MinIO : créez simplement votre propre service de stockage objet, compatible S3 et distribué
Sous Linux, macOS ou Windows

Les services de stockage en ligne tels qu'Amazon S3 sont pratiques, mais parfois coûteux. En être dépendant peut être un problème, notamment en phase de développement d'une application. Heureusement, des outils open source, compatibles avec l'API S3 et relativement complets tels que MinIO existent. Voici comment l'installer.
Les développeurs ont l'habitude d'utiliser des solutions de stockage objet, ayant pour principal avantage de se reposer sur une API REST, accessible via de simples requêtes HTTP. Idéale à intégrer dans le code d'une application.
Applications et serveurs compatibles S3 : des outils à tout faire
Amazon a été pionnier en la matière avec son service S3, devenu une référence du genre. À tel point que son API est un standard de fait, intégrée à de nombreux services et outils. De quoi inciter les concurrents du géant américain à offrir une compatibilité plus ou moins complète, leur ouvrant les portes d'un vaste écosystème.
Cela permet également de limiter la dépendance des développeurs à S3, pouvant passer d'un service de stockage à l'autre sans trop d'efforts. Poussé à l'extrême, ce concept a donné naissance à MinIO, un serveur de stockage objet open source (Apache 2.0), multiplateforme, compatible S3, très facile à installer. L'idéal pour des développements locaux par exemple.
Ainsi, vous pouvez installer MinIO sur votre machine, un serveur local ou distant, l'utiliser comme n'importe quel service compatible S3 pour développer votre site ou application, comme nous allons le voir dans cet article. Vous êtes libre, ensuite, de simplement modifier les paramètres de connexion si jamais vous utilisez un autre service en production.
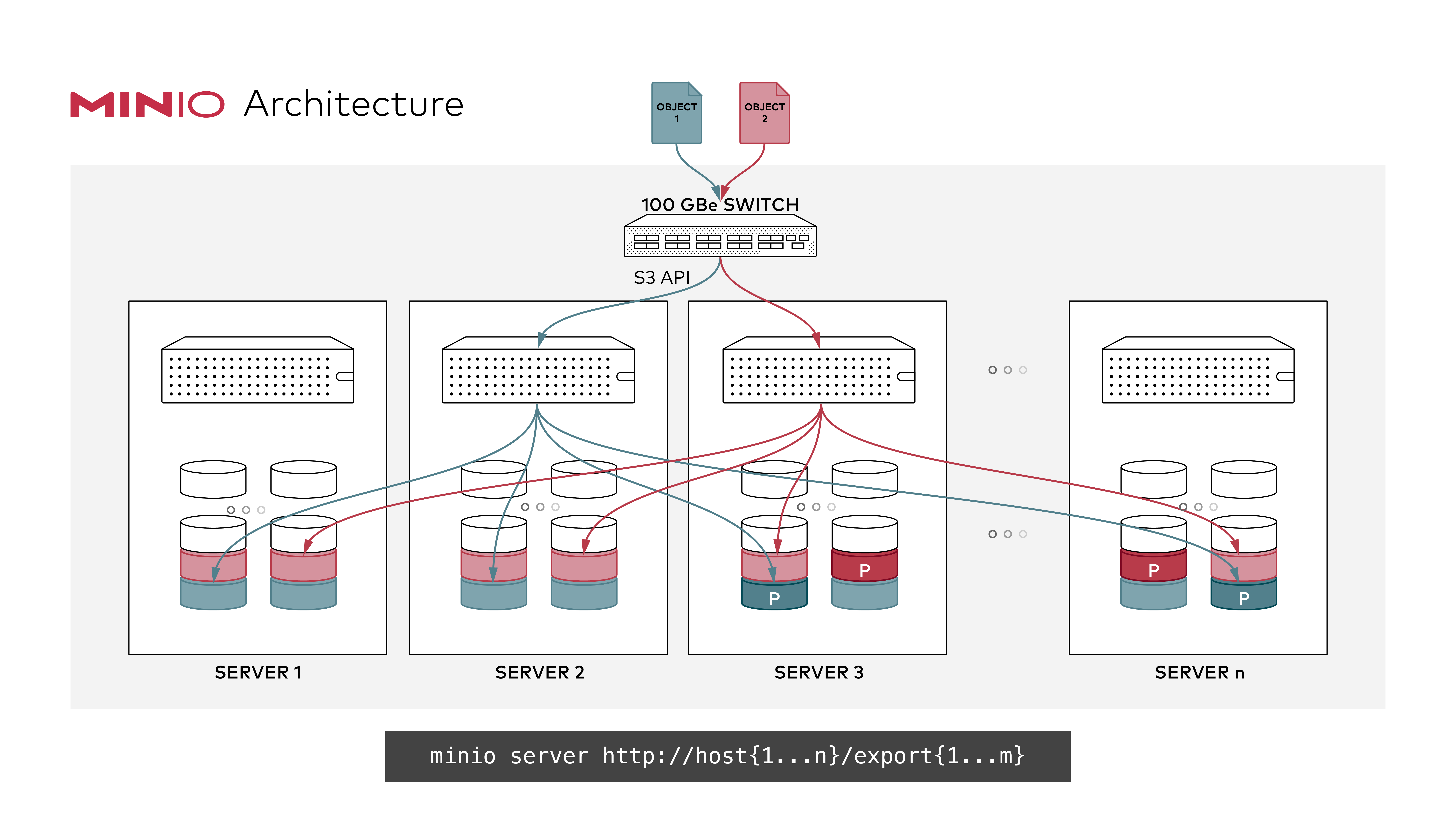
Mais cela peut aller plus loin avec la mise en place de MinIO sur un ou plusieurs serveurs/instances, chacun disposant d'un ou plusieurs périphériques de stockage pour la protection et la redondance des données. Le tout géré à la main ou via Docker/Kubernetes. Des cas que nous étudierons plus en détail dans de prochains articles de ce dossier.
