

Mistral veut bousculer la gestion des documents avec son modèle OCR 4
Plus de dame du CDI

Mistral a lancé la quatrième version de son modèle dédié à l’OCR, la reconnaissance de texte. Mais de simple extracteur de texte, le modèle spécialisé devient un parseur documentaire sémantique, que Mistral présente comme particulièrement adapté aux pipelines de recherche ou au RAG. L’entreprise parle désormais d’intelligence documentaire.
Le nouveau modèle Mistral OCR 4 lancé ce 23 juin vise l’extraction d’informations et la restitution de représentations structurées de documents entiers. Cette nouvelle version va donc plus loin que la seule extraction de données, au point que le nom même du modèle devient peu représentatif de ce qu’il a vraiment dans le ventre.
Selon Mistral en effet, OCR 4 « extrait et structure le contenu d’un large éventail de documents ». Tous les formats courants comme PDF, DOC, PPT et ODF sont pris en charge. « Là où les générations précédentes se concentraient sur la conversion d’une page en texte et tableaux clairs, OCR 4 restitue une représentation structurée du document », avec encadrés « englobants » (bounding boxes), classification par blocs et scores de confiance par page et par mot.
Ce que fait le nouveau modèle
Dans son communiqué, Mistral assure que ces encadrements étaient la fonction la plus demandée. OCR 4 prend ainsi en charge des données de localisation capables de présenter une traçabilité de l’information. Le modèle renvoie ainsi une représentation en couches dans laquelle chaque bloc est localisé dans une boite, classé par type (titre, tableau, équation, signature, etc.) et assorti d’une note de confiance.
Mais à quoi tout cela sert-il ? Sans ces informations, et avec les modèles précédents, les systèmes en aval ne pouvaient pas retracer un extrait jusqu’à sa source sur une page spécifique. Impossible de poser alors une question simple comme « D’où vient ce chiffre ? ». OCR 4 permet de résoudre ces problèmes selon Mistral.
Autre avantage de cette classification, un texte tagué comme « titre » peut segmenter un document en morceaux hiérarchiques pour une recherche sémantique. En fait, chaque morceau d’un document, une fois étiqueté, peut être acheminé vers un pipeline de traitement spécifique ou non. Si l’on prend le cas des éléments reconnus comme signatures par exemple, ils peuvent alors être repris dans des flux de travail dans un système de conformité.
Mistral indique que ces opérations ne sont pas nouvelles en soi. En revanche, le nouveau modèle les intègre toutes, annulant pour les clients le besoin d’entreprendre eux-mêmes ces traitements et analyses. OCR 4 propose ainsi une fonction triple : localisation spatiale, typage sémantique et confiance. Les zones ayant une confiance faible pourront par exemple être automatiquement routées vers des vérificateurs humains. À l’inverse, les éléments obtenant une note élevée pourront intégrés automatiquement dans les flux de travail.
La reconnaissance de texte est rarement la finalité dans ce type de processus. Le développement de systèmes RAG, des flux de travail agentiques ou tout ce qui touche à une forme d’automatisation avec les documents demande plus de temps que cette étape. OCR 4 veut justement taper dans la fourmilière en proposant une solution capable de faire sauter toute l’étape de reconstruction, avec à la clé des économies, aussi bien sur les coûts de l’OCR proprement dit que sur les heures investies par les ingénieurs chargés du reste. C’est du moins ce qu’affirme Mistral.
Scores à l’appui
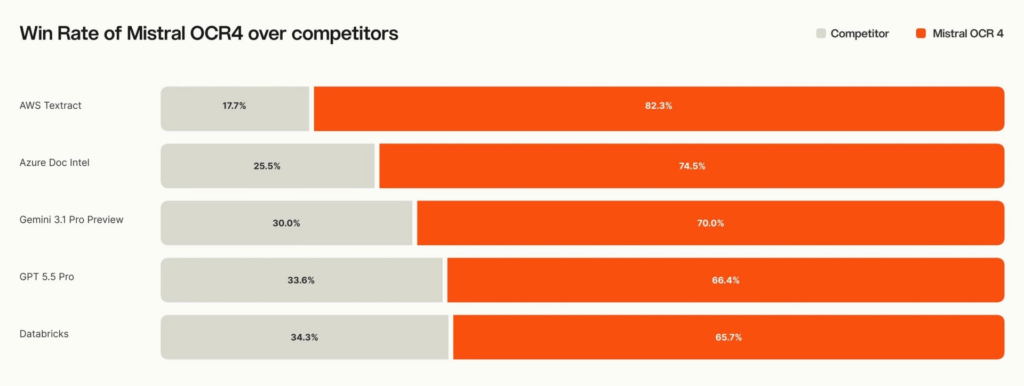
Pour prouver le sérieux de sa nouvelle offre, l’entreprise donne plusieurs chiffres. Des annotateurs indépendants auraient ainsi préféré OCR 4 dans 72 % des cas face « à tous les principaux systèmes OCT et IA documentaires testés ». Le modèle de Mistral affiche également un score de 85,20 % sur le benchmark OlmOCRBench, prenant la première place. Le modèle prend en charge 170 langues réparties dans 10 groupes linguistiques, « avec des gains mesurables sur les langues spécialisées et à faibles ressources où plusieurs systèmes concurrents se dégradent ».
Mistral affirme également que son modèle est suffisamment compact pour être déployé dans un seul conteneur. Le Français met ce point en avant, évoquant les gains de confidentialité, de conformité et – bien sûr – de souveraineté. Plusieurs témoignages élogieux sont de la partie dans le billet de blog, de même que sur X.
La tarification proposée via l’API est de 4 dollars pour 1 000 pages, avec une remise de 50 % sur l’API par lots. Si les développeurs passent par Document AI, le tarif passe à 5 dollars pour 1 000 pages. Les cas d’utilisation recommandés sont ceux attendus : analyse et extraction de documents, RAG, flux de travail agentiques, pipelines de données structurées utilisant des scores de confiance, et recherches en bases de connaissances.
Mistral tient cependant à rappeler que son nouveau modèle vise la compréhension, pas l’aide à la décision. « Il n’est pas destiné au diagnostic médical, aux conseils ou jugements juridiques, aux décisions financières à enjeux élevés, aux systèmes critiques pour la sécurité, au traitement en temps réel ou sensible à la latence, ni aux entrées non documentaires (audio brut, vidéo, etc.) », indique l’entreprise.

