Pour Canonical, l’intelligence artificielle se répartit en deux grandes catégories : l’IA implicite, qui améliore discrètement des fonctions existantes, et l’IA explicite, qui correspond à des fonctions que l’on appelle en toute connaissance de cause. Dans notre article du 8 juin, nous évoquions quelques exemples d’IA implicite donnés, comme l’amélioration de l’autofocus pour la webcam ou la qualité du son sur le micro. Ces opérations pourraient être réalisées assez simplement depuis un modèle local.
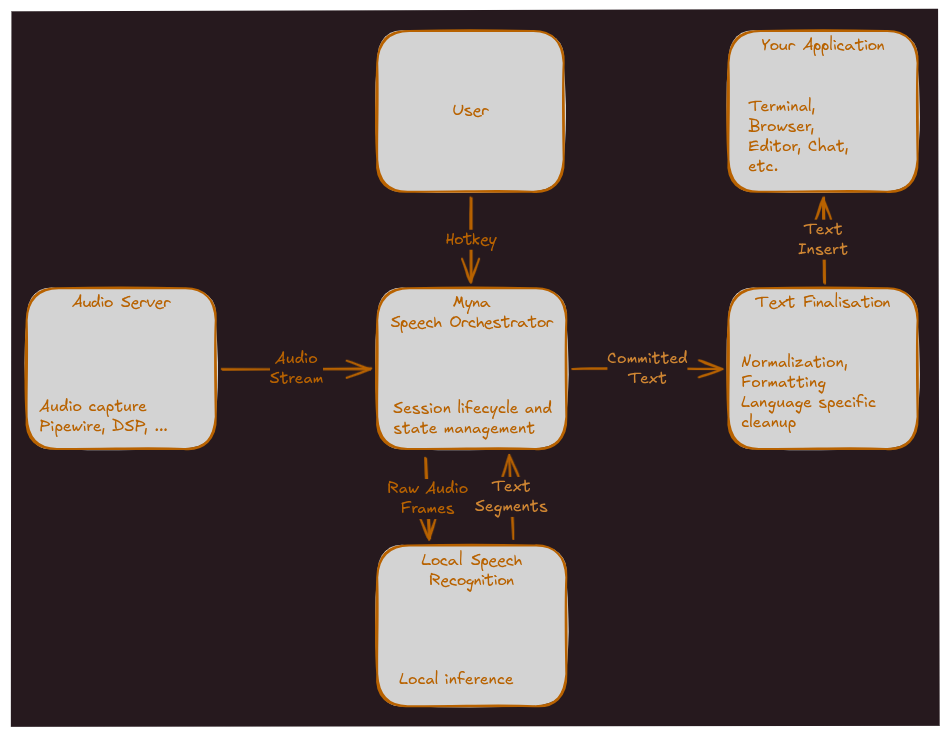
La seule fonction d’IA explicite prévue était alors une dictée vocale à l’échelle de tout le système. Le 17 juin, Canonical a précisé dans un billet son projet, nommé Myna : « une nouvelle initiative visant à introduire la dictée vocale sur Ubuntu Desktop. Nommé d’après le myna [mainate religieux en français, ndlr], connu pour sa capacité à imiter la parole humaine, le projet vise à offrir une expérience de dictée qui ressemble naturellement à un ordinateur de bureau tout en respectant la confidentialité des utilisateurs et fonctionnant entièrement sur du matériel local ».

L’éditeur confirme l’arrivée de cette fonction dans Ubuntu 26.10, qui arrivera en octobre. Il s’agira d’une première version, au fonctionnement simple : en appuyant sur une touche, on déclenchera l’écoute et le texte s’affichera dans le champ texte de l’application utilisée. Cette première version visera Ubuntu Desktop sous Wayland avec GNOME. Canonical ajoute que l’architecture sera « suffisamment ouverte pour supporter d’autres environnements de bureau à l’avenir ».
Canonical affirme que la fonction est pensée dès la conception pour la confidentialité. Elle ne fonctionnera qu’en local, sans besoin d’une connexion internet. L’accès au microphone ne se fera qu’avec l’activation explicite du raccourci clavier. Quant à l’audio récupéré, il est effacé de la mémoire après avoir été traité et rien n’est envoyé sur des serveurs.
Ubuntu dit chercher des retours sur cette fonction. Un dépôt GitHub a été ouvert pour l’occasion, mais on ne trouve pour l’instant qu’un peu de documentation.
Commentaires (6)
Abonnez-vous pour prendre part au débat
Déjà abonné ou lecteur ? Se connecter
Cet article est en accès libre, mais il est le produit d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles d'un média expert
Profitez d'au moins 1 To de stockage pour vos sauvegardes
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 22 juin à 12h48
Le 22 juin à 14h19
Modifié le 23 juin à 10h43
C'est pas vraiment confidentiel dans mon cas, plus une question de réactivité en situation d'urgence.
Dans mon cas il y a de la synthèse vocale aussi (mais ça il me semble que c'est moins un souci aujourd'hui)
On verra...
Le 22 juin à 15h32
À mon sens c'est un cas d'usage de l'IA pertinent, et le traitement en local + solution open source indique clairement la bonne direction. Maintenant, à voir ce que ça donnera au final, surtout sur les machines les plus modestes.
Le 22 juin à 16h46
Le 30 juin à 06h52
L'IA apporte quelque chose ici ?
"IA" ne serait pas un simple rewording des algo existants de dictée vocale ? (sans doute basée depuis des années sur du deep-learning)
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?