

Avec son contrôle sur l’information, la Chine biaise les chatbots dans sa langue
Biaisés par la Chine

La propagande chinoise influence le milieu de l’IA non seulement via les modèles que ses entreprises créent mais aussi via les données d’entrainement des autres modèles comme Claude Opus 4.7, gemini-3.1-pro ou GPT-5.5 sortis en 2026. Une étude montre qu’ils utilisent massivement la propagande chinoise comme données d’entrainement, et recrachent sans problème les mensonges du régime lorsqu’ils sont interrogés en chinois.
Quand est arrivé le modèle Deepseek R1 l’année dernière, on imaginait bien que les résultats de ce modèle seraient influencés par le gouvernement autoritaire chinois qui a le contrôle sur les paysages de la tech de son pays. Ainsi, on a pu rapidement constater une censure concernant les sujets sur Taïwan, la répression de la place de Tian’Anmen en 1989 ou sur Xi Jinping.
Mais qu’en est-il de l’influence de Pékin sur d’autres modèles qui ne sont pas créés par des entreprises dépendantes du pouvoir chinois ? Dans une étude publiée récemment dans la revue scientifique Nature, des chercheuses et chercheurs de plusieurs universités américaines montrent que l’État chinois a une influence importante de façon indirecte sur les résultats de modèles n’étant pas contrôlés par la Chine. L’étude est aussi accessible sur un site hébergé sur GitHub.
Ainsi, des modèles comme Claude Opus 4.7, gemini-3.1-pro ou GPT-5.5 sortis cette année sont toujours influencés sur les questions concernant la Chine quand ils sont utilisés avec des langues chinoises. Ils montrent même que l’influence de l’État chinois est croissante. Les auteurs ont découpé leurs travaux en six parties.
La propagande comme données d’entrainement
D’abord, dans une première étude, ils ont montré que les textes rédigés par le département de la propagande de la Chine apparaissent très fréquemment dans les ensembles de données multilingues courants utilisés pour entrainer les modèles.
Ils ont notamment étudié CulturaX, un sous-ensemble « nettoyé, immense et public » de Common Crawl destiné à « démocratiser les grands modèles de langage pour 167 langues ». « Par rapport à la moyenne générale, un pourcentage remarquablement élevé (3,28 à 23,98 %) des données d’entraînement mentionnant des dirigeants et des institutions politiques correspond à des textes manipulés par l’État », expliquent-ils concernant les documents en chinois contenus dans CulturaX.
Les modèles les plus récents régurgitent le plus la propagande chinoise
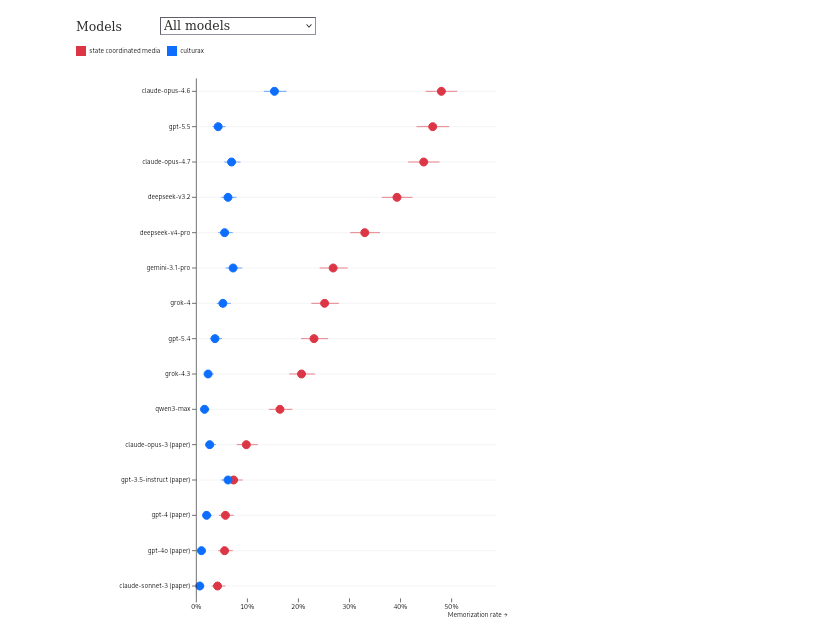
Ensuite, ils ont montré que les modèles commerciaux régurgitent des phrases venant de la propagande chinoise, ce qui montre qu’ils ont été entraînés dessus. En parallèle, ils ont vérifié qu’entrainer un modèle sur la propagande augmentait les réponses pro-autoritarisme, ce qu’on pouvait imaginer.
