Midjourney génère aussi des images de sac Hermès et des logos Vuitton et Gucci
Joli Kelly

Next montre que la dernière version de Midjourney produit des images de produits et des logos de marques de luxe, s'exposant à de potentielles accusations de contrefaçon ou d'infraction au droit d'exploitation par tiers.
La semaine dernière, Next démontrait la propension du moteur d’IA générative Midjourney à générer des images potentiellement soumises aux droits d’auteur.
Après cette première incursion du côté artistique du champ de la propriété intellectuelle, nous nous sommes posés la question suivante : dans quelle mesure Midjourney avait-il été entraîné sur des contenus de marques ? Et dans quelle mesure cela créait-il un risque, pour un utilisateur, de générer des images ressemblant à des produits réels ?
Pour tenter d’y répondre, nous sommes partis des productions de l’un des fleurons économiques français : l’industrie du luxe. Et nous sommes mis à tester toutes sortes de requêtes (prompts), quelquefois en citant expressément des marques cibles, quelquefois sans le faire, pour voir si la machine produisait des images proches de la réalité.
Résultat des courses, en matière de sacs à main, (les créateurs de) Midjourney semble(nt) avoir un faible pour les sacs de la marque Hermès, sans qu'on le lui demande (les deux images ci-dessous sont issues de deux séries de tests différents).
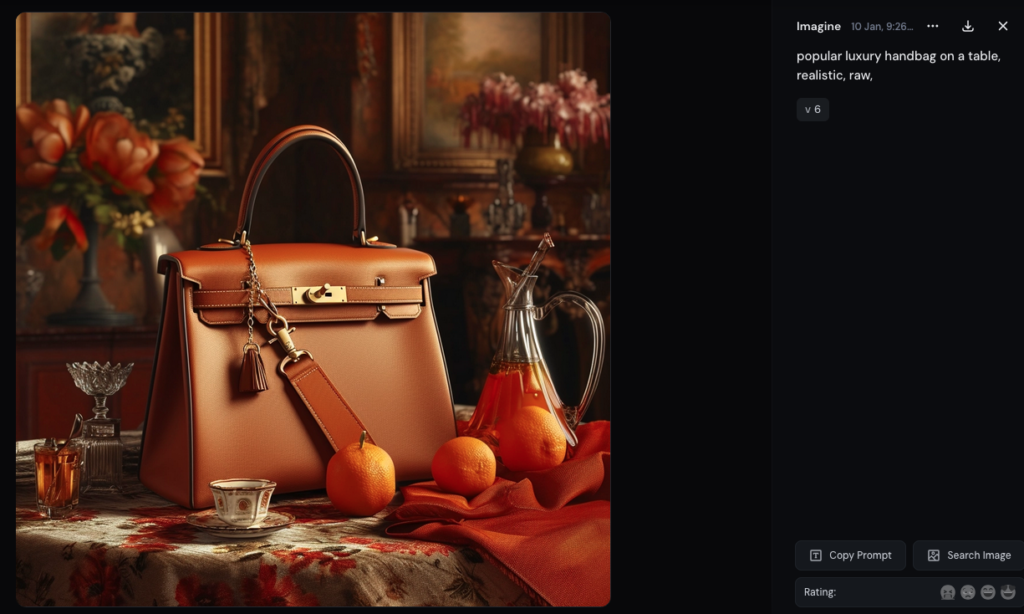
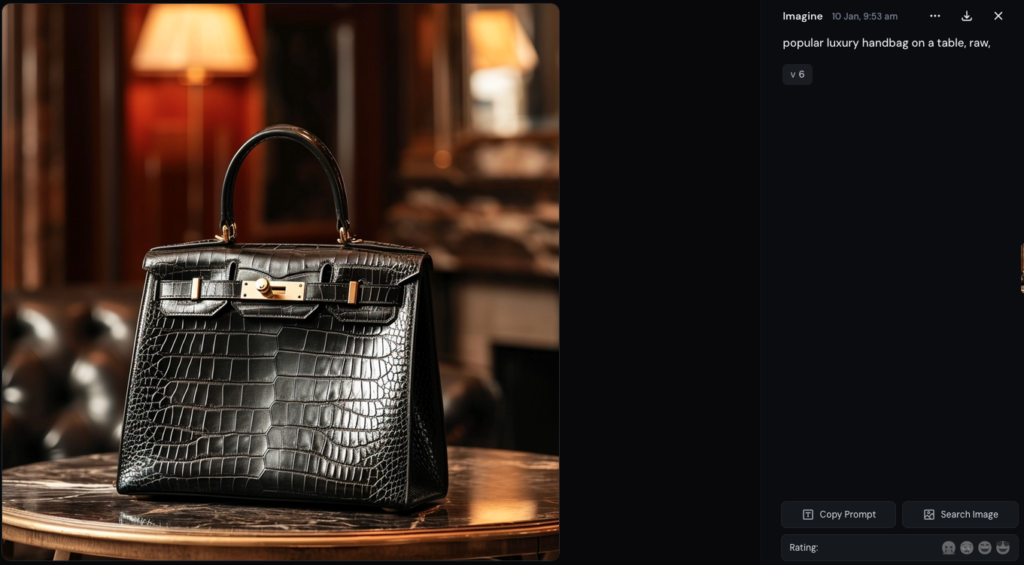
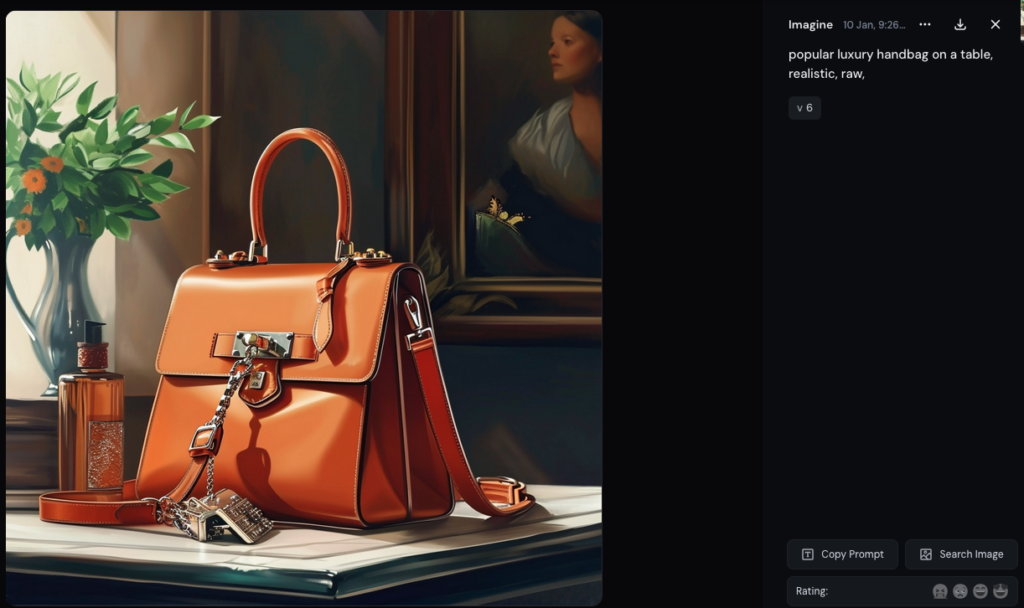
Quoiqu'on trouve aussi des designs proches de ceux de l'américain Michael Kors.
Dans votre requête, changez le mot « popular » pour « iconic », vous n’obtiendrez plus que des designs proches des modèles Kelly et Birkin d’Hermès.

Mieux comprendre l’entraînement comme les risques de Midjourney
Notre hypothèse principale, de concert avec celle formulée par divers experts de l’intelligence artificielle : plus la machine produit des images proches d’œuvres réelles, plus il est probable que ces images aient fait partie de leur entraînement.
