

Rhea1 : enfin des détails techniques sur le CPU pour les supercalculateurs européens
Un lancement avant Ariane 6 ?

SiPearl donne enfin des détails sur son processeur Rhea1 pensé pour les supercalculateurs. On apprend notamment qu’il exploitera 80 cœurs Arm Neoverse V1. Il n’arrivera qu’en 2025, en retard sur ce qui était encore prévu il y a quelques mois.
En septembre dernier, nous avions rencontré les équipes de SiPearl, une société française (basée à Maisons-Laffitte) en charge de développer le processeur européen pour le HPC (calcul haute performance). Il sera notamment dans JUPITER, le premier supercalculateur exascale européen (financé en partie par la Commission européenne) qui sera installé en Allemagne.
Il y a un an, SiPearl bouclait un tour de table de 90 millions d’euros auprès d’Arm, Eviden (Atos), le fonds d’investissement European Innovation Council (EIC) et French Tech Souveraineté. Cette manne lui a permis ainsi de régler ses soucis financiers, de recruter et d’aller de l’avant. Marie-Anne Garigue, directrice de la communication de la société, affirmait que les soucis étaient uniquement financiers, pas techniques.
80 cœurs Arm Neoverse V1…
On sait depuis longtemps que le processeur sera articulé autour de cœurs Arm Neoverse v1. On connait désormais leur nombre : 80 cœurs par CPU. Le Neoverse V1 est pour rappel un dérivé du Cortex-X1, mais pensé pour les datacenters. Arm a depuis lancé les Neoverse V2 (dérivés du Cortex-X3) et récemment le Neoverse V3.
NVIDIA utilise par exemple 72 cœurs Arm Neoverse V2 pour la partie CPU de sa puce GH200 Grace Hopper Superchip et de sa nouvelle GB200 Grace Blackwell Superchip. Même chose chez Amazon avec son SoC Graviton4 et chez Google avec l’Axion.
…avec des extensions vectorielles évolutives
Revenons à SiPearl et son Rhea1. Chacun des 80 cœurs Neoverse V1 sera accompagné de « deux unités SVE [Scalable Vector Extension ou extension vectorielle évolutive, ndlr] de 256 bits », comme c‘est le cas par défaut avec les cœurs Neoverse V1.
Ces deux unités sont d’ailleurs une différence importante avec les Cortex-X1. Selon SiPearl, elles permettent « des calculs vectoriels rapides tout en optimisant l’espace et l’énergie utilisée ».
Arm ajoute qu’elles proposent « de meilleures performances HPC et IA/ML ». L’entreprise est un peu plus loquace et ajoute que « SVE a été inventé en collaboration avec Fujitsu pour le projet Fugaku [un supercalculateur qui a pendant un temps occupé la première place du Top500, ndlr] et permet une programmation agnostique en largeur vectorielle. SVE permet l’exécution de code de vecteurs allant de 128b à 2048b de large sur Neoverse V1 sans nécessiter de recompilation ».
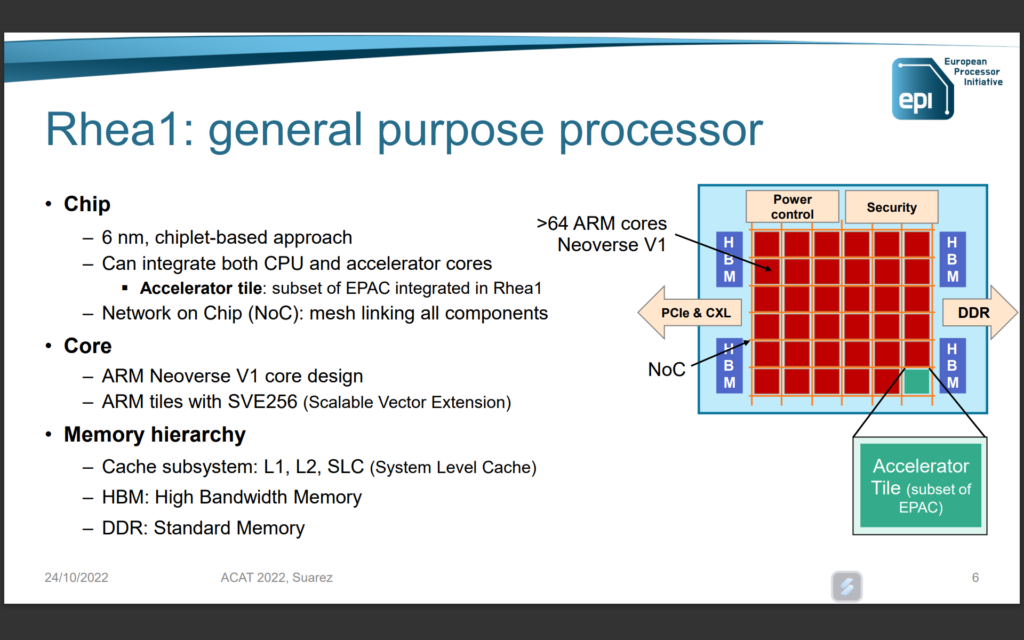
HBM, DDR5,104 lignes PCIe 5.0 et CMN-700
Côté mémoire, Rhea1 dispose de « quatre piles HBM » (dans d’autres documents, il est précisé HBM2e) et de « quatre interfaces DDR5 », prenant en charge deux DIMM par canal. On retrouve aussi 104 lignes PCIe Gen 5 avec une répartition 6x 16 lignes + 2x 4 lignes (soit 104 lignes au total, le compte est bon).
