Comparatif des SoC Apple : des M1 aux M4, M4 Pro et M4 Max
Attention, M6 est déjà pris !

Comment se positionne la nouvelle puce M4 Pro d’Apple face à la M4 ? Et qu’en est-il de la M4 Max face à la M4 Pro et la M4 ? Nous avons regroupé les principales caractéristiques techniques dans un tableau pour vous aider à y voir plus clair.
Cette semaine, Apple a présenté deux nouvelles puces : la M4 Pro inaugurée avec les Mac mini hier, et la M4 Max lancée aujourd’hui avec les nouveaux MacBook Pro. Voilà de quoi compléter la famille des M4 présentée pour la première fois en mai de cette année dans l'iPad Pro.
Notre comparatif de 12 SoC « M »
Nous avons regroupé l’ensemble des caractéristiques techniques des nouveaux SoC dans un tableau comparatif, avec les différentes déclinaisons des M1, M2 et M3 à titre de comparaison :
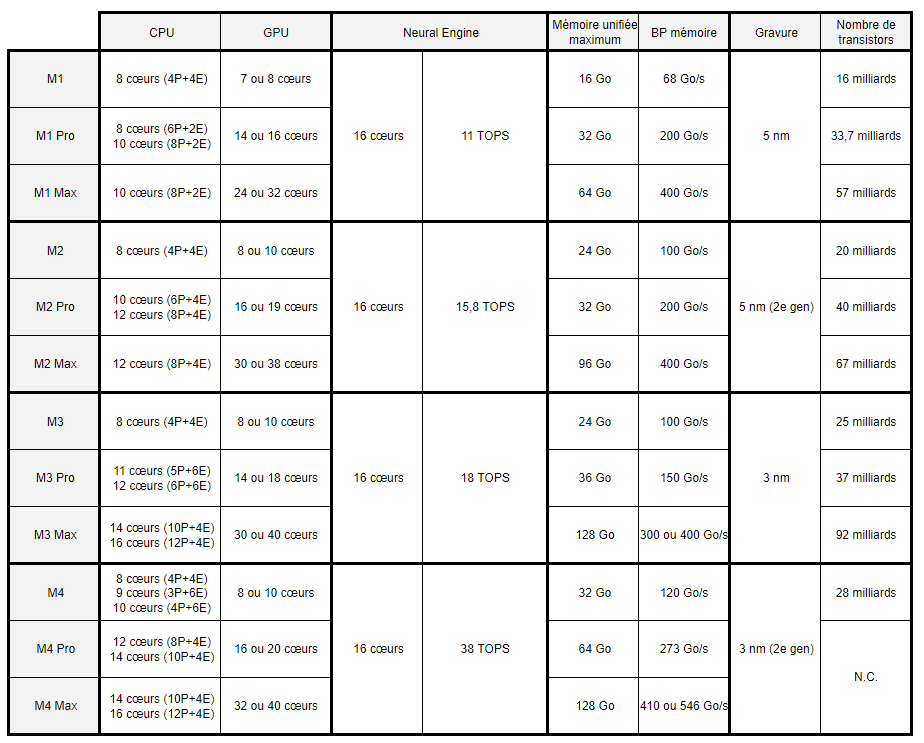
Nombre de cœurs (CPU et GPU) et mémoire unifiée variables
Comme toujours chez Apple, une même puce peut avoir plusieurs variantes. En M4 par exemple, la partie CPU intègre 8 à 10 cœurs, contre 12 ou 14 pour la version Pro et 14 ou 16 pour le M4 Max. Attention donc au moment de choisir le SoC de votre machine.
La puce M4 reste assez proche de la M3 avec trois ou quatre cœurs performances. Par contre la version Pro s’approche davantage du M4 Max avec 8 à 10 cœurs performances, là où le M3 Pro en avait cinq ou six.
Même chose sur la partie GPU, avec là encore des écarts sur les performances. Le nombre de cœurs du NPU pour les calculs liés à l’intelligence artificielle ainsi que les performances semblent être les mêmes sur l’ensemble des SoC M4, comme c’était le cas avec les générations précédentes.
« Intégrant un Neural Engine jusqu’à deux fois plus rapide que celui de la génération précédente et des accélérateurs d’apprentissage automatique améliorés dans les CPU, les puces de la famille M4 livrent des performances incroyables pour l’exécution de projets professionnels exigeants et de tâches exploitant l’IA », affirme Apple… sans s’étendre davantage sur les chiffres, comme lors du lancement du M4.