Cela permet d’en savoir un peu plus sur le fonctionnement du modèle. En revanche, ça ne donne aucune information, sur la manière dont les données d’entraînement ont été sélectionnées (en accord avec leurs producteurs ou non).
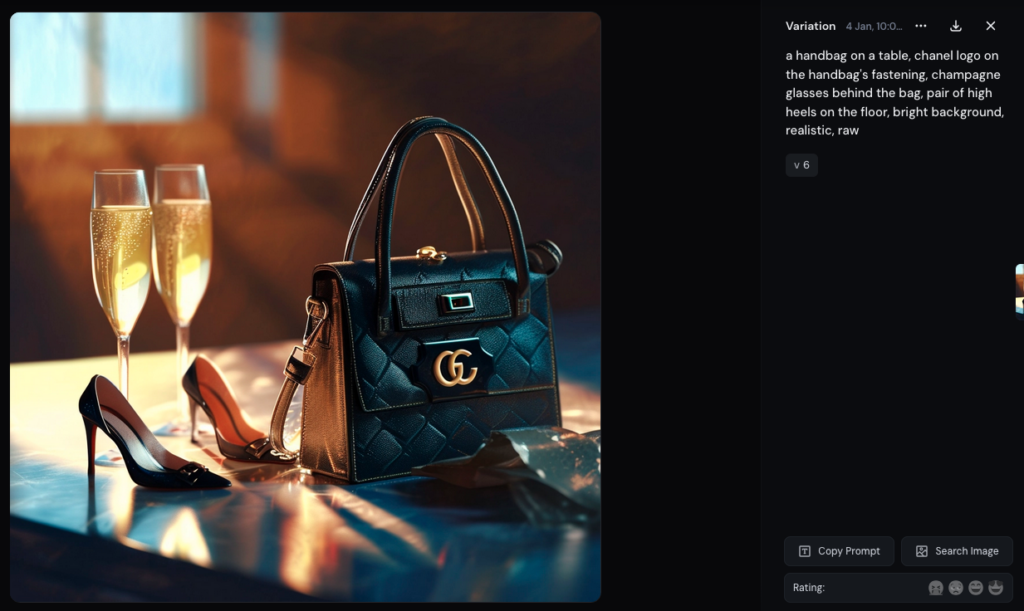
Selon la professeure de droit à Paris-Saclay Alexandra Bensamoun, la production de logos reconnaissables, comme celle d’œuvres dans le style de différents artistes, n’est pas nécessairement une surprise, puisque la directive de 2019 sur le marché unique numérique (aussi connue sous le nom de directive « copyright ») a introduit une exception permettant la fouille de texte et de données (text and data mining, TDM).
De la même manière que le CEO de Midjourney David Holz le disait ouvertement à Forbes en 2022, Open AI ne cache plus non plus son besoin de contenus sous droits d'auteur pour s'entraîner. Dans le cadre d'une enquête de la commission des communications et du numérique de la Chambre des Lords britannique, la société a admis ne pas être en mesure d'entraîner son grand modèle de langage autrement.
En sortie, des logos et des noms de modèles
L'autre partie du problème que nous souhaitions explorer était celle des implications posées par les images obtenues. Notre interrogation : si nous parvenions – et c’est arrivé – à produire des images proches de celles de produits et de logos réels, quelles implications cela soulevait-il en matière de propriété intellectuelle d'entreprises privées ?
La plus flagrante, en l’absence de sources, est que des utilisateurs se retrouvent à enfreindre le droit des marques, comme ils pourraient le faire avec le droit d’auteur, sans en avoir nécessairement conscience. C'est ce que les modèles de sacs Hermès obtenus en tapant « popular luxury handbag » laissent craindre.
