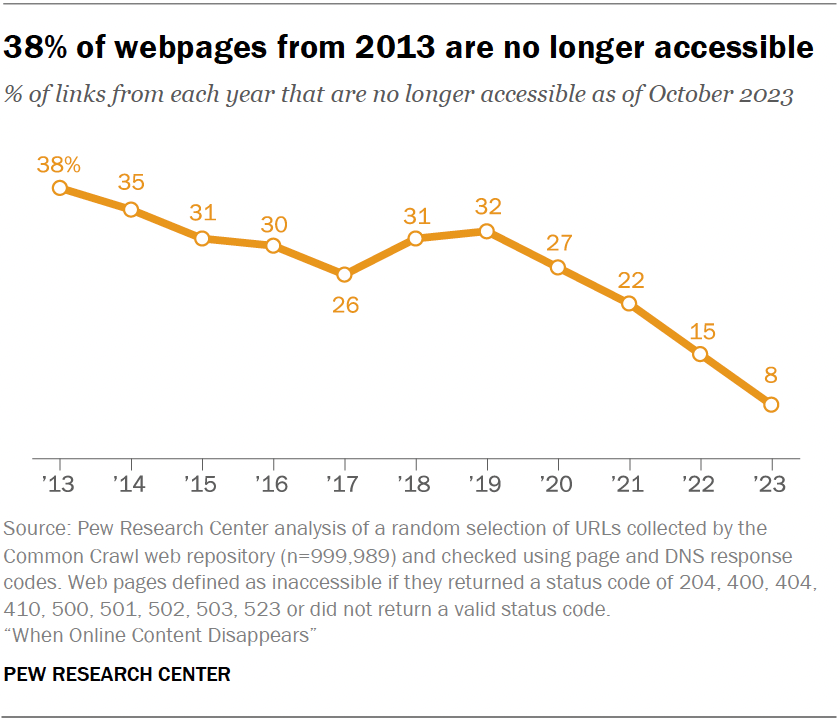
38 % des pages web de 2013 n’étaient plus accessibles fin 2023

Une étude du Pew Research Center, repérée par Meta-Media, le service de veille numérique de France Télévisions, relève que 38 % des pages web existantes en 2013 ne sont plus accessibles dix ans plus tard, contre 8 % des pages qui existaient en 2023 :
« Un quart des pages web qui ont existé à un moment donné entre 2013 et 2023 ne sont plus accessibles depuis octobre 2023. Dans la plupart des cas, cela est dû au fait qu'une page individuelle a été supprimée ou retirée d'un site web par ailleurs fonctionnel. »
Cette analyse des « liens morts » (« link rot », en anglais), reposant sur un examen des liens apparaissant sur les sites gouvernementaux et les sites d'information, ainsi que dans la section Références des pages Wikipédia au printemps 2023, révèle en outre que :
- 5 % des liens sur les sites d'actualités n'étaient plus accessibles, et 23 % des pages examinées contenaient au moins un lien brisé ;
- 11 % de toutes les références liées à Wikipédia ne sont plus accessibles, et 54 % des pages de Wikipedia contenant au moins un lien dans leur section Références pointent vers une page qui n'existe plus ;
- au moins 14 % des pages gouvernementales, et 21 % des pages web des administrations publiques, contenaient au moins un lien brisé ;
- 23 % des pages web d'actualités contiennent au moins un lien brisé, de même que 21 % des pages web de sites gouvernementaux ;
- 25 % de toutes les pages collectées de 2013 à 2023 n'étaient plus accessibles en octobre 2023 : 16 % des pages sont inaccessibles individuellement mais proviennent d'un domaine de niveau racine par ailleurs fonctionnel ; les 9 % restants sont inaccessibles parce que l'ensemble de leur domaine racine n'est plus fonctionnel.
L'examen d'un échantillon d'utilisateurs de Twitter indique par ailleurs que près d'un tweet sur cinq (18 %) n'est plus visible publiquement sur le site quelques mois seulement après avoir été publié. Dans 60 % de ces cas, le compte qui a publié le tweet à l'origine a été rendu privé, suspendu ou entièrement supprimé.
Dans les 40 % restants, le titulaire du compte a supprimé le tweet, mais le compte lui-même existe toujours :
- 1 % des tweets sont supprimés en moins d'une heure
- 3 % en l'espace d'un jour
- 10 % en l'espace d'une semaine
- 15 % en l'espace d'un mois

Commentaires (28)
Abonnez-vous pour prendre part au débat
Déjà abonné ? Se connecter
Cet article est en accès libre, mais il est le fruit du travail d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles
Profitez d’un média expert et unique
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 10/06/2024 à 11h32
Je sais que c'est devenu autre chose (OpenClassroom).
Mais de voir que l'ancienne URL ne fonctionne plus m'a fait un petit pincement au coeur.
Le 10/06/2024 à 18h34
Le 10/06/2024 à 20h25
Merci pour ton message
Le 10/06/2024 à 12h02
Le 10/06/2024 à 12h28
Le 10/06/2024 à 14h34
https://www.peugeot.fr/toto
Le 10/06/2024 à 14h00
Après sont viendus les TGP ...
Encore heureux, les européens découvraient l'euro, le paiement par carte et imaginaient que 1€ = 1 FRF :)) Quelle période bénite.
Le 10/06/2024 à 14h02
Le 10/06/2024 à 14h16
il est même surprenant qu'autant de pages webs aient conservées leurs URLs.
Parmi les causes:
- les URLs auto-générées qui changent quand le contenu/layout/engine du site change.
