

[MàJ] OpenAI lance vraiment GPT-5.6 Sol, Terra et Luna
GPT-5.6 derrière un cordon de sécurité
![[MàJ] OpenAI lance vraiment GPT-5.6 Sol, Terra et Luna](https://next.ink/wp-content/uploads/2025/08/Openai2.webp "[MàJ] OpenAI lance vraiment GPT-5.6 Sol, Terra et Luna")
Sol, Terra et Luna : les trois versions de GPT-5.6 sont maintenant disponibles, après quelques semaines de purgatoire à la Maison Blanche.
Mise à jour, 9/07 — Après quelques semaines en accès limité, GPT-5.6 a reçu le feu vert de l’administration Trump pour être lancé auprès du grand public.
Article original, 26/06 — GPT-5.6 est finalement disponible, deux mois après la précédente version du grand modèle de langage d’OpenAI. Enfin, disponible… façon de parler. En vertu d’un décret du président Trump, l’entreprise limite le déploiement à quelques organisations et entreprises triées sur le volet. Le labo IA espère pouvoir distribuer le modèle aussi largement que possible « dans les prochaines semaines ».
Une situation loin d’être idéale et qui ne fait pas les affaires d’OpenAI. « Nous ne pensons pas que ce type de processus d’accès gouvernemental doive devenir la norme à long terme », écrit la société. « Il prive des meilleurs outils les utilisateurs, les développeurs, les entreprises, les défenseurs en cybersécurité et les partenaires internationaux qui en ont besoin », ajoute-t-elle. OpenAI dit continuer de travailler avec l’administration Trump pour améliorer le cadre prévu du décret présidentiel sur la cybersécurité.
GPT-5.6 : un modèle à voir de loin
Dont acte, il faudra donc se contenter de GPT-5.5 pendant quelques temps avant de pouvoir juger de son successeur sur pièces. Ou plutôt, de ses successeurs car OpenAI a opté pour trois versions de son modèle :
- GPT-5.6 Sol est présenté comme le modèle le plus puissant du lot. OpenAI assure qu’il est le plus calé pour les tâches les plus complexes, comme le code, les raisonnements longs, la biologie, la cybersécurité et les usages agentiques. Sol reçoit également les garde-fous les plus costauds (on va y revenir).
- GPT-5.6 Terra est le modèle intermédiaire, pensé pour les usages quotidiens avec un équilibre entre performances et coûts. Ses performances devraient le mettre au niveau de GPT-5.5, tout en étant deux fois moins cher, promet OpenAI.
- GPT-5.6 Luna est le modèle rapide et abordable de la gamme. Il se destine aux usages où la vitesse et le prix comptent davantage que les performances brutes.
On pourra voir dans cette gamme un certain alignement avec Anthropic et ses modèles Haiku, Sonnet et Opus.
Deux modes de consommation sont proposées : « max », qui donne à GPT-5.6 Sol davantage de temps pour raisonner sur des tâches complexes. Et « ultra », qui mobilise plusieurs agents capables de travailler en parallèle sur des tâches plus lourdes.

