

OpenAI : les injections de prompts resteront « un défi pour de nombreuses années »
Prise de devants

Dans un billet de blog publié ce 22 décembre, OpenAI a abordé plus en détail la sécurité de son navigateur Atlas. L’entreprise a notamment décrit la formation d’un agent spécialement entrainé pour trouver des failles. Elle reconnait cependant que les injections de prompts resteront possibles pour longtemps.
Le billet d’OpenAI se concentre sur les attaques par injection de prompts, aussi appelées injections rapides. Spécifiques à l’IA générative, elles tablent sur l’exploration par un chatbot de ressources contenant des instructions malveillantes cachées. Une requête peut par exemple envoyer ChatGPT visiter une certaine page sur un site, laquelle abrite un autre prompt, que l’IA va analyser et interpréter comme tel, avant de satisfaire la demande. Le résultat peut être notamment une fuite d’informations personnelles.
« À titre d’exemple hypothétique, un attaquant pourrait envoyer un courriel malveillant tentant de tromper un agent pour qu’il ignore la demande de l’utilisateur et transmette à la place des documents fiscaux sensibles vers une adresse e-mail contrôlée par l’attaquant. Si un utilisateur demande à l’agent de revoir les e-mails non lus et de résumer des points clés, l’agent peut ingérer cet e-mail malveillant pendant le flux de travail. S’il suit les instructions injectées, il peut s’écarter de sa tâche et partager à tort des informations sensibles », explique ainsi OpenAI.
Atlas au premier plan
Problème pour OpenAI : tout ce qu’il est possible de faire avec l’interface classique de ChatGPT l’est avec les agents. Selon les instructions données, ces derniers exécutent même leur mission de manière automatisée. Et puisqu’ils sont au cœur du navigateur Atlas, OpenAI fait le pari de communiquer directement sur la question.

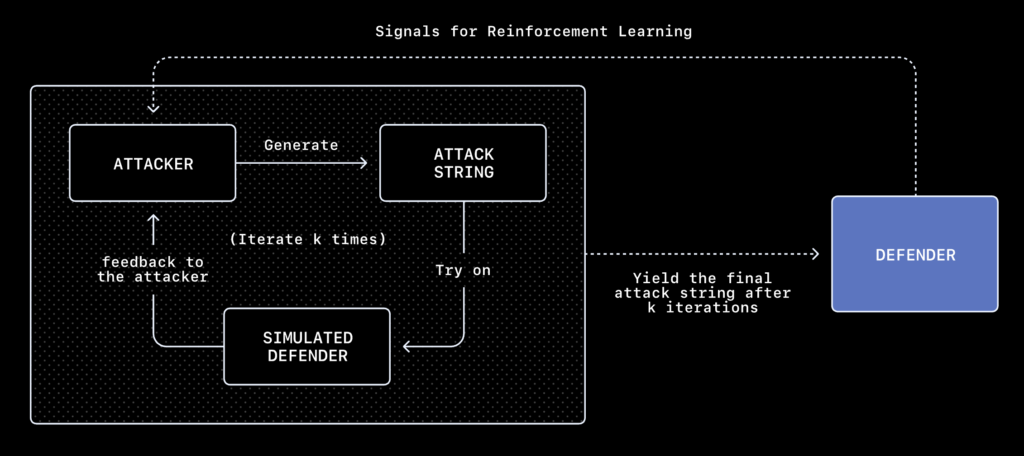
Cette publication se fait à la faveur d’une mise à jour du modèle, décrit comme mieux entrainé et doté de meilleures protections contre les injections. OpenAI ajoute que cette mise à jour a été déployée suite à la détection d’une série d’attaques par sa « red team automatisée interne ». Une « red team » est une équipe chargée de tester les défenses d’un produit. Dans le cas présent, OpenAI évoque un agent spécialement créé et entrainé dans cet objectif.
Reconnaissant que le « mode agent élargit la surface d’attaque », l’entreprise en a formé un pour attaquer son navigateur. Il fonctionne par renforcement et est décrit comme s’adaptant sans cesse pour trouver de nouvelles portes d’entrée. OpenAI indique avoir accès à la liste de toutes les opérations tentées, l’agent étant présenté comme plus rapide dans ses approches qu’aucun humain ne pourra jamais l’être. Il est basé sur un LLM et se comporte comme un pirate survitaminé, selon l’entreprise.
Pour OpenAI, cette méthode a deux gros avantages : l’approche proactive forçant une adaptation rapide et l’analyse du comportement de tous les agents impliqués, aussi bien en attaque qu’en défense. L’agent attaquant peut lui aussi analyser le comportement des agents présents dans Atlas, pour itérer et lancer une boucle de rétroaction : chaque « décision » prise par Atlas est scrutée pour trouver une faille.
Un problème « à long terme »
Si OpenAI veut montrer qu’elle prend le problème des attaques par injection très au sérieux, elle reconnait dans le même temps qu’il ne sera probablement jamais circonscrit.
« Nous nous attendons à ce que nos adversaires continuent de s’adapter. L’injection rapide, tout comme les arnaques et l’ingénierie sociale sur le web, est peu susceptible d’être un jour complètement « résolue ». Mais nous sommes optimistes quant à une boucle de réponse rapide proactive, très réactive et capable de continuer à réduire de manière significative les risques réels au fil du temps », reconnait l’entreprise dans son billet de blog.
OpenAI parle de « lucidité » sur le compromis entre puissance et surface d’attaque. Cette communication a en outre un autre effet : le sous-texte est que tous les navigateurs agentiques sont concernés, avec des piques invisibles lancées aux concurrents comme Perplexity et son Comet, et surtout Google avec Chrome. Et que dire d’un Windows 11 agentique ?

