Des échecs au jeu de Go : quand l’intelligence artificielle dépasse l’homme
Skynet jouait au Go ?

Une machine a remporté la victoire contre le multi champion Lee Sedol au jeu de Go, une première pour un match de ce niveau. Il s'agit de l'intelligence artificielle AlphaGo développée par DeepMind (Google). Pourquoi a-t-il fallu attendre 2016 pour en arriver là et en quoi est-ce important ?
L'affaire aura finalement été pliée très rapidement. Les trois premiers matchs ont en effet suffi à l'ordinateur de DeepMind (AlphaGo) pour remporter la victoire au jeu de Go face au champion Lee Sedol, qui est parmi les meilleurs joueurs professionnels au niveau mondial. Score final sans appel : quatre à un. Mais cette victoire symbolique n'est qu'une pierre de plus à l'édifice de l'intelligence artificielle. Ce n'est pas la première, et ce ne sera pas la dernière, loin de là.
Mais au fait, c'est quoi exactement l'intelligence artificielle ?
Avant d'entrer dans le vif du sujet, il est important de définir quelques bases sur l'intelligence artificielle, un (très) vaste sujet. Commençons par préciser ce que l'on entend exactement par intelligence artificielle, ou IA. Le dictionnaire Larousse en donne la définition suivante : « Ensemble de théories et de techniques mises en œuvre en vue de réaliser des machines capables de simuler l'intelligence humaine ». Voici également une alternative présentée par Dominique Pastre, professeur de mathématiques à l'Université Paris 5 : « Faire faire par une machine des tâches que l'homme accomplit en utilisant son intelligence ».
Pour J.L Laurière (ancien professeur de Paris 6 et pionnier de la recherche en intelligence artificielle), il s'agit de l'« étude des activités intellectuelles de l'homme pour lesquelles aucune méthode n'est a priori connue ». En effet, si un programme informatique existe déjà, pas la peine d'avoir une intelligence artificielle pour effectuer cette tâche. Parmi les exemples courants, on retrouve ainsi écrire le fait de résumer un texte, les mathématiques au sens large, poser un diagnostic médical, etc.
On peut également citer Turing et son fameux test qui consiste à déterminer si une machine intelligente peut être définie comme « consciente ». Pour passer ce test, il faut que la machine parvienne à se faire passer pour un humain lors d'une conversation via des messages textes (il serait trop facile d'identifier un ordinateur sinon). De nombreux programmes ont essayé et s'y sont cassés les dents.
Le jeu de dames (500 milliards de milliards de possibilités) a été résolu en 2007
Avant le Go, les ordinateurs se sont attaqués à de nombreux autres types de jeux : les morpions (mis sur le devant de la scène par le film Wargames en 1983), les dames, le poker et les échecs pour ne citer que ces quatre-là. Si la résolution du morpion est triviale avec seulement 9 cases sur le plateau (362 880 possibilités), il en était autrement pour les dames.
Néanmoins, dans les années 90, un ordinateur eut pour la première fois le droit de participer au championnat du monde. Un changement dans les mœurs qui ne s'est pas fait en douceur, puisque tout le monde ne voulait pas qu'une machine participe à ce genre de compétitions.
Le programme informatique perdit son premier match en 1992, mais remporta la victoire en 1994 après que son adversaire abandonne pour des raisons de santé. Une victoire en demi-teinte pour certains. En 1996, les ordinateurs ont arrêté de participer aux compétitions, car ils étaient « beaucoup plus forts que tout être humain » selon les experts.
En 2007, une équipe de l'Université d'Alberta annonçait fièrement que « le jeu de dames est maintenant résolu ». Il faut comprendre par là que les 500 milliards de milliards (5 x 10^20, soit 5 suivi de 20 zéros) de coups possibles ont été calculés et enregistrés dans un ordinateur. Il connait donc toutes les combinaisons possibles et peut réaliser la partie « parfaite » du premier coup, jusqu'au dernier, en toute circonstance.
