

Mistral prépare son IA chasseuse de failles, Microsoft déploie déjà son armée d’agents

Qui n’a pas son arsenal IA pour la cybersécurité ? Après Anthropic et Mythos, après OpenAI et Daybreak, Microsoft a dévoilé sa solution. Et Mistral, le petit Poucet français, planche également sur un modèle capable de détecter les failles à grande échelle.
Mistral AI travaille au déploiement d’un modèle IA auprès de banques européennes pour détecter les failles de sécurité dans le code de leurs infrastructures informatiques, selon une indiscrétion de Bloomberg. Impossible de dire quand ce modèle sera lancé à l’assaut des vulnérabilités, ni depuis quand ces discussions ont débuté avec les établissements.
« Imagine-t-on les bases de données de l’armée française scannées par Mythos ? »
Mais ce qui est certain, c’est que Mistral n’a pas attendu la présentation de Mythos début avril pour s’atteler à cette problématique de la cybersécurité. La startup travaillait déjà avec ses clients du secteur bancaire pour découvrir des vulnérabilités dans le code de leurs logiciels avant les premiers pas du modèle d’Anthropic, selon nos confrères. Désormais, il s’agit de développer une version « clé en main » pour un déploiement plus large.
« On a un de nos concurrents qui sait très bien faire du marketing de la peur », a témoigné (sans citer le nom d’Anthropic) Arthur Mensch, le directeur général de Mistral, devant la commission d’enquête sur les vulnérabilités numériques à l’Assemblée nationale cette semaine. « On travaille avec nos clients pour les aider sur ces sujets cyber », ajoute-t-il. Pour lui, il s’agit d’un sujet régalien « et un argument supplémentaire pour dire qu’il faut avoir un contrôle sur cette technologie » :
« Vous ne pouvez pas avoir les bases de données et le code de l’armée française scannés par Mythos. Ça crée une dépendance tellement irrémédiable qu’il faut absolument trouver des solutions. »
Il aurait pu ajouter : des solutions souveraines, car c’est bien sûr ce que l’on comprend en creux. Mythos n’est actuellement disponible que dans un format d’aperçu et distribué au compte-gouttes auprès d’organisations et d’entreprises majoritairement américaines. Et l’Europe n’a toujours pas reçu sa carte du club.
Une armée d’agents de cybersécurité chez Microsoft
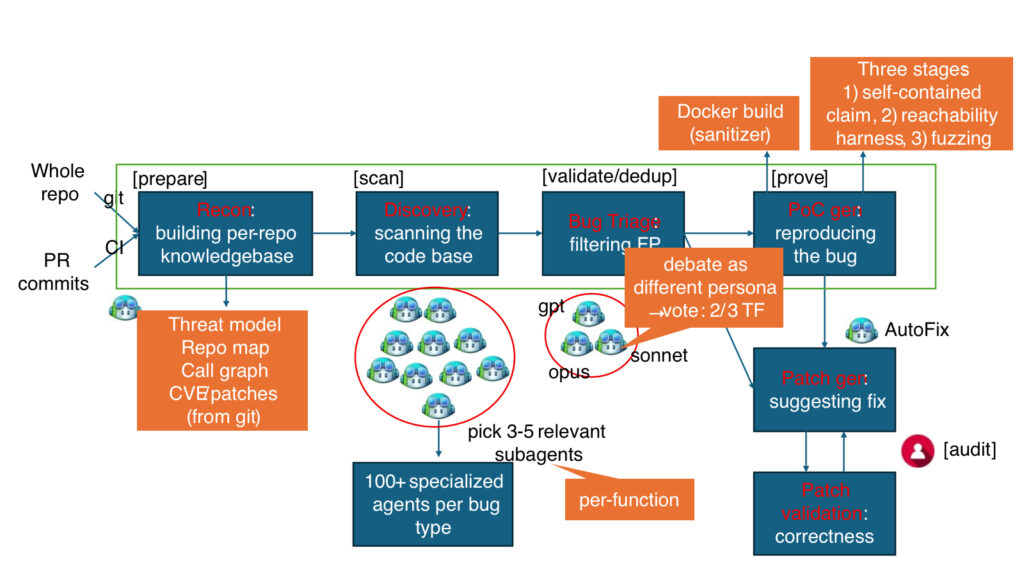
Après Mythos et l’initiative Daybreak d’OpenAI, et avant celle de Mistral, Microsoft a levé le voile sur son nouveau système de sécurité agentique multi-modèles. L’éditeur ne se contente pas d’un seul modèle : plusieurs sont à l’œuvre et ils sont secondés par une armée de plus de cent agents spécialisés à l’assaut du code.
MDASH, pour « Microsoft Security multi-model agentic scanning harness », a déjà mis la main sur 16 vulnérabilités dans la pile d’authentification et l’infra réseau de Windows, dont 4 failles critiques permettant d’exécuter du code à distance. « L’implication stratégique est claire : la découverte de vulnérabilités par IA est passée du stade de curiosité de laboratoire à celui d’outil de défense déployable à grande échelle en entreprise », explique l’éditeur, qui vante « l’avantage durable » de son système agentique.

