Bluesky est-il décentralisé ?
Décentralisation quantique

Bluesky et son protocole AT sont souvent décrits comme décentralisés, à la manière de Mastodon. Mais est-ce bien le cas ? La question fait débat.
Bluesky est actuellement sous les feux des projecteurs. L’effet boule de neige semble enclenché et on peut voir un nombre croissant de comptes importants partir de X pour des cieux plus cléments. Chez Science, on lit la même chose au sujet de la communauté scientifique.
Bluesky attire pour plusieurs raisons, en plus du critère classique de nouvel horizon. D’une part, des fonctions de blocage et de modération nettes et précises. D’autre part, l’affichage chronologique par défaut des publications, loin des algorithmes poussant à l’engagement. Et que cet engagement se fasse sur les impressions de publicités ou sur les réactions de comptes Premium n’y change rien.
Que sait-on de Bluesky ? C’était initialement un projet incubé chez Twitter par Jack Dorsey en personne. Le fondateur de Twitter souhaitait tester l’idée d’un protocole open source pour un réseau de micro-blogging. Cette idée a accouché du protocole AT, qui est effectivement open source, sous double licence Apache 2.0 et MIT. Jack Dorsey, lui, a quitté l'entreprise en mai.
Ce protocole a été pensé initialement pour permettre un fonctionnement décentralisé et fédéré, comme le propose Mastodon. Mais peut-on dire que Bluesky est réellement décentralisé ? La réponse n'est pas si simple.
Un serveur, un relai et une vue entrent dans un bar
Lorsque l’on parle de Bluesky, on évoque le réseau dans son intégralité. Mais ce réseau se compose en fait de trois parties, comme l’entreprise l’explique dans sa documentation : les serveurs, les relais et les vues d’applications.
Les serveurs constituent les réservoirs de données personnelles. Un utilisateur peut y stocker toutes ses informations, dont ses publications et tout ce qui sert à l’identifier (nom de connexion, mots de passe, clés cryptographiques) ou encore la liste des personnes suivies. Les PDS (Personal Data Server) gèrent également la mise en relation avec les services en fonction des requêtes. Il peut y avoir autant de PDS que l’on souhaite et tout le monde peut en créer un. En théorie.
Sur les relais en revanche, tout change. Leur mission est de parcourir tous les PDS, d’agréger et indexer le contenu pour en produire un énorme flux unique de données en streaming, souvent appelé firehose dans le jargon. Ce flux est ensuite mis à disposition de tout l’écosystème atproto (protocole AT). Les relais agissent comme un moteur de recherche.
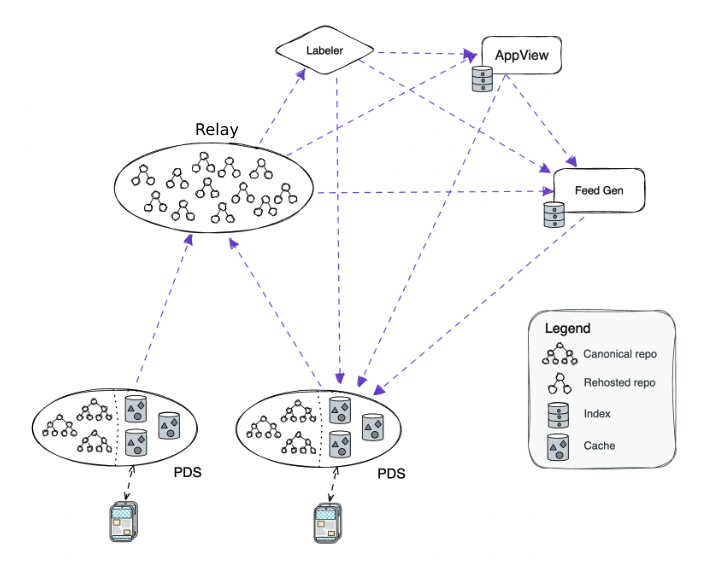
Quant aux vues d’application (App View), elles constituent la face visible de l’iceberg. Une App View est ce qui permet d’afficher des informations exploitables à partir du flux agrégé. Elle réalise un assemblage à partir des critères définis aussi bien par la requête que les différents paramètres. Par exemple, afficher le flux personnel ou les résultats d’une recherche, tout en masquant certains résultats, par exemple provenant des personnes bloquées.