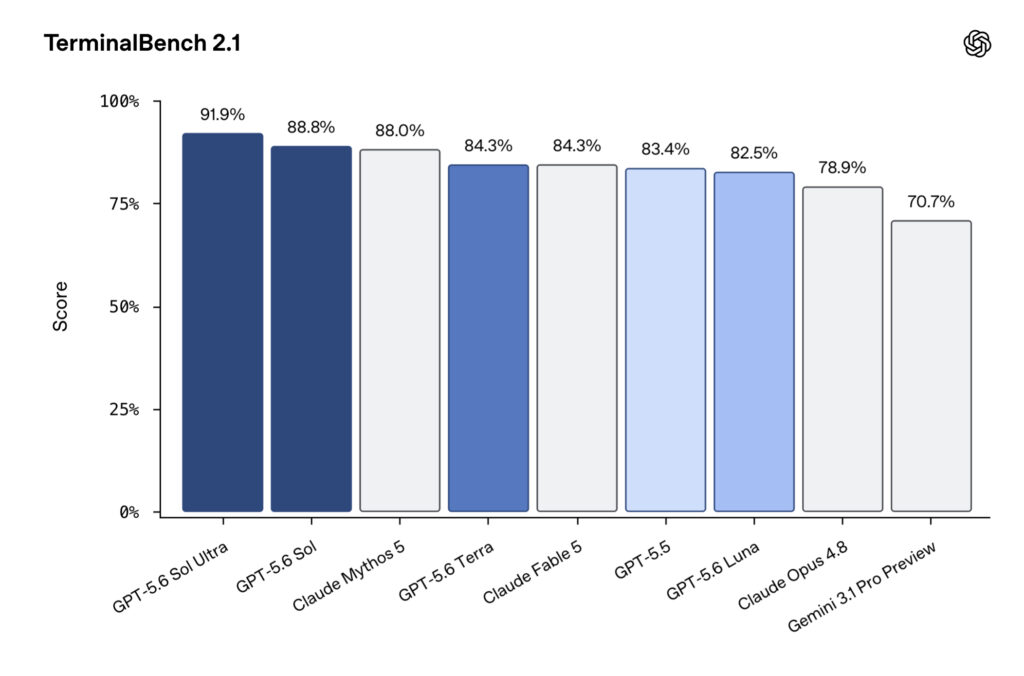
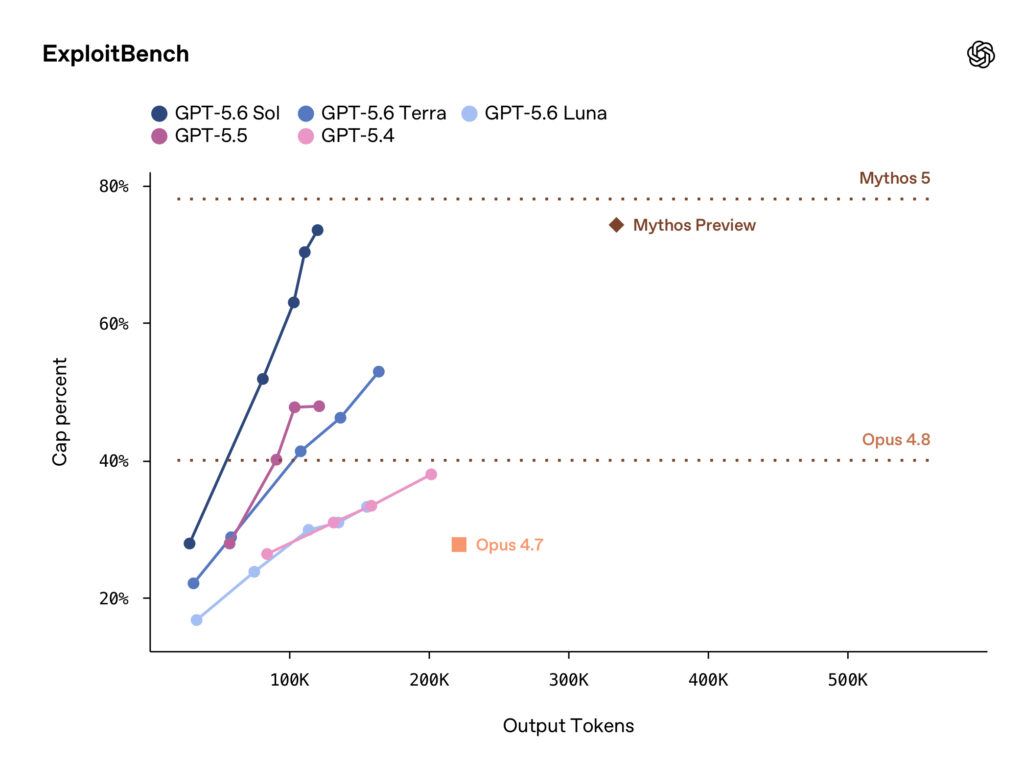
GPT-5.6 Sol se veut donc particulièrement performant sur les tâches liées au code. Sur le benchmark Terminal‑Bench 2.1, les versions standard et Ultra affichent des scores légèrement supérieurs à celles de Mythos 5. Mais OpenAI insiste surtout sur les capacités du modèle pour la cybersécurité (recherche de vulnérabilités et leur exploitation). Sol rivalise avec Mythos Preview sur ExploitBench, en n’utilisant qu’un tiers des tokens en sortie.
