

arXiv : les chercheurs qui soumettent des articles genAI erronés seront suspendus un an
À inondation massive, solution massive

Alors que les plateformes de prépublications et éditeurs scientifiques sont inondés d’articles générés par IA, arXiv s’affiche plus sévère. Elle annonce une suspension d’un an pour celles et ceux qui soumettent des articles dont la génération n’a manifestement pas été vérifiée.
La plateforme pionnière de prépublication scientifique arXiv va suspendre pour un an tout chercheur qui aurait mis en ligne un article erroné et manifestement généré par IA.
« Si un article contient des preuves irréfutables indiquant que les auteurs n’ont pas vérifié les résultats générés par un grand modèle de langage (LLM), cela signifie que nous ne pouvons avoir confiance en quoi que ce soit contenu dans cet article », expliquait dans un thread sur X jeudi dernier Thomas Dietterich, le responsable adjoint de la plateforme.
Une année de suspension et un retour très balisé ensuite
Il ajoutait que l’équipe avait décidé d’une suspension d’un an de la plateforme pour tout auteur ayant signé un tel article. Après cette année de suspension, la plateforme acceptera les articles signés par cet auteur s’ils ont déjà été acceptés par une revue ou une conférence qui aura déjà effectué le filtre de relecture par les pairs. Autant dire que l’intérêt de mettre en ligne sur arXiv deviendra quasiment inexistant pour ces personnes.
« Notre code de conduite stipule qu’en apposant sa signature en tant qu’auteur d’un article, chaque auteur assume l’entière responsabilité de l’ensemble de son contenu, quelle que soit la manière dont celui-ci a été élaboré », justifie-t-il.
Certains chercheurs comme l’économiste James D. Miller s’inquiètent du fait que tous les auteurs d’un article pourraient être sanctionnés : « Cela signifie-t-il donc que vous attendez de chaque auteur qu’il vérifie chaque référence et s’assure que chacune d’entre elles est authentique et exacte ? Que se passe-t-il si l’un des auteurs n’est pas en mesure de vérifier une référence parce que celle-ci est rédigée dans une langue qu’il ne maîtrise pas ou porte sur un sujet technique qu’il ne comprend pas, alors qu’un autre auteur de l’article en est capable ? », demande-t-il.
« Nous notons que les outils peuvent produire des résultats utiles et pertinents, mais aussi des erreurs ou des résultats trompeurs ; c’est pourquoi il est important de savoir quels outils ont été utilisés pour évaluer et interpréter les travaux scientifiques », expliquait le site dans sa politique de modération.
Et l’équipe d’arXiv y rappelait déjà à ses collègues « qu’en apposant leur signature en tant qu’auteur d’un article, ils assument chacun individuellement l’entière responsabilité de l’ensemble de son contenu, quelle que soit la manière dont celui-ci a été généré. Si des outils linguistiques d’IA générative produisent des propos inappropriés, du contenu plagié, du contenu biaisé, des erreurs, des fautes, des références erronées ou du contenu trompeur, et que ces résultats sont intégrés dans des travaux scientifiques, la responsabilité en incombe au(x) auteur(s) ».
Mais la masse d’articles contenant ce genre de problèmes est telle qu’arXiv semble avoir dû, si ce n’est relever la barre de la sanction, au moins la rendre publique.
Thomas Dietterich finit son thread en donnant quelques exemples de preuves indiscutables de ce genre d’utilisation : « références fantaisistes, méta-commentaires du LLM ( » voici un résumé de 200 mots ; souhaitez-vous que j’y apporte des modifications ? » ; « les données de ce tableau sont données à titre indicatif, complétez-le avec les chiffres réels issus de vos expériences ») ». Interrogé par 404 Media, il ajoute que la plateforme ne fera aucune exception à cette règle tout en ajoutant qu’une procédure d’appel existe et que les modérateurs de la plateforme doivent documenter clairement le signalement. Le responsable d’arXiv pour la discipline doit confirmer avant sanction.