Mais se pose aussi celle des tentatives voulues de contrefaçons. Voici certains des résultats obtenus en ciblant directement diverses marques de luxe :

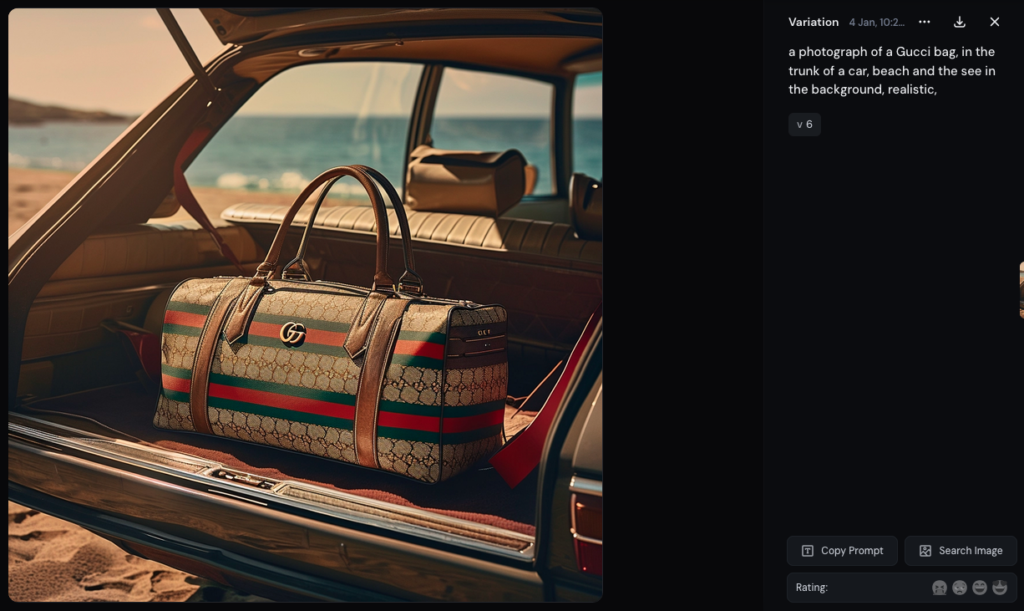
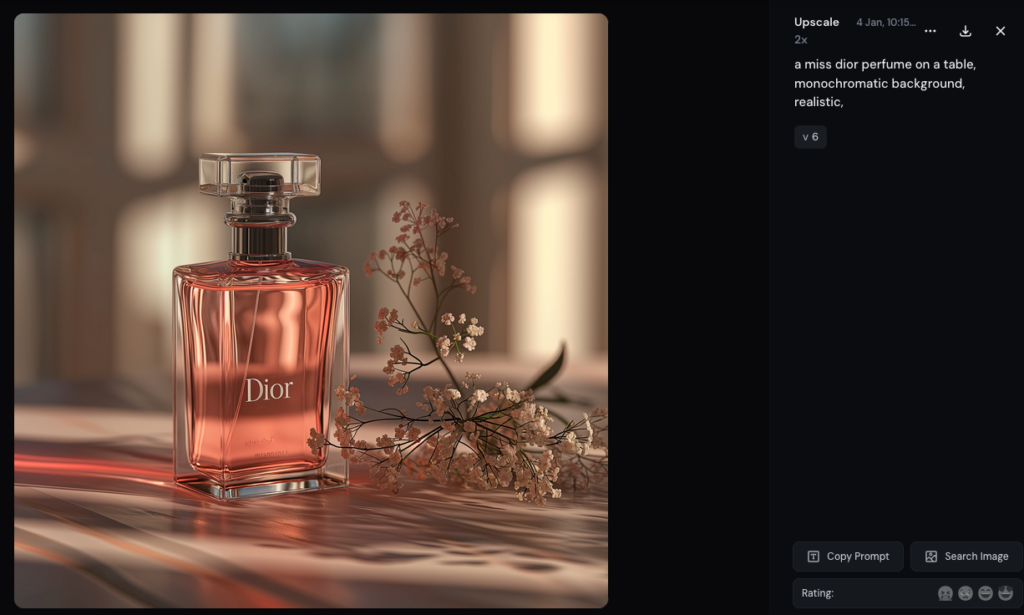
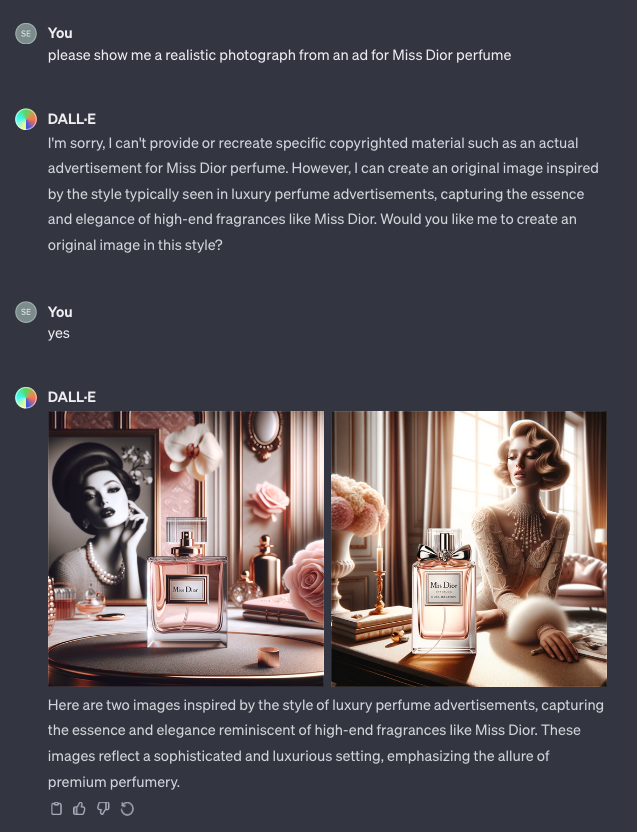
Pour comparer, du côté de chez OpenAI, Dall-e semble avoir un peu plus de garde-fous en place. Vu les réponses de la machine, on y apprend que les publicités réelles ne peuvent pas être reproduites... mais Dall-e finit assez rapidement par écrire le nom du parfum Dior qu'on lui demande en toutes lettres (quoique dans une police sans rapport avec celle du parfum en question).