La sécurité en bandoulière
Ces super-pouvoirs sont sévèrement encadrés, tient à rassurer OpenAI. Toute la chaîne de sécurité autour de GPT-5.6 Sol a été renforcée, avec des garde-fous directement entraînés dans le modèle, des systèmes de détection en temps réel, des contrôles au niveau des comptes et un accès différencié en fonction des usages.
Il s’agit de compliquer la vie des pirates qui voudraient exploiter ces capacités pour pénétrer par effraction dans des infrastructures sensibles. Mais sans bloquer pour autant les travaux légitimes de recherche et de correction de failles, de débug ou de formation. OpenAI ajoute que certaines activités peuvent entraîner une vérification au niveau du compte, pour distinguer un usage défensif licite d’un comportement malveillant répété.
« Lors d’évaluations portant sur Chromium et Firefox, [GPT-5.6 Sol] a identifié des bugs et des éléments pouvant servir à construire un exploit, mais il n’a pas été capable de produire seul une chaîne d’exploitation complète et fonctionnelle dans les conditions testées. »
OpenAI insiste tout particulièrement sur le travail mené pour contrer les tentatives de jailbreak, qui poussent les modèles à contourner leurs mesures de sécurité. Plus de 700 000 heures de calcul (en équivalent GPU A100) ont été consacrées à du red teaming automatisé : les propres modèles d’OpenAI ont tenté de chercher des failles dans les garde-fous.
Il s’agissait de détecter des jailbreaks « universels » qui peuvent fonctionner dans toute sorte de contextes, pas uniquement sur une requête précise. Des experts humains sont également mobilisés, et les tests se poursuivent durant la phase d’aperçu. Les premiers testeurs pourront d’ailleurs buter sur des restrictions qui bloqueront ou refuseront certaines demandes. D’autres requêtes prendront davantage de temps de traitement, afin de procéder à des examens de sécurité supplémentaires.
Tokens raisonnables
Les tarifs intéresseront les entreprises qui font bûcher les agents IA pour produire du code et qui voient les factures s’alourdir invariablement. La grille des prix de GPT-5.6 est la suivante :
- GPT-5.6 Sol : 5 $/1 million de tokens en entrée ; 30 $/1M en sortie ;
- GPT-5.6 Terra : 2,50 $/1M en entrée ; 15 $/1M en sortie ;
- GPT-5.6 Luna : 1 $/1M en entrée ; 6 $/1M en sortie.
Sol a ceci d’intéressant que ses tarifs sont identiques à ceux de GPT-5.5. Quant à Terra, ils sont tout simplement deux fois moins chers, pour des performances annoncées comme similaires. Un caillou dans le jardin d’Anthropic, dont les derniers modèles se montrent très gourmands.
OpenAI ajoute que GPT-5.6 Sol pourra tourner sur l’infrastructure Cerebras avec une vitesse pouvant atteindre 750 tokens par seconde. De quoi offrir des temps de réponses beaucoup plus rapides pour les clients professionnels exigeants disposant des ressources financières nécessaires.