Les revues et actes de conférences sont aussi inondés de genAI problématiques
Les plateformes de prépublication comme les revues scientifiques sont de plus en plus inondées d’articles générés par IA et non vérifiés. Récemment, une étude montrait que les actes des conférences scientifiques peuvent accueillir massivement des articles rédigés (ou générés par IA) dans le but de vendre aux chercheurs une place bien au chaud pour leur signature moyennant 11 à 400 dollars.
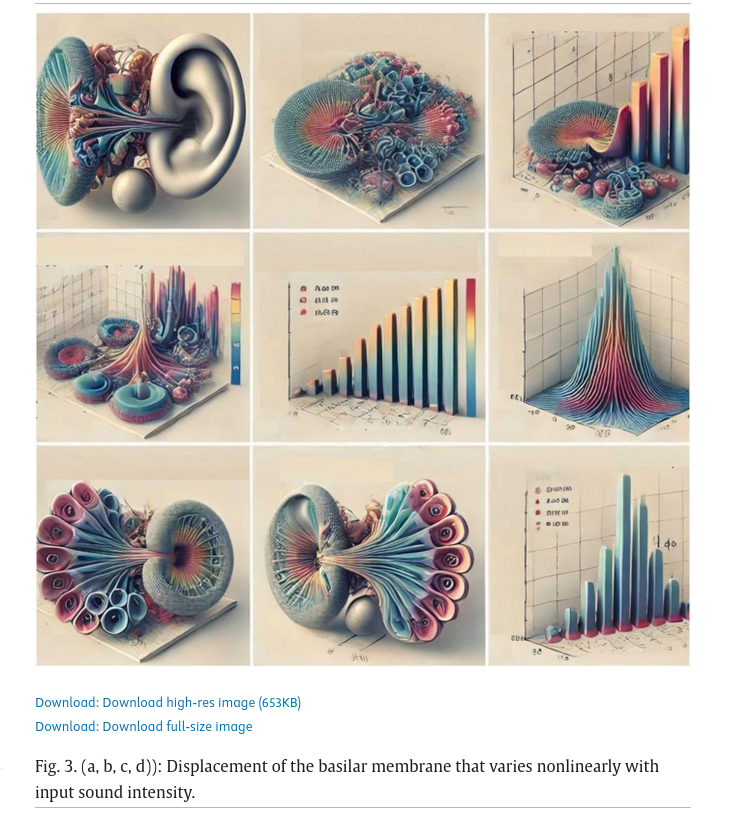
On peut aussi régulièrement repérer des articles scientifiques incluant des schémas fantaisistes générés par IA. Ainsi, on peut trouver, par exemple, cet article, publié en mars 2025 dans la revue Alexandria Engineering Journal éditée par Elsevier, censé présenter une modélisation mathématique de la mécanique cochléaire et des dysfonctionnements liés à la cochlée. On peut y trouver ce genre d’illustrations totalement fantaisistes et inappropriées :

L’article n’a actuellement pas encore été rétracté.
L’ACL prend aussi des mesures
Les plateformes de prépublication ne sont pas les seules à réagir. Ainsi, par exemple, les responsables de la conférence de l’Association for Computational Linguistics qui doit avoir lieu en juillet prochain ont dû publier une déclaration spécifique concernant le rejet d’articles contenant des références fantaisistes. L’organisation explique que beaucoup de propositions ont été rejetées dès le début pour ce genre de problème.
Mais elle ajoute que même après ces filtres, il y a eu des trous dans la raquette : « lors des derniers contrôles des versions finales des articles acceptés pour l’ACL 2026, nous avons identifié plus d’une centaine d’articles contenant des références à des publications inexistantes ». Et elle ajoute qu’« en conséquence, nous avons pris la décision de rejeter d’office ces articles acceptés afin de préserver la qualité et la fiabilité des actes du colloque ».