Notez qu'il ne s'agit ici pas d'intelligence artificielle, la machine exploite simplement une base de données dans laquelle elle pioche les bons coups à jouer, il n'y a pas besoin « d'intelligence » pour cela. Pour la petite histoire, sachez que si aucun joueur (homme ou machine) ne commet d'erreur, l'issue de la partie sera obligatoirement un match nul, et ce, quelle que soit l'ouverture lancée par celui qui commence.
Les échecs ne sont pas résolus, mais la machine domine l'homme depuis 20 ans
Du côté des échecs, la progression de la machine s'est faite en plusieurs étapes. La première tentative sérieuse remonte à la fin des années 80 avec Deep Thought, un ordinateur développé par IBM et dont le nom vient du livre Le Guide du voyageur galactique. Capable d'analyser plus de 720 000 coups par seconde, il est battu deux à zéro par le champion Garry Kasparov. En 1996, c'est Deep Blue qui prend la relève avec une puissance de calcul plus importante (entre 50 et 100 millions de coups par seconde). Cette nouvelle version se fait de nouveau battre par Garry Kasparov trois victoires à une.
Un an plus tard, une version encore améliorée baptisée Deeper Blue (100 à 300 millions de mouvements par seconde) remporte la victoire trois manches à deux (et un nul) contre Kasparov. Notez que durant le premier match, l'ordinateur a joué un coup très surprenant qui déstabilisa Kasparov, et qui lui permit de gagner la partie.
En 2000, Dominique Pastre (professeur de mathématique à l'Université de Paris 5) expliquait par contre que « les performances aux échecs sont encore inférieures à celles d'un champion du monde, bien que le champion du monde ait pu être battu par un programme. Les progrès les plus récents sont dus plus à l'amélioration des ordinateurs et des techniques de programmation qu'à l'IA ».
Deeper Blue vs Kasparov : un bug pour gagner dans l'immensité des possibilités ?
Plusieurs années plus tard, un statisticien de renom (Nate Silver) publiait un ouvrage The Signal and the noise où il revenait sur le match opposant Deeper Blue à Kasparov et sur le coup surprenant de la machine. Il y explique qu'il s'agirait en fait d'un bug. Sur les centaines de millions de combinaisons calculées, la machine ne serait pas parvenue à se décider pour un déplacement plutôt qu'un autre et... aurait donc joué au hasard en sacrifiant un pion. Ce qui avait été pris pour « un signe d'intelligence supérieure » ne serait donc qu'un bug. Et si c'était un peu ça l'intelligence artificielle ? C'est un autre sujet sur lequel nous aurons l'occasion de revenir prochainement. Dans tous les cas, que le coup soit dû à un bug ou une idée de génie de la machine, l'homme a donc permis à la machine de battre l'homme... Ironie du sort quand tu nous tiens.
Contrairement au jeu de dames, le jeu d'échecs n'a pas été totalement résolu à l'heure actuelle. Selon le mathématicien Claude Shannon, il y aurait environ 10^120 parties « intéressantes » à jouer. Pour arriver à ce résultat, il prend une moyenne de 40 coups dans une partie, avec en moyenne 30 possibilités de mouvements pour chaque joueur, soit (30x30)^40 combinaisons. Mais si l'on prend l'ensemble des parties possibles en tenant compte de la règle des 50 coups, on obtient un nombre encore bien plus grand. Dans tous les cas, c'est beaucoup trop important pour être entièrement stocké dans un ordinateur.
Il existe néanmoins des tables partielles avec un nombre limité de pièces en jeu. Pour cinq pièces et moins, elle pèse un peu moins de 1 Go, tandis qu'on passe à plus de 1 To pour six pièces sur l'échiquier. Avec sept pièces, il est question de 140 To (compressés). Les calculs ont été effectués en 2012 à Moscou sur un ordinateur baptisé Lomonosov. Pour rappel, en début de partie, il y a 32 pièces sur l'échiquier, on est donc bien loin d'avoir résolu entièrement ce jeu.