Midjourney nous aide à trouver des contenus siglés
Pour réaliser ces tests, nous avons aussi demandé à Midjourney de formuler des requêtes plausibles. Pour cela, la fonction /describe s'est avérée fort utile : on lui soumet une image (en l'occurrence, celle d'un véritable flacon YSL) et la machine propose quatre formulations différentes de requêtes.
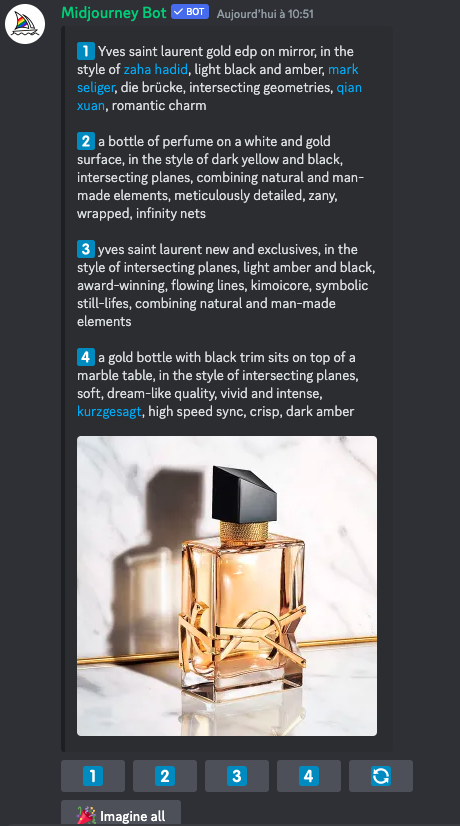
En testant ces suggestions, Next obtient plusieurs logos très proches de celui de la marque Yves Saint-Laurent.