Commentaires (45)
Abonnez-vous pour prendre part au débat
Déjà abonné ou lecteur ? Se connecter
Cet article est en accès libre, mais il est le produit d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles d'un média expert
Profitez d'au moins 1 To de stockage pour vos sauvegardes
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 18 mai à 12h37
Le 18 mai à 13h40
Modifié le 18 mai à 14h33
Pour les langues, il n'est pas rare de trouver des sources qui ne sont pas en anglais. Beaucoup de thèses sont écrites dans la langue native du doctorant, des conférences nationales se font dans la langue du pays. Je ne sais pas si ça existe encore en France, mais il existe(ait?) des journaux dans une autre langue que l'anglais. Enfin, tu te retrouves à citer un article du siècle dernier écrit en allemand, car c'est l'article qui a initialement décrit un élément de tes travaux.
Edit : je n'ai pas parlé des consortiums, qui, lorsque ça publie un article, inclus facilement une 50aine d'auteurs de domaines variés dans un énorme article qui couvre justement un peu tous les domaines.
Le 18 mai à 14h24
Ben en fait, non, puisque tu ne l'as pas lu, comment es-tu en droit d'affirmer quoi que ce soit sur cette référence ?
Le 18 mai à 14h52
Si je ne comprends pas l'allemand, je ne peux pas citer "Zur Elektrodynamik bewegter Körper" et je suis donc interdit d'utiliser des éléments introduit par ce document ? Je ne comprends pas l'allemand, mais il n'y a aucun doute de ce qui est introduit par cet article et tu peux être assez serein à le citer lorsque tu parles de relativité restreinte.
Le 18 mai à 15h10
Non, tu ne peux pas. Tu pourras citer un article en Anglais ou en Français d'un auteur qui, lui, comprend l'Allemand, ou une traduction de cet article dans une langue que tu comprends.
Si on en est à se contenter de Jean-Michel Àpeuprès qui "voit" ce que dit l'article rien qu'à une traduction approximative du titre, effectivement, on peut se lâcher et tout torcher à l'IAgen, à ce stade, plus rien n'a aucune importance.
Le 18 mai à 16h33
Le 18 mai à 17h14
Être chercheur, c'est beaucoup d'humilité, il faut savoir accepter de ne pas tout savoir, de ne pas pouvoir tout savoir. Il y a des compétences et des connaissances que tu n'as pas. Tu pourrais passer beaucoup de temps pour les acquérir, mais tu peux aussi tout simplement demander à une autre personne qui possède justement ces compétences/connaissances de travailler avec toi. Il pourra t'expliquer dans les grandes lignes ce qu'il faut, tout comme toi, tu pourras l'expliquer dans les grandes lignes, mais tu ne pourras pas comprendre dans le détail ce qu'il faut sans avoir à te taper les 5 ans d'études, les 3 ans de thèse et les 10 aines d'années d'expérience pour atteindre son niveau de compréhensions du problème. C'est un expert dans son domaine, tu vas lui faire confiance dans ce qu'il raconte, dans ce qu'il fait, et dans les articles qu'il trouve pertinents de cité.
Pour diverses raisons, il faut citer l'article "original", celui qui introduit la notion, la théorie. "Zur Elektrodynamik bewegter Körper" : c'est l'article d'Einstein qui introduit les bases de la relativité restreinte. Il a été analysé en long en large et en travers, même sans comprendre l'allemand, le contenu a été largement discuté et analyser. Si tu dois citer un article lorsque tu parles de la relativité restreinte, c'est celui-là. Il faut citer l'article original. Dans mon cas, c'était un genre bactérien, je ne vais pas citer un autre article que l'article original, le premier, la source, je cite donc les auteurs et leur article, qui était en allemand. Et dans le fait, dans mon cas, j'associe juste un nom de genre bactérien à un identifiant unique qu'est la publication, le contenu de l'article dans ce cas est assez secondaire, je veux juste bien identifier le genre bactérien.
