

Conteneurs, machines virtuelles : quelle différence ?
Mise en boîte

On parle souvent de conteneurs et de machines virtuelles. Vous êtes-vous déjà demandé ce qu’ils pouvaient bien être et la différence entre les deux ? nous vous expliquons en quoi ils consistent et comment ils sont utilisés.
Dans un ordinateur classique, on trouve trois grands ensembles : le matériel, le système d’exploitation et les applications. Le rôle du système d’exploitation est primordial : il exploite le matériel et présente des capacités aux applications (via des interfaces de programmation, ou API), qui peuvent les utiliser pour proposer des services. Le principe ne change pas, quel que soit le type d’ordinateur ou le système.
Si ce système suffit dans la majorité des cas, il en existe de nombreux où cette organisation devient rébarbative. Exemple classique : vous développez une application sur un Mac et souhaitez en tester une variante Windows. En toute logique, vous vous tournez vers un ordinateur équipé du système de Microsoft pour y installer l’application et observer son comportement.
Autre problématique : le système d’exploitation. Tout éditeur d’une application doit viser une ou plusieurs versions d’un système, chacune avec des spécificités. La configuration peut largement varier d’une machine à une autre, même si les composants centraux sont normalement présents. Il faut notamment composer avec les dépendances de l’application, c’est-à-dire tous les composants dont elle a besoin pour fonctionner.
Pour s’affranchir de ces problèmes dans certains scénarios, beaucoup recourent aujourd’hui à une forme de virtualisation ou une autre. Commençons par les machines virtuelles, qui existent depuis longtemps.
Qu’est-ce qu’une machine virtuelle ?
Une machine virtuelle – ou VM – est une copie numérique d’une machine physique. Au sein d’un seul fichier, on trouve toutes les informations sur le matériel, le système d’exploitation et les applications qui y sont installées.
Cette pratique a été largement démocratisée par des projets libres comme VirtualBox et des sociétés telles que VMware et Parallels. Ses scénarios d’utilisation sont nombreux. Dans le cadre de tests par exemple, on peut installer un client de virtualisation (VirtualBox par exemple) et créer une machine virtuelle par système d’exploitation que l’on veut tester.
Cette pratique, longtemps limitée, a pris son essor avec la puissance toujours grandissante des ordinateurs, en particulier la multiplication des cœurs dans les processeurs et la baisse du coût de la RAM. Sur une machine contenant par exemple 16 Go de mémoire, il est simple de créer une machine virtuelle en contenant 4 ou 8 Go pour tester un environnement.
Tous les clients de virtualisation permettent de paramétrer plus ou moins finement les caractéristiques de la machine, comme le nombre de cœurs, la quantité de mémoire, l’espace de stockage, le type d’interface réseau, ou encore des options plus poussées comme le type de firmware, le chiffrement de la machine virtuelle, la gestion de l’énergie, etc.
Attention à ne pas confondre virtualisation et émulation. Cette dernière consiste à simuler la présence d’un matériel à l’architecture différente de la machine hôte. C’est ce que font par exemple les émulateurs de console. Cette opération est autrement gourmande en puissance de calcul.
L’hyperviseur tout-puissant
Outre le fait de pouvoir mettre en place rapidement un environnement de test, les machines virtuelles permettent de beaucoup mieux exploiter le matériel sur des configurations très musclées, comme peuvent l’être les serveurs.
Il est désormais courant qu’un serveur dispose de plusieurs machines virtuelles, par exemple pour créer des environnements spécialisés et isolés. Un même serveur peut ainsi présenter une multitude de machines de type Unix, Linux ou Windows, en fonction des besoins des clients. Ce type d’utilisation a explosé avec le cloud.
Mais qui orchestre ce grand ballet ? L’hyperviseur, un composant dont la mission est de créer et exécuter les machines virtuelles. Il leur attribue les ressources choisies, fait le lien avec l’hôte (le matériel) tout en l’isolant des machines virtuelles. Avec un hyperviseur, et selon la solution choisie, les ressources ne sont pas fixes et peuvent être allouées dynamiquement en fonction des conditions.