Le cas du jeu de Go et son plateau à 361 cases
Après les échecs, c'est donc au tour du jeu de Go de « tomber » sous la puissance de calcul et l'intelligence artificielle de l'ordinateur. À l'instar des échecs, le nombre de coups possibles est abyssal. Techniquement, sur un Goban de 19x19 (soit 361 cases au total), il est possible de jouer 361 combinaisons, soit 1,4 x 10^768 coups (14 suivi de 767 zéros)... Excusez du peu !
C'est donc bien plus de possibilités qu'aux échecs, mais ce n'est pas la seule problématique. En effet, il est difficile pour une machine d'estimer la force d'une position à un instant T sur le plateau de jeu, c'est-à-dire de déterminer si un coup est intéressant à jouer afin de prendre un certain avantage sur l'adversaire. Aux échecs, on peut compter le nombre de pièces de chacun, les comparer, etc. Au jeu de Go, c'est bien plus compliqué. Or, pour savoir où poser sa pierre, il est important de savoir ce que cela aura comme conséquences.
Ces deux problèmes (estimer la force d'un coup et explorer l'éventail des possibilités) en font un cauchemar pour les intelligences artificielles et leur analyse traditionnelle. C'est pour ces raisons que le mathématicien Dominique Pastre expliquait il y a quelques années que « les méthodes combinatoires ne peuvent pas être utilisées pour le jeu de Go qui est devenu un domaine test pour différentes méthodes d'IA ».
Apprentissage profond et par renforcement pour AlphaGo
Pour parvenir à se hisser au plus haut niveau mondial du Go, AlphaGo est donc passé par le deep learning, ou l'apprentissage profond, et l'apprentissage par renforcement. Une méthode automatique qui utilise des réseaux de neurones, appelés ainsi car proches de ce que l'on retrouve dans le cerveau humain.
AlphaGo s'est ainsi nourri de milliers de parties de jeu de Go des grands champions pour apprendre et mémoriser des techniques, avant de jouer des milliers (voir des millions) de parties contre différentes instances de lui-même. Tel un algorithme qui permet d'identifier des images ou de la voix, l'intelligence artificielle s'améliore un peu plus à chaque itération.
Pour de plus amples détails sur les techniques utilisées par Google, Serge Abiteboul (chercheur à l'Inria) et Tristan Cazenave (Professeur Université Paris-Dauphine) ont publié un intéressant billet sur un blog du Monde.
Un... et deux... et trois.... zéro
Au final, le résultat est là, car AlphGo remporte la victoire, quatre matchs à un face à Lee Sedol, l'un des meilleurs joueurs mondiaux avec pas moins de 18 titres internationaux. Notez que lors d'un match à huis clos en octobre 2015, la machine de DeepMind (filiale de Google) avait déjà écrasé le champion Fan Hui par cinq à zéro. Mais Lee Sedol joue dans une toute autre catégorie, bien plus élevée. Ce dernier pensait même pouvoir battre la machine cinq à zéro avant de changer de discours quelques semaines avant la compétition.
Dans tous les cas, voici le détail des différents matchs :
- 1e partie : victoire d'AlphaGo (186 mouvements)
- 2e partie : victoire d'AlphaGo (211 mouvements)
- 3e partie : victoire d'AlphaGo (176 mouvements)
- 4e partie : victoire de Lee Sedol (180 mouvements)
- 5e partie : victoire d'AlphaGo (280 mouvements)
Lors de la première manche, Lee Sedol a tenté des mouvements audacieux qui sortent un peu des sentiers battus, c'est du moins l'avis des experts sur la question. Une technique classique contre un ordinateur et dont le but est de « déstabiliser » la machine, mais AlphaGo n'a « pas reculé dans les combats » explique Google, et a même remporté la victoire.
