/08/2020 à 10h21
Je sais pas ce qu’en disent ceux qui utilisent le FaaS (c’est pas mon cas), mais je crois pas qu’il faille chercher du côté de la simplicité pour les arguments. Ça, c’est le discours marketing, mais il faut aussi voir qu’avec le FaaS on se créé une nouvelle dépendance vers un fournisseur externe qu’il faudra gérer différemment du reste de l’application qui elle n’est pas en FaaS. Donc, ça ajoute de la complexité. Si ce qu’on recherche c’est simplement un environnement prêt à l’emploi, le “platform as a service” le fournit aussi.
Je crois que le principal intérêt du FaaS est pour les boîtes qui veulent optimiser leur facturation aux petits oignons.
Cf aussi le commentaire de @MrKuja plus haut
Le 10/08/2020 à 12h31
si le boulot est de dev avec ce framework, c’est quoi l’interet de ce test? je suis d’accord qu’il est préférabe pour un dev de comprendre ce qui se passe globalement “sous le capot” (et autour), mais il n’est pas non plus nécessaire de savoir réinventer la roue (la plupart du temps). Sinon on place le curseur où? en entretien je vais te demander de me balancer tous les algos de sort même si le language/framework fournis les méthodes qui vont bien?
Le 10/08/2020 à 14h49
Intéressant, mais tout ça ça fragilise les entreprises lors des crises. Faire héberger=louer= coût constant impossible à baisser (rapatrier une infra cloud pour pouvoir suspendre ses activités et les reprendre plus tard, c’est totalement illusoire).
Quand on possède sa propre infra, elle est payée. Si on doit suspendre ses activités (cas d’une crise dans le genre COVID ou autre désastre), elle ne coûte presque plus rien mais reste totalement opérationnelle alors que les revenus fondent.
Bon courage pour sortir du cloud quand vous n’avez plus les revenus pour payer.
Le 10/08/2020 à 15h28
Déjà dit mais l’un n’est pas exclusif de l’autre. Tu peux avoir ton infra et faire du serverless ponctuellement, redonder de telle ou telle manière (c’est aussi pour ça que le cloud hybride public/privé est de plus en plus poussé), etc.
Après oui on peut tout faire soi-même et juste monopoliser du capex pour du matériel qui sera rapidement obsolète pour se rassurer sur son indépendance (vu qu’on est toujours dépendant de quelque chose, même en internalisant). Mais ce n’est pas franchement adapté à toutes les situations.
Le 10/08/2020 à 15h50
C’est une méthode de calcul différent pour le TCO, mais elle peut être appliquée de la même façon qu’un hébergement on premise.
Par exemple des prestataires Cloud permettent de réserver une ressource pour 3 ans (moyennant une ristourne sur le coût) avec derrière un engagement du client pour payer la facture. Ce qui revient plus ou moins comme le fait de budgétiser une infra interne avec son amortissement derrière. Les calculatrices d’estimation de coûts permettent aussi de se donner une idée du budget à allouer.
Après il me paraît illusoire d’estimer que son infra interne, aussi bien conçue soit-elle, soit résiliente à une crise difficile à anticiper comme celle du COVID-19 qui a pris beaucoup d’entreprises de court (Cloud providers inclus !). Tu as une infra en interne, elle tourne, et tout ce que tu payes c’est le coût énergétique et bande passante de celle-ci (ce qui est déjà loin d’être négligeable…), et là tu as un serveur qui lâche et porte une partie de tes applications business. Par chance, tu auras évidemment prévu la redondance, mais l’entreprise n’a pas les moyens de remplacer le serveur perdu à cause de la crise. La prod tourne sur une patte pendant combien de temps ? Quel risque que l’autre serveur tombe entraînant un blackout avec impact business ?
C’est loin d’être rare, j’ai connu une période où des BladeCenter IBM (les HS-22 de mémoire) tombaient comme des mouches.
Après, dans les faits, il y a beaucoup d’entreprises qui hébergent leur production on premise dans leurs propres locaux ? Tous les grands comptes que j’ai connu ont soit leur propre datacenter (parce qu’ils peuvent payer un tel coût d’hébergement…), soit l’hébergement est sous traité chez un prestataire (location de salles, voire location de serveurs chez un provider du marché). Parce que le on premise sur site, faut quand même gérer aussi toute la sécurité du DC… Ce qui devient vite un gouffre financier.
Quant aux plus petites entreprises, je les vois mal faire de l’auto hébergement à moins qu’elles n’aient une rentabilité de ouf le permettant.
Le 10/08/2020 à 17h30
Pas sûr que le sujet ai été abordé mais le Serverless avec AWS Lambda n’a pas vocation à fonctionner 24*7, les fonctions ont une timeout maximum. L’objectif est vraiment de donner un environnement d’exécution Python/Node/etc pour qu’on ne s’occupe plus que du code. L’idée étant de pouvoir faire l’interface avec d’autres APIs / services (S3/RDS par ex pour les données) pour construire ses propres briques.