Que peut-on faire soi-même ?
Certaines actions peuvent être entreprises par les utilisateurs, du moins sur le papier. Monter un serveur personnel est le plus simple, Bluesky fournissant de nombreuses informations sur GitHub et jusqu’à un conteneur pour simplifier l’installation. Mais, comme son nom l’indique, un serveur de données personnelles ne peut héberger que ses propres informations. Il n’est pas question de créer une instance comme le fait Mastodon. On ne peut y inviter personne.
Sur les relais, c’est nettement plus compliqué. Dans sa documentation, Bluesky explique que tout le monde peut en héberger un, mais que c’est « un service assez gourmand en ressources ». Gourmand comment ? Très vorace en fait, car les relais arpentent l’intégralité des PDS pour en indexer le contenu. Certaines estimations tablent sur un minimum de 4,5 To à l’installation et d’une croissance minimale de 18 Go par jour pour les seules données JSON, sans parler des données brutes, beaucoup plus volumineuses, d’un facteur 10 selon Gavin Anderegg. Ce dernier rappelle d’ailleurs que ces chiffres ne tiennent pas compte du récent emballement dans les inscriptions sur Bluesky.
Concernant les vues d’applications, techniquement tout le monde peut en développer. Dans l’idée d’ailleurs, Bluesky parle de vue pour évoquer un prisme permettant de représenter des données depuis un flux brut. Si la seule utilisation actuelle est faite dans le cadre d’un service de micro-blogging, le protocole AT peut a priori être utilisé pour tout et n’importe quoi.
Pour le reste, tout est du ressort strict de l’entreprise. Bluesky contrôle notamment deux éléments importants : les DID:PLC et les DM. Les premiers représentent, dans les grandes lignes, les identifiants des utilisateurs. Les seconds sont les messages privés, qui ne sont pas pris en charge par le protocole AT. Les données correspondantes ne sont donc pas présentes dans les PDS, mais gérées directement par Bluesky de manière séparée.
Bluesky n’est ni fédéré, ni décentralisé… pour l’instant
Le protocole AT a été pensé pour être décentralisé. Dans la pratique, Bluesky ne l’est pas. La possibilité de créer facilement un PDS n’est qu’un petit élément parmi d’autres. Même si l’on peut créer des relais, leur mise en œuvre est complexe et sans doute bien trop onéreuse en stockage et bande passante pour être intéressante.
On ne peut pas dire que Bluesky soit actuellement décentralisé, et encore moins fédéré. Il y a bien un centre, et il est géré par l’entreprise Bluesky. Sans son relai, rien ne fonctionne. Chaque serveur de données personnelles ne sert ainsi que comme petit réservoir pour les informations d’une personne, incapable de fonctionner par lui-même.
Pour Gavin Anderegg, ce n’est ni bien ni mauvais : ce n’est que le fonctionnement actuel, qui pourrait changer. Il estime en effet que l’équipe en charge du réseau se dirige petit à petit vers la décentralisation, mais que la tâche reste immense au vu des choix techniques. En outre, il souligne la grande ouverture du protocole, qui permet de voir l’intégralité du flux, puisque toutes les informations y sont publiques.
