

Sur les réseaux sociaux, une redirection peut en cacher une autre
Toujours réfléchir avant d’agir

La désinformation peut prendre de nombreuses formes, mais elle essaye généralement de se faire passer pour légitime en copiant (souvent grossièrement) des sites officiels. Ajoutez l’empressement des utilisateurs à partager des informations sans vérifier outre-mesure et vous avez un combo gagnant (enfin perdant). Les Twitter Cards en sont victimes en ce moment, mais ce ne sont pas les seules.
Comme l’explique Wikipédia, le cloaking (ou masquage) est une technique qui consiste « à présenter un contenu de page web différent suivant que le client distant est un robot de moteur de recherche ou un internaute humain ».
Cette distinction peut se faire suivant différentes techniques, l’adresse IP et l’user-agent sont les deux principales. L’user-agent est une chaine de caractères permettant d’identifier le type de navigateur, sa version, le système d’exploitation de la machine, etc.
Deux salles, deux ambiances
Cela permet ainsi d’afficher une mise en page différente sur un smartphone et sur un ordinateur de bureau. On peut aussi adapter la page au navigateur, ce qui était parfois indispensable à l’âge d’or d’Internet Explorer de Microsoft.
Mais l’utilisation de l’user-agent peut aussi être détourné. Google donne un exemple de ce qu’il ne faut pas faire : afficher « une page sur des destinations de voyage pour les moteurs de recherche et une autre sur des médicaments à prix réduit pour les utilisateurs ».
Les Twitter Cards détournées
C’est ce qui se passe en ce moment sur certaines publications X (anciennement Twitter), même si le phénomène n’est pas nouveau ni limité à ce réseau social. Les Twitter Cards sont en effet détournées pour rediriger des utilisateurs sur des fausses informations, tout en se faisant passer pour des sites légitimes.
En voici un exemple :
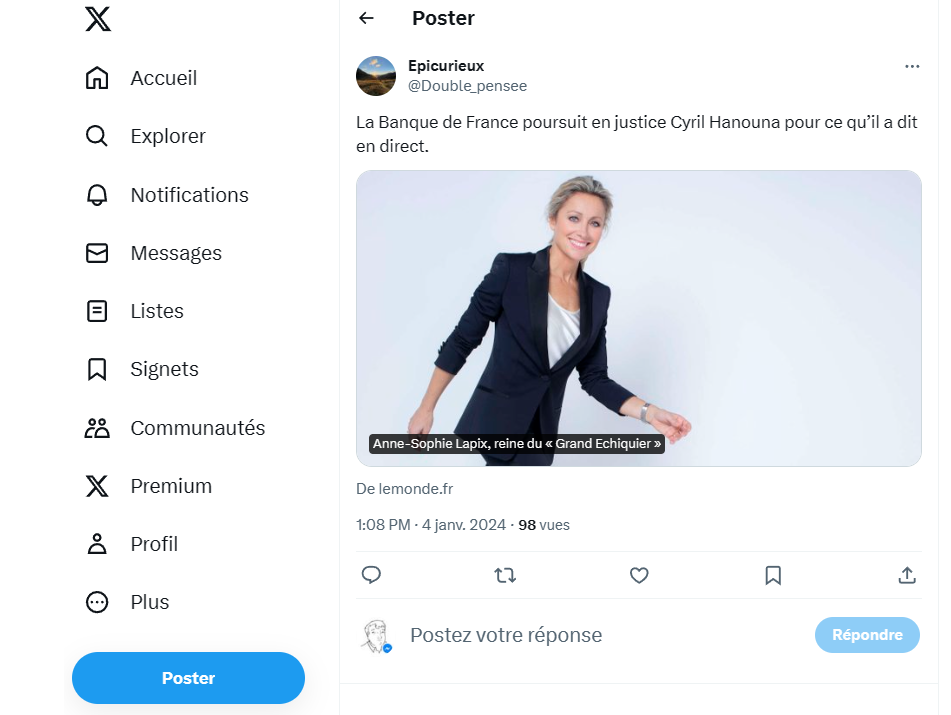
La Twitter Card indique que l’aperçu vient de « lemonde.fr ». C’est vrai, mais ce n’est pas forcément cette page que l’utilisateur va voir s’il clique sur le lien, comme l’explique Nico Popy sur X. Suivant votre user-agent (mais cela peut être un autre paramètre), vous serez redirigé vers le site officiel du Monde, ou bien vers un site frauduleux en insidetodayreportsnow[.]xyz.