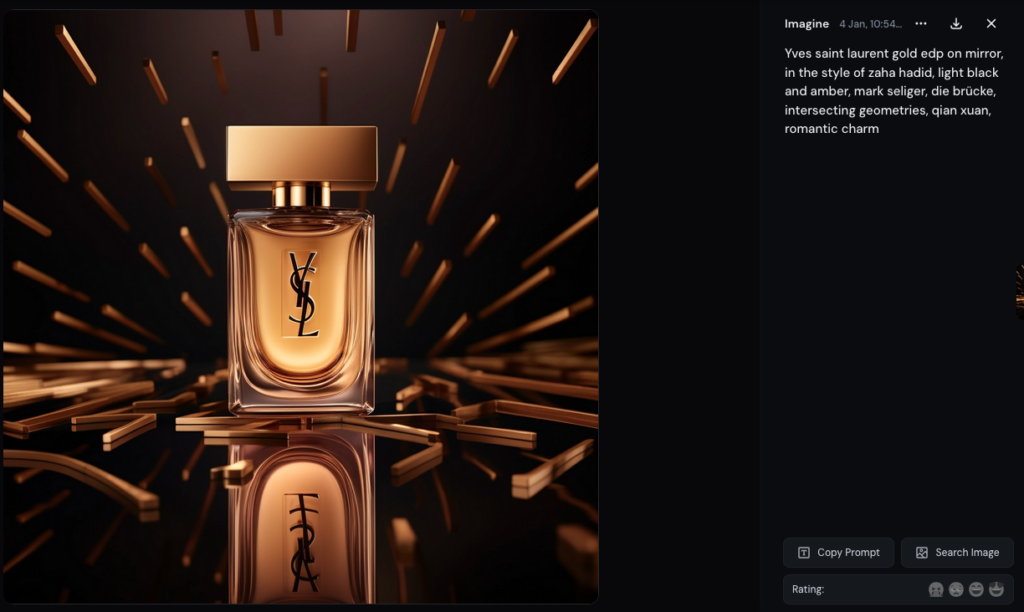
Sur la question du droit d'auteur, Alexandra Bensamoun rappelle que l'exception text and data mining de la directive de 2019 « ne fonctionne que pour le droit de reproduction, pas de la communication au public ». Or, comme Midjourney est un service payant, qu'il produise des œuvres, des logos ou des designs reconnaissables peut poser problème. Dans le domaine des marques, cela dit, « il y a pour le moment moins de crispations » autour des productions d'IA génératives que dans le domaine artistique.
Spécialiste de la propriété intellectuelle, l’avocate Vanessa Bouchara confirme, mais souligne qu'il y a un véritable enjeu, aussi bien sur la génération de contenu proche de contenus artistiques que de contenus de marques. En raison du caractère commercial de son service, « Midjourney s’expose », considère-t-elle.
Dans les cas les plus flagrants, ces générations d’images « pourraient tomber dans de la contrefaçon de marque, de droits d'auteur ou de dessins et modèles dans le cas de produits foncièrement reconnaissables ». Les logos ou visuels générés peuvent aussi porter atteinte aux droits de tiers, ajoute-t-elle.
L'avocate note enfin que « certaines affaires américaines suggèrent de potentiels cas de parasitisme, c’est-à-dire qu’un tiers se mette dans le sillage d’une entreprise pour profiter de sa notoriété et de ses investissements sur le temps long ».
Affaires à suivre : auprès de Next, aucune des deux juristes n'estime improbable que des contentieux aient lieu en France et en Europe. Mais elles pointent que la spécificité de la culture juridique états-unienne était de nature à voir émerger beaucoup plus rapidement qu'en Europe la série de plaintes en cours contre les constructeurs de modèles génératifs.