Notez que MinIO propose également un client, qui a déjà fait l'objet d'un précédent tutoriel. Il peut également être exploité à travers différents SDK proposés pour .Net, Go, Java, Node.js et Python.
- DAS, NAS, SAN, stockage en blocs, fichiers ou objets : qu'est-ce que ça signifie ?
- Utilisez l'Object Storage pour stocker des fichiers et les partager simplement en ligne
- Stockage en ligne, compatible S3, archivage : quel prix pour la conservation de vos données ?
Un serveur lancé en un instant
Ce qui est le plus souvent apprécié avec MinIO, c'est sa simplicité de mise en œuvre. Il peut être nativement lancé sous Linux, macOS ou Windows, proposé comme un exécutable. Vous pouvez aussi le faire via WSL v1/v2.
Pour ce premier essai, nous récupérerons la version Windows que nous plaçons à la racine du compte utilisateur. Nous créons un dossier nommé « minio » qui contiendra les données à la racine du disque principal.
Il suffit alors de lancer le serveur :
minio.exe server c:\minio
C'est tout ! Une fois initialisé, le service sera exposé sur l'ensemble des adresses IP locales de la machine, sur le port 9000. Vous pouvez aussi spécifier une adresse et un port de la sorte :
minio.exe server c:\minio --address IP_ou_hostname:port
Les identifiants par défaut sont minioadmin/minioadmin comme indiqué dans la fenêtre. L'application MinIO Browser est active par défaut, permettant un accès depuis une interface dans un navigateur :

Vous pouvez y créer directement des buckets, y envoyer des données via un simple glisser-déposer, les modifier, télécharger, et même les partager si un accès depuis l'extérieur est configuré.
Pour cela, il faudra ouvrir le port 9000 du firewall de votre machine et y rediriger celui de votre routeur. N'importe qui disposant des identifiants pourra alors accéder aux données. Compatibilité S3 oblige, cela pourra également se faire avec toutes applications ou services gérant cette API, comme MinIO Client.
Pour personnaliser les clés d'accès/secrète, utilisez des variables d'environnement. Soit sous Windows :
set MINIO_ACCESS_KEY=clepubliquepastropsecrete
set MINIO_SECRET_KEY=clepriveetroptropsecrete!