Ce dernier reprend un design proche de celui du Monde. La supercherie ne tient pas longtemps si on regarde un tant soit peu attentivement. Il suffit par exemple d’essayer de cliquer sur le bandeau supérieur (qui ne se déroule pas). Cette mise en page peut néanmoins suffire à tromper des utilisateurs. Sur ce site, on retrouve donc une fausse information montée de toutes pièces.
Sur l’image ci-dessous, la même URL (t.co/xxxx) redirige vers un site frauduleux si on ne change pas notre user-agent, alors qu’on arrive sur Le Monde avec un user agent ne correspondant pas à celui d’un navigateur.
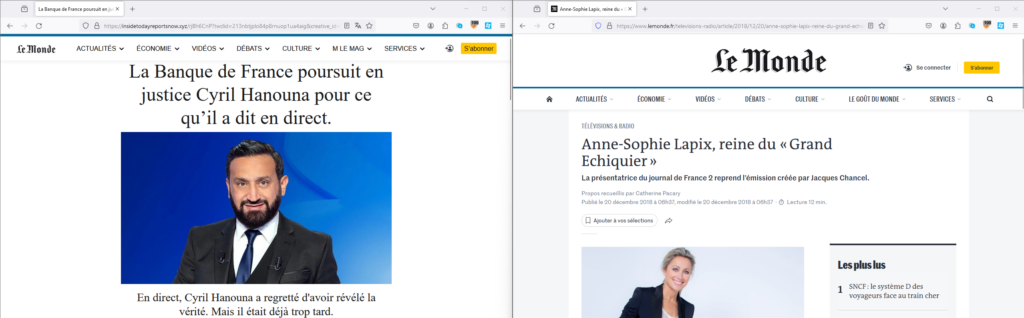
Une redirection peut en cacher une autre
Mais comment se fait-il qu’il existe deux versions ? Un petit passage par Wheregoes (qui permet de suivre les redirections d’un lien sans cliquer dessus) donne la réponse : il y a deux redirections différentes. La première, en 301 (redirection permanente) renvoi vers le site frauduleux insidetodayreportsnow[.]xyz. La seconde, en 302 (redirection temporaire) vers le site du Monde.
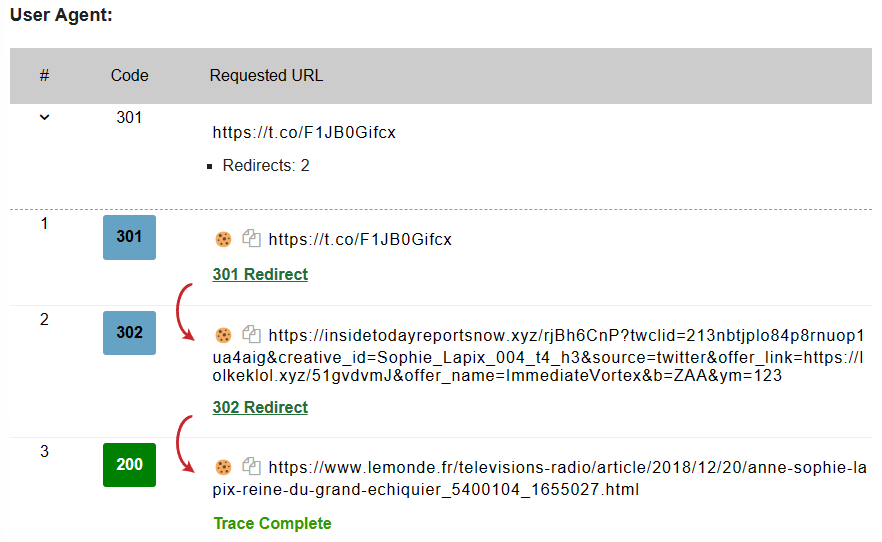
Les utilisateurs classiques restent bloqués à la première redirection, tandis que ceux avec un user-agent spécifique (les moteurs de recherche par exemple) sont renvoyés vers la seconde page.