Le but final de AWS / Google / Microsoft étant de faire utiliser toute la panoplie de leurs services pour faire de l’argent
Le 11/08/2020 à 01h02
Oui particulièrement les frameworks faisant un maximum de chose au runtime donc initialisation un peu longue, sans aller jusqu’à la compilation native permise par GraalVM, certains frameworks (Micronauts, Quarkus), préfèrent digérer un maximum d’opérations lors du build pour permettre un démarrage rapide (pas de lecture d’annotation, de création de proxy à tout va comme Spring) tout en gardant le bytecode / JVM et les optimisations permises par JIT
Le 11/08/2020 à 05h29
Je ne connais pas suffisamment AWS, mais chez Microsoft ils ont des Durable Functions qui permettent d’exécuter un workflow d’Azure Functions, pour un traitement qui du coup ne timeout plus car il est séparé entre plusieurs appels. C’est vraiment super intéressant et ça marche vraiment bien !
Le 11/08/2020 à 06h17
Tkt, je suis totalement dépassé et je reste sur mon LAMP aussi (juste MySQL/MariaDB que je remplace par SQLite :p) ^^. Pour la prod, je passe juste par un hébergeur qui me propose un espace disque et un accès FTPS.
Mais Lamp ça marche très bien et au moins tu ne dépends de personne. Faut juste mettre les mains dans le cambouis pour le moindre script, mais d’un côté, c’est ce qui est intéressant.
Le 11/08/2020 à 06h56
Ca marche très bien mais le serverless apporte des avantages. Une fois ton appli en serverless, tu ne te soucies plus de la scalabilité, du monitoring de la machine, de la capacité d’espace disque, de la haute dispo, ….
Je suis un ancien admin sys linux, donc gérer un serveur ne me ferait pas peur. Mais depuis que j’ai monté ma boite je développe notre appli en serverless (AWS) et tous nos outils internes classiques (compta, collab, ERP, …) sont en SaaS. j’ai bien conscience de restreindre ma possibilité de migration future mais j’ai autre chose à faire que de gérer des machines. J’accepte le vendor-locking pour le gain en sécurité / disponibilité / couts de développements que ça m’apporte.
oui, je mets sécurité sur la liste. Je sais que beaucoup mettent la sécurité de l’autre côté de la balance, mais moi je considère que j’ai un gain à externaliser. Je n’aurais jamais la prétention de faire mieux qu’Amazon via Cognito pour protéger les comptes de mes utilisateurs ;)
Le 11/08/2020 à 08h22
Je pense aussi qu’il existe une histoire d’évolution des compétences. Dans certaines entreprises dans lesquelles j’ai travaillé, certains admin sys étaient totalement réfractaires au serverless (et même au cloud en général). Evidemment, c’est un tout nouveau monde à appréhender, et se former n’est pas toujours simple quand on voit le nombre de ressources pouvant être créées chez Amazon ou Microsoft.
J’entends également souvent dire “le cloud, ça coûte trop cher”, pourtant, une fois bien utilisé et optimisé avec des politiques d’unscale automatique la nuit par exemple, on s’en sort beaucoup mieux.
Bref, la formation serverless / technologies cloud me parait indispensable aujourd’hui ^^
Le 11/08/2020 à 10h42
Moi c’est justement ce qui me fait peur:
OK le cloud ça scale, mais à quel prix ? J’ai pas envie de recevoir un beau jour un prélèvement de 125k€ parce qu’un script est parti en live et m’a bouffé du CPU, ou parce qu’on m’a DDOS un site web et que le système a réagit en augmentant la capacité…
Pour moi cette incertitude de facturation est un tel risque que je ne comprends pas comment on peux gérer une activité avec une telle épée de damoclès.
Le 11/08/2020 à 11h36
Je trouve que le Faas répond à 2 objectifs :
Par contre, il faut être rigoureux en cartographiant l’ensemble des lambdas et leur finalité sinon c’est vite le bordel.
De part mon expérience sur AWS :
Le 11/08/2020 à 12h26
en fait il faut surtout voir la possibilité de scaling comme une possibilité de scaling à la baisse. tu peux sans problème limiter la capa max et te mettre des alertes si tu dépasses des seuils (nombre d’execution, limite budgétaire, …)
Le 11/08/2020 à 12h40
C’est parce qu’il ne faut pas s’arrêter aux tableaux de la page pricing et regarder ce qu’il en est/mettre le nez dedans. Comme dit par d’autres commentaires, le scaling n’est pas qu’à la hausse, il est aussi à la baisse, sans parler de l’accès à des instances spécifiques, de la pré-reservation, du préemptable, etc. qui réduisent en général encore la facture.
