AlphaGo Zero : derrière le dernier coup de comm’ de DeepMind, l’apprentissage par renforcement
Mais l'Homme reste indispensable

Vous vous souvenez d'AlphaGo, l'intelligence artificielle de DeepMind qui avait écrasé le champion Ke Jie ? Eh bien, elle vient à son tour de se faire dépasser par... AlphaGo Zero. Cette fois-ci, l'intelligence artificielle a étudié seule, uniquement grâce à de l'apprentissage par renforcement. Une technique qui n'est en soi pas nouvelle.
Il y avait un avant et un après AlphaGo, en sera-t-il de même avec AlphaGo Zero ? Peut-être... DeepMind, filiale de Google, revient avec une nouvelle version de son intelligence artificielle dédiée au jeu de Go. Comme son nom l'indique, elle a été repensée de zéro avec une « nouvelle » approche. En parallèle d'un billet de blog, elle a droit à une publication dans Nature, la seconde pour AlphaGo.
Selon ses concepteurs, il n'a fallu que trois jours (environ 4,9 millions de parties) à AlphaGo Zero pour dépasser l'intelligence artificielle qui s'était imposée (4 à 1) face au champion Lee Sedol (voir cette actualité). En seulement trois semaines, elle est arrivée au niveau de la version qui avait affronté (là encore avec une victoire à la clé) le champion Ke Jie.
Comment la société DeepMind est-elle parvenue à une telle performance ? En utilisant une technique qui existe déjà depuis des années, mais qui lui a permis de changer la donne.
Partir d'une feuille blanche, des coups joués au hasard pour commencer
Alors que les versions précédentes d'AlphaGo s'étaient entrainées en regardant des milliers de parties jouées par des humains, aussi bien amateurs que professionnels, « AlphaGo Zero zappe cette étape et apprend simplement en faisant des parties contre lui-même, en commençant à jouer de manière totalement aléatoire ». AlphaGo Zero est ainsi « son propre professeur ».
Pour cela, Google utilise une technique baptisée apprentissage par renforcement. Elle n'est pas nouvelle, datant même des années 90. D'ailleurs, « ce n'est pas le premier logiciel qui apprend par lui-même, la nouveauté c'est que AlphaGo Zero soit si bon », précise le futurologue Anders Sandberg de l'Université d'Oxford à nos confrères de l'AFP.
Pour rappel, les précédentes versions d'AlphaGo misaient en partie sur cette technique et un apprentissage dit supervisé. Dans ce second cas, l'IA apprend par des exemples qu'elle va chercher à reproduire. On peut ainsi lui montrer des millions de photos d'une chaise en lui disant « c'est une chaise » pour qu'elle soit ensuite capable d'en reconnaitre une.
À chaque partie, le réseau de neurones est amélioré
AlphaGo Zero de son côté, n'utilise que de l'apprentissage par renforcement. Au début, elle ne connait donc rien au jeu de Go, si ce n'est évidemment les règles. Ses premiers coups sont joués aléatoirement sans aucune supervision ou aide en s'inspirant de parties déjà jouées.
En fonction du résultat de la partie, l'IA reçoit un bonus ou un malus : « au fur et à mesure qu'elle joue, son réseau neuronal est réglé et mis à jour afin de prédire les mouvements, ainsi que l'éventuel vainqueur de la partie » explique DeepMind. Un peu comme certains peuvent tenter de dresser un animal (sans le côté « joueur » de celui-ci).
Après chaque partie, les performances d'AlphaGo s'améliorent donc légèrement. Cette suite de petits riens finit rapidement par faire un tout. L'intelligence artificielle n'est ainsi « plus contrainte par les limites de la connaissance humaine », estiment ses créateurs dans l'une de ces envolées lyriques dont ils ont le secret.
Un seul réseau de neurones au lieu de deux, Monte-Carlo laissé de côté
Pour arriver à ce résultat, DeepMind a dû procéder à des changements en profondeur. Tout d'abord, AlphaGo Zero n'utilise plus qu'un seul réseau de neurones au lieu de deux. Les précédentes versions en avaient en effet un pour estimer le prochain coup à jouer, l'autre permettant de prédire le gagnant potentiel de la partie suite à cette action.
DeepMind déclare aussi qu'il a laissé de côté la recherche via la méthode de Monte-Carlo, pour une méthode plus simple (sans plus de détails). Pour rappel, cette technique permet d'explorer les conséquences d'un coup en se fondant sur des statistiques plutôt qu'en étudiant l'intégralité des possibilités.