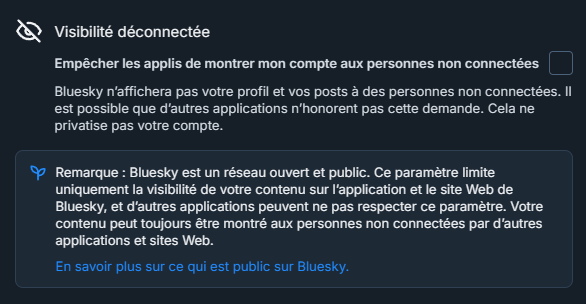
Cet aspect du réseau est d’ailleurs moins connu et peut avoir toute son importance : rien de ce que vous publiez sur Bluesky n’est privé. On peut s’en rendre compte facilement en allant dans les options de vie privée et sécurité. Là, un réglage propose de masquer le compte aux personnes non connectées à Bluesky. Cependant, on est averti : « Bluesky est un réseau ouvert et public. Ce paramètre limite uniquement la visibilité de votre contenu sur l’application et le site Web de Bluesky, et d’autres applications peuvent ne pas respecter ce paramètre. Votre contenu peut toujours être montré aux personnes non connectées par d’autres applications et sites Web ». Les profils privés n’existent pas sur le réseau. Une page résume la situation sur les données publiques et privées.

Commentaires (11)
Vous devez être abonné pour pouvoir commenter.
Déjà abonné ? Se connecter
Abonnez-vousAujourd'hui à 16h51
ça lie très bien avec l'article d'hier où les commentaires mettaient le côté supposé fédéré et décentralisé de Bluesky en avant
Merci Vincent!
Modifié le 21/11/2024 à 17h27
C'est précisément la conversation, très riche, enclenchée entre hier et ce matin qui nous a motivé à synthétiser les choses et essayer de les rendre accessibles au plus grand nombre !
C'est aussi le fait qu'on lit partout que BS est un réseau "décentralisé", alors que comme le montre Vincent, c'est un peu plus compliqué que ça...
D'ailleurs @Vincent_H on aura peut-être intérêt à faire un article du même genre sur ActivityPub, histoire de
Aujourd'hui à 17h09
Aujourd'hui à 18h00
Merci @VincentHermann pour l'article !
Aujourd'hui à 17h22
Modifié le 21/11/2024 à 18h42
Donc je vois plus son intégration ActivityPub comme un moyen d'interco pour se connecter au Fediverse que comme un backend pur. Un peu comme les bus d'événement chez les Cloud Provider par exemple, qui ont tous une compatibilité Apache Kafka / Kafka Connect (car produit très à la mode dans le domaine) mais qui reposent sur un logiciel propriétaire du CSP.
Cette couche de compatibilité est, évidemment, un moyen de faciliter la migration d'une solution à l'autre. On le voit aussi dans le domaine des SDK autour de l'IA générative où les autres concurrents émulent les API d'OpenAI dans les leurs. Celles-ci sont devenues un standard de fait en raison de la rapide adoption de leurs produits. C'est aussi utilisé dans la stratégie du EEE comme l'a subi XMPP en son temps.
Aujourd'hui à 21h03
Par exemple, mon instance est configurée par défaut en privé. Si mes membres veulent avoir un compte public, ça nécessite une action de leur part et c'est tout l'intérêt. Ils et elles doivent être conscient que c'est un choix important.
Je ne suis, donc, pas compatible avec Threads et c'est de la merde, en gros.
Attention, une instance privée ne veut pas dire que les publications ne sont pas visible de l'extérieur. On discute avec la terre entière sans souci. Ça veut juste dire que, sans compte, tu ne peux pas tout voir de l'extérieur.
Modifié le 21/11/2024 à 22h03
Une vue un peu biaisée d'un hébergeur d'une instance Mastodon de 2 utilisateurs: Y a quelques mois (un peu plus d'un an en fait), Meta a invité "confidentiellement" les administrateurs.ices des "grosses" instances Mastodon à causer fédération. Il s'en est suivi un débat ouvert, pas du tout confidentiel, autour de "oui/non pourquoi/comment avec quelles conséquences" on pourrait accepter de fédérer avec les serveurs de Threads.