Des paramètres qui ne seront valables que pour la session en cours. Pour qu'ils perdurent :
setx MINIO_ACCESS_KEY=clepubliquepastropsecrete
setx MINIO_SECRET_KEY=clepriveetroptropsecrete
Sous Linux, utilisez la commande export plutôt que set/setx.
Ces éléments peuvent être passés au serveur via un fichier de configuration, comme d'autres variables : définition de régions, de classes de stockage, des mécaniques de cache, des limites d'accès à l'API, etc. Tout est détaillé sur cette page. Pour mettre en place un accès HTTPS via un certificat TLS il faut suivre cette procédure. Pour la compression, c'est par là.
Le chiffrement côté serveur avec des clés fournies par le client (SSE-C) est également géré. Un serveur simplifié de distribution de clés, KES, est également proposé en open source (licence AGPL v3) depuis peu. Bien entendu, MinIO peut être lancé comme un service au démarrage de la machine, sans avoir à taper des commandes dans un terminal.
Protéger les données avec des blocs de parité
La gestion des codes d'effacement (erasure code via Reed-Solomon) est l'une des fonctionnalités intéressantes de ce serveur. Elle est complétée par une protection contre la dégradation des données (Bit Rot) via HighwayHash.
À la manière d'un RAID 5 ou 6 cela permet de découper les données en blocs, répartis sur les différentes unités de stockage, avec un calcul de blocs de parité permettant une recomposition et une restauration en cas de problème. La contrepartie est que les blocs de parité occupent de l'espace.
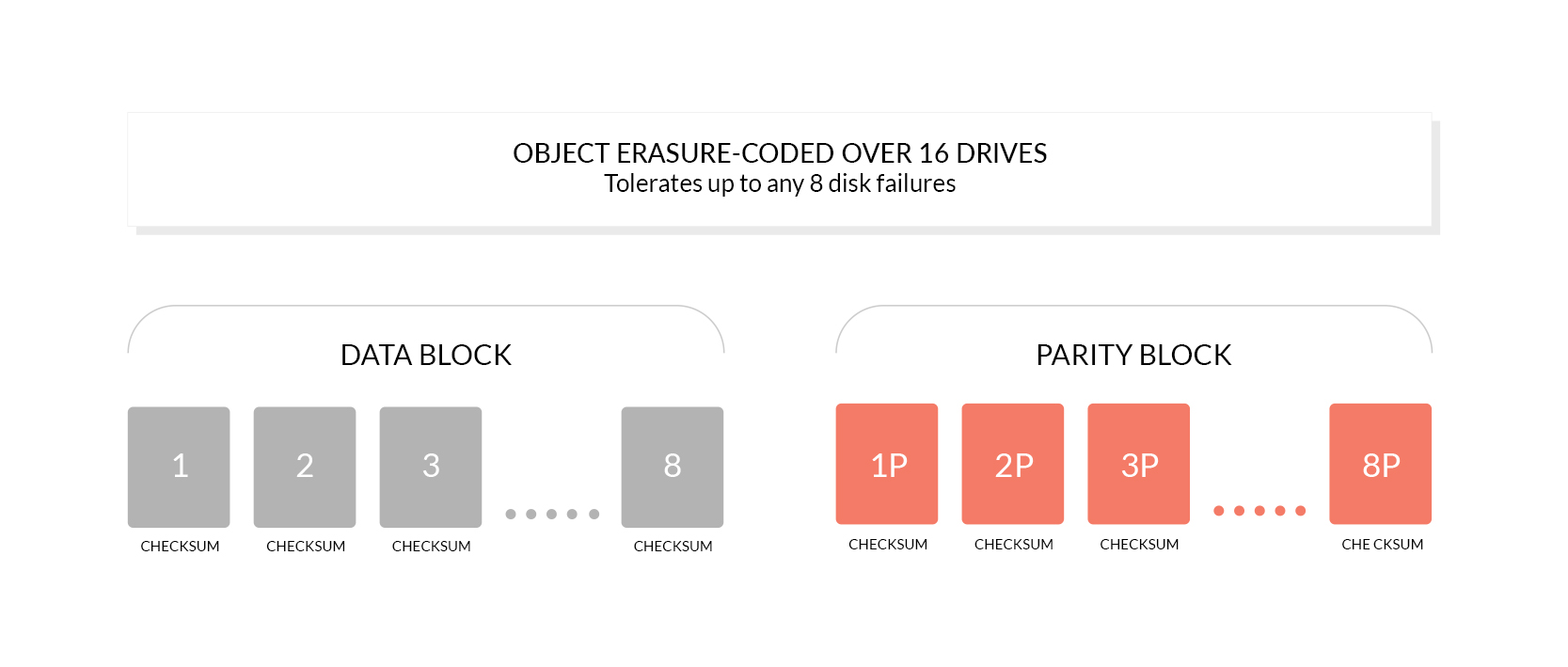
Par défaut il y a autant de blocs de données que de parité
Cette protection se veut plus élevée que du RAID 5/6 la moitié des périphériques pouvant être défaillants sans qu'aucune donnée ne soit perdue avec les paramètres par défaut. Sur 4 disques durs de 4 To, vous ne pourrez donc pas stocker 16 To de données mais 8 To. Il y a ainsi autant de blocs de données que de parité, répartis sur l'ensemble des périphériques.