Dans le cas du jeu de Go, cet éventail de possibles serait en effet bien trop grand pour un ordinateur. Un Goban (le plateau de jeu du Go) comprend 19x19 cases (soit 361 au total), il est possible de jouer 361 combinaisons (361 !), soit 1,4 x 10^768 coups (14 suivi de 767 zéros)... Excusez du peu !
Nous avions déjà largement abordé le sujet en mars dernier, en revenant sur le cas des jeux de dames et d'échecs :
De 176 GPU à 48 TPU pour AlphaGo Zero, pour les détails on repassera
DeepMind explique aussi avoir réussi à limiter la consommation électrique grâce à des optimisations au niveau des algorithmes et du matériel. De 176 GPU utilisés par l'IA AlphaGo qui a battu Fan Hui, la société est passée à 48 TPU (Tensor Processor Unit) sur la mouture qui a affronté Lee Sedol et enfin à seulement 4 TPU pour les deux dernières (celle qui a joué contre Ke Jie et AlphaGo Zero).
AlphaGo Zero « n'utilise qu'une seule machine dans Google Cloud avec 4 TPU (AlphaGo Zero peut également être distribué, mais nous avons choisi d'utiliser l'algorithme de recherche le plus simple possible) » précise DeepMind, là encore sans donner aucun détail supplémentaire. À quoi correspond une machine dans Google Cloud ? Impossible à dire pour le moment...
Si la progression est intéressante, on regrette de ne pas avoir plus de données exploitables comme la consommation électrique, le détail des GPU/TPU utilisés, leur puissance de calcul, etc. En l'état difficile d'en tirer des conclusions précises.

Voici un rapide rappel des différents noms des intelligences artificielles AlphaGo de DeepMind :
- AlphaGo Fan a battu Fan Hui en octobre 2015
- AlphaGo Lee a battu Lee Sedol en mars 2016
- AlphaGo Master a battu les meilleurs joueurs mondiaux et Ke Jie début 2017
- AlphaGo Zero a dépassé toutes les autres versions d'AlphaGo
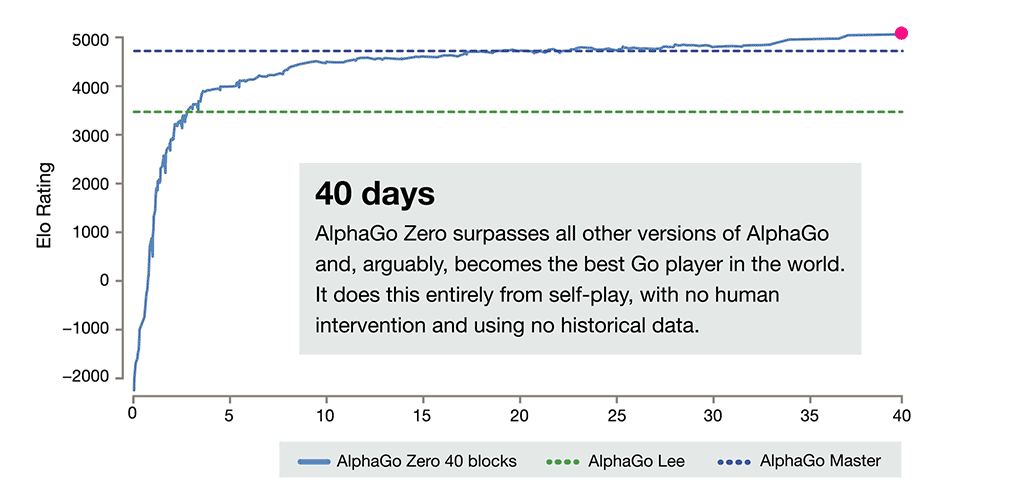
3 jours pour dépasser AlphaGo Lee, 40 jours pour venir à bout d'AlphaGo Master
Bien évidemment, la progression d'AlphaGo Zero est exponentielle durant les premières heures/jours, avant de rapidement se calmer et de stagner, comme vous pouvez le constater sur les graphiques ci-dessous.
Voici quelques échelles de temps des progressions de l'IA telles que données par DeepMind :
- 3 heures : l'IA joue comme un humain débutant et se concentre sur la capture rapide d'un maximum de pierres.
- 19 heures : l'IA maitrise des concepts stratégiques avancés comme la notion de territoire, de vie et de mort, etc.
- 3 jours : l'IA arrive au niveau d'un très bon joueur et dépasse AlphaGo Lee avec un résultat sans appel : 100 à 0.
- 21 jours : AlphaGo Zero arrive au niveau d'AlphaGo Master, l'IA qui avait terrassé le champion Ke Jie en 2017.
- 40 jours (29 millions de parties) : l'IA dépasse toutes les versions d'AlphaGo et devient virtuellement le « meilleur joueur de Go au monde ».