Le système repose sur trois éléments : un ensemble de modèles IA complémentaires pilotés par MDASH, dont plusieurs modèles spécialisés qui se confrontent pour repérer les vulnérabilités ; la centaine d’agents dédiés à des tâches spécifiques (détection, vérification, exploitation potentielle d’un bug) ; et enfin une chaîne d’analyse qu’il est possible d’étendre avec des plugins.
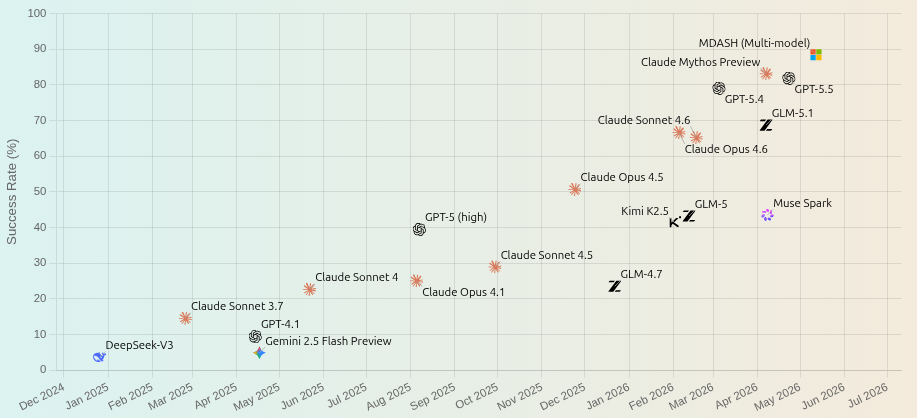
Sur le benchmark CyberGym, qui regroupe plus de 1 500 tâches reproduisant des vulnérabilités réelles issues de projets open source, MDASH atteint un taux de réussite de 88,45 %. C’est le meilleur score publié à ce jour, et environ 5 points de plus que Claude Mythos Preview, et 6 de plus que GPT-5.5, ses concurrents les plus proches.
Microsoft souligne que ce résultat a été obtenu avec des modèles IA déjà disponibles publiquement, ce qui laisse entendre que les performances viennent surtout de l’orchestration « agentique » autour des modèles plutôt que des modèles eux-mêmes.
Les agents MDASH sont utilisés par les équipes d’ingénierie sécurité de Microsoft, et testés par un groupe de clients dans le cadre d’un aperçu privé. Il est possible de demander un accès à l’aperçu.

Commentaires (14)
Abonnez-vous pour prendre part au débat
Déjà abonné ou lecteur ? Se connecter
Cet article est en accès libre, mais il est le produit d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles d'un média expert
Profitez d'au moins 1 To de stockage pour vos sauvegardes
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 15 mai à 12h23
Modifié le 15 mai à 12h25
Modifié le 15 mai à 12h54
Et c'est purement factuel que Mistral est bien moins performant que GPT, Claude, Deepseek, Kimi...
C'est nécessaire d'avoir un LLM Français/Européen, mais il n'est pas (encore ?) au niveau des autres.
Le 15 mai à 13h16
Le 15 mai à 13h36
Il ne faut pas oublier l'effet pervers de marteler ce genre d'idée. C'est en n'osant pas utiliser les outils français/ européens qu'on continue à creuser notre dépendance aux USA ou à la Chine
Modifié le 15 mai à 16h20
En ce qui me concerne, je considère que les entreprises qui en ont besoin ne devraient pas utiliser d'outils externes/distants (mistral, GPT, Claude...) et auto-héberger les LLM de leurs choix.
Il pourrait d'ailleurs y avoir un marché pour ça, que des gens expérimentés comme toi, pourraient pousser.
Le 15 mai à 19h00
Le 15 mai à 17h36
Personnellement, pour le peu de fois où j'ai recours à un LLM je trouve que Mistral est toujours le plus pertinent. Une réponse concise, moderne (au sens C++ du terme) et propre.
Seul Deepseek (leur derniers modèle est vrai pas mal) le talonne. Je précise que je parle des modèles "open-sources", et ma métrique est l'étude de la pertinence de la solution proposée au problème posé sur les critères de performances, de consommation mémoire et de maintenabilité.
Modifié le 15 mai à 19h05
J'ai pas à m'en plaindre, ça fait très bien le taff en ce qui me concerne pour diverses tâches d'assistance / recherche. J'ai déjà testé le Deep search de Mistral, mais le résultat était toujours assez perfectible. Disons qu'il m'a donné ce que j'aurais mis une heure à faire via recherches Web.
Je pense que la raison vient du fait que beaucoup de sites bloquent les bots des LLM, réduisant les résultats pour le RAG. Sans oublier les sites SEO de merde.
ChatGPT je n'y ai pas touché depuis... 2 ans ?
Le 18 mai à 16h03
Le 15 mai à 13h17
Le 15 mai à 14h33
Le 18 mai à 12h16
Je ne dis pas que ça ne sert à rien, je dis qu'un modèle doit être comparé dans un flow de travail précis avec un autre modèle pour savoir s'il est bon ou non. C'est ce qui rend la comparaison si difficile, hélas.
Personnellement, pour avoir accès aux 3 "gros", Gemini Pro, Claude Opus 4.X et ChatGPT 5.5, chacun dans les versions les plus chères, chacun ont leurs forces et faiblesses. Par contre, chacun pris à part, intégré dans un flow précis, avec des demandes précises, cadrées, etc, font un excellent boulot. Le cadrage et la création du flow peut différer d'un modèle à l'autre pour s'adapter à ses particularités, mais le résultat final reste très très proche.
Le 18 mai à 15h16
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?