Durant le second match, le commentateur Yoo Changhyuk (9-dan pro, le plus haut niveau mondial pour les joueurs professionnels) explique que Lee Sedol a proposé un jeu bien différent « en toute sécurité ». Ce dernier aurait néanmoins commis quelques erreurs qui lui auraient coûté la victoire. Le second présentateur de la rencontre, Michael Redmond (9-dan pro également) se dit « impressionné » par le début de jeu de la machine. Que ce soit avec une entrée en matière classique ou atypique, AlphaGo remporte donc la victoire, ce qui ne laisse que peu d'espoir au champion coréen pour la suite des opérations ?
Selon les présentateurs, le troisième match était l'occasion pour Lee Sedol de jouer son jeu habituel, notamment avec des batailles de kos, une phase très importante du jeu, mais assez compliqué (voir ici pour les détails). Peine perdue, AlphaGo a encore réussi à se sortir de cette situation et à remporter la victoire. Trois à zéro pour la machine de Google, l'issue de la compétition est pliée : Google est vainqueur, peu importe le résultat des deux autres matchs.
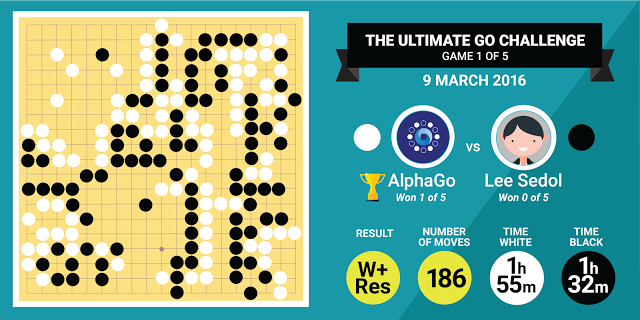


La partie entre les deux protagonistes n'est pour autant pas terminée et le quatrième match était l'occasion pour Lee Sedol de remporter sa victoire, qui sera la seule dans cette compétition. Selon les commentateurs de la partie (deux experts 9-dan pro), le coréen a joué un coup brillant au 78e mouvement, suivi par une erreur d'AlphaGo. Plus gênant, la machine n'aurait pas remarqué son erreur tout de suite et ne s'en serait rendu compte qu'au 87e coup selon Demis Hassabis, PDG de DeepMind. Première victoire de Lee Sedol qui démontre qu'AlphaGo n'est pas (encore ?) infaillible.
Le cinquième et dernier match était très attendu par certains, non pas pour connaitre le gagnant de la compétition puisqu'AlphaGo l'a d'ores et déjà remporté, mais pour voir si Lee Sedol arriverait à mieux cerner la machine au bout de quatre affrontements. C'est comme lors de duels entre humains : ils apprennent à se connaitre et à plus ou moins anticiper les techniques de jeu de l'adversaire. Mais après une victoire au quatrième round, Lee Sedol laisse de nouveau filer la victoire sur la dernière manche. Michael Redmond explique qu'il « était difficile de dire à quel moment AlphaGo était en avance ou en retard, c'était un match serré tout du long ». Quatre à un, score final.


L'enjeu de la compétition était un chèque d'un million de dollars reversé par DeepMind au gagnant. Comme la société l'avait déjà annoncée en cas de victoire, elle a décidé d'en distribuer l'intégralité à l'UNICEF, à des organismes de charité dans le domaine des sciences, à des organismes de bienfaisance ainsi qu'à des organisations du jeu de Go.
Les cinq matchs sont disponibles en intégralité sur la chaine de DeepMind, tandis que vous trouverez les résumés (90 secondes par partie) ici :
Que faut-il retenir de la victoire d'AlphaGo ?
La première chose importante à préciser est que la victoire de la machine sur l'homme au jeu de Go était attendue. Elle arriverait un jour, c'était une certitude. Pour autant, les spécialistes n'attendaient pas cela avant cinq ou dix ans. Les progrès ont donc été plus rapides que prévus, ce qui laisse penser qu'ils pourraient encore s'accélérer dans les années et décennies qui viennent.
