[Tuto] L’influence des couches de neurones sur l’intelligence artificielle
Il était une fois…
![[Tuto] L’influence des couches de neurones sur l’intelligence artificielle](https://next.ink/wp-content/uploads/2024/08/neurone-couche.webp "[Tuto] L’influence des couches de neurones sur l’intelligence artificielle")
Continuons de plonger dans les méandres de l’apprentissage de l’intelligence artificielle, qui ne demande pour rappel pas plus de 10 lignes de code pour commencer. Après notre analyse sur l’influence du nombre d’images pour l’entrainement, les couches et les neurones.
Nous l’avons déjà expliqué, une intelligence artificielle est composée de différentes couches, chacune avec des neurones. Chaque couche n’a pas obligatoirement le même nombre de neurones, mais tous les neurones d’une couche sont reliés à ceux de la couche précédente.
Et si vous vous demandez ce qu’est exactement un neurone dans le cas d’une IA, on a évidemment un dossier sur le sujet.
Notre programme du jour pour « jouer » avec les neurones
Sans attendre, voici le programme que nous utilisons pour nos tests. Il reprend la même structure que dans nos précédentes analyses, avec quelques modifications néanmoins.
import tensorflow as tf
from tensorflow import keras
import numpy as np
import time
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test)= mnist.load_data()
x_train, x_test = x_train / 256.0, x_test / 256.0
start_time = time.time()
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28,28]))
model.add(keras.layers.Dense(500, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
model.summary()
model.compile(loss="sparse_categorical_crossentropy", metrics=['accuracy'])
history = model.fit(x_train, y_train, epochs=10)
model.evaluate(x_test, y_test)
end_time = time.time()
execution_time = end_time - start_time
print(f"Temps d'exécution: {execution_time} secondes")On ajoute une mesure : le temps d’entrainement
Nous avons ajouté une nouvelle bibliothèque time, simplement afin de pouvoir mesurer le temps nécessaire à l’apprentissage. On l’affiche à la fin (dernière ligne de notre code). On va le voir, cela peut varier de quelques dizaines de secondes à des heures suivant les cas. On adapte ensuite le nombre de neurones dans la première couche dense (500 dans l’exemple ci-dessus).
Résumé rapide : augmenter le nombre de couches et/ou de neurones n’est pas obligatoirement synonyme d’augmentation des performances. En plus de ne pas être productif, cela peut rapidement conduire à des modèles occupant plusieurs dizaines, voire centaines de Go en mémoire, à des entrainements de plusieurs heures, etc.
Comme toujours, chaque mesure est faite trois fois et nous prenons la moyenne. Notez que le temps d’exécution de l’entrainement est assez variable d’un essai à l’autre, mais l’ordre de grandeur reste le même. Nous avons donc décidé de laisser la durée dans notre tableau récapitulatif avec un arrondi à l’unité la plus proche, à prendre comme une indication.
Une chose est sûre, on passe de moins d’une minute avec de quelques dizaines de neurones, à plusieurs minutes entre 500 et 5 000 neurones, et à plusieurs heures au-delà de 10 000 neurones dans la couche intermédiaire.
De 0 à 100 000 neurones : le récapitulatif des résultats
Dans tous les cas, la première couche est keras.layers.Flatten(input_shape=[28,28]), avec donc 784 valeurs (28 x 28), puis une seconde dense avec keras.layers.Dense(xxx, activation="relu") sur laquelle nous faisons varier le nombre de neurones. Bien évidemment, pour 0 nous avons simplement supprimé cette ligne. La dernière est aussi dense avec 10 sorties et une activation de type softmax.