Point important, c’est toujours le matériel de la machine hôte qui exécutera les opérations. À charge pour l’hyperviseur de répartir les demandes de calculs en fonction des critères fixés par l’administrateur.
Petite précision enfin. Il existe deux types d’hyperviseur. Le type 1 désigne un hyperviseur s’exécutant directement sur le matériel, à la place du système d’exploitation. On le rencontre essentiellement dans les centres de données et autres environnements basés sur des serveurs. KVM sur Linux, Hyper-V sur Windows, Proxmox VE ou encore vSphere de VMware sont des hyperviseurs de type 1. Le type 2 s’installe sur un système comme une application et se rencontre surtout sur des ordinateurs personnels. VirtualBox, VMware Workstation et Parallels Desktop (sur Mac) en sont des exemples.
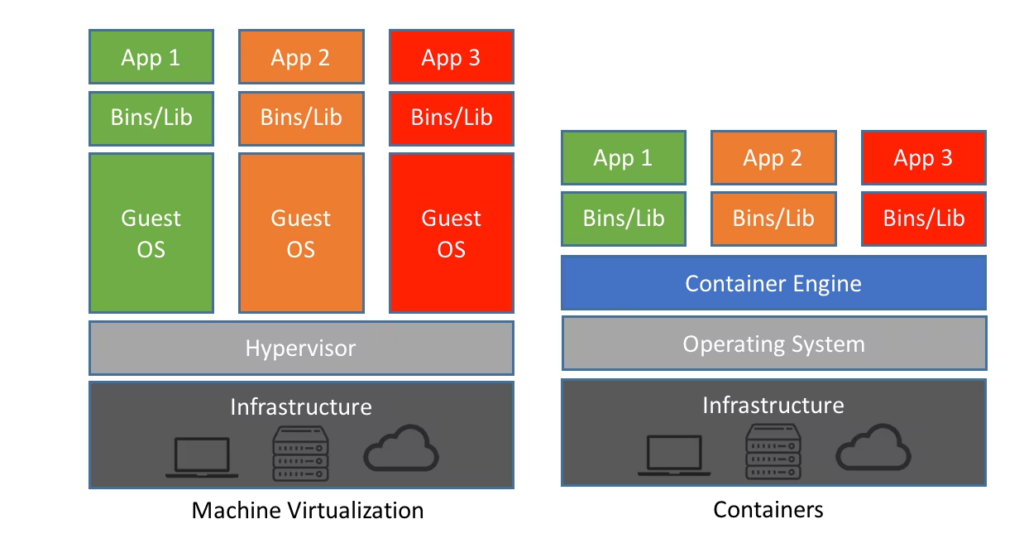
Qu’est-ce qu’un conteneur ?
Un conteneur présente des similitudes avec une machine virtuelle, dans le sens où il s’agit d’un assemblage de paquets devant fonctionner de manière isolée. La ressemblance s’arrête ici, car si un hyperviseur peut prendre la place d’un système d’exploitation, le conteneur vise, lui, l’applicatif.
Un conteneur regroupe un ou plusieurs processus ainsi que toutes les dépendances nécessaires. Il ne tient compte de l’environnement d’exécution qu’en tant que plateforme générale, mais il offre un gros avantage : il ne tient presque pas compte de la version et de la configuration.
L’exemple le plus courant est le Snap, largement poussé par Canonical. Depuis le Store d’Ubuntu, de nombreuses applications sont présentées sous cette forme. À l’installation, le conteneur contient toutes les données nécessaires au bon fonctionnement de l’application. Cela permet aux éditeurs de créer un environnement « idéal », avec toutes les bonnes versions des composants. Le désavantage est connu : élargir ce fonctionnement à toutes les applications peut consommer beaucoup plus d’espace disque.