SiPearl précise qu’un « réseau maillé cohérent sur puce (NoC) haute performance arm Neoverse CMN-700 [CMN pour Coherent Mesh Network, ndlr] pour interconnecter les éléments de calcul et d'entrée/sortie » est aussi de la partie. Là encore, c’est dans le package proposé par Arm avec sa plateforme Neoverse V1. Le CMN-700 peut gérer jusqu’à 256 cœurs par die, selon Arm.

Multiples langages : C++, GO, Rust, TensorFlow, PyTorch
Côté programmation, le CPU Rhea1 « sera supporté par une large gamme de compilateurs, de bibliothèques et d'outils, allant des langages de programmation traditionnels tels que C/C++, Go et Rust aux structures d'intelligence artificielle modernes comme TensorFlow ou PyTorch ».
Rhea1 n’arrivera finalement qu’en 2025
On apprend par contre que le processeur aura encore du retard puisque « les premiers échantillons de Rhea1 seront disponibles en 2025 ». En effet, en septembre dernier, SiPearl nous expliquait que la commercialisation se ferait dans le « courant de l’année » 2024. En avril 2023, après la levée de fonds, l’entreprise annonçait « une commercialisation début 2024 ».
Le supercalculateur européen JUPITER devra donc lui aussi attendre, puisqu’il est prévu qu’il intègre les processeurs Rhea1. La Commission européenne expliquait il y a peu que « le supercalculateur JUPITER devrait être accessible à un large éventail d’utilisateurs européens à partir de la fin de 2024 ».
Rhea2 aussi en 2025 ?
Rhea2 était prévu pour 2025 aux dernières nouvelles, avec une technologie « dual chiplet » permettant d’intégrer plus de cœurs sur une même puce. La société ne précise pas si le calendrier de la seconde génération glisse lui aussi.

Commentaires (16)
Abonnez-vous pour prendre part au débat
Déjà abonné ou lecteur ? Se connecter
Cet article est en accès libre, mais il est le produit d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles d'un média expert
Profitez d'au moins 1 To de stockage pour vos sauvegardes
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 14/05/2024 à 16h31
Le 15/05/2024 à 16h54
Le 14/05/2024 à 17h00
Le 14/05/2024 à 18h44
Au moins, peut-on espérer les bench en 2025. Le reste c'est de la com'.
Par contre rust pour du HPC ?! Mais attend là, c'est Chat-GPT4 qui a déconné ou bien ils sont vraiment sérieux ?
Le 14/05/2024 à 22h11
De ce que j'en ai lu (je ne suis pas dev), c'est quasi aussi performant de C/C++, tout en ayant des protections contre les fuites de mémoire.
Modifié le 15/05/2024 à 10h19
Par HPC, j'entends calculs à mémoire partagées et à mémoires distribuées et le calcul sur des accélérateurs. Pour le dernier, il y a beaucoup de wrapper pour s'appuyer sur les API du fabricants àla fin, donc Rust, C ou Python ne change rien au problème ici. Pour la mémoire distribuée, je ne sais pas vraiment mais je ne vois pas de raison techniques pour lesquelles Rust serait en deça, surtout qu'il va wrapper les lib dédiées à cette tâche.