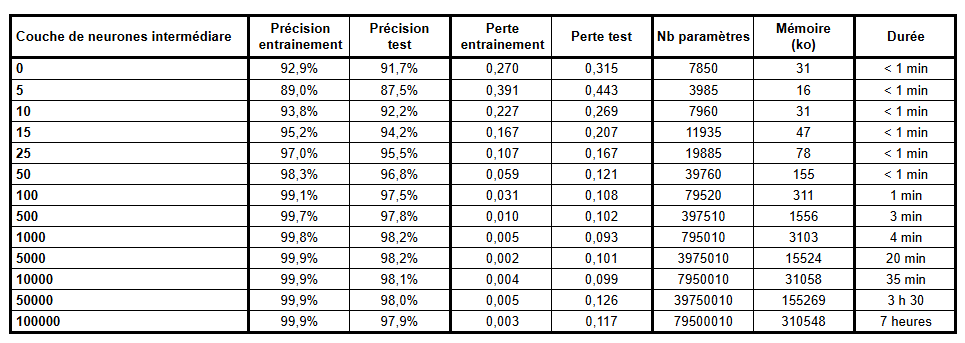
Le nombre de paramètres se trouve pour rappel avec une simple opération mathématique puisque tous les neurones sont reliés à ceux de la couche précédente. Avec 500 neurones intermédiaires, on a donc 397 510 paramètres : 500 x 784 (la couche intermédiaire est reliée aux 784 données)+ 10 x 500 (les 10 de la dernière couche sont reliées aux 500 intermédiaires). On arrive à 397 000.
Mais où sont passés les 510 restants ? Souvenez-vous des poids de chaque neurone ! Nous en avons 500 intermédiaires et 10 à la fin, soit 510 paramètres supplémentaires. On s’en doute bien : plus on a de neurones, plus on a de paramètres… ce qui implique aussi une consommation mémoire plus importante (pour stocker les paramètres). Avec 100 000 neurones, le modèle occupe plus de 300 Mo contre 310 ko avec 1 000 neurones.
Graphiquement, les résultats sont bien visibles
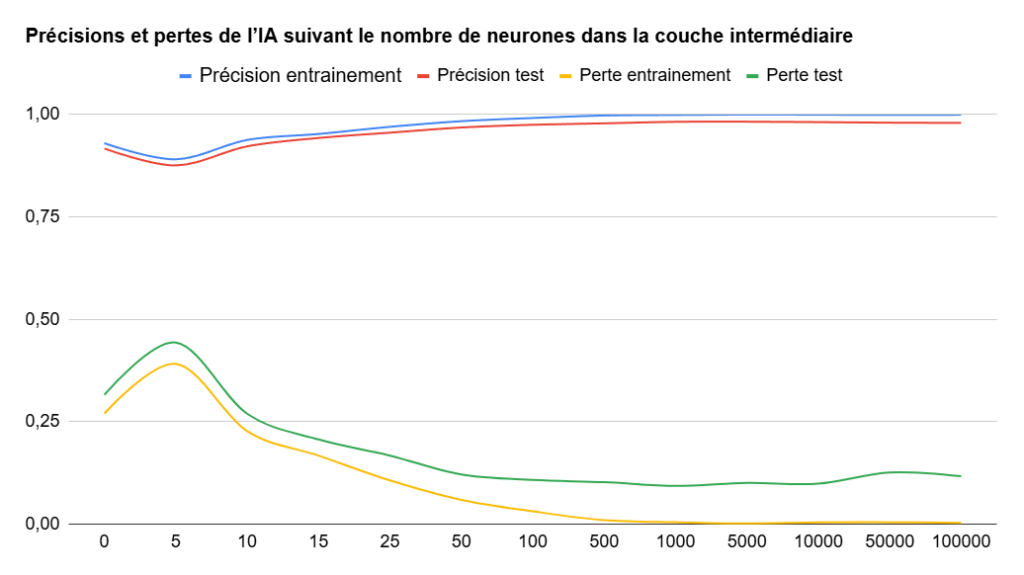
Afin de voir un peu plus facilement l’évolution sur les précisions et les pertes, nous vous proposons un graphique. On peut constater qu’ajouter une couche intermédiaire de cinq neurones est contre-productif. Ce n’est pas surprenant pour une intelligence artificielle qui doit classer… 10 éléments.
Ajouter une seconde couche de 10 neurones permet d’améliorer très peu les performances, mais on continue sur cette lancée avec l’augmentation du nombre de neurones dans notre couche intermédiaire. On remarque que les changements sont très limités à partir de 1 000 neurones… sauf sur le temps d’entrainement et l’occupation mémoire qui augmentent de manière très importante.