Un article ici par exemple : https://hub.fosstodon.org/facebook-fosstodon-fedi
De nombreuses instances (invitées ou pas par Méta) on eu cette conversation en interne et ont conclu selon les cas "on bloque les serveurs méta" ou "on va bien voir" ou "mais si allons-y, fédérons". (blocage préventif puisque la fédération n'était encore qu'en projet et pas du tout effective à ce moment là).
Dans la première catégorie y a celleux qui savent bien comment marchent les machines à emmerdification comme Facebook et qui ont bien compris qu'il ne s'agit là que d'une nouvelle mouture du Embrace Extend Extinguish d’antan. (les barbus des années 90 reconnaîtront).
Dans la dernière catégorie, y a Mastodon.social, l'instance de Eugene. et la direction qu'il prend (pousser son instance promotionnellement au détriment des autres) est pas super bien perçue. J'ai plus les chiffres du moment mais je serais pas étonné que mastodon.social représente 1/4 ou plus des utilisateurs.ices actifs de Mastodon. Alors que initialement, l'objectif était justement de pousser à des myriades de petites instances à taille humaine. Et donc mastodon.social ne s'oppose pas à threads et n'a pas il me semble une attitude hostile envers Meta. (normalement y a le meme de Gandalf "Fly you fools" qui arrive à ce moment là).
A titre perso, sur mon instance de 2, j'ai bloqué Threads.
Aujourd'hui à 22h26
Aujourd'hui à 17h01
Je pense qu'il y a dans tous les cas une idée fondamentalement différente entre ActivityPub utilisé par Mastodon (entre autres) et AT Protocol de Bluesky.
La fédération et la décentralisation ont, à mon sens, quelques petites subtilités.
ActivityPub, techniquement, c'est comme un email : des messages (événements) placés dans des boites in et out. Il est vraiment abstrait de l'application qui l'implémente. C'est là où la fédération diffère un peu de la décentralisation, car ça signifie qu'on interconnecte une multitude de produits différents via un protocol commun (Mastodon, PeerTube, PixelFed, etc, utilisent ActivityPub alors que ce sont des logiciels différents). Un peu comme HTTP sert à faire causer plein de technos et produits différents. La fédération n'est pas une nécessité en soi et une instance Mastodon peut vivre de manière isolée (réseau social interne d'entreprise par exemple).
L'idée du décentralisé à la Bluesky, je la vois au sens où on a un service (ici : un média social) mais dont on peut instancier soi-même certains composants pour rejoindre une ruche collective qui elle, est centralisée. De ma compréhension de l'explication du protocole AT et de son implem de Bluesky, c'est grosso merdo comme du Bittorrent où le tracker (une partie centralisée, mais potentiellement multiple) s'occupe de la mise en relation avec les Peers (qui seraient un mix du PDS et Relay je dirais de prime abord). La diff avec la fédération, c'est qu'ici, le produit décentralisé n'est pas autonome, car il lui manque l'annuaire central. Mais comme ce produit décentralisé est rattaché à un service (ce que n'est pas Mastodon, par exemple), c'est une architecture qui s'explique aussi.
Modifié le 21/11/2024 à 20h07
Il est utilisé pour des questions de performance, mais le protocole est prévu pour fonctionner sans, et c’est officiellement dans la doc, et AT encourage officiellement à s’en passer.
https://atproto.com/guides/glossary#relay
Relays are an optimization and are not strictly necessary. An AppView could communicate directly with PDSes (in fact, this is encouraged if needed). The Relay serves to reduce the number of connections that are needed in the network.
Given all that, our proposed methodology here of networking through Relays instead of server-to-server isn’t prescriptive. The protocol is actually explicitly designed to work both ways.
Donc absolument aucun problème à ce qu’actuellement seul BS en fasse tourner un ou que ça ne soit à la portée que de gros moyens.
Et dire « sans relay, rien ne fonctionne » est donc faux.