GPT-5.6 améliore aussi le « cache de requêtes », un mécanisme présent depuis octobre 2024 chez OpenAI qui permet de réduire les coûts quand un développeur réutilise plusieurs fois le même contexte dans ses requêtes. Le nouveau modèle conserve les éléments réutilisables d’une requête pendant au moins 30 minutes ; l’écriture dans le cache coûte 1,25 fois plus cher, mais la lecture (la réutilisation) bénéfice de 90 % de remise. C’était 50 % au lancement de cette fonction. Par ailleurs, les développeurs pourront mieux découper leurs prompts pour choisir les parties à garder en cache et à réutiliser ensuite.

Commentaires (12)
Abonnez-vous pour prendre part au débat
Déjà abonné ou lecteur ? Se connecter
Cet article est en accès libre, mais il est le produit d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles d'un média expert
Profitez d'au moins 1 To de stockage pour vos sauvegardes
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousModifié le 26 juin à 23h19
OpenAI n'augmente pas le prix de ces abonnement visuellement, mais c'est tout comme, en deux mois et demi, les quotas d'usages ont été divisés par 5, pour forcer les clients à passer aux abonnements supérieur.
"Plus" est devenu "Pro" en terme d'usage (et quotas largement amoindris), qui dans sa version à 100$ a été coupé en deux un mois plus tard. Et la version à 200$ permettait par le passé, deux fois plus.
Un jour, j'espère vraiment que certaines personnes vont se pencher sur ces pratiques.
Le 27 juin à 09h21
Modifié le 27 juin à 11h58
La seule fois où ils ont été transparents, c'est pour l'offre pro 100$ annoncée x10 durant un mois, pour un passage en x5 aussi; comparé à l'abonnement "plus", mais juste avant ça, il avait déjà divisé par 3 ou 4, à vue de nez, les usages possibles avec la formule "plus".
Et là dernièrement, sans avertir, ils ont encore réduit les usages de tous les abonnements, plus, et pro.
Il y a un énorme problème de transparence sur les formules avec abonnement, que ce soit chez OpenAI avec Codex, Claude, et les concurrents chinois.
Le 27 juin à 18h05
Anthropic, OpenAI sont guère différents dans leur stratégie d'un dealer de drogue. D'abord la 1er dose gratuite, puis une fois que le client revient on exploite son besoin de dépendance pour augmenter les prix. Mais pas trop brutalement sinon le client part. En gros, tu adaptes ton prix en fonction du degré de dépendance de ton client.
Ici c'est la même chose. Il augmente progressivement pour faire revenir du cash qu'ils ont en manque cruellement tout en évitant de faire fuir les utilisateurs.
Le 27 juin à 18h24
Le 29 juin à 10h01
-> nouvelle version = augmentation de la valeur du produit > augmentation de prix possible
-> Pas de contrat long terme = haussi de prix possible de mois en mois, si t'es pas content tu t'en vas.
C'est le même principe que pour les telco.
De fait, je ne vois pas en quoi ce serait fleurter avec l'illégalité.
Modifié le 29 juin à 10h22
Le 29 juin à 10h38
On peut critiquer la pratique. Mais il n'y a rien d'illégal : ils sont libres de fixer les prix et conditions qu'ils souhaitent. A moins qu'il y ait eu un engagement contractuel qui fixe cela durant la durée du contrat (si aucune clause de révision n'est prévue), ce qui n'est pas le cas.
Et je ne dis pas cela pour défendre OpenAI, car c'est un principe qui s'applique plus largement dans le commerce en général.
Le 29 juin à 14h22
On t'accoutume à un service, puis on fait évoluer successivement les tarifs, on ajoute de la pub que tu peux enlever contre une option payante... Bref ils refont exactement la même chose.
Le 29 juin à 13h21
une fois accro là....
Pour rappel, en début de mois un article indiquait qu'un abonnement de 200$ chez eux leur coutait 14000$
A un moment quelqu'un doit payer la facture et plus vite se sera, plus vite la bulle explosera (ou à minima on reviendra à un équilibre)
Le 27 juin à 09h47
Le 29 juin à 18h26
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?