Au bout d’un moment, les modèles ne sont pas forcément plus performants, mais le coût d’entrainement – en temps et en énergie – est bien plus élevé. Avec 100 000 neurones, on passe même à sept heures d’entrainement simplement pour identifier des chiffres, contre quelques minutes et des résultats comparables avec 1 000 neurones.
Et si on augmente le nombre de couches ?
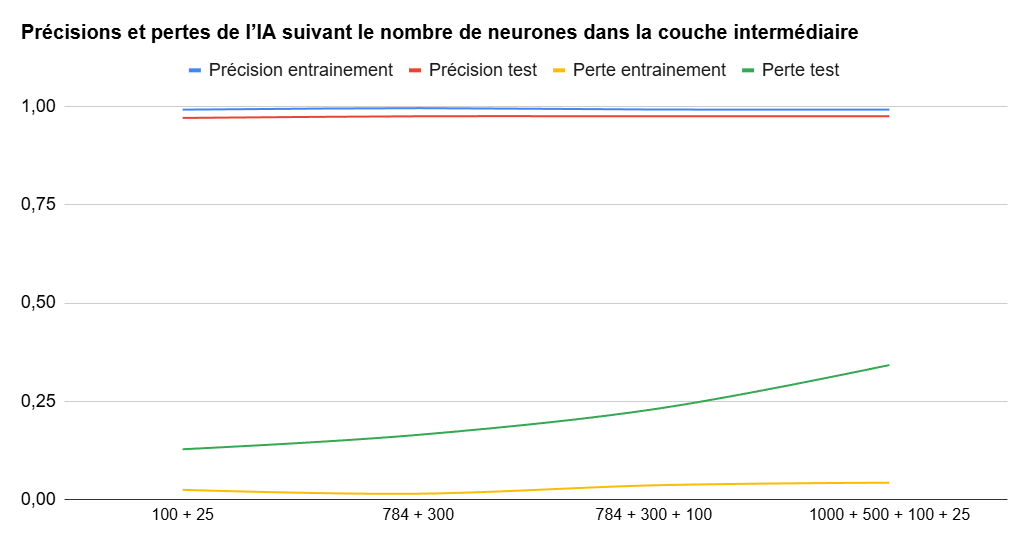
Nous avons ensuite tenté d’ajouter des couches intermédiaires avec une descente progressive du nombre de neurones. Nous avons ainsi fait les mesures avec deux couches intermédiaires de 100 et 25 neurones, de 784 et 300 neurones, de 784 + 300 + 100 neurones, etc. Les possibilités sont infinies.

Les changements sur la précision ne sont pas réellement significatifs. Cependant, la perte a tendance à être plus importante avec l’augmentation du nombre de couches intermédiaires. Pas sur la phase d’entrainement, mais sur celle de test (courbe verte) avec les nouvelles images auxquelles notre IA n’avait pas été confrontée.

Commentaires (15)
Vous devez être abonné pour pouvoir commenter.
Déjà abonné ? Se connecter
Abonnez-vousLe 28/08/2024 à 10h15
Le 28/08/2024 à 10h18
Le 28/08/2024 à 10h22
Le 28/08/2024 à 16h53
Le 28/08/2024 à 16h51
Modifié le 28/08/2024 à 13h54
Le 28/08/2024 à 16h55
Modifié le 28/08/2024 à 13h05
pour ceux qui veulent se faire la série :
Le 28/08/2024 à 13h39
Modifié le 31/08/2024 à 19h12
Et je dis la chose car parler d'intelligence artificielle devient gavant.
Je reprends des arguments vus sur cette page : ce n'est pas avec ça qu'on peut avoir de l'intelligence artificielle.
1. Le neurone formel est une approximation datée de plus de 80 ans du neurone biologique.
2. L'impasse a été faite sur les cellules gliales qui participent aux fonctions cognitives (et non, ce n'est pas que de la glu).
La chose c'est juste des mathématiques, des probabilités et des algorithmes.
Le 28/08/2024 à 14h29
Le 28/08/2024 à 17h05
Le 29/08/2024 à 08h17
Le 29/08/2024 à 09h11
Le 29/08/2024 à 09h31