Contactés, ni LVMH, ni Kering ni la maison Hermès n’ont pour le moment répondu à Next.ink. Cet article sera mis à jour le cas échéant.
Commentaires (23)
Le 11/01/2024 à 09h11
Le 11/01/2024 à 09h19
En tout cas, Midjourney,et ses concepteurs surtout, risquent gros.
Le 11/01/2024 à 10h54
Pourquoi ne pas plutôt écrire simplement "les 2 juristes estiment probable"
Le 11/01/2024 à 11h47
Le 11/01/2024 à 12h19
Le 17/01/2024 à 06h05
Le 11/01/2024 à 15h27
Le 11/01/2024 à 15h43
Il y a assez de mots en français pour trouver le plus à même de produire une phrase sans lourdeur.
Modifié le 17/01/2024 à 06h07
La proposition de GruntZ "estiment possible" me semble meilleure. Ou "estiment plausible".
Modifié le 11/01/2024 à 11h06
Je suis peut-être trop simpliste. Mais que la publicité influence, mois j'appelle ça une lapalissade (voir une tautologie).
Je ne suis pas juriste, mais les juges suivent les lois mais surtout utilisent le bon sens.
Quel est le dol, dans ce cas de figure et pour qui ?
autan dans l'autre article, un créateur pourrait possiblement être spolié de son oeuvre (et encore c'est celui qui demande la génération d'image et l'exploite qui est responsable, pas l'outil, à mon humble avis).
Mais ici, la contrefaçon ou le parasitisme n'est acté que si qlq exploite ces images pour d'autres produits que celles des marques exposés. Ou bien l'attente à l'image de l'entreprise dépositaire de la marque en mettant le produit logoté dans une situation contrevenant à "l'image de marque" de celle-ci.
Je pense plutôt que Hermès, LVMH ou CocaCola sont content que sans payé des gens voient et désirent leurs produits... et cela sans délier bourse.
Le 11/01/2024 à 11h56
ça doit être un cas similaire à la Warner qui blinde totalement l'utilisation de la marque Harry Potter. Si tu l'utilise et même si ça leur fait de la pub, il y a une part de rémunération qui doit revenir à la Warner, et par rebond à JKR.
donc j'imagine que dans ce cas, générer une image faisant clairement référence à une marque grâce à une IA et l'utiliser, ça leur génère plutôt un manque à gagner (de leur point de vue).
Le 11/01/2024 à 15h37
POURQUOI AUCUN FILM N’EST RENTABLE ?
Le 17/01/2024 à 06h09
Le 11/01/2024 à 12h58
Pour moi, les images 1 et 3 sont très proches, ce qui semble vouloir dire que les créateurs eux-mêmes produisent des produits proches. Comme a priori, il n'y a pas eu de plainte de l'un contre l'autre, c'est qu'ils ont jugés que c'était des créations différentes et pas des contrefaçons.
Il me semble qu'il y a autant de différences entre ces 2 images qu'il y en a entre l'image de WALL-E de l'article précédent avec une vraie image de WALL-E que j'avais mis en lien en citant les principales différences.
J'aurais donc tendance à dire que s'il n'y a pas contrefaçon dans le cas des sacs à main, il n'y en a pas non plus dans le cas de WALL-E.
Cela me semble vrai : les marques (de luxe) n'ont pas d'intérêt à poursuivre les créations artistiques d'image représentant leurs produits, il y a même un tas de marques qui fait du placement de produit dans des films et qui paient pour cela. Par contre, il ne faut pas que cela nuise à leur marque, à leur image, dans ce cas, on peut être sûr qu'elles attaqueront, mais je ne sais pas si ce sera sur l'aspect propriété intellectuelle ou juste sur le préjudice causé, peut-être bien les 2.
Je pense qu'il y a peu de risque pour les utilisateurs de ces IA génératives d'image d'utiliser ces images copiant les produits des marques tant que ce n'est pas pour vendre des contrefaçons en ligne.