Pour Google, « ce test est de bon augure concernant le potentiel de l'IA dans la résolution d'autres problèmes [...] Cela a un énorme potentiel pour l'utilisation de la technologie d'AlphaGo afin de trouver des solutions que les humains ne voient pas nécessairement dans d'autres domaines ». Lesquels ? Ce n'est pas précisé pour le moment.
Plus qu'une victoire de la machine contre l'homme, on peut aussi voir cela comme la victoire d'une équipe de scientifiques (et donc de l'homme) contre un seul humain. AlphaGo ne s'est en effet pas programmé tout seul, il a été mis sur pied par des hommes qui lui ont expliqué le fonctionnement du jeu. Il s'agit d'apprentissage supervisé, comme le rappel le français Yann LeCun, patron de l'intelligence artificielle chez Facebook.
« Nous sommes encore loin d'une machine qui peut apprendre à effectuer avec souplesse la gamme complète des tâches intellectuelles d'un être humain, ce qui est peut-être la marque de la vraie intelligence générale artificielle », ou intelligence artificielle forte, explique Google. Même son de cloche pour Yann LeCun : « Comme je le dis souvent, nous ne connaissons toujours pas les principes de l'apprentissage prédictif (aussi appelé apprentissage non supervisé). C'est ce type d'apprentissage qui permet aux humains (et aux animaux) d'acquérir du bon sens ».
Dans tous les cas, la victoire d'AlphaGo est surtout celle de Google sur le plan médiatique. La société de Moutain View s'est en effet offert une exposition très importante, surtout dans les pays d'Asie, où elle n'est pas toujours en position de force. Ceci explique peut-être pourquoi elle souhaiterait se débarrasser de Boston Dynamics, sa filiale qui met sur pied des robots parfois inquiétants, parfois humanoïdes (ou les deux) comme le dernier Atlas, malmené par ses créateurs afin de le tester.
Commentaires (39)
Le 21/03/2016 à 22h53
https://deepmind.com/alpha-go.html
( combines monte carlo …. and …. )
edit: oooppsss grilled
Le 21/03/2016 à 23h09
Ca dépend de l’interface avec le jeu aussi. Si l’IA passe par un écran + “souris/clavier” (émulation ou autre) pour avoir la même contrainte qu’un utilisateur humain, c’est déjà pas aussi simple.
Le 22/03/2016 à 06h41
ha bah steinfield t’as répondu aussi.
 " />
" />
oui, pour le reseau de neurone, je savais
Le 22/03/2016 à 06h43
ha bah steinfield t’as répondu aussi.
 " />
" />
oui, pour le reseau de neurone, je savais
Le 22/03/2016 à 06h54
l’idée sur SC ne serait-il pas de limiter le micro-management et le temps de réponse de l’IA ?
ainsi avec ces limites, il faudrait trouver un algo complexe pour battre les Humains
Le 22/03/2016 à 07h55
Ils devraient mettre leur IA sur des jeux de bastons avec un poil de complexité (les vieux jeux SNK ou un bon vieux Super Street Fighter 2X ou 3.3). Les possibilités tactiques sont immenses et c’est en temps réel
Le 22/03/2016 à 08h40
Yep, je pense aussi que le but de l’IA sera de battre le joueur en s’adaptant à son kpm.
Le 22/03/2016 à 08h43
Aaah, je ne serais pas si catégorique.
Déjà parce que le brouillard de guerre pose un problème d’entrée de jeu : tu dois définir une stratégie en aveugle. Ca va aussi gêner dans la tactique attaque sur le flanc ? gauche ou droite ? Nul doute que les humains essaierons de trouver ce que l’algo utilise pour decider et le feinter là dessus.
Par contre, aucun doute que l’ordi gagnera en terme d’apm et de calcul des forces en présence pour ne pas livrer de batailles perdues d’avance (note, ça peut être exploité contre lui).
Je pense que tout comme le Go l’ordi ne fera qu’une bouchée des humains, si c’est pas au premier match, ce sera le suivant mais c’est inéluctable.