Si Apple est passé à 16 Go de mémoire minimum sur ses nouveaux produits (enfin…), la quantité maximale dépend aussi du SoC : 32 Go en M4, 64 Go en M4 Pro et enfin 128 Go en M4 Pro Max. La mémoire n’est pour rappel pas évolutive une fois la machine achetée.
Et encore, c’est la théorie. En pratique, c'est plus compliqué. Sur la fiche produit des nouveaux MacBook Pro, Apple annonce les limitations suivantes : 36 Go de mémoire unifiée sur les M4 Max avec CPU 14 cœurs, 24 ou 48 Go sur les M4 Pro avec CPU 16 cœurs, et enfin jusqu'à 128 Go uniquement avec les M4 Max à 16 cœurs. Une limite qui dépend donc à la fois de la variante du SoC, mais également de son nombre de cœurs. Un découpage beaucoup plus commercial que technique.


Thunderbolt 5, nombre de moteurs de codage et décodage
Toutes les puces M4 disposent d’une accélération matérielle pour H.264, HEVC, ProRes et ProRes RAW, ainsi que d’un moteur de décodage vidéo. La puce M4 Max juxtaposant deux GPU M4 Pro, elle hérite du double de ces moteurs : deux pour le codage, deux pour le codage/décodage ProRes. Le décodage AV1 est aussi supportée par l’ensemble des puces M4.
Signalons aussi que les puces M4 Pro et Max proposent du Thunderbolt 5 jusqu’à 120 Gb/s, là où la M4 classique se contente de Thunderbolt 4.
On vous épargne le discours sur les performances par rapport aux puces des générations précédentes. Il se trouve dans ce billet de blog.
Commentaires (20)
Abonnez-vous pour prendre part au débat
Déjà abonné ? Se connecter
Cet article est en accès libre, mais il est le fruit du travail d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles
Profitez d’un média expert et unique
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 30/10/2024 à 18h58
Au moins dans le tableau comparatif en tout cas.
Modifié le 30/10/2024 à 19h28
Le M3 Pro écrase (+20%) le M2 Pro sur les benchs "single core" et l'écart se resserre en multi (moins de cœurs mais plus rapides).
Le 30/10/2024 à 21h55
Mais le fait que le M2 ait plus de performance cores que le M3 et une plus grande bande passante mémoire font que dans certains usages, le M2 est plus rapide que le M3.
La baisse du nombre de transistors est un bon indicateur de la baisse de puissance également, mais ici, vu l'ordre de grandeur, ça joue pas à grand chose.
Bref, tout ça pour dire que c'est fou de sortir un processeur moins bon sur les specs de base que son prédécesseur. Surtout sur la bande passante mémoire. Je comprend pas comment on peut sortir un produit comme ça. Mais bon, c'est Apple, faut pas chercher à comprendre…
(note, tous les "MX" sont des "MX Pro". Flemme de l'écrire à chaque fois).
Le 30/10/2024 à 19h18
Le 30/10/2024 à 23h45
Le 30/10/2024 à 21h10
Le 31/10/2024 à 14h27
Tu voulais quel genre de com de leur part ?
Apple communique rarement sur la partie matériel, c'est "accessoire", le plus important c'est l'expérience utilisateur.
Le 31/10/2024 à 15h43
Le 31/10/2024 à 19h20
Et les concours de com de Intel et AMD ne servent qu'à une partie des clients, une autre partie d'en moque. Cela contribue même à l'impression d'ultracomplexité de l'informatique. Plus on a d'infos, plus on a de comparaisons à faire, plus il y a de doutes...
Un peu comme vendre une voiture de série en indiquant jusqu'au 0 à 100 par défaut...
Le 01/11/2024 à 11h15
Je me sers pas de la com' de ces boîtes. Mais ce qui m’intéresse c'est les détails plus profonds comme l'IPC, la longueur du décodeur d'instruction, le TLB, l'organisation des unités flottantes, la longeur du data path.... Et c'est pour ça que je préfère les slides car ces informations sont parfois accessibles. Et je chérie ces informations car avec tu peux comprendre ce qui se passe dans le CPU mieux que les slides des marketeux sur les perfs du CPU lors de benchmark (dont on ne connait jamais les conditions de tests [OS, température ambiante...])
En ce qui concerne l'ultracomplexicité de l'informatique... Et bien oui l'informatique est une science et c'est très complexe. Rien de nouveaux sous le Soleil. Par contre, la quantité d'informations n'est pas un problème tant que ce n'est pas du bullshit de marketeux (parce que ça c'est vraiment cancérigène).