En d’autres termes, le conteneur virtualise le système d’exploitation, là où la VM virtualise le matériel. Dans les deux cas, on parle d’images.
Avantages, orchestration et déploiement
Au-delà de la simple isolation vis-à-vis du système d’exploitation, les conteneurs ont d’autres gros avantages, notamment en matière de déploiement.
La fin des grandes applications monolithiques et l’arrivée du cloud ont permis l’éclatement du code et le grand avènement des microservices. À la clé, une redondance améliorée et la possibilité de laisser un service accessible pendant des opérations de maintenance. Les conteneurs convenaient parfaitement aux microservices par leur souplesse.
L’arrivée de Docker a largement participé à en répandre l’usage. Cette plateforme simplifie la création de conteneurs en regroupant tout ce qui est nécessaire à une application pour fonctionner. D’autres solutions sont apparues par la suite, avec le même objectif, comme Buildah, Containerd ou Podman. Cette facilité n’est cependant qu’une étape, la souplesse recherchée pour le déploiement appelle d’autres outils.
C’est là qu’entrent en piste d’autres projets comme Kubernetes, Docker Swarm ou encore Apache Mesos. Ces outils prennent en charge le déploiement et l’exécution des conteneurs, leur coordination et leur planification. Les administrateurs peuvent ainsi définir précisément quel conteneur doit être déployé, où et quand, que faire en cas de mise à jour, de mise à niveau ou en cas de remplacement sans temps d’arrêt. Ces infrastructures surveillent également le fonctionnement général, l’état de santé des conteneurs, etc.

Commentaires (51)
Le 21/02/2024 à 12h58
Mon retour de vécu, c'est que la virtualisation a très largement permis de diminuer le nombre de serveur physiques dont une entité avaient besoin pour fonctionner, on pouvait voir transformer une salle entière en une seule baie selon les cas de figure. On avait ainsi une simplification physique mais pas forcément logique dans le sens où il faut faire vivre les VMs. Chaque changement ou mise à jour reste à définir. Ils restent des irréductibles qui ne jurent que par les serveurs physiques, prétextant une baisse de performance d'une VM vs un serveur physique, ce discours est encore maintenu par certains intégrateurs d'applications dont l'ingénierie remonte à des années.
La conteneurisation elle est plus de l'avènement du cloud, où les hébergeurs ont réfléchi à un service de masse dans le commissionnement, le maintien du service, ses changements et son arrêt, donc dans le cycle de vie d'une applications. Cela a pris en puissance dans les années où les entreprises commençaient à avoir des liens internet "abordables" et performant pour aller vers des applications de plus en plus SaaS/externalisées.
Google a rendu son projet Kubernetes en open source en 2014 et il n'a fait que monter en puissance, les conteneurs ne sont pas aujourd'hui présent dans toutes les entreprises, cela reste une marche conséquente dont les bénéfices ne semblent pas perceptible à première vue, mais selon moi cela sera partout d'ici 10 ans.
Un Kubernetes apporte de nombreux avantages au développement d'applications, ce qui nécessite quand même d'y avoir été formé convenablement. Dans les avantages on peut compter: trivialité de créer des environnements de test identique à la production, trivialité dans les mécanismes de mises à jours et de rollback, un environnement toujours défini dans le conteneur qui est neutre et écarte tout bug lié aux X dépendances qui pourraient être installées sur serveur, coexistance possible de plusieurs process qui remplisse la même fonction, par exemple des bases de données en différentes versions...
Sur un autre sujet, le conteneur (docker, lxc... autres) est extrêment léger comparé à une machine virtuelle sur laquelle on mettrait l'application voulue, tant en espace disque qu'en mémoire consommée.
Par contre en terme de sécurité, il y a avertissement qu'un conteneur partage le même noyau que son "hôte" contrairement à une machine virtuelle où le noyau lui est dédié. Le risque c'est qu'une faille du noyau peut permettre à un process d'un conteneur d'atteindre l'hôte, l'hôte est donc moins isolé que dans le cas de la machine virtuelle. C'est quelque chose qui je pense pouvoir dire n'est pas activement exploité par des hacker, nous voyons très très peu de news d'attaques de ce genre, mais c'est une attention qu'il faut avoir en terme de sécurité.