Non la vraie question c’est : avec quelle unité l’ordi sera le plus à l’aise ? Zerg ?
Le 22/03/2016 à 08h43
Le 22/03/2016 à 08h54
Le 22/03/2016 à 08h59
Serge Abiteboul
De la famille de l’homme le plus classe du monde ?
Le 22/03/2016 à 12h15
Le 22/03/2016 à 12h59
Le 21/03/2016 à 16h44
Sébastien :
La société de Moutain View s’est en effet offert une exposition très importante, surtout dans les pays d’Asie…. Ceci explique peut-être pourquoi elle souhaiterait se débarrasser de Boston Dynamics
Je ne vois pas le rapport de cause à effet ? Quel est le rapport ?
La dernière phrase arrive comme un cheveu sur la soupe.
Le 21/03/2016 à 16h45
De loin le meilleur article que j’ai pu lire sur le sujet ! Merci.
Le 21/03/2016 à 16h55
Je crois que ça n’a pas été dévoilé, mais si quelqu’un connait un article sur quels critères le réseau de neurones d’évaluation des coups se base, je suis preneur.
Pour jouer au go à mon petit niveau, en dehors des formes classiques, je ne vois pas du tout comment “algorithmer” la force d’un coup.
Le 21/03/2016 à 17h09
Justement le renforcement learning signifie ici que la machine joue contre elle même pour s’améliorer, il n’y a pas de “base préétablie” de coups possible sauf pour quelques ouvertures et coups, connus aussi par l’humain en face car assez courants.
Comme expliqué dans l’article, le nombre de possibilité au Go est bien trop grand pour precalculer les coups.
La définition de l’intelligence n’est pas vraiment precise, le cerveau humain aussi fonctionne avec un gros réseau de neurones déterminé par des lois physiques, ça n’empêche pas qu’il soit “intelligent”.
Le deep learning signifie qu’on utilise des réseaux de neurones avec de nombreuses couches (l’output d’une couche est l’input de la suivante), chaque couche possédant typiquement moins de neurones que la précédente, ajoute des non-linéarités et “encode” l’input avec un peu moins de dimensions. La couche ayant le moins de neurones encode ainsi une représentation de haut niveau d’abstraction de l’input. Cet encodage est vraiment “appris” par la machine et n’est aucunement pre-determiné, il sera différent pour chaque instance du réseau (l’aléatoire rentre presque toujours en jeu dans le processus d’apprentissage).
À partir du moment où le comportement de la machine est suffisamment subtil et complexe pour être complètement imprévisible aux yeux d’un des meilleurs experts humains au point de pouvoir le battre au terme d’un tel processus d’apprentissage, je pense qu’on peut raisonnablement parler d’une forme d’intelligence.
Le 21/03/2016 à 17h14
tu ne cites pas la partie intéressante:
la filiale qui met sur pied des robots parfois inquiétants, parfois humanoïdes (ou les deux) comme le dernier Atlas, malmené par ses créateurs afin de le tester.
quant au rapport de cause à effet, Intelligence Artificielle et robots, ça ne te parle pas? ^^
On séduit plus facilement les asiatiques avec une IA qui fait du Go qu’avec des robots militaires humanoïdes, non?
Le 21/03/2016 à 17h27
Le 21/03/2016 à 17h41
Le 21/03/2016 à 17h43
“Pour autant, les spécialistes n’attendaient pas cela avant cinq ou dix ans. Les progrès ont donc été plus rapides que prévus, ce qui laisse penser qu’ils pourraient encore s’accélérer dans les années et décennies qui viennent.”
je suis dubitatif sur ce point,
si je me trompe pas, ils ont utilisé un algo type monte carlo et donc, pas la puissance pure,
je pense que les spécialistes pensaient à un Super-Ordi qui calculerait TOUTES les possibilités du jeu de Go,
d’ici 5 à 10ans donc.
mais là c’était autre chose que la puissance pure.