Non, le problème de Rust va être pour la mémoire partagées, et notamment lorsqu'on l'applique pour séparer des grosses boucles (e.g., grosse inversion de matrice) en plus petits boucles chacune allant tourner sur un coeur de calcul du CPU (en pratique, c'est plus compliqué mais c'est l'idée).
En C/C++ quand tu fais ce genre de choses tu es responsable de gérer correctement les accès mémoires (et donc d'éviter les races conditions et autres soucis du calcul //). Mais en pratique, tu utilises des libs qui t'aide à faire ce travail.
Cette façon de faire lui permet de garantir certaines sécurités à la compilation (pas uniquement au niveau des fuites mémoires, mais également au niveau des races conditions et autres choses désagréables et parfois difficile à débugger). Sauf que voilà, ceci vient avec un prix ! La copie (qui s'effectue d'abord pour feeder les coeurs puis pour récupérer les résultats) augmente l'usage de la mémoire (bottleneck n°1 à l'heure où j'écris ces lignes), sature les unités de copies mais également les caches (j'ai pas encore vu Rust être capable d'exploiter les instructions NT pour la mémoire).
Et perso, je trouve ça syntaxe trop AT&T et pas suffisamment propre pour lire naturellement du code, déjà très technique et parfois délicat à comprendre (coucou le F77
Dans ma boîte j'ai mené, avec l'aide d'un collègue qui ne jure que par Rust, des benchmarks pour mesurer les perfs. Tu comprendras que je n'ai pas le droit de poster les résultats ici. Par contre, nous nous sommes inspirés de ce papier (même si je le trouve par super en terme de qualité) : Is Rust C++-fast? Benchmarking System Languages on Everyday Routines ainsi que ce document de l'EuroHPC.
Et nous trouvons des conclusions similaires dans nos expérimentations mais pas toujours les même écarts.
La conclusion générale que je partage, car on peut en déduire la même chose en lisant ces papiers et d'autres, c'est que pour faire un code très performants en C++ (en somme le H, de HPC) il faut un dev/ingé C++ expérimenté sur ces questions avec de larges compétences et une très bonne connaissance full-stack entre la µ-arch du CPU, le C++ et l'assembleur produit. Tandis qu'avec Rust, même sans connaissance (mais en étant pas une tanche non plus), tu arrives à être performant (le P de HPC) à condition d'utiliser des libs en C++, parce que beaucoup de libs de calculs HPC de bonnes qualités, éprouvées et de très bonnes perfs en Rust n'existe pas encore.
Et pour finir, ceci n'est valable qu'à cet instant T. Rust est libre d'évoluer pour ce perfectionner dans le HPC mais ça ne sera pas, selon moi, sans devoir faire des sacrifices sur son fonctionnement. Et dès lors, Rust ou C++ ne sera plus qu'une question de goûts et de couleurs. Et comme j'aime taquiné mon collègue syntaxe AT&T vs Intel
Le 16/05/2024 à 00h05
Ce que j'en ressort, globalement, est qu'on arrive toujours au même problème de trade-off, qu'est qu'on gagne, qu'est ce qu'on perd.
Soit on fait son code de façon ultra optimisé (C++) pour la tache spécifique dont on a besoin et on paye le prix de sa complexité (gestion de la mémoire). Soit on délègue (Rust), c'est moins complexe, donc plus rapide à sortir un résultat, mais c'est du coup moins performant.
Comme dans mon monde (admin système), parfois, on utilise des softs sur étagère, c'est lourd (déploiement de solution), on se sert de 20% des features, c'est pas très performant, mais ca marche sans prise de tête.
Sinon on code un truc en
PythonGolang qui fait le taff spécifique de façon super optimisé, mais il faut maintenir l'outil.Je ne connais pas du tout le monde du HPC, mais j'imagine qu'une fuite de mémoire n'est pas si catastrophique. Il n'y a pas de client (genre site web public), ni d'attaquant cherchant des failles de sécu. Les calculs ont de toute façon une durée limité. Et j'imagine que sur un calcul réparti, la perte d'un noeud est un événement "normal". Au pire, ça plante, on le relance?
Modifié le 16/05/2024 à 11h06
Oui la notion de tradeoff est présente, comme toujours. Et d'ailleurs Python se retrouve en HPC, notamment des communautés moins "geeks" (e.g., sciences plus orienté biologie...). J'ai souvenir lors d'une conf en Asie d'avoir retrouvée une amie virologue qui présentait un talk sur la simulation de virus biologique sur ordinateur. Et quand j'ai discuté avec elle, elle me racontait que son équipe est divisée en deux sous-équipes. L'une de virologues (doctorants, post-doc...) qui code en Python et une autre avec un profil plus d'info/math appliquée qui développe les outils mathématiques et numériques pour les premiers.