Dans le cas de Twitter ou d’autres applications proposant un aperçu, c’est le second site qui est pris en compte, avec donc la miniature et la provenance du Monde. Les utilisateurs ont ainsi l’impression de se rendre sur un site légitime, alors que non.
Nous avons testé le lien dans différentes applications proposant une prévisualisation. LinkedIn, Twitter et Mattermost par exemple propose un aperçu du site du Monde, alors que les internautes verront bien (trop) souvent le site frauduleux.
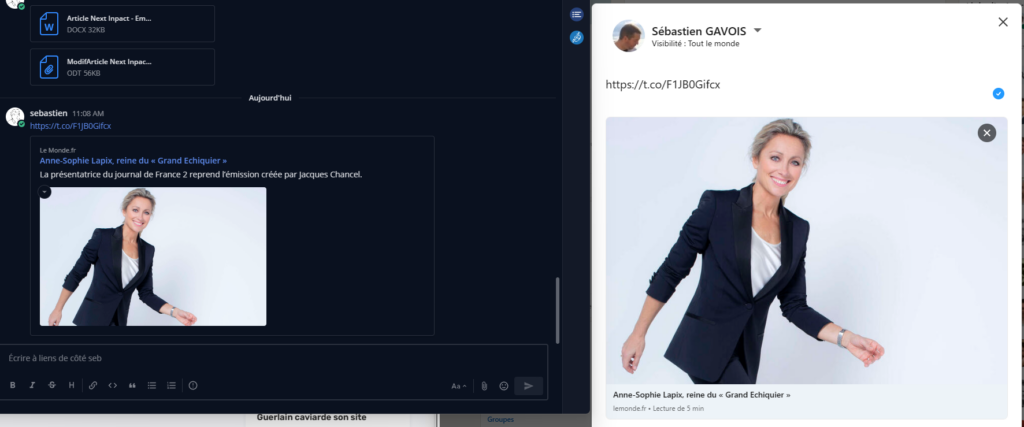
Résultat des « cards » de prévisualisation sur Mattermost et LinkedIn.

Commentaires (23)
Abonnez-vous pour prendre part au débat
Déjà abonné ou lecteur ? Se connecter
Cet article est en accès libre, mais il est le produit d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles d'un média expert
Profitez d'au moins 1 To de stockage pour vos sauvegardes
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 05/01/2024 à 16h10
Rien que pour le site WhereGoes, je suis content d'avoir lu cet article :) #Bookmark
Le 05/01/2024 à 16h47
Il y a ceux qui utilisent des raccourcisseurs d'URL (on se demande pourquoi ?) et les autres.
Je suis surpris que tu soies surpris.
Le 05/01/2024 à 16h37
Le 05/01/2024 à 16h51
Redirection : rien n'est généré.
Il n'y a aucun contenu "frelaté" : ce qui est présenté à client reconnu comme navigateur classique est différent de ce qui est présenté aux autres (dont les robots).
Les robots (ou plutôt la logique inverse : les "agents non-reconnus comme des navigateurs classiques") sont redirigés vers un contenu final légitime, d'où la synthèse image & nom de domaine) est faite. C'est exactement comme cela que tout "lien enrichi" ont de tous temps été créés.
Le 05/01/2024 à 18h24
Le 05/01/2024 à 22h28
Merci beaucoup Sébastien (et Next) ! Comme d'habitude, vous êtes des champions !
Le 06/01/2024 à 07h26
Ou c'est juste un bug/feature qui fait que les robot de prévisualisation (et d'indexation?) suivent la redirection temporaire là où un navigateur "standard" va rester sur la redirection "normale"? (Ce qui me paraît aberrant).