Le 21/03/2016 à 18h13
Le 21/03/2016 à 18h17
C’est pas Microsoft qui veut devel une IA qui joue à Minecraft ? Faudrait mettre AlphaGo sur le coup, les laisser créer leurs villes (genre Metropolis et Gotham) puis lancer les hostilités " />
" />
Le 21/03/2016 à 18h32
Le 21/03/2016 à 18h55
Le 21/03/2016 à 19h07
Le 21/03/2016 à 19h22
Tous les jeux de plateau sont “symétriques” dans leur façon de donner l’information sur l’état de la partie.
Mais faire un algo qui est capable de faire un plan, de comprendre la stratégie possible d’un advaire à partir d’informations parcellaires, voir carrément l’absence d’information, puis de changer son plan, c’est vraiment pas pour tout de suite.
Mais c’est un sacré challenge !
Le 21/03/2016 à 19h37
Apparemment, tout est suffisamment décrit dans leur papier paru dans Nature pour recoder le logiciel. Les parties utilisées pour l’entraînement du réseau de neurone viennent de KGS.
Le 21/03/2016 à 19h54
Le 21/03/2016 à 15h52
On a une estimation du nombre de serveurs que monopolisais alpha go ?
(J’ai pu lire un millier, mais ca semble pas etre une source très sure)
(Pour relativiser Les capacités mises en jeu pour battre un seul cerveau)
Le 21/03/2016 à 16h00
J’ai lu un article selon lequel ils envisageaient de passer au défi suivant : battre les meilleurs joueurs de starcraft.
(source anglaise :
http://fortune.com/2016/03/11/go-deepmind-starcraft/ )
Vu le temps mis pour le go, j’ai des doutes pour un jeu d’une aussi grande complexité que starcraft…
Le 21/03/2016 à 16h06
j’ai lu 1920 cpu et 280 gpu
http://www.economist.com/news/science-and-technology/21694540-win-or-lose-best-f…
Le 21/03/2016 à 16h08
ouais enfin le nombre d’actions par minute (enfin là on pourra parler par seconde avec l’ordi) va donner un avantage énorme à la machine : la micro gestion des unités va rendre la tâche aisée à la machine.
Le 21/03/2016 à 16h11
J’ai trouvé cela super intéressant, du coup je me suis mis au go. Bon faut avouer que c’est un peu simplet comme jeu. " />
" />
Le 21/03/2016 à 16h13
Le 21/03/2016 à 16h14
Oui enfin appeler cela de l’intelligence artificielle est un brin exagéré, même si c’est le terme officiel.
Dans le cadre d’AlphaGo, il s’agit d’utiliser un réseau de neurones pour estimer le meilleur coup donné en fonction d’une bibliothèque préétablie d’apprentissage.
Bien entendu que l’ordinateur allait finir par gagner un jour ou l’autre, comme cela sera le cas sur tous les jeux à règle bien définie et à champ restreint.
La raison: cela fait longtemps que l’ordinateur peut calculer beaucoup plus vite que l’homme en s’appuyant sur une “mémoire” qui est bien supérieure à la notre.
Mais comme cela est dit en conclusion: il s’agit surtout de la victoire de scientifiques qui ont réussi à programmer un outil avec les bons algorithmes pour battre un homme qui n’avait que son seul cerveau pour se battre.
C’est un peu comme si on s’apercevait qu’un char est plus fort qu’un fantassin armé d’un baton.
On pourra parler d’intelligence artificielle quand une machine sera capable de s’auto programmer pour assimiler, comprendre et interagir avec l’univers qui l’entoure.
Le 21/03/2016 à 16h28
Des petits graph sympa sur le temps de réflexion par tour :
Le 21/03/2016 à 16h33
ouais enfin il restait le coups de latte à la fin de le première partie, le sac à puces ne serait pas revenu faire les 4 dernières parties
Le 21/03/2016 à 16h43
Bah, justement je ne pense pas à dire vrai.
EDIT : Mega-grillé (consolation, mon post est plus détaillé