Commentaires (16)
Abonnez-vous pour prendre part au débat
Déjà abonné ou lecteur ? Se connecter
Cet article est en accès libre, mais il est le produit d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles d'un média expert
Profitez d'au moins 1 To de stockage pour vos sauvegardes
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 26 juin à 10h45
Le 26 juin à 11h02
C'est moins que le format du contenant que le contenu.
Que se soit dans les PDF , les DOC les PPT ou les ODF, ils peuvent contenir déjà du textes que des images...
Donc 100% de reconnaissances de texte alors que ce l'est déjà c'est facile :-)
Le 26 juin à 11h09
Le cas de l'OCR + RAG est déjà utilisé en entreprise, par exemple pour intégrer en compta des factures de fournisseur qui sont du papier scanné.
Le 26 juin à 11h32
Aussi, malgré le format structuré (virement), j'avais visité (en tant que dev connexe) le bureau des correctrices d'une très grande banque; une vingtaine de personnes avec une charge de correction inouïe (de mon ressenti ça faisait plus ou moins 40 corrections par minutes) full-time... Le rythme de scan des virements était impressionnant.
aujourd'hui, il faudrait que je vois avec notre propre compta pour le scannage automatique des factures mais j'ai la forte impression qu'il y a encore bcp de suivi manuel (et c'est un logiciel "pro" dont autres entreprises utilisent également).
Mais je me demande comment se passe le "state of the art" actuel....
Le 26 juin à 12h47
Puis le système de traitement les télécharge, applique un OCR avec différents masques. Les factures restent des documents avec de nombreuses similarités de mise en page malgré la variété (et cette variété va disparaître avec la facturation électronique, mais les entreprises devront toujours gérer le cas du non-UE).
Ces masques permettent d'extraire les données de comptabilité via l'OCR qui mappe tout ça dans une payload envoyée à l'ERP.
Le service comptabilité parlait de quelques 98 % de fiabilité, ce qui est plutôt pas mal quand on traite des milliers de factures par mois.
Le 26 juin à 16h41
Maintenant pour la fiabilité, si ça passe par un système de comparaison des facturations régulières à montant défini répétitif, ça facilite le traitement. ;) Manquerait plus qu'un petit malin joue sur les ambiguïtés numériques et toute la compta est en mode alerte ! :)
Malgré tout, je trouve quand même surprenant que les factures se fassent encore via papier... J'ai l'impression parfois qu'une partie de l'IA sera seulement là pour compenser la "paresse" du changement informatique d'il y a 20 ans. Pour dire, certain doc officiels qui transitent à mon boulot furent encore via papier il y a fort peu longtemps et qu'une approche numérique a été enfin appliquée. Et il y a toujours du papier qui arrivent, parfois de ceux qui prônent l'efficacité...
J'ai toujours dis à mes collègues, c'est bien beau d'avoir des process, des techniques, des outils complexes, le mieux c'est d'avoir des données fiables de manière fiable. Et si on les structures bien on arrive à un résultat efficace et pertinent à moindre coût. Mais bon, ça c'est dans mes rêves les plus fous.
Le 26 juin à 17h56
Et oui, le papier est encore pas mal utilisé. C'est l'un des enjeux de la directive ViDA en plus de la fraude à la TVA : supprimer le papier. Échéance 2030 dans l'UE.
Le 29 juin à 15h37
Modifié le 26 juin à 11h21
Le 26 juin à 15h23
Le 27 juin à 12h39
Le 27 juin à 13h02
Il se trouve que l'un des intervenants sur la vidéo est basé là-bas.
Il est Research scientist chez Mistral et a fait ses études en Inde ! Cocorico ?
Le monde de la tech est très international et avoir un site en Californie a probablement des avantages pour le recrutement.
Le 28 juin à 21h58
Le 28 juin à 09h49
Le 28 juin à 10h23
Le cas d'usage commun des chat bots en ligne, c'est qu'ils vont initier une recherche web et étudier le contenu pour donner leur réponse.
Le 29 juin à 09h18
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?