Mon cerveau manque d'information technique (et de café) pour bien comprendre la bail du pourquoi du comment là.
Le 06/01/2024 à 09h55
Il ne s'agit pas de redirection au niveau DNS, le terme n'est même pas dans l'article.
Il s'agit de redirection d'URL faite par un serveur WEB.
Un serveur Web a bien accès au user-agent du navigateur contrairement à un serveur DNS.
Le 08/01/2024 à 08h21
Certes DNS n'est pas cité, mais de base c'est les seule redirections que je connais et les codes 301 302 me disaient quelque-chose du coup j'ai mixé ^^".
Je trouve l'explication de fdorin vachement plus claire, et avec ça et deux de café plus tard, je comprends le cheminement sur la capture de wheregoes :p
Le 06/01/2024 à 10h09
Ainsi, les moteurs d'indexation ou ceux qui font apparaitre des miniatures voient le site légitime, tandis que les véritables utilisateurs voient le contenu vérolé.
Le 08/01/2024 à 08h22
Le 08/01/2024 à 16h45
Le 08/01/2024 à 18h19
Dans le cas de 301, "Moved permanently", le serveur renvoie ce code au client avec l'adresse (Location) du nouveau document à consulter pour lui indiquer que le chemin désiré a été déplacé de manière permanente.
Par exemple, mon site répondait avait sous
monsite.fr/index.phpet depuis c'estmonsite.fr/index.html, le serveur renvoie cette info au client avec le code 301. Ce code a aussi pour effet de demander aux moteurs de recherche de mettre à jour leur index.Dans le cas de l'URL réduite, il s'agit de l'étape où le lien court est traduit avec l'URL complète.
Cependant, la "vraie" URL renvoie un HTTP 302 ("Found") qui est un code ayant une petit particularité : les moteurs de recherche ne mettent pas à jour leur index quand ils reçoivent ce message. Car il s'agit d'une redirection considérée comme temporaire. Là où le navigateur du client va suivre l'adresse de redirection.
C'est là que les bactéries attaquent car l'URL malveillante répondant un code 302, elle trompe les clients qui ne sont pas des navigateurs Web et renvoie une carte réputée être la destination de l'URL raccourcie.
En fait, de ma compréhension, c'est un usage détourné du code HTTP 302 qui est utilisé comme si c'était HTTP 307 ("Temporary redirect") qui profite du fait que tous les clients ne l'ont pas forcément implémenté comme la spécification l'attendait.
Modifié le 08/01/2024 à 18h56
Et donc de ma compréhension non, ça ne s'appuie pas sur le comportement du client : la redirection n'est tout simplement pas présentée si l'UA correspond à un navigateur.
Le 09/01/2024 à 06h23
Et ouais quand on fait joujou avec Apache et son
.htaccesset qu'on ne comprend pas pourquoi une redirection est tjr effective alors qu'on l'a retirée...Donc faut faire attention avec la 301.
Modifié le 09/01/2024 à 09h16
Sur le côté permanent / temporaire : cela permet de gérer soit un déménagement, soit des travaux de maintenance par exemple. Pour donner des idées : lors du déménagement de nextinpact vers next.ink, le site nextinpact redirige vers next.ink via une redirection permanente. Il n'y a plus de raison de conserver l'ancienne URL (le contenu a été déplacé) si ce n'est pour indiquer où il se trouve maintenant pour permettre d'y accéder. En analogie routière : la route est définitivement fermée, prenez la rocade qui a été mise en place.
Le temporaire, est, comme son nom l'indique bien... temporaire (vous ne vous y attendiez pas, avouez !!!). Une redirection temporaire peut avoir plein de cause. Maintenance serveur, mode dégradé, ... et dénote, normalement, une situation exeptionnelle qui n'est pas sensée durer. Quand le site ne nextinpact a connu un gros plantage il y a quelques mois, et que le site a été redirigé vers la beta, c'était de manière temporaire. En analogie routière : la route est temporairement fermée (réfection, installation électricité / gaz / autre, etc.), suivez les panneaux de déviation.