Ce rapport de 1:2 peut bien entendu être modifié (via les classes de stockage et la configuration) et aller jusqu'à cinq blocs de données pour six écrits (et donc un de parité). Les unités de stockages sont organisées en groupes de 4 à 16, il n'est donc pas possible de profiter de cette fonctionnalité avec seulement deux HDD/SSD.
Pour en profiter, rien de plus simple, il suffit d'indiquer différents dossiers à utiliser. Nous avons testé avec notre ProLiant Microserver Gen10 Plus de HPE dans lequel nous avons placé quatre HDD. Chacun disposait d'un dossier minio à sa racine devant accueillir les données :
minio.exe server c:\minio d:\minio e:\minio f:\minio
Nous avons copié une ISO de 4,42 Go. Chaque HDD était alors occupé à hauteur de 2,21 Go, soit un total de 8,84 Go :

Notez qu'il est possible d'utiliser une cible iSCSI accessible via le réseau comme périphérique de stockage. Sous Linux, on peut également créer différents points de montages et se simplifier la vie en les différenciant par un numéro à la fin de leur nom. Cela rendra accessible une commande de lancement simplifiée sous cette forme :
minio server /data{1...12}
Une procédure identique peut être utilisée pour différentes instances, comme nous le verrons dans la suite de ce dossier.




Commentaires (32)
Vous devez être abonné pour pouvoir commenter.
Déjà abonné ? Se connecter
Abonnez-vousLe 03/06/2020 à 08h57
cool, c’est intéressant…
et coté perfs, ça donne quoi vis-à-vis de S3 ?
Le 03/06/2020 à 09h44
Bah ça dépend du serveur que tu mets derrière " />
" />
Le 03/06/2020 à 10h05
comment on fait quand on a pas un switch 100gbps à la maison ? " />
" />
Le 03/06/2020 à 10h23
Tu fais pareil
Le 03/06/2020 à 10h31
Merci pour cette découverte, pour moi qui cherchait à redonder des données à travers internet entre mon serveur et un NAS prochainement existant.
S’en va tester avec Veeam
Le 03/06/2020 à 10h37
Le 03/06/2020 à 11h22
D’ailleurs je n’en parle pas dans ce papier mais MinIO peut faire gateway pour certains services
Le 03/06/2020 à 12h27
Ma question va peut être paraître bizarre, mais il a des surcouches ou passerelles pour s’interfacer avec de la gestion d’accès type CIFS / NFS ?