Dans la recherche, un élément central, c'est faire un minimum confiance aux autres et à leur sérieux. La recherche se crée par accumulation de connaissance, si untel à démontrer quelque chose dans un article publié dans une revue, tu ne vas pas t'amuser à refaire toutes les manipulations qu'il a faites pour l'accepter. Normalement, ça a été relu par les pairs (pas dans arxiv, qui est de la prépublication). Tu n'as surement jamais lu un article, mais en réalité, un article, tu l'analyses rarement en détail. Tu vas le lire globalement, porter l'attention sur les points qui t'intéressent, accepter certaine chose sans trop chercher à comprendre en détail, laisser des parties que tu t'en fous (typiquement, dans le matériel, tu passes au travers, surtout dans les parties qui ne t'intéressent pas, et pour les méthodes, tu ne vas pas forcément regarder les détails), tu gardes un peu d'esprit critique (surtout dans les parties qui sont dans ton domaine). Lire un article et le comprendre dans les moindres détails, c'est impossible, tu as toujours des éléments manquant (le choix d'une méthode au lieu d'une autre par exemple), et même là, c'est le condenser d'années de travail, de discussion, il y a des détails qui te passeront à côté, même après de multiples lectures.
Nous ne sommes pas natifs anglais pour la très grande majorité. Nous avons une maîtrise assez limitée de cette langue. Un article écrit par un non-anglophone n'est pas parfaite, et même un article écrit par un anglophone aura tendance à utiliser des formulations peu commune. À ceci s'ajoute que le lecteur n'est pas anglophone pour la majorité et la compréhension n'est pas tout le temps aisée (je suis tombé sur des phrases, trois personnes : trois interprétations différentes). Donc même si l'anglais est la langue qui est majoritairement utilisée en science, nous sommes déjà majoritairement des "Jean-Michel Àpeuprès". Et encore, nous avons de la chance, en tant que français, nous partageons une racine indo-européenne avec l'anglais. Pour les asiatiques, c'est un tout autre niveau : un apprentissage très moyen d'une langue qui ne ressemble pas du tout à la leur. C'est pour ça que je n'ai pas été étonné lorsqu'il a été démontré qu'une forte proportion des articles écrits pas des chercheurs asiatiques sont écrite à l'aide de LLM : ils doivent surement écrire en natif, ou dans un anglais approximatif, et demande à un LLM de le réécrire proprement. Donc même citer un article écrit en anglais ne garantie pas qu'il y a été parfaitement lu et compris. Du coup, ton problème de "Jean-Michel Àpeuprès" c'est déjà le cas pour la majorité.
Le 18 mai à 20h21
Pff, ben je peux dire que tu n'as clairement aucune connaissance de quels sont les processus pour arriver à un article rédigé et publié ;) Ou alors qu'on n'est pas dans les mêmes domaines de publication, chez moi, le modèle du loup solitaire est encore très courant: en sciences humaines, on a des idées, mais pas les moyens...
c'est faire un minimum confiance aux autres et à leur sérieux
Ça c'est clair, même quand je fais une relecture, je commence par faire confiance, puis peut venir le moment où la confiance se dégrade
Le 18 mai à 21h56
Le 19 mai à 10h36
En médecine, il y a des fois pls dizaines d'auteurs, mais c'est le grand n'importe quoi (certains ne savent même pas qu'ils ont cet article dans leurs publications - parlons de la rupture de confiance !) et c'est pas un gage de sérieux.
Le 19 mai à 13h11
Et personnellement, je préfère cette dernière approche : j'ai déjà vu des ingénieurs faire un boulot monstre dans le travail des données, qui ont eu un énorme impact sur la direction de la recherche par leur travail.
Le 19 mai à 10h33
Et donc, selon toi, la solution pour avoir de l'humilité, c'est d'empiler des références pour faire étalage d'une pseudo connaissance d'un sujet ?