Mais Rust, j'ai encore du mal à voir l'idée tant (et c'est un avis personnel) je trouve que la courbe d'apprentissage est plus ardu que Python en raison d'une syntaxe assez horrible, pour au final ne pas apporter de vrais avantages (la fuite mémoire ok, mais si c'est uniquement lors de l'initialisation de la matrice (par ex.) c'est pas la peine de se faire chier à compiler pendant 30 ans).
Les fuites mémoires sont catastrophiques en HPC aussi. Pas forcément pour les failles de sécurités (quoi qu'on puisse en discuter car il y a un gap entre le HPC sur un cluster du CEA et celui chez un provider).
Le gros problème des fuites mémoires en HPC selon moi, c'est surtout le risque de corrompre des données, et donc d'affecter les résultats obtenus. Parfois ça saute aux yeux qu'il y a un problème (tiens mes électrons sont plus rapide que la lumière de 231%
La perte d'un noeud je ne sais pas à l'heure actuelle si ça réagit comme avant. J'ai quitté le domaine depuis un moment.
Mais je me souviens une fois d'un noeud de calculs qui a claqué (en tout cas c'est que j'en ai déduis) car subitement mon calcul a brutalement planté. Les logs de mon code n'ont rien indiqué d'anormal mais par contre celui de la session de calculs m'a poliment dit qu'il ne trouvait plus le noeud (l'IP était injoignable et que la fonction que je demandais ne pouvait pas fonctionner -> crash [Et aussi parce que je n'ai pas prévu ceci dans mon code]).
Maintenant, avec une sorte de convergence qu'on observe entre le monde du HPC et du data-center, je me demande si, avec des softs comme openStack, ce genre d'incident (rare sur une machine entretenue) ne ce gère pas en sous-marin.
Pour l'aspect sécurité, oui il y a des choses de valeurs (codes, résultats) pour des questions de gros sous industriels mais aussi pour des choses plus militaires.
Tu te connectes toujours à un front-end pour préparer tes simulations. Généralement compiler le code, mettre les données, configurer les chemins et soumettre le job aux back-ends (le calculateur en lui-même).
En fonction des endroits, de ta nationalité... tu peux te connecter directement avec la création de ton compte en SSH avec une machine de ton institut (filtrage MAC au niveau du pare-feu) et le front-end n'est pas joignable de l'extérieur ni via le VPN.
Dans d'autres endroits, tu dois montrer patte blanche et surtout, tu ne peux pas déposer ton code sans ce que celui-ci ne soit pas revue par un soft ou un humain pour s'assurer que tu n'as introduit de backdoor ou autres exploits. Et parfois, tu n'as pas même pas le droit de le faire, tu es obligé de passer directement par un intermédiaire (confrère ou sous-traitant) qui s'occupe de tout faire pour toi.
Note que ça devient une tendance d'isoler les simulations (soit à la "docker" ou avec des hyperviseurs de type 1).
Edited: typos + reformulations
Modifié le 14/05/2024 à 18h53
Le 15/05/2024 à 07h28
Ça me rappelle les discussions vaccins COVID. Évidemment qu'on dépasse les délais. Qui ne l'a jamais vécu ??
Modifié le 15/05/2024 à 08h35
Il est très rare qu'un projet ne rencontre pas des aléas et sorte dans le planning défini en début (qui n'est là que pour donner un cap à tenir, au mieux). D'où l'intérêt des REX réguliers.
Quant aux soucis financiers ils viennent souvent d'une vision courte-termiste. En UE nous voulons des résultats immédiats, des bénéfices rapides, là où les USA, par exemple, vont accepter de débourser des millions voire des milliards avant.
C'est une approche différente, pas forcément meilleure. Mais différente (perso je pense que le curseur doit être entre les deux : prise de risque mais savoir arrêter la casse suffisamment tôt - même si ça dépend grandement du type de projet).
Le 15/05/2024 à 12h08
je penser a cela en faite ^^
Le 15/05/2024 à 14h17
Le 15/05/2024 à 16h00
Le 14/05/2024 à 21h36
Je suis déjà dehors.....
Le 14/05/2024 à 22h49
Les Inconnus - Le Journal Japonais
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?