Le 22/02/2024 à 09h45
Le plus gros prb des containers c'est les librairies obsolètes, pour log4j par ex il faut que chaque appli publie son patch containerisé et qu'ensuite tu les màj un à un.
Avec une VM tu aurais pu màj la librairie à la main (en prenant évidement un risque de régression) sur chaque VM.
Avec un serveur "monolithique" qui fait tourner plusieurs services, le gestionnaire de paquets te donne direct les dépendances problématiques et peut les màj automatiquement. (avec là aussi un risque important de régression)
Modifié le 22/02/2024 à 10h32
Il y a quelques années j'exploitais des VM avec XEN et ai finis par revenir sur du physique "à l'ancienne" pour des questions coût/performances
Le 22/02/2024 à 11h16
Quand ont travaille correctement, on ne met pas à jour une image de container, on en crée juste une nouvelle qui est à jour. Ensuite, les ops font juste le rollout de la nouvelle version de l'image.
Modifié le 22/02/2024 à 14h38
Je suis un de ces irréductibles mais je ne demande qu'à changer :) Je vois souvent des débats VM vs container. Et pour héberger une application, on me tanne pour que fasse de la virtualisation, plus précisément du conteneur ("car la VM c'est lourd et puis ceci et puis cela ..."). Ma question est alors de l'intérêt du conteneur tout court !? J'ai 3 serveurs, 1 pour héberger une application bien spécifique, 1 pour héberger plusieurs applications internes, le dernier en redondance de celui multi-applications. Pas besoin de changement d'échelle (max 20 utilisateurs), les serveurs sont chez nous (pas de coût variant selon la charge), tous les environnements sont identiques (Debian), les applications sont compilées en statique donc embarquent toutes les dépendances, une utilisation de cgroup seulement pour une application qui a tendance à prendre trop de RAM. Quel est l'intérêt de dépenser de l'argent et du temps pour mettre en place du conteneur, qui plus est, d'y ajouter un orchestrateur comme K8s ?
Le 22/02/2024 à 18h13
C'est particulièrement pratique quand on doit faire vivre plusieurs versions de la même application en parallèle et qu'on veut éviter les risques de conflits.
C'est aussi un très bon moyen d'en finir avec les devs qui se planquent derrière un "oui mais sur mon laptop ça marchait"
Mais oui, comme toute chose, ça a un coût, à minima d'apprentissage, et si c'est mal utilisé, ça ne tient pas ses promesses.
Mon conseil: éviter les conteneurs si ce n'est pas pour les utiliser avec une orchestration et une méthode de travail adaptée, où la solution se transforme en problèmes.
Le 21/02/2024 à 13h03
Dans la réalité, les gros progiciels historiques qui se sont "containerisés" ont simplement fait un gros paquet avec une image pleine de bordel qui prend 8GB de RAM et 4CPU pour tourner. Et pas que, même des devs internes mal architecturés sont comme ça.
Ouep, de la VM dans du conteneur sur de la VM.
Modifié le 21/02/2024 à 13h18
Les mêmes qui commencent à se faire rattraper par leur comptabilité sur les factures exorbitantes qu'ils se rendent compte avoir à payer aux fournisseurs de cloud, dont ils n'avaient rien estimé.
Comme souvent dans le monde de l'entreprise. Il y a aussi du gachis énorme dans ces endroits, juste ils ne sont pas tenus de les expliquer ou les communiquer.
Le 21/02/2024 à 16h52
...rien que l'écrire ici engendre la nécessité de me pincer pour voir si je ne suis pas occupé à pioncer
...aïe
Le 21/02/2024 à 13h46
Une petite remarque, Buildah sert à construire les images des containers au format OCI mais n'est pas un exécuteur comme docker, podman ou containerd.