Comme dit, il y a quelques exceptions (et tu remarqueras que tu parles certainement d'une référence qui prédate l'IAgen, et donc pour laquelle on peut accorder un certain niveau de confiance).
Je sais pas depuis quand tu fais de la recherche, mais quand j'ai commencé, il y a un certain nombre d'articles que j'ai potassé en profondeur, précisément parce que construire la science brique par brique, ça suppose de savoir sur quelles briques antérieures tu t'appuies pour ton travail. Donc, certains articles tu les parcours et tu peux les mentionner dans un état de l'art où tu vas identifier ce que tu veux et où tu vas (et donc écarter certaines classes de solutions, que tu citeras parce que tu les as lues, même si pas à la virgule près), et ceux qui sont sur le chemin que tu as choisi d'explorer, et que tu vas pousser plus loin (et là, si tu ne les maîtrises pas, tu n'iras nulle part, en tout cas, c'est comme ça que ça marche en informatique).
C'est exactement ce que je souligne en disant que le processus de publication est parti en couille bien avant l'IAgen, la faute à l'évaluation basée quasiment que sur la bibliométrie ("regarde mon gros h-index, noob !") qui fait qu'on soumet trop, pour des contributions assez légères, et que les reviewers sont surchargés et ne font pas correctement leur boulot. Et ça n'est pas qu'une vue de l'esprit et un problème de labos, ça a de vraies conséquences sur le mon et le vivant (cf. l'étude frauduleuse sur le glyphosate rétractée récemment, qui a servi de cheval de bataille à Monsanto - et à la communauté zet - pour taper sur ceux qui demandent un peu de recul et de prudence)
Soit tu es entouré de billes en Anglais, soit les reviewers ont mal fait leur boulot (les phrases à la limite du compréhensible, il faut éviter). La règle générale, en particulier quand on n'est pas natif, c'est de faire des phrases courtes. Les circonvolutions à la française des Lumières, c'est niet.
Comme dit plus haut, dans la majorité des cas, tu vas identifier si l'article a un intérêt ou une connexion pour ton travail. Le niveau de proximité déterminera le niveau de détail que tu dois en tirer, donc le temps passé à analyser.
Dans l'idéal (tout le monde publie en suivant un processus rigoureux, avec des reviewers sérieux et investis dans leur relecture), oui. Dans la pratique, tu dois toujours avoir une dose de vigilance et de doute, qui doivent te conduire à avoir au moins un regard sur l'article cité, ne serait-ce que vérifier son existence depuis que des collègues utilisent l'IAgen. L'IAgen brise totalement la confiance dans la recherche parce qu'elle est susceptible d'introduire des éléments fictifs ou frauduleux dans l'ensemble de la production scientifique, tout simplement parce que la confiance vient non pas du résultat (l'article écrit) mais du processus qui mène au résultat.
C'est une construction récurrente : parce que tu te bases sur des écrits validés et ayant appliqué la méthode scientifique, et que tu rédiges en suivant cette même méthode, ta contribution peut recevoir la confiance de la communauté. Dès que tu commences à jouer à couper dans les virages pour aller plus vite, c'est mort, tu brises la chaîne et on ne peut plus démontrer que ton travail, ou les travaux subséquents qui se base sur ton travail, sont dignes de confiance.
La collaboration entre équipes est difficile à cause de ça, parce qu'il faut avoir une confiance absolue en tes partenaires (et vice versa), du fait que tu ne sois pas assez au courant de ce qui se fait dans leur domaine pour pouvoir avoir un regard critique sur leur propre partie. D'un autre côté, je vais être cynique une minute sur le sujet : les travaux interdisciplinaires, c'est intéressant quand tu approches d'une application pratique, et (pour cette raison) c'est attendu par les institutions, mais niveau publication, c'est rarement génial (la discipline A trouvera que c'est trop axé sur B et vice versa). Pour ma part, je collabore, je mentionne les partenaires dans la section acknowledgment, mais en général, chaque discipline du projet publie dans ses propres domaines pour un impact plus important et des reviews plus pertinentes.