- les rachats/rebranding qui provoquent un changement des noms de domaine.
- la rumeur qui consiste a supprimer/recréer les pages pour "optimiser" le SEO.
Next.ink coche les deux premières cases.
Modifié le 10/06/2024 à 14h51
exemple:
https://nextinpact.com/36280/73198-windows-8-pro-media-center-pack-pour-999-euros/
par contre l'ere de pcinpact est enterré :
Le 10/06/2024 à 15h05
c'est ça l'INpactitude
Le 11/06/2024 à 00h04
la bibliothèque d'alexandrie doit s'en retourner dans ses archives..
Le 11/06/2024 à 12h08
Les pages web ont dès le début eu vocation a maintenir des connaissances dans le temps et permettre leur partage.
Les URLs et leur structure identifient de manière uniques des ressources, donc vocation à rester et être facilement joignables.
Le code HTTP 301 et 302 vont également dans ce sens pour garantir qu'une ressource déplacées restent joignables.
Les causes que tu cites sont toutes à l'encontre de l'esprit du WWW, mais l'esprit de ce dernier est bien de perdurer.
Le 11/06/2024 à 18h03
Si le web était conçu dés le départ pour perdurer, les structures/protocoles auraient gérées l'aspect temporel de l'information (version, date...).
Le 11/06/2024 à 19h34
Je n'ai pas dit que unique = perdurer, j'ai dit que au vue de sa conception, avec des ID uniques, c'est fait pour durer. Comme git a des ID unique de commit, et littéralement fait pour durer. Pas comme ton argumentation
Le 11/06/2024 à 20h24
La meilleure preuve que les contenus du web ne sont pas conçus pour durer, c'est le titre de cette news.
Un autre indice: la création du projet 'Internet Archive'.
Le 12/06/2024 à 22h42
Ce que ça prouve surtout c'est que la gestion des causes que tu cites n'est pas bien faite. Un lien brisé n'est pas forcément un contenu qui n'existe plus, mais un contenu qui a possiblement bougé et dont le propriétaire ou gérant n'a pas bien fait la liaison des anciennes adresses.
Un document architecture.pdf à l'adresse unsitesuper.fr/archi/docs/architecture.pdf si le site change de structure ou bien de nom ou les deux, si l'ancienne adresse ne fait pas une redirection (native au protocole HTTP) vers la nouvelle supersite.eu/documents/archi/architecture.pdf ça ne veut pas dire que tu ne retrouves pas le fichier en cherchant sur le site en question, ou sur un moteur de recherche avec ça :
site:supersite.eu filetype:pdf architecture.Bref, tout le contenu du web ne durera pas de toute façon car chacun a le droit de supprimer son propre contenu, mais la structure et les protocoles sont fait pour permettre de faire durer le contenu qui doit l'être.
Ce site en est la preuve, il n'a pas besoin d'Internet Archive, tout comme Wikipedia.
Le 13/06/2024 à 10h45
Cette information ne garantit ni la disponibilité, ni l'intégrité de la ressource.
perte de disponibilité: la news dit que dans 38% des cas, l'URL de 2013 ne permet plus d'accéder à d'accéder à la ressource en 2023.
perte d'intégrité: le serveur peut retourner une ressource différente (=un contenu différent) à chaque appel. Soit parce que la ressource a été modifiée par son auteur (ex: un billet de blog, une news, ...). Soit parce que la ressource est générée dynamiquement (ex: contenu personnalisé).
L'URL c'est l'analogue d'un chemin de fichier. Connaitre un chemin de fichier ca ne garantit pas que le fichier sout dispo et inchangé.
Le 16/06/2024 à 21h19
Oui, l'URL en tant que telle ne garantit pas la disponibilité. Mais : et alors ?
Le web est fait pour que la disponibilité puisse être garantie, cf. les redirections évoquées plus haut, couplés avec l'URL qui est un chemin facile à sauvegarder pour retrouver un document dans le temps.
Donc dire que le contenu web et les URLs ne sont pas faites pour durer c'est n'importe quoi. C'est fait pour le permettre, mais comme tout outil / technologie, cela dépendra de l'utilisation qui en est faite.
Le 10/06/2024 à 14h59
Le 10/06/2024 à 15h36
Le 10/06/2024 à 21h26
Déjà que Google favorise le contenu récent de façon de plus en plus agressive, mais en plus les anciennes pages qui meurent, c'est devenu mission impossible si c'est pas une information "majeure" qui a été relayée moultes fois.
Le 11/06/2024 à 00h05
Le 11/06/2024 à 00h05
il faut admettre que plus de la moitié des références (journalistiques et autres) donnaient lieu à des 404
là j'ai compris que j'aurai plus jamais confiance en autre source pérenne qu'archive.org et autres miroirs de mon cru..
Le 11/06/2024 à 00h14
à chaque vidéo que je juge intéressante et trop importante pour qu'elle disparaisse de yt, j'en fais une copie personnelle, en locale, que j'héberge également sur des espaces nextcloud distants.
également, le nombre de sites web de particuleirs, et emails rattachés, qui disparaissent est troublant :
chaque année de nombreux geeks, passionnés, et ingés, oublient de renouveller leur NDD perso, et du coup leur site tombe dans les limbes et pire, emportant avec eux.... la précieuse adresse email, qui rend leurs coordonnées caduques.
Le 11/06/2024 à 02h41
Le 11/06/2024 à 07h52
http://chez.com/
Modifié le 11/06/2024 à 17h21