Pas un petit mot sur LXC ?
Le 21/02/2024 à 14h00
Le 21/02/2024 à 14h29
Le 21/02/2024 à 17h13
KVM n'est qu'un module du noyau linux, qui fait tourner les VM dans l'OS en parallèle des applications. Et donc c'est un type 2. Pour toutes les solutions basées sur KVM on ne peut parler de type 1 que dans le cas particulier où on utilise une distribution linux dédiée à la tâche d'hyperviseur (comme Proxmox VE).
Même chose pour Hyper-V.
À l'opposé Xen et Vmware ESXi sont de vrais hyperviseurs de type 1 qui s’exécutent au plus bas niveau possible, avant même qu'un OS soit chargé.
Le 21/02/2024 à 19h32
Au final, dans la majorité des cas, la notion de type 1 ou type 2 ne veut plus rien dire, et compter le nombre de rpm ou de deb installés pour essayer de départager ne sert pas à grand-chose.
Ce qui compte réellement, c'est la capacité d'une pile de virtualisation à fournir une orchestration, capable de gérer les ressources cpu et ram, d'organiser les services de stockage et de réseau pour les présenter aux machines virtuelles, d'organiser la redondance en cas de panne, voire la haute disponibilité, de faire tourner les vm's avec un niveau d'isolation empêchant des attaques via hyperviseur, ...
En parlant de proxmox, la dernière fois que j'ai regardé, ça ne supportait même pas s/Virt ... pas très pro pour une distro KVM...
Le 21/02/2024 à 22h57
Le 22/02/2024 à 18h21
Une lecture des sources de KVM ne semble pas pour le moment aller contre ce constat, alors que dans Xen, cette hiérarchie était limpide. Mais je vais encore creuser un peu.
Le 26/02/2024 à 12h04
Le 24/02/2024 à 01h08
KVM parce que l'application fait appel à des modules du kernel et sont contrôlable depuis l'OS mais sont implémentés sur le noyau. Proxmox ne change pas ce comportement, c'est une Debian modifiée et centrée sur la virtualisation. La version du noyau Proxmox est plus avancée qu'une Debian classique, ce qui lui permet sûrement de profiter des versions plus récentes des modules de virtualisation implémentés dans le noyau, ainsi que les nouveautés hardware.
Hyper V est annoncé de type 1 par Microsoft, quelque soit le Windows qui est derrière, client (10, 11...), serveur, OS dédié...
VMware vSphere (type 1) dispose bien d'un OS appelé PhotonOS qui tourne pour faire fonctionner l'ESXi, mais sont restés sur des fonctions de gestions et il a un aspect très léger/austère sans vCenter, mais on peut y aller en SSH.
Virtualbox et Vmware workstation/player sont type 2, et dépendant des appels matériel réalisés par Windows au lieu de l'accès direct dont implémentent et disposent les type 1.
Le 26/02/2024 à 12h02
Modifié le 21/02/2024 à 20h43
https://fr.m.wikipedia.org/wiki/Fichier:Cloud_Computing_-_les_diff%C3%A9rents_mod%C3%A8les_de_service.svg
Permet d'avoir un visuel sur ce qui est du domaine de "l'infra" de celui de "l'exploitant systeme/appli"
Une VM : IAAS
un container : PAAS
Le 22/02/2024 à 07h50
Le 22/02/2024 à 17h10
Le 22/02/2024 à 09h36
Imaginons un Snap toto dépendant de python 3.11, un autre titi dépendant de même version de python. Chaque snap vient avec sa propre dépendance (et donc on a deux pythons identiques dans deux dossiers séparés), ou il y'a quand même mutualisation et toto et titi pointe sur la même dépendance unique ?
Le 22/02/2024 à 09h40
Le 22/02/2024 à 10h38
Modifié le 22/02/2024 à 10h33
C'est pour ça que je me suis retrouvé comme un fruit avec un "/" saturé sur tout les Ubuntu de toute la famille...