Le 19 mai à 14h46
J'ai mis le rarement. Car oui, certains articles, tu vas les bosser, car c'est surement un article qui va apporter des éléments centraux pour ton travail. Je le fais toujours. Mais la masse d'articles, c'est surtout ce qui a été démontré qui t'intéresse, pas forcément les détails de comment ça a été démontré (tu lis en biais pour vérifier si ce n'est pas un truc bidon, mais tu ne vas pas forcément chercher à comprendre tous les détails).
Justement, souvent ce sont des articles écrits par des natifs anglais qui ont les tournures les plus alambiquées. Après, il y a toujours des phrases (ou plus des paragraphes) qui sont plus difficiles à comprendre, et ce n'est pas forcément à cause de la langue, mais plutôt à cause de la complexité de ce qui est dit. Limite, il est plus simple de décrire les relations de filiation qu'entretiennent 2 personnes dans la lignée des Ptolémée.
On n'est pas naïf non plus. On ne croît pas tout ce qui est écrit, et on va même ne pas être d'accord avec les conclusions des auteurs. J'ai plusieurs exemples d'article que j'ai lu, voir même d'outils assez communs, qui sont assez douteux.
Je ne suis pas d'accord. Quand tu fais de la recherche interdisciplinaire, si tu as besoin, tu vas justement faire appel à des experts de chaque domaine pour faire les choses correctement. Et tu vas demander à ces personnes leur apport dans l'article, d'écrire des parties, de relire, corriger, ajouter... Mais si tu as fait appel à 2 experts de domaines opposés, ils vont généralement comprendre grossièrement l'intérêt du travail de l'autre, mais clairement pas les détails et encore moins les articles cités.
Après, il y a aussi les consortiums, qui sont des collaborations à plus grande échelle. C'est un autre cas de figure. Mais là, c'est un gros projet, ça permet de réunir énormément de moyen sur un sujet, avec des ressources importantes et une production de données importante (qui sont assez standardisées, ce qui est plutôt cool). Et effectivement, le main paper va avoir une liste d'auteurs très longue qui ont travaillé chacun sur une partie du projet (et souvent, on cite ce main paper, c'est parce qu'on utilise les données produites par ce consortium, pas pour ce qui est dit dedans : tu cites tes sources, incluant les données utilisées).
Le 20 mai à 14h01
Et tu ne peux accorder cette confiance que si ils travaillent avec méthode. Sinon, tu prends le risque que leurs erreurs te retombent dessus, et c'est normal.
Ce que je dis depuis le début.
Le 21 mai à 18h06
Du coup, tu te retrouves vite avec une bonne poignée d'auteurs qui ont tous contribué d'une manière ou d'une autre aux travaux présentés dans l'article, mais dans des domaines d'expertise bien différents et du coup, les articles cités par l'un ne seront pas forcément lus par l'autre (lire un article que tu ne comprends pas un mot, ça n'a aucun intérêt).
A ceci s'ajoute qu'il y a la tradition de citer au mieux ces sources. Tu utilises des données publiques, tu cites l'article d'où elle provient. Aujourd'hui, c'est souvent demander que les auteurs fournissent aussi leurs données avec l'article, cependant les travaux de l'article n'ont pas forcément grand-chose à voir avec les tiens. Pareil, tu utilises un outil, tu cites l'article qui lui est associé. Et effectivement, tu te retrouves avec un article comme celui de BLAST (Basic local alignment search tool) qui est cité 124183 fois (pour l'article original) par des biologistes qui n'ont pas les compétences de comprendre ni le fonctionnement exact de l'outil ni l'article. L'outil, tu l'utilises, tu le cites.