Après, c'est à chacun de savoir ce qu'il intéresse dans les infos et ce qu'il considère comme utile à garder ou à ignorer pour son analyse. Ce n'est, cependant, pas propre à l'informatique ou même spécifique à ces histoires d'architectures CPU.
Le 03/11/2024 à 15h23
Autant ce sont des informations précieuses quand on fait des compilateurs CPU, autant sur des machines ultra hétérogènes et des traitements répartis comme maintenant, ça a peu d'intérêt je trouve, sans compter que l'IPC ARM et l'IPC x64 sont non comparables, surtout si on parle d'IPC de type AVX ou autre.
Ce qui m'intéresserait, c'est de voir comment les Apple Mx réorganisent les instructions. Je penche depuis le début pour une réorganisation qui tant vers une exécution proche du VLIW, ce qui expliquerait en grande partie les perfs en émulation.
Mais c'est du pinaillage: si je développais des compilateurs ça m'intéresserait, mais pour de l'utilisation, ce qui m'intéresse c'est plus le confort (qui n'est pas totalement /uniquement lié aux perfs théorique d'un CPU)
Le 03/11/2024 à 17h51
Bref, elle recherche des infos qui ne sont pas utiles pour le commun des mortels.
Ses commentaires sur le sujet sont généralement très intéressants.
Le 04/11/2024 à 14h52
Tu es dans le vrai pour le compilateur. En revanche je ne suis pas en total accord pour la suite. Certaines de ces informations sont pertinentes pour des cas d'usages. Le TLB a une énorme importance pour les accès mémoires, sa profondeur et la taille des pages peut avoir une influence non-négligeable sur certains scénarios mais connaître aussi le nombre d'unités FPU sont des détails importants. Pas uniquement pour les compilateurs ou des applications spécifiques, mais aussi pour voir l'évolution d'une architecture et éviter le discours marketing.
Même si ton architecture est très hétérogènes au sein de ta puce (CPU, NPU, GPU...) il n'empêche que c'est intéressant en soi d'avoir les informations propres à chaque partie et à leur interconnexion, indépendamment du fait que tu réalises plus de calculs d'un type que d'un autres.
Bonne question pour VLIW, je ne sais pas pour le CPU. Par contre pour le GPU et le DSP c'est plus que probable car c'est plutôt répandu.
*
"Mais c'est du pinaillage: si je développais des compilateurs ça m'intéresserait, mais pour de l'utilisation, ce qui m'intéresse c'est plus le confort (qui n'est pas totalement /uniquement lié aux perfs théorique d'un CPU)"*
Et moi ce qui m'intéresse, au delà du confort, c'est d'avoir un processeur adapté à mon usage. Si je dois acheter (ou louer) ce type de machine, j'aime savoir ce qu'il y a dedans à minima pour faire un choix éclairé.
Après je tiens à préciser: Mme Michu & co n'ont clairement rien à faire de ceci. La notion même de fréquence ou de coeur de calculs sont très loin dans leur critère d'achat. Elles préfèrent des arguments plus "marketing" que techniques. Et sur ce point, elles achèteront Apple pour ce qu'Apple représente et non ce qu'Apple a mis comme génie dans la puce.
Le 04/11/2024 à 19h10
Apple ne fait plus dans le pro (dans le sens ils ont tué leurs serveurs, leurs téléphones et ordis sont une plaie en réseau encore maintenant).
Ils sont dans la station de travail et très orientés multi-média.
Pour le moment, ils glânent les clients du côté "ras le bol du blabla technique - on veut du résultat" (et je les comprends après 40 ans de "révolutions")
Apple a peut-être de l'or dans les mains, mais ne sautent pas encore le pas pour repartir sur le côté "technique". Pour le détail, peut-être un oeil du côté des forum de Avahi Linux donnera un peu d'idées?
Par contre à part usage extrêmement spécifique, en général il y a beaucoup à faire pour optimiser "aux petits oignons" pour sa machine, que ce soit sur l'algo, la répartition sur els coeurs, le type de parallélisation, la complexité des tâches ... Là on est en présence de CPU+RAM très rapides, ça aide à ne plus se poser trop de questions :)
Le 05/11/2024 à 10h48
(en espérant que ce x94 en perf n'équivaut pas à générer un film en noir et blanc :) )
Le 05/11/2024 à 18h43
Le 05/11/2024 à 21h11
Mais les langages 'classiques' sont incapables de gérer correctement ces instructions. C'était d'ailleurs le constat dans les années 80 qui a amené le RISC et les 1er ARM: l'adoption de compilos haut niveau faisait disparaître l'usage des instructions cisc (par exemple, un x86 a des instructions de calcul en mode quasi texte ou de recherche qui ne correspondent à rien dans les langages).