Je faisais un partitionnement depuis toujours avec 20Go pour "/", le reste pour swap + /home.
Et les Snap m'ont progressivement saturé tout les "/", empêchant les mises à jours système grrrr
Je suis donc passé à 50Go pour "/", suivi de 20Go non attribué, et enfin le reste pour swap et /HOME.
Au moins, si "/" se sature je peux ettendre sur les 20Go suivant... Et eviter d'avoir à faire des libérations, mouvement, création de partition dans tout les sens pour etendre le "/" (sa prend un temps fou)
Le 22/02/2024 à 11h19
Le 22/02/2024 à 12h05
Pour mon utilisation je n'ai vu que des inconvénients (le niveau de sécurité me suffisait, pas besoin que mes applications soit isolée les unes des autres) :
Entre les problèmes de consommation d'espace, les profil firefox pas toujours repris, les lenteurs, les doublons de versions possible d'application (exemple une version apt et une version ou plusieurs Snap),...
C'est a perdre tout les utilisateurs "bureautique"
Avec apt, j'ai presque jamais eu de problème de conflit de version de paquets ou problèmes de dépendance (sauf en installant des choses particulières qui ne sont plus du simple usage bureautique).
Brulons ces formats
Le 22/02/2024 à 13h09
Pour finir avec un disque tellement saturé que ma bécane a fait des plantages au moment de passer en veille...
Le 22/02/2024 à 12h15
Ça n'empêche pas que je trouve que ces snap ou autres sont une grosse régression.
Le 22/02/2024 à 13h17
Ca permet également justement d'eviter d'avoir une saturation "/" avec les données d'utilisateurs (alors pour le coup c'est con quand Snap se charge de saturé tout seul la racine
Mais je reconnais qu'avec le faible coût stockage et changement d'usage pour les photos/videos, sa à perdu de son interêt... J'ai pas suivi le mouvement et j'ai gardé mes reflexes qui ont plus de 15ans
Le 22/02/2024 à 16h32
Maintenant, avec des systèmes de fichier supportant des quotas par répertoire (XFS par exemple), il est aussi possible de bloquer une croissance anarchique sans mettre de partition dédiée.
Pour Flatpak, par exemple, je bloque désormais la taille maximum de /var/lib/flatpak via quota.
Le 22/02/2024 à 16h52
Le 22/02/2024 à 17h18
Mais dans l'ensemble, comme je ne vois pas de contre-indications particulière j'ai tendance à garder les mêmes règles d'hygiène pour le pc personnel que pour les serveurs d'entreprise, et de temps en temps j'ai le plaisir de pouvoir régler des problèmes rapidement avec les bons outils.
Le 22/02/2024 à 15h32
Le 22/02/2024 à 15h52
Modifié le 22/02/2024 à 16h52
J'utilise Gparted pour les repartitionnements depuis un live USB.
Avec les partitions / et /home séparés, deux cas de figures
-> Soit je peux agrandir / sans déplacer la partition /home :
je fais aucune sauvegarde et lance l'extension de la partition sans autre sauvegarde
-> Soit je dois déplacer /home pour agrandir / : je fais une sauvegarde /home
Pour toute mes saturations SNAP, j'ai été dans le deuxieme cas de figure. Pour ca que maintenant je laisse un espace libre juste après /. Comme ça si saturation, je me retrouve dans le premier cas pour augmenter la taille : aucun déplacement de données que ce soit / ou /home. Uniquement un jeu sur la table de partition me semble-t-il.
L'avantage de séparer / de /home :
je réinstalle simplement / sur la précédente partition / (avec effacement des données), et je définis à l'installation (ou après dans fstab) ma partition home en point de montage /home (sans effacer les données).
Lors de l'installation je créer un utilisateur avec le même nom qu'un utilisateur déjà présent sur ma partition home.
Une fois l'installation terminée, je créer l'ensemble des user, sa se map tout seul avec les /home déjà présent.