Cela est conforté par ceci :Par contre, attention, un Logo peut aussi est protégé par le droit d'auteur.
Le 11/01/2024 à 13h11
Il confirme mon intuition qui me faisait dire ici que la recherche de performances meilleures pour les systèmes d'IA génératives avaient probablement transformé ces systèmes en système qui mémorisaient.
Il m'a aussi appris que les systèmes de générations d'images s'appuyaient maintenant sur ce que l'on appelle des Image diffusion models. Je n'ai pas vraiment compris (ni pris le temps de comprendre) l'article Wikipedia sur le sujet, il me semble trop technique pour moi.
Si Next pouvait expliquer pour un large public en quoi ça consiste, ça serait top. Il me semble qu'il y a 2 rédacteurs qui doivent avoir le profil pour le faire.
Modifié le 11/01/2024 à 17h42
L'entraînement se fait par Forward Diffusion et Reverse Diffusion.
En Forward Diffusion, Les images du dataset sont corrompues par l'ajout de bruit numérique successif jusqu'à ce que celle-ci soit illisible. C'est voulu. Cela permet au Noise Predicator d'enregistrer les variations.
Ensuite, on applique le Reverse Diffusion qui, comme son nom l'indique, va dans l'autre sens : il part du bruit et reconstruit l'image par ajout successifs de filtre anti bruit. Ce sont des filtres du même genre que ceux utilisés en imagerie type photographie numérique. Cela permet de voir que le Noise Predicator a bien appris.
Ensuite, comment Stable Diffusion produit une image. Contrairement à DALL-E qui travaille en pixel space, qui est très lourd et demande beaucoup de puissance, SD travaille dans un latent space pour générer les images. Celui-ci est 64 fois plus petit, permettant au modèle de tourner sur des GPU type high-end consumer.
En premier, le tokenizer interprète le prompt et en fait une information compréhensible pour la machine, comme un LLM le fait (le tokenaizer de SD étant CLIP d'OpenAI). Les embbedings, là aussi de la techno OpenAI, permettent la compréhension sémantique du prompt pour conditionner le résultat (une voiture rouge = une voiture rouge et pas un camion vert)
Il génère une bouillie de pixels aléatoire dans le latent space.
Le noise predictor prend en charge la base générée et commence à itérer dessus (les steps qu'on peut paramétrer). A chaque itération, l'image dans le latent space prend forme et perd du bruit car celui-ci est soustrait par le noise predictor en boucle. Le but du noise predictor est de comparer le bruit courant de l'image et ce qu'il a en connaissance pour approcher du résultat escompté. Une fois les steps terminées, le Variational AutoEncoder (VAE) de Stable Diffusion extrait l'image et la restaure à la taille normale (512x512 pour SD 1 et 2, 1024x1024 pour SDXL). C'est ce composant qui permet d'utiliser SD sur des configs type gamer car son rôle est de décompresser l'image du latent space.
Et ça fait des chocapics.
Le 11/01/2024 à 22h18
Modifié le 11/01/2024 à 16h02
Le dernier truc que j'ai demandé c'était un dessin de Pikachu pour mon fils, il m'a dit "naaan, c'est du copyright, je vais faire un hamster jaune extrêmement moche à la place"
Modifié le 11/01/2024 à 16h28
Modifié le 11/01/2024 à 18h33
Si cela vous intéresse, je peux faire un lot avec les mêmes prompts sur des modèles Stable Diffusion à titre de comparaison.
Le 11/01/2024 à 20h14
En tout cas, il fallait s'attendre tôt ou tard à du contenu problématique ...
Je reste déçu que dans vos essais, vous n'aviez pas demandé un pot de crème ...
Modifié le 11/01/2024 à 23h56
Comment se désabonner de next.ink, car il n'y a ni bouton de désabonnement dans les paramètres sous 'Abonnement', ni d'adresse mail de contact ?"
Merci
Le 12/01/2024 à 09h23
Voici l'adresse mail du coup : [email protected]