Pour terminer, une redirection permanente peut être mise en cache par le navigateur, alors qu'une temporaire ne doit surtout pas l'être.
Maintenant, la différence entre le 302 et le 307 (hormis que cela pourrait être des gammes de voiture). Tout se joue au niveau des verbes HTTP. En HTPP, il en existe plusieurs, le plus connu est le GET (on récupère les ressources) et le POST (en envoie des données, par exemple, un formulaire). Mais avec les API REST, on a vu se démocratiser les autres verbes (PUT, DELETE, ...).
Pour une redirection GET, il n'y a aucune différence entre le 302 et le 307. Donc, dans le cas du raccourcisseur d'URL, aucune importance.
Par contre, dans le cas des autres verbes, cela à son importance :
Ce besoin provient initialement d'une mécompréhension de la RFC qui défini les verbes HTTP. Normalement, seules les redirections permanentes devaient changer le verbe en GET. Mais beaucoup de clients (les navigateurs par exemple) ont appliqué la même stratégie aux redirections temporaires. Changer cet état de fait aurait créé de nombreux problèmes de compatibilité.
Aussi, il a été décidé de créer un deuxième code d'erreur, le 307, qui fait comme le 302, mais interdiction formel de changer le verbe HTTP.
Le 09/01/2024 à 18h46
Le 08/01/2024 à 18h45
À chaque réponse du serveur est associé un de ces codes, dont certains (d'erreur notamment, forcément plus visibles) sont plus ou moins connus, par exemple 404 (not found). Ici, ce sont les codes de redirection (3xx) qui sont utilisés pour envoyer le client tout d'abord depuis le raccourcisseur vers le sitàlacon, puis, dans le cas où c'est un robot qui visite, du sitàlacon vers lemonde.fr.
La différence entre 301 et 302 n'a que peu d'intérêt ici, il suffit de retenir que ce sont des redirections renvoyées par un serveur HTTP qui a tous les éléments pour appliquer la logique détaillée par fdorin plus haut.
Le 06/01/2024 à 11h48
Et bien la faculté de l'être humain de pervertir les choses m'émerveillera toujours !
C'est assez ingénieux, un peu comme un lien web avec l'url affichée en texte mais le href différent, on pense aller vers ce qu'on vois mais non.
Mais le pire au final c'est de tromper les outils qui cherchent les cards et les metatags.
Ces bots ne devraient pas suivre les redirections et encore plus quand ce ne sont pas vers les mêmes noms de domaine.
Merci pour le wheregoes effectivement
Le 06/01/2024 à 12h17
Le 06/01/2024 à 13h25
Si X s'occupe de l'aperçu, le site en question ne sait pas qui voit l'aperçu, tant que l'utilisateur n'aura pas cliqué sur le lien (si il clique).
Si X ne s'occupe pas de l'aperçu, mais que c'est un javascript côté client, alors le site en question saura qu'il y a un aperçu. A noter également que l'aperçu côté client poserait sans doute problème d'un point de vue consentement et dépôt des cookies.
De plus, d'un point de vue de X, si c'est X qui gère l'aperçu, il peut optimiser l'affichage (notamment le temps) via une mise en cache, du contenu au moment où il est posté. Chose impossible à faire si le rendu est géré côté client.
Bref, X (ou tout autre site d'ailleurs) a de nombreux intérêts à gérer les aperçus côtés serveur.
L'aperçu de la card à donc
Le 08/01/2024 à 09h54
Merci pour le site whereitgoes, je connaissais pas.
Le 08/01/2024 à 10h28
Si une URL apparait dans un document par exemple, et si l'URL a expiré, alors on a une erreur 404. Mais pire ! Il y a déjà eu des attaques où l'URL raccourcie était réutilisée par des attaquants pour rediriger vers un contenu malveillant ! (certains raccourcisseur d'URL permettent de choisir l'URL générée) On avait donc des documents "officiels" qui pointaient sur des contenus vérolés.
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?