DeepMind n'est pas peu fière de son intelligence artificielle, qui aurait ainsi « accumulé des milliers d'années de connaissances humaines pendant une période de quelques jours seulement ». AlphaGo Zero aurait également développé de nouveaux mouvements et des stratégies non conventionnelles. Pour rappel, c'était déjà le cas dans les affrontements avec les champions où l'IA surprenait parfois avec le placement de ses pierres.
Google propose de retrouver une sélection de parties jouées par AlphaGo Zero. Toutes sont présentées au coup 50 par défaut, mais un menu permet de se déplacer aux coups suivants/précédents et de remonter au début ou à la fin de la partie.
AlphaGo Zero est certainement au top pour le jeu de Go, mais pour le reste...
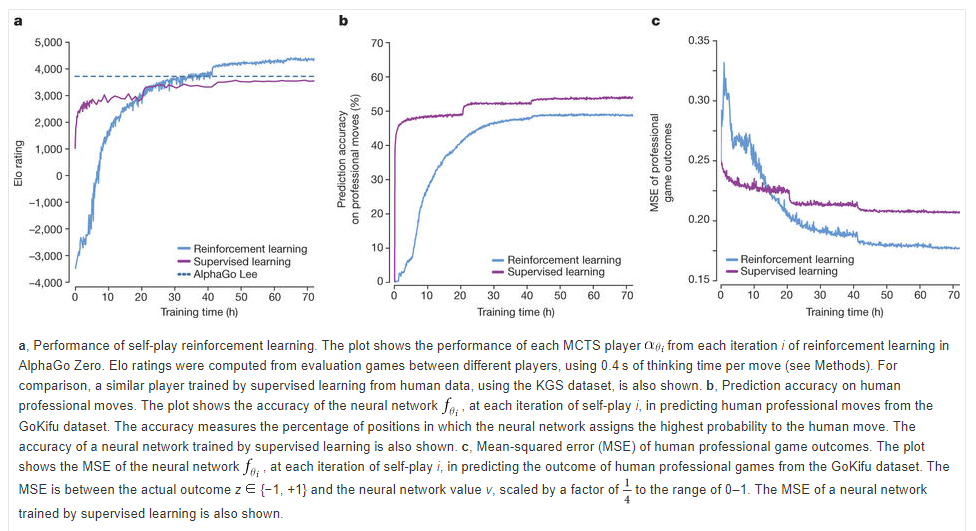
Dans le billet technique publié sur Nature, les chercheurs affirment que leurs « résultats démontrent que l'apprentissage par renforcement pur est pleinement réalisable, même dans les domaines les plus difficiles : il est possible de s'entraîner à un niveau surhumain, sans aucun exemple humain ou conseil, et sans aucune autre connaissance que les règles de base ». Ils démontrent également qu'il ne faut « que » quelques heures d'apprentissage pour obtenir de meilleures performances qu'en s'entrainant à partir de matchs entre humains.
Rappelons enfin qu'AlphaGo n'est pas une intelligence artificielle forte, nous en sommes d'ailleurs très loin. De plus, bien qu'elle ne soit « plus contrainte par les limites de la connaissance humaine » pour son apprentissage, elle a été développée grâce... aux connaissances humaines. Dans tous les cas, elle n'est (très) douée que dans une tâche bien précise : jouer au Go.
Demandez-lui autre chose et elle sera perdue : y'a-t-il un ballon dans une image ? Un éléphant sait-il jouer de la flûte ? Reconnais moi toutes ces fleurs... L'intérêt est surtout la rapidité à laquelle elle peut jouer des millions de parties et donc apprendre de cette expérience, ce qu'un humain n'est pour le moment pas capable de faire (par contre il peut faire un café).
Pour rappel, DeepMind avait annoncé son retrait des compétitions de Go et ne semble pas vouloir revenir sur cette décision, il ne devrait donc pas y avoir d'affrontement entre AlphaGo Zero et des joueurs professionnels. Prochain défi annoncé par la société : s'attaquer à Starcraft II et battre des joueurs.
Commentaires (24)
Le 19/10/2017 à 17h35
Archi faux! Ton imagination découle de l’apprentissage de ton environnement. Tu améliore une idée, tu tire ton idée d’une autre idée etc..
Sinon les civilisations ne seraient pas aussi différentes. Notre imagination n’est que le renforcement de nombreuses itérations faites par l’humanité. Alpha Go lui il le fait tout seul
Le 19/10/2017 à 17h41
Le 19/10/2017 à 18h23
C’est WOPR de Wargame " />
" />
Le 19/10/2017 à 21h00
L’échelle de temps renvois de façon assez flippante au temps estimé pour qu’une IA forte et auto améliorable devienne un “dieu” " />
" />
ou comme un bébé/enfants avec les différentes phase d’apprentissage.