Bref, je te donne raison sur l'intérêt de bien connaître son archi.
En même temps ces annonces ARM me rappellebt les années 90 quand IBM/Apple faisaient du Power PC (et les difficultés d'IBM à sortir le meilleur des power pc - ainsi que la difficulté de prédire comment allait se comporter le cpu ce qui gênait les dev en assembleur).
Bref, même si Apple a un excellent CPU, je n'enterrerait pas le x86 avant un moment. (Tout en remerciant AMD de montrer à Intel comment implémenter AVX512)
Le 05/11/2024 à 22h29
Néanmoins tout les processeurs sont des risc à l'heure actuelle si on regarde dans les détails. Les x86 sont certes des CISC, mais dès le tout début du front-end du CPU, tu as une conversion des instructions en micro-opérations, qui ressemble furieusement à ce que tu as en risc. Est-ce une bonne chose ? Honnêtement je ne sais pas à l'heure actuelle. Les deux approches ont des avantages et inconvénients.
Mais néanmoins je pense que ce n'est pas nécessairement un problème de langage. Il existe un langage pour ça, et c'est l'assembleur. Les langages de haut-niveau s'appuie dessu via un interpréteur (compilateur, JIT...).
Je pense que le soucis concerne la capacité du compilateur a comprendre un code ou une fonction dans sa globalité et comment l'optimiser avec les bonnes instructions. Il y a, selon moi, une responsabilité majeure des développeurs qui, pour la très grande majorité, ignore comment fonctionne un ordinateur, et par conséquent n'ont pas connaissance de ce genre de détails et son impact.
Mais finalement, bien que non-idéal, on s'y retrouve sous la le bon outils pour la bonne tâche.
VLC est en majorité codé en C++, et tu trouves de l'assembleur pour les fonctions les plus critiques (e.g., en/decoders).
Je n'ai malheureusement jamais joué avec l'architecture PowerPC :( Mais je ne perds pas espoir avec la possiblité d'en louer ou d'en acheter un). En revanche, de ce que j'ai vu de son fonctionnement, elle a des trucs sympathiques.
Je te rejoins à 100%, l'x86 n'est pas mort ni à court ou moyen terme. Et oui, merci à AMD pour le double pumping qui ouvre la voie à de possibles folies (AVX-2048 ?
Le 06/11/2024 à 00h13
- tout à fait d'accord, RISC ou cisc, ce n'est qu'une façade. Et même RISC-V n'est qu'un ensemble d'ISA, l'implémentation 'hardwired' d'un RISC-V est possible, mais ne permet pas les performances d'un CPU qui redécoupe/réorganise
- en termes de langages, je connais fortran et ses extensions (MPI/OpenMP) que j'ai utilisé il y a plus de 20 ans sur du code matriciel et 64 CPU. Je n'ai pas compris que fortran ne soit pas utilisé avec le GPGPU et le SIMD.
- pour les dev, c'est très variables. Mais j'estime que dans les outils bureautiques/internet, les CPU sont sollicités essentiellement pour de la comparaison de chaîne (indexation des colonnes, des attributs par nom, interprétation de scripts, de XML, de HTML...) +le chiffrement (donc multiplication et division entières). Tout soft de compta utilise une représentation parfaite des nombres (donc pas de virgule flottante) et ces opérations n'ont pas de bench généralement (bon, un peu avec les benchs bdd). Donc se poser la question de comment ma structure va tomber avec les pages mémoire ou si mes nombres sont alignés et si ma boucle passe en cache... C'est loin de 90% des dev.
- est-ce que les Apple M ne ressembleraient pas un peu aux transmeta?
Le 06/11/2024 à 13h51
Fortran fait du SIMD mais il délègue ceci aux compilateurs. Tu le peux faire un peu plus "nativement" via l'iso_c_binding sur les intrinsiques. Note que le C++ propose d'introduire le SIMD dans la norme C++26. A ma connaissance actuelle, seul Rust propose de faire du SIMD d'une façon naturelle.
Dans tout les cas, il faut checker l'assembleur et parfois jouer avec les options du compilateurs et le code pour arriver à ses désirs.
Pour le GPGPU, tu peux regarder du coté d'OpenMP pour les calculs hétérogènes ou OpenACC. Certains compilateurs comme pg ce sont aussi associées avec Nvidia pour intégrer du CUDA en Fortran sous forme d'extension.