Il y a quand même quelques réunions, où chacun explique sa partie, ce qu'il a fait, pourquoi, et où on discute des résultats et des conclusions. Mais tu te retrouves à collaborer sur des travaux avec des experts de domaines qui n'est absolument pas le tient, il va donc avoir des citations dont tu n'as aucune expertise à valider leur qualité.
Le 21 mai à 21h09
Le 22 mai à 10h33
Donc, si un article est écrit par plusieurs mains (ce qui arrive assez souvent selon les domaines) chaque auteur va être en mesure de vérifier les références qu'il a ajoutées, mais pas forcément celles citées par les autres. Et c'est ce qu'il dit.
Le 22 mai à 11h18
Pire encore, demander que chaque auteur fasse la vérification de toutes les références est un homme de paille, Arxiv n'a jamais demandé ça, et ce pauvre type bondit là dessus parce qu'il se sent en danger vis-à-vis de ça simplement parce qu'il est fortement possible qu'il soit peu regardant dans ses collaborations.
Le 22 mai à 13h52
Et s'il y a un point que je suis assez d'accord, si vraiment, tu veux vérifier une référence, il faut aussi aller vérifier que ce qui est associé à celle-ci se trouve effectivement dedans et que les propos ne soit pas dénaturé. Et alors là, bon courage si tu n'es pas du domaine.
Ce n'est pas le sujet de notre discussion, ce n'est pas sur ce point que l'on débat depuis le début. Les quelques lignes de son intervention me paraissent un peu trop courtes pour réellement faire des extrapolations qui ne soient pas de pures fabulations.
Le 22 mai à 15h17
Le reste, c'est une question de confiance entre co-auteurs. Mais la réaction de Miller est ridicule et semble relever plus de la projection de ses propres manquements que d'un quelconque problème chez Arxiv. En gros, il se plaint qu'on va l'obliger à faire son boulot de chercheur (parce que le reste de son fil de discussion est encore plus ridicule).
Le 22 mai à 16h34
Le 22 mai à 21h18
Le 25 mai à 00h05
Le 18 mai à 12h43
Le 18 mai à 13h23
Les labos ou équipes dans lesquels le directeur est automatiquement dans les papiers publiés par les membres, ça risque d'être folklorique.
Le 18 mai à 14h00
Le 18 mai à 14h24
Le 18 mai à 14h19
Et après on va pleurer sur la perte de confiance des citoyens envers la science.
Le 18 mai à 15h05
Si un de mes co-auteurs, pendant la phase de rédaction, cite un article pertinent dans sa spécialité, je me devrais de vérifier qu'il est cité à bon escient ? Non seulement c'est impossible car très souvent un travail collaboratif implique des compétences variées que chacun ne peut pas maitriser (bah oui sinon on s'embêterait pas à collaborer), mais en plus on n'est pas là pour fliquer ce qu'écrivent nos collègues. Oui l'auteur principal peut être tenu responsable de l'ensemble de l'article, mais pas l'ensemble des co-auteurs qui parfois ont contribué sur un aspect précis.
Le 18 mai à 15h12
Si tu délègues à n'importe qui, tu mérites autant la sanction que celui qui a commis la faute.
Le 18 mai à 16h42
Le 18 mai à 16h56
Le 18 mai à 17h35
A la base, c'est une façon de mettre à disposition gratuitement et à tous, un article en cours de validation. Dans certain domaine, l'étape de publication peut prendre beaucoup de temps (plusieurs années), du coup l'idée du site et de laisser les chercheurs déposer leur "preprint" sur la plateforme, il sera disponible immédiatement, gratuitement et même après publication.
Ils ne sont pas cependant par relu par les pairs, et même si la grande majorité des articles qui y sont déposés sont honnêtement faits, tu as toujours des petits malins qui déposent ce genre de chose.