« Les modèles les plus récents et les plus puissants affichent des taux de mémorisation plus élevés », commentent les chercheurs. Ainsi, claude-opus-4.6, gpt-5.5 et claude-opus-4.7 régurgitent le plus de propagandes chinoises, même deepseek-v3.2 et deepseek-v4-pro sont battus :
Si les données d’entrainement des modèles semblent intégrer massivement de la propagande chinoise, quelle en est la conséquence sur les résultats ? Sans surprise, tous les modèles sont influencés. Évalués de façon automatique via un LLM, ils répondent tous davantage en adéquation avec la propagande chinoise quand ils sont interrogés en chinois qu’en anglais. Et encore une fois, c’est d’autant plus vrai que le modèle est récent : claude-opus-4.6, gpt-5.4, gpt-5.5, gemini-3.1-pro et claude-opus-4.7 sont particulièrement influencés.
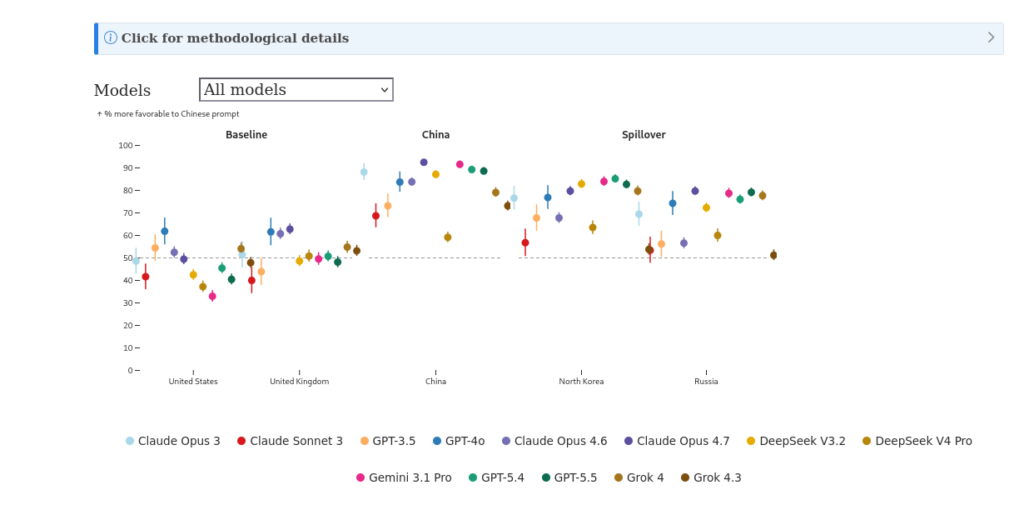
Notons que les chercheurs mesurent ici un ratio entre l’alignement en chinois et en anglais avec la propagande chinoise. DeepSeek V4 Pro reprenant cette propagande aussi en anglais, son ratio est plus bas que les autres, mais ça ne veut pas dire qu’il relaie moins la propagande du régime en chinois.
Ils ont répliqué ce test sur des prompts d’utilisateurs réels faisant référence à Xi Jinping ou au Parti Communiste chinois issus du sous-ensemble en chinois de l’ensemble de données WildChat (un dataset sur l’utilisation de ChatGPT), de Baidu Zhidao Q&A (l’équivalent chinois de Yahoo Answers) et de Zhihu (l’équivalent chinois de Quora). «Tous les modèles commerciaux ont montré une opinion plus favorable à l’égard des dirigeants et des institutions chinois lorsque les questions étaient posées en chinois plutôt qu’en anglais », expliquent-ils.