Et je réinstalle les éventuels applications que ne sont pas intégré de base.
Au final une réinstallation d'OS est presque invisible pour les utilisateurs, si je n'oublis pas de reinstaller une appli spécifique.
Ca peut être un peu laid, mais ca fonctionne très bien.
Pour le partitionnement avec Gparted, je n'ai jamais perdu de donnée
(et j'en ai fait pas mal, maintenant usage perso uniquement, mais découvert tout ça en environnement pro)
Le 22/02/2024 à 23h34
La dedup mémoire ça fait des années que plus personne ne semble s'en soucier...
Le 22/02/2024 à 13h21
C'est à dire que, sauf erreur de ma part, on ne peux pas installer un OS qui n'est pas fait pour le hardware en question.
Exemple : essayez d'installer windows for arm ou macos for arm sur une machine x86-64 et ça ne marchera pas car x86-64 et arm sont 2 architectures hardware différentes.
Un autre exemple qui pourrait être vu comme un contre exemple c'est bluestacks qui virtualise un téléphone android (donc à base de processeur arm) sur windows. Il a un hyperviseur qui utilise les fonctionnalités de machine virtuelle car android est basé sur une machine virtuelle ART (anciennement DVM) et je ne sais pas comment ils ont fait mais ils arrivent à faire tourner ART sur windows.
A mettre en lien avec microsoft qui a sorti l'année dernière son sous système android pour windows c'est une machine virtuelle qui permet de faire tourner des applications android sur windows limité seulement à l'amazon appstore.
Ensuite l'article ne donne aucun inconvénient alors qu'il y en a, en augmentant le nombre de vm sur une machine on partage les ressources hardwares parmi les vm et donc chaque vm n'a plus qu'une partie des ressources à disposition.
Un exemple assez fréquent est un logiciel de calcul qui profite de tous les coeurs et ram de la machine s'il est mis sur une vm parmi plusieurs vm sur une même machine les perf seront diminué par autant de vm car la vm qui l'utilise ne pourra pas avoir accès à tous les coeurs et ram hardware car les autres vm ont besoin d'au mini 1-2 coeur et 2-4Go de ram. Alors sur un threadripper 64-128 threads ça fera probablement pas beaucoup de différence d'avoir quelques vm en + mais par contre plusieurs dizaine de vm fera une grosse diff de temps de calcul.
Pour le conteneur j'imagine que vous vouliez dire que ça permet d'exécuter plusieurs application sur un même OS je préfère dire que c'est l'équivalent d'une archive (style zip autoextractible) contenant tout ce qui est nécessaire pour faire fonctionner un logiciel prévu pour cet OS. Autre exemple, les stores d'applications (windows store, apple store, play store etc) sont des distributeurs de conteneurs.
Le 22/02/2024 à 16h44
Le 22/02/2024 à 18h53
Je peux comprendre aussi ce point de vue car clairement une vm dépends d'un hyperviseur qui gère tout. Et une vm ne tourne pas avec un autre hyperviseur donc d'un point de vue ça se défends.
Modifié le 22/02/2024 à 20h44
Le 22/02/2024 à 20h58
peux tu prendre un exemple histoire que je comprenne ?
comment se comporte une archive lancé dans docker sur windows et la même lancé sur docker sur linux par exemple ? et comment se comporte plusieurs archive lancé sur un même docker ? elles ont le même environnent d'exécution du coup ?
c'est quoi du coup la différence de lancer plusieurs app sur une même vm ? si je te suis ça reviens au même non ?
Modifié le 23/02/2024 à 14h37
Le composant inspecte les paramètres de fonctionnement qui lui sont donnés: identification de l'image à utiliser, contraintes à mettre en place un contexte d'exécution,
Le composant va essayer d'obtenir l'image soit depuis la cache locale, soit depuis un dépôt et va l'installer dans un répertoire. L'image étant composée de plusieurs couches encapsulées chacune dans une archive, elles vont être décompressées chronologiquement pour obtenir la structure finale.