Le 19/10/2017 à 21h55
C’est fou le nombre de personnes qui ont besoin de se rassurer genre “oui mais moi je sais me brosser les dents”
Le 19/10/2017 à 23h26
Pour suivre un peu l’actu du deep lerning :
 YouTube
YouTube
. Meilleur que nous pour reconnaitre des visages
. Possibilité de créer du ralentit vidéo par création de sous images
. Simulation de fluide en 3d via de la vidéo
. Rendu 3d avec un max de bruit puis anti bruit
Et au niveau du jeu vidéos :
. Champion du monde battu sur dota 2 ( équivalent starcraft )
. A roxé tous les jeux d’attari
Allez check cette chaine pour plus de détails :
Le 20/10/2017 à 07h25
Le 20/10/2017 à 07h39
Le 20/10/2017 à 08h03
Je ne suis pas sûr d’où tu veux en venir. L’article rappelle bien
Rappelons enfin qu’AlphaGo n’est pas une intelligence artificielle forte, nous en sommes d’ailleurs très loin. (…) Dans tous les cas, elle n’est (très) douée que dans une tâche bien précise : jouer au Go.
Il n’y a pas d’ambigüité : AlphaGo est une IA faible, c’est-à-dire spécialisée pour une tache. Elle invente dans le cadre de cette tache (son apprentissage l’a menée à découvrir des coups que personne ne lui a jamais appris, donc de l’invention), mais ne fera jamais rien d’autre que cette tache précise.
Lui demander quoi que ce soit d’autre, c’est lui demander d’être une IA forte, qui est un concept totalement différent, et en l’état actuel de la science de la pure science fiction.
Le 20/10/2017 à 09h12
Le 20/10/2017 à 11h43
+10
Le 21/10/2017 à 08h23
Le 22/10/2017 à 16h47
« accumulé des milliers d’années de connaissances humaines pendant une période de quelques jours seulement ». Ceci est faux.
Le 19/10/2017 à 15h08
40 jours (29 millions de parties)
J’imagine qu’il ne dort jamais ?
Le 19/10/2017 à 15h10
Ca occupera le chef des ants un petit moment ;)
Le 19/10/2017 à 15h47
C’est un peu bizarre de parler en jour et en semaine pour le temps d’apprentissage, alors que de toute évidence c’est le nombre de parties qui importe.
Le 19/10/2017 à 15h59
Quoique… Compter en temps plutôt qu’en nombre de partie permet de prendre en compte à la fois le nombre de parties ET le temps qu’il met à jouer des parties.
Le 19/10/2017 à 16h00
Oui et non.
Lorsque l’on veut déterminer si un algorithme est efficace, on essaie d’avoir une notion de temps d’exécution.
Pour le nombre de partie, si le temps de calcule était constant pour tous les algorithmes et aussi tout au long de l’apprentissage, ça aurait était une possible mesure. Mais ici, rien n’est moins sûr, aussi bien car on peut imaginer qu’un algorithme va passer plus de temps pour réaliser ou analyser chaque partie mais aussi que la longueur des partie varie au fur et à mesure que l’apprentissage s’effectue.
Enfin, tout simplement, ce qui importe au final, ce qui affecte l’utilisateur, c’est le temps qu’à mis un algorithme à s’exécuter et sa consommation de ressource.
Le 19/10/2017 à 16h00
Certes, mais si on m’annonçait juste qu’il a fallu 29 millions de parties pour arriver à tel niveau, je demanderais “oui, mais ça a pris combien de temps ?” D’autant que la durée des parties n’est sans doute pas constante.
Le 19/10/2017 à 16h01
Et il consomme combien de KWatt par partie ?
Le 19/10/2017 à 16h04
Le 19/10/2017 à 16h51
Du coup, on a une idée de la taille du programme une fois l’apprentissage terminé ?
Un peu plus de 2 millions de parties en 3 jours, il faudrait réduire encore d’un bon facteur 100 pour arriver au niveau d’un apprentissage equivalent à celui d’un grand maître.
Le 19/10/2017 à 17h03
Exact, je suis sûr que je peux le battre… si j’ai le temps de jouer 29 millions de parties " />
" />
Le 19/10/2017 à 17h12
Peut-on dire d’un algorithme qu’il n’est jamais assez fort pour ce calcul ?
Au jeu de Go, je me ferai sans aucun doute battre à plate couture par AlphaGo, mais je sais faire tellement d’autres choses, y compris imaginer ou inventer, sans avoir eu besoin d’étudier ce qu’ont fait les autres, comme tous les lecteur de NI et même n’importe quel homo sapiens d’ailleurs.