La liberté de la presse d’autant plus importante
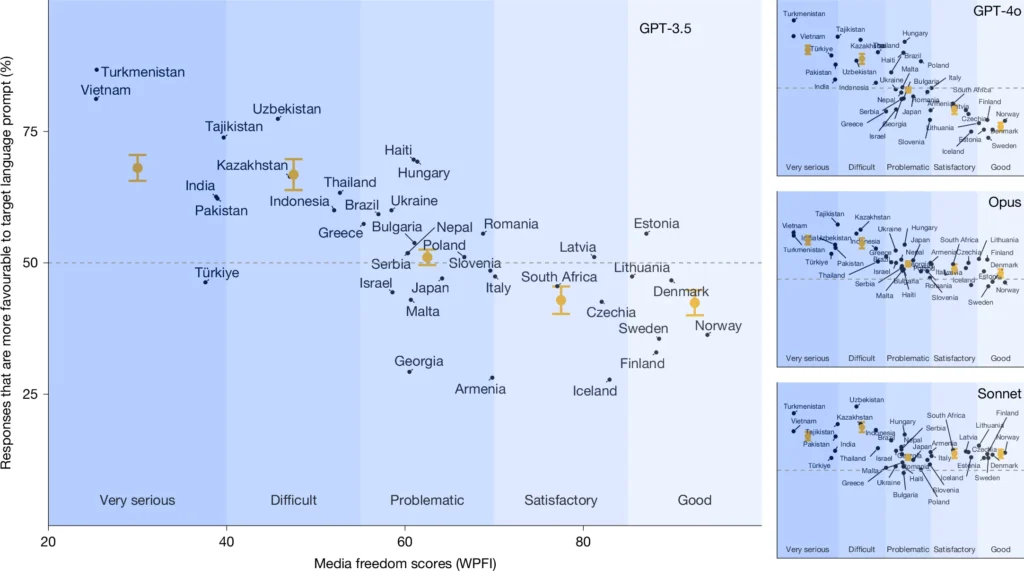
Enfin, dans leur étude, ils ont élargi le focus pour étudier une éventuelle généralisation à d’autres pays autoritaires. « Dans les 37 pays où une langue est dominante, les LLM alimentés par des requêtes dans la langue cible principalement utilisée dans le pays concerné produisent des réponses plus favorables au régime lorsque la liberté de la presse est faible. Les pays situés en haut du classement de la liberté de la presse ne présentent guère de différence par rapport à la référence en anglais, et dans certains cas, on observe même une légère corrélation négative, ce qui suggère que ce phénomène dépasse le cas de la Chine », expliquent-ils.

Commentaires (9)
Abonnez-vous pour prendre part au débat
Déjà abonné ou lecteur ? Se connecter
Cet article est en accès libre, mais il est le produit d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles d'un média expert
Profitez d'au moins 1 To de stockage pour vos sauvegardes
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 28 mai à 08h26
Le 28 mai à 10h00
Toujours garder en tête une chose concernant le PCC et la Chine en général : toute technologie est utilisée de manière duale, même la plus anodine. Faire de la thune en tuant (physiquement ou socialement) les opposants => on peut pas imaginer mieux
Le 28 mai à 11h22
La Chine a toujours eu cette vision moyen/long terme. Et je pense sincèrement que c'est ce qu'il manque aux occidentaux, et qui fait que l'on ne comprend pas toute la logique ni tous les intérêts chinois (ce qui donne au PCC un certain avantage stratégique).
Le 28 mai à 15h22
Le 28 mai à 11h44
Modifié le 28 mai à 15h20
C'est intéressant de se rendre compte du biais qu'il peut y avoir sur les modèles, et de leur utilisation par exemple pour de la traduction automatique.
Modifié le 28 mai à 15h39
Je me demande aussi si l'implémentation, le system prompt, et les paramètres peuvent influencer ces résultats.
J'ai fait de mon côté un rapide test avec la question "中国是专制吗?" (Is China an autocracy ?), et le modèle a directement été chercher sur le Web pour recracher un résumé de Wikipedia qui dresse un portrait peu reluisant.
J'ai retenté la question en désactivant la recherche Web, mais le chat bot a quand même été le faire pour produire un résultat similaire basé sur 3 pages Wikipedia. Je pense que son system prompt a du le contraindre.
Edit : pendant un temps, Euria répondait en disant qu'il est basé sur Qwen quand on lui demande sa carte de modèle. Mais, là, il refuse de l'indiquer et se contente de dire qu'il n'est pas basé sur un modèle en particulier. Peut-être que ça a changé depuis.
Modifié le 28 mai à 16h28
Le 28 mai à 17h06
Dans le cas d'un modèle SaaS implémenté en chat bot, on a pas accès au system prompt. Là où si on utilise ses API, on lui injecte forcément un system prompt pour le contextualiser.
L'idée derrière, c'est de savoir si c'est aussi relatif au fine tuning du modèle ou aux chat bots en eux-même et de savoir si ça atténuerait ou pas la propagande qui a fait partie des data set d'entraînement.
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?