Commentaires (8)
Abonnez-vous pour prendre part au débat
Déjà abonné ou lecteur ? Se connecter
Cet article est en accès libre, mais il est le produit d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles d'un média expert
Profitez d'au moins 1 To de stockage pour vos sauvegardes
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousModifié le 23/12/2025 à 10h29
Seuls les contenus venant de l'utilisateur (par son interface homme machine) doivent être des prompts, le reste c'est de la donnée à traiter mais pas des commandes à exécuter.
Le 23/12/2025 à 10h55
Par exemple, si je donne en entrée un CSV au LLM pour lui demander de faire des stats dessus, le prompt contiendra à la fois :
Leur candeur est le gros point faible des LLM aujourd'hui. D'un certain point de vue, au même titre qu'on (les humains) apprend à repérer des patterns d'attaque informatique, les LLM doivent aussi apprendre à les détecter et la sécurité des modèles se renforcer pour ne pas bypass les instructions du system prompt ou du fine tuning.
On en est qu'au début, je pense. L'OWASP a un site dédié à la sécurité de l'IA générative qui est très intéressant pour se rendre compte de la surface d'attaque.
Le 23/12/2025 à 11h32
Le 23/12/2025 à 11h41
L'OWASP donne déjà des recommandations pour limiter les risques liés au prompt injections et liste aussi les schémas d'attaque courants.
C'est aussi le problème des LLM : comme c'est un système versatile au comportement moins prévisible, sa surface d'attaque est beaucoup plus vaste et complexe à anticiper qu'un logiciel ordinaire plus déterminé dans son fonctonnement.
Le 23/12/2025 à 11h13
Si on insère des commandes en guise de contenu et qu'elle est prise en compte, la commande prend le pas.
Et tant que ces dispositifs ne sauront pas faire preuve de compréhension (donc conceptualisation) du contexte ce sera l'arlésienne. Ce qui à regarder les résultats n'arrivera pas de sitôt.
En bref la société dit qu'il n'y a pas de solution. Elle vient elle même de décrire que l'IA est conne et qu'il n'y a pas de solution. Et que donc son produit est voué à l'échec... En tout dans certains domaines applicatifs. C'est plutôt une bonne nouvelle pour l'humanité.
La suite c'est que les gens qui s'occupent de sécuriser ces IAs vont faire le travail de rendre les dispositifs de plus en plus proche d'un... Wiki. Autant de pognon envoyé par brouette et de dévastation écologique pour ça, ça fait réfléchir.
Le 23/12/2025 à 10h31
Ça disait en gros que l'injection de prompt, c'est inhérent aux LLMs. Ça fait partie du truc, c'est juste inévitable.
Le 23/12/2025 à 10h44
https://llm-attacks.org/Bon courage.
Le 23/12/2025 à 13h19
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?