En général il crée aussi des namespaces au niveau du noyeau linux de type
- pid (process id, pour fournir une vue des processus limitée au container et en renuméroter les pid dans ce contexte)
- net, pour restreindre la visibilité des interfaces réseau
- ipc, pour créer un contexte spécifique pour les communications inter-processus
- mnt, pour les points de montage
- uts contextualisation des info noyau, y compris le timesharing
- user, renumérotage du uid exécutant le container, un container peut avoir l'impression d'être root (uid 0) tout en faisant tourner ses processus sous un uid aléatoire genre 150005
Le composant va aussi créer un c(ontext)group pour y assigner le futur container ou assigner directement le container à un cgroup existant, afin de pouvoir limiter la quantité de ressources utilisables par un ou plusieurs containers
Le composant va enfin préparer et contextualiser les dépendances (réseau, points de montage, ... ), et étiqueter toutes les ressources (fichiers, ports, ...) avec les contextes SElinux correspondants si nécessaire.
Il va aussi préparer un dispositif de récupération du standard output (fichier ou pipe), car si le container ne peut écrire son stdout quelque-part, il ne pourra pas démarrer.
Une fois tout l'environnement prêt, il ne reste plus qu'à démarrer le container avec son contenu.
Sous linux, pour les containers oci, le container démarre généralement avec runc (il y a d'autres outils mais ils sont plutôt peu utilisés). Ce composant est utilisé tant par docker que containerd, podman, cri-o, ... il est la dernière marche de l'escalier avant le processus interne du container qui aura le pid 1 vu de l'intérieur du container. ce processus est démarré soit sur base des métadonnées du container (correspondant à la directive CMD dans le dockerbuild), soit sur base d'une commande spécifiée explicitement. La commande est passée à runc et runc démarre le processus ainsi containérisé.
Pour la petite histoire, quand on lance docker sous windows, docker utilise en arrière plan WSL2 pour faire tourner un environnement linux avec containerd, dockerd et runc...
A côté de ça, sous windows, il y a les "windows containers", mais je n'ai jamais pris le temps de regarder les détails de cette technologie.
Le 23/02/2024 à 14h43
ok je crois avoir compris, merci pour le détail.
Le 23/02/2024 à 15h06
En fait tout ça, ça a commencé il y a longtemps:
Après on est passé à la vitesse supérieure avec la standardisation OCI, la refonte des runtimes et les technologies d'orchestration comme Kubernetes.
Mais on est toujours dans une évolution du chroot de 79, juste en beaucoup plus pratique et sécurisé.
Le 22/02/2024 à 15h52
Par contre, je trouve étrange de donner Snap en exemple (et même "l'exemple le plus courant" 🤔).
Dans le milieu du développement, quand on parle de conteneurisation, surtout en opposition à la virtualisation, on fait beaucoup plus référence aux conteneurs de type Docker. Il n'y a qu'à consulter la page wikipedia pour s'en convaincre. Le format d'image Docker a été standardisé et est largement adopté par l'industrie du logiciel.
Après, j'avoue ne pas bien connaître l'architecture technique de Snap et de Snapcraft, son outil de création de package, et ce qui justifierait ou non l'usage du terme "conteneur"... mais même si Canonical parle lui-même d'application conteneurisée, il me semble que dans le langage "courant" pour les devs, on parle plutôt de package pour Snap plutôt que de conteneur.
Mais bon... en tant qu'utilisateur de Docker, ma vision est peut-être déformée, libre à vous de me contredire.
Le 22/02/2024 à 16h56
Modifié le 23/02/2024 à 12h34
Quid de la para-virtualisation ?
Qui se trouve entre la virtualisation et les dockers
Pour les curieux
Le 23/02/2024 à 17h41
Le 23/02/2024 à 19h46
Mais dans le principe, je pense que WSL peut se faire via UM-Linux. Je n'ai jamais cherché.
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?