Granite : IBM lance son pavé dans la mare des modèles de langage pour la génération de code

IBM vient de publier une famille de huit nouveaux grands modèles de langage nommée Granite. Celle-ci a la particularité de se concentrer sur les tâches liées au code : générer du code, corriger des bugs, expliquer et documenter le code.
Les huit modèles (de 3 à 34 milliards de paramètres) sont distribués sous licence Apache 2.0. Dans leur article expliquant la création de ces grands modèles de langage, les chercheurs d'IBM indiquent qu'ils ont été entraînés sur les jeux de données de code Github Code Clean et StarCoderdata mais aussi « des dépôts de code publics sur GitHub et des problèmes signalés [ndt : issues en anglais] supplémentaires » dont le jeu de données n'est pas clairement connu.
Dans les tests de comparaison qu'ils ont effectués, les chercheurs montrent que le modèle Granite-8B devance ses concurrents « ouverts » :
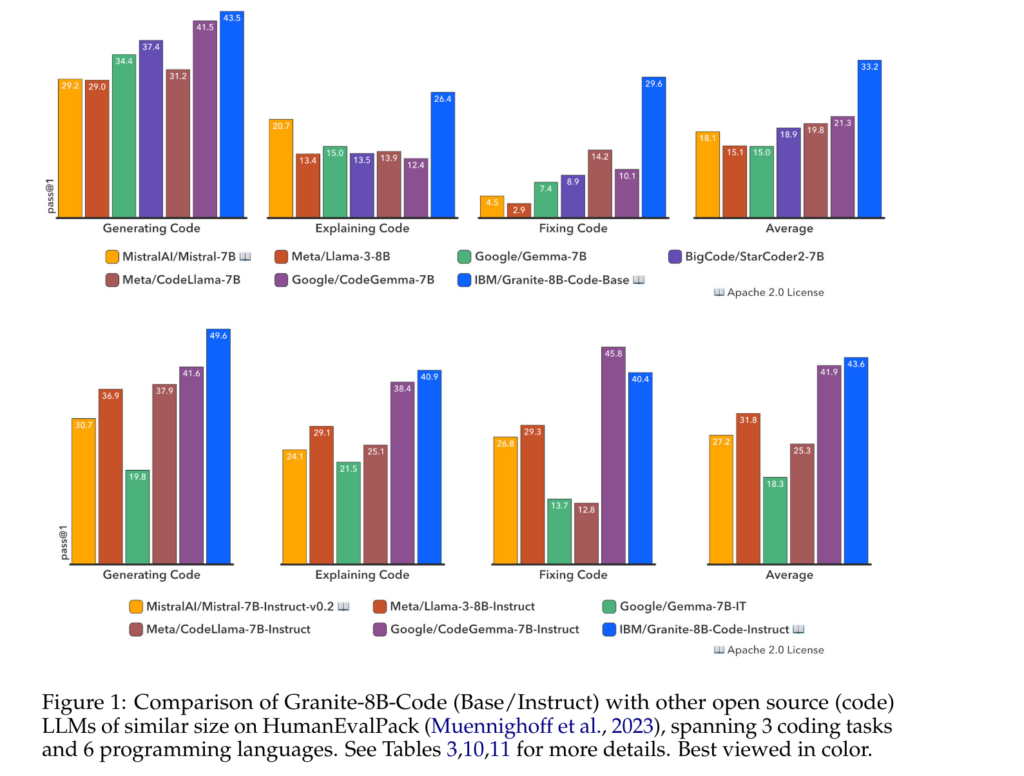
À la fin de l'article sont listés les langages sur lesquels la famille Granite peut être utilisée :
ABAP, Ada, Agda, Alloy, ANTLR, AppleScript, Arduino, ASP, Assembly, Augeas, Awk, Batchfile, Bison, Bluespec, C, C-sharp, C++, Clojure, CMake, COBOL, CoffeeScript, Common-Lisp, CSS, Cucumber, Cuda, Cython, Dart, Dockerfile, Eagle, Elixir, Elm, Emacs-Lisp, Erlang, F-sharp, FORTRAN, GLSL, GO, Gradle, GraphQL, Groovy, Haskell, Haxe, HCL, HTML, Idris, Isabelle, Java, Java-Server-Pages, JavaScript, JSON, JSON5, JSONiq, JSONLD, JSX, Julia, Jupyter, Kotlin, Lean, Literate-Agda, Literate-CoffeeScript, Literate-Haskell, Lua, Makefile, Maple, Markdown, Mathematica, Matlab, Objective-C++, OCaml, OpenCL, Pascal, Perl, PHP, PowerShell, Prolog, Protocol-Buffer, Python, Python-traceback, R, Racket, RDoc, Restructuredtext, RHTML, RMarkdown, Ruby, Rust, SAS, Scala, Scheme, Shell, Smalltalk, Solidity, SPARQL, SQL, Stan, Standard-ML, Stata, Swift, SystemVerilog, Tcl, Tcsh, Tex, Thrift, Twig, TypeScript, Verilog, VHDL, Visual-Basic, Vue, Web-Ontology-Language, WebAssembly, XML, XSLT, Yacc, YAML, Zig.