L'utilisation d'arXiv a évoluer. Le domaines du machin learning évoluant si vite a travers les réseau de neurones, les articles étaient déjà dépassés avant qu'ils soient publié, le dépot sur arXiv est devenu une norme. C'est même arrivé à un point que beaucoup d'articles (surtout de chez les GAFAM) y sont déposés sans jamais être publiés dans un quelconque journal. Par exemple, tu vas trouver Attention Is All You Need, qui est l'article qui introduit les couches d'attention, qui est le cœur des LLM (les ChatGPT&co) là, mais qui n'a jamais été publié dans aucun journal (donc si tu parles de couche d'attention, tu vas citer la référence sur arXiv)
Le 18 mai à 22h40
Le 19 mai à 08h21
Que l'éditeur prenne un abonnement, en soit, ce n'est pas déconnant (il y a quand même un minimum de service et l'infra à payer). Mais les tarifs totalement exhorbitants, c'est juste du grand n'importe quoi (pour ne pas dire du vol).
Le 19 mai à 09h33
Le 19 mai à 11h25
Ca, par contre, c'est totalement honteux. Surtout de la part d'un éditeur comme Elsevier (qui est effectivement un des plus gros éditeurs). Cela montre bien que la plus value d'un tel éditeur aujourd'hui est vraiment très très faible.
Historiquement, avant l'informatique et surtout internet, ces éditeurs avaient une réelle utilité quant à la diffusion des savoirs.
Un éditeur digne de ce nom devrait bannir les auteurs de l'article, mais aussi bannir les reviewers dans le cas présent... (oui, je suis sévère et j'assume
Le 19 mai à 12h41
En science, les éditeurs ont toujours fait le strict minimum (la relecture est faite bénévolement par des chercheurs), c'est à dire imprimer les actes de conférence/les journaux. Le reste est à la charge des chercheurs (ceux qui publient, ceux qui relisent, ceux qui gèrent les journaux/confs)
Le 19 mai à 13h19
Aujourd'hui, tout est fait par les chercheurs eux-mêmes (y compris la mise en page de leur article). Et la diffusion ne requiert plus ces éditeurs. Il reste toutefois des articles fondateurs qui ne sont accessibles que par ce biais malheureusement... (et je suppose que ça, c'est un problème rencontré un peu dans tous les domaines anciens).
Le 20 mai à 14h03
Même sur des articles récents, quand tu publies à l'IEEE ou chez Springer, tu cèdes tes droits sur le document.
Le 20 mai à 14h18
Alors, tu cèdes des droits oui. Tu cèdes tes droits, là, j'avoue que je ne me souviens plus. En général, les chercheurs ne publient pas directement leur article auprès d'un éditeur spécifique, mais le soumette lors d'une conférence ou d'un call for paper. Et c'est ensuite l'éditeur partenaire de l'événement qui publie l'article.
Mais beaucoup d'auteurs fournissent malgré tout une version (parfois non finalisée) sur Arxiv. Ou dans le pire des cas, si l'auteur est encore en vie, un petit mail et généralement, il est très content de fournir une version PDF de son article (et de savoir qu'il est lu
Dans mon domaine en tout cas (l'informatique), c'est le cas. On peste suffisamment contre les coûts totalement prohibitifs de ces éditeurs pour essayer de les contourner au maximum.
Le 20 mai à 15h36
Ha ça, l'abo IEEE ou Springer pour qql GB de transfert par mois (pour une institution donnée), c'est une arnaque totale.
Le 31 mai à 11h46
https://www.cnrs.fr/fr/actualite/frais-de-publication-nous-sommes-au-bord-du-gouffre
Le 19 mai à 11h44
D'un côté, les éditeurs qui peuvent bâcler ou radiniser sur le travail éditorial (correction pas terrible, typographie bof, etc.), et de l'autre l'autoédition qui peut prendre de sacrés raccourcis crado avec peu de relecture avant et des couvertures IA dégueulasses.
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?