L’idée c’est plutôt que se caler sur une infra fixe qui marchera correctement 90% du temps, sera overkill 50% de cette part et les 10% restant sous l’eau, c’est d’avoir une infra qui s’adapte au besoin. Pour le reste, il y a des cappings de facturation, tout se gère même via API si tu veux intégrer ça en direct dans des outils maison, etc.
Puis bon, le DDoS, si c’est ton instance qui la prend en frontal, c’est que tu as un souci de conception de ton infrastructure.
Après si ton revenu ne dépend pas de l’importance de ton activité, répondre à des pics de charge n’est pas forcément ta priorité (mais c’est quand même rare). Et quand bien même, le fait de pouvoir optimiser par rapport à du dédié à gérer à 100% est quand même un confort assez apprécié en général (sans parler de l’impact coté capex).
Le 11/08/2020 à 16h04
Le scalling est verrouillable, c’est toi qui défini les modalités.
Par exemple tu déploies une application via l’AKS d’Azure, comme pour n’importe quel autre Kubernetes, tu pourras dire à combien d’instances elle doit se dupliquer.
Egalement, tu peux définir des seuils d’alerte de facturation pour être prévenu si une ressource se met à coûter trop cher par rapport à l’estimer. Il y a également des outils de conseils pour optimiser la facturation. Par exemple chez Azure, typiquement le truc qui est oublié quand on drop une VM c’est de supprimer son disque qui est rattaché… Résultat tu te retrouves à le payer dans vide. Il y a également des calculatrices pour une ressource, mais aussi pour le TCO d’une ressource sur X temps (genre pour dire que ta webapp + la BDD associée + le stockage avec XGo de BP te coutera xxxx€ sur 5 ans).
Il faut avoir une autre vision quand on consomme du Cloud public, l’aspect “pay as you go” peut vite devenir imprévisible si on pense gérer ça en dépense fixe alors qu’elle est mécaniquement variable en temps quasi réel. Je cite Azure car c’est celui avec lequel j’ai le plus d’expérience, mais j’imagine qu’AWS et GCP ont les mêmes outils de conseil et d’optimisation de coûts. J’ai une souscription OVHCloud à titre perso et j’y ai aussi défini un seuil d’alerte à partir du moment où la facturation devient délirante (3€, oui j’utilise qu’un object storage dessus pour mes backup ).
).
Toutes ces réflexions sont à avoir lors de l’étude du projet de toute façon… Le Cloud peut vite devenir un gouffre financier au même titre qu’une infra on premise mal maîtrisée.
Le 12/08/2020 à 05h49
Un jour (2011-2012) pour une migration, j’ai expliqué qu’on n’apprenait pas “ASP.Net MVC”: on devait apprendre en fait une dizaine de technos et langages: C#, Razor, HTML, JS, CSS, Entity Framework, le comportement d’un serveur web, la programmation par état et sans connection, les injections de dépendances, et un contrôle de code source.
Tout cela pour une équipe qui connaissait surtout VB.Net, Winforms et SQL Server.
Passer du client/serveur au web a été pour moi un calvaire (surtout avec JS et CSS): c’était un retour de 20 ans en arrière sur les outils de dev (et je pèse mes mots: en même temps je faisais encore du fortran sur un VAX de 1996, dont les outils de débogages étaient largement plus efficaces).
Donc ce genre de package tout fait peut aider à sortir une appli rapidement, du moment qu’on est capable de lister les fonctionnalités désirées, de développer la glue dans son coin et d’assembler tout correctement.
Downside plus loin…
Mouais. Pour utiliser ce genre de services depuis un moment, le problème c’est qu’on n’a pas une compétence par API: on en a par API/version. C’est dingue comme des frameworks/API ont tendance à casser les fonctionnalités existantes ou les modifier de façon qu’on passe notre temps à combler les trous par ce que notre appli dépend de services instables dans leur définition.
Ca me rappelle une équipe de la dinum qui a dit “Nos applis n’ont pas de maintenance. Elles évoluent en continu.”
Ben rejoignez donc la vie réelle des gens qui n’ont pas un deux ou trois projets en portefeuille mais plutôt entre 20 et 50 à faire vivre et maintenir en vie en même temps.
Les “compétences” côté web (API ou framework), à part sur les très grands domaines (react et consorts, AWS) sont très très très volatiles.
Le 12/08/2020 à 12h25
Je rejoins totalement la vision de @brice.wernet pour vivre sensiblement la même expérience. Je fais la passerelle entre plusieurs applications web via des API et je passe mon temps à patcher pour que tout fonctionne comme avant.
Valeur ajoutée pour moi et ma compagnie : Zéro.
Je fais juste le support de ces compagnies, une espèce de sous-traitant gratuit corvéable à merci et non plus un client qui a payé pour un service pérenne.
Le 13/08/2020 à 16h05
En l’occurence c’était une mission sans framework, donc logique de poser ce genre de questions.