Commentaires (24)
Vous devez être abonné pour pouvoir commenter.
Déjà abonné ? Se connecter
Abonnez-vousLe 07/05/2024 à 16h18
Le 07/05/2024 à 18h30
Le 07/05/2024 à 20h50
Le 08/05/2024 à 17h57
Le 07/05/2024 à 18h47
S'il y a bien un truc que je ne veux pas auto-héberger pour l'instant c'est un service d'IA. C'est onéreux et ca change tout le temps. Le temps d'écrire ce message il y aura déjà 3 nouveaux modèles annoncés et 5 études qui démontrent qu'il ne faut pas les utiliser.
Le 07/05/2024 à 20h50
Ah ben du coup j'utilise pas d'iA/
Le 07/05/2024 à 22h54
Je trouve également bien qu'on spécialise des modèles pour des tâches précises. Parce que le nouveau modèle de Google et ses 10Mo d'entrées (et ses éventuelles 1000 milliards de paramètres), c'est pas très sobriété non plus.
Le 08/05/2024 à 09h39
Mais que le reste de la boîte est sous ...
MS Office 365
Le 08/05/2024 à 13h03
Le 08/05/2024 à 08h57
Le 08/05/2024 à 12h50
Perso je ne vois pas ce qu'il y a de confidentiel à demander de la génération de code javascript ou C# pour faire un client socket ou un parseur JSON.
Entre taper ta demande dans google/stackoverflow ou dans un prompt d'IA, je ne vois pas trop la différence en terme de confidentialité.
Le 08/05/2024 à 19h53
Le 08/05/2024 à 20h21
Donc à minima tout ce que tu vas demander à l'ia ne restera pas chez toi.
Et si t'es parano selon ce que peut faire l'ia tu peux te dire que presque tout peut partir là bas et enrichir l'ia.
Le 09/05/2024 à 11h23
Cf les soucis relatif aux licenses open-source.
Aussi un risque de faire fuiter des règles de gestion métier implémentées dedans.
Dans le cas de l'usage des services d'IA générative hébergés, il est extrêmement important de regarder le traitement des données. Par exemple chez Mistral, utiliser leur Chat en ligne revient à leur donner les prompts et le résultat. L'opt-out n'étant possible qu'en version payante. Même auparavant, des linters en ligne pouvaient stocker et conserver les données. OpenAI pareil, il est clairement indiqué dans la FAQ que les utilisations de leur service sont analysées.
C'est même de plus en plus insidieux avec les solutions du marché qui intègrent de l'IA désormais. Il faut éplucher les politiques d'utilisation des données pour s'assurer qu'il n'y a pas risque de fuite. L'ironie du SaaS en gros.
Enfin, le coup des clés privées, tokens, etc en dur dans le code... Perso j'ai arrêté de compter les alertes qui pleuvaient. On peut dire ce qu'on veut, que les devs n'ont qu'à faire attention, etc, si des détecteurs de secrets dans le code ont été créés, c'est pas pour rien. Les mauvaises pratiques, ça va vite.
Le 08/05/2024 à 09h06
Le 08/05/2024 à 09h33
Le 08/05/2024 à 12h54
Ça ajoute au ridicule.
Modifié le 08/05/2024 à 16h23
Le 08/05/2024 à 18h39
Le 08/05/2024 à 19h54
Le 09/05/2024 à 02h43
1) on rêve qu'une technologie permette de réduire la masse salariale.
2) un manager fait un gros contrat avec un fournisseur de ladite technologie et proclame que le problème est résolu
3) on vire massivement selon les estimations faites
4) les employés survivants doivent absorber la charge de travaille de leurs collègues disparus
5) et ils doivent aussi travailler sur les projets d'adaptation/migration en extrême urgence (mais sans allègement du point 4)
6) les séniors se barrent car ils ne voient plus où ça mène et tant qu'à faire c'est le moment de bouger
7) il ne reste que des juniors sous très haute pression qui doivent en plus intégrer les outils choisis
8) profit ?!?
(perso, pour l'avoir vécu plusieurs fois, je me dis qu'il y a une sorte d'échec éducatif absolument terrible dans les écoles de management... 25 ans à voir ce cycle dévastateur se répéter)
Le 12/05/2024 à 18h24
Le 12/05/2024 à 19h30
Modifié le 08/05/2024 à 20h12
Et le mieux c'est que cet argumentaire n'a pas besoin d'être vrai !
Il suffit de dire à l'entreprise que tout ses concurrents vont utiliser l'IA et que s'il ne le fait pas il sera le seul à être défavorisé.