Le 03/06/2020 à 12h44
Le 03/06/2020 à 12h56
Le 03/06/2020 à 13h03
Pour ma part, je l’utilise en container, dans kubernetes, en production chez plusieurs clients, ça marche assez bien. En deux ans, MinIO est passé de ‘assez bien pour un lab’ à ‘robuste en prod’
Sinon, pour les perfshttps://blocksandfiles.com/2019/07/24/minio-object-storage-benchmarks/
Le 03/06/2020 à 14h51
Le 03/06/2020 à 15h49
Purement théorique, admettons que l’on préfère de l’objet pour le stockage et pour profiter de certains aspect positif, mais que l’on veuille rester compatible avec des clients qui ne savent que consommer du NFS ou SMB/CIFS. Ça serait possible ?
Le 03/06/2020 à 16h18
Ah, ok, dans ce sens… alors il y a S3FS, mais ça devient un peu lourd (je n’ai jamais testé NFS ou Samba avec S3FS en back-end).
Dans l’ensemble, curl est un très bon client, disponible sur un tas de plateformes.
Je pensais avec ton message précédent que tu voulais pouvoir appliquer les acl’s de l’OS hôte au niveau des droits S3.
Le 03/06/2020 à 18h00
Là aussi ça dépend, tu veux accéder aux mêmes fichiers par ce biais ? Une solution peut être d’utiliser HybridMount chez QNAP par exemple qui permet de monter un service S3 comme un périphérique local (ou des solutions à la S3FS par exemple). De mon point de vue, je vois ce que tu veux faire mais je ne pense pas que CIFS/NFS soit le meilleur moyen, du coup si tu as le détail du besoin concret, je suis preneur " />
" />
Le 03/06/2020 à 20h25
Le 04/06/2020 à 06h16
Après, n’oubliez pas de voir une couche S3 comme un “fournisseur de stockage” “comme un autre”. Du coup un nombre croissant de services peuvent l’attaquer directement sans passer par des couches classiques (partages réseaux, montages…)
par exemple, testé avec succès avec SeaFile, et ça a l’air d’être
possible chez son “concurrent” NextCloud, et surement d’autres de la
même catégorie.
Le 04/06/2020 à 06h47
Super article David ! J’apprécie vraiment tes derniers articles orientés dev, ce qui me fait remarquer qu’on n’a pas des masses de ressources en français dans ce domaine qui ne soit pas de la doc purement technique (quand elle est traduite). Merci pour ça.
Et l’article me fait découvrir le serveur MinIO que je n’imaginais pas aussi simple. Vraiment cool pour un environnement de dev ou même pour redonder du stockage perso sans trop prise de tête.
Le 04/06/2020 à 07h16
Bah après via internet ou pas c’est à toi de voir, ça n’est pas plus risqué qu’exposer un autre service.
Le 04/06/2020 à 19h23
Ca fait plusieurs articles qui parlent de stockage objet… mais malgré les avoir lu, je n’ai toujours pas compris de quoi il s’agit.
Par rapport à un fichier, c’est quoi un objet ? Parce que au final, ce sont bien des fichiers qu’on stocke !
Le 05/06/2020 à 00h11
Bonjour !
Ca serait interessant d’avoir un article sur Storj (https://storj.io/)
Stockage decentralise, compatible S3, il est meme possible d’etre un hebergeur contre remuneration apparement.
Le 05/06/2020 à 05h11
Regarde au début de l’article, il y a trois liens, le premier devrait t’intéresser, on a justement écrit ça pour ça ;)
Le 05/06/2020 à 06h49
Le 05/06/2020 à 07h22
En effet, je n’avais pas lu cet article sur IN-HW, merci !
Le 05/06/2020 à 07h37
“Edit” du post précédent : Ok, j’ai compris maintenant.
Je ne vois pas l’utilité pour un usage perso, ni dans mon métier, mais je comprends bien l’intérêt d’un tel système de stockage pour ceux qui manipulent des grandes quantités de données hétérogènes.
Le 05/06/2020 à 08h54
Vraiment mille mercis pour ce genre d’articles. Je suis satisfait d’être abonné !
Le 05/06/2020 à 09h44
Le 05/06/2020 à 11h47
Pas de besoin concret, encore une fois c’est purement théorique. Food for thought comme ils disent :p
En gros comment marier du stockage objet qui a l’air d’avoir plein d’avantage mais l’utiliser dans un contexte plutôt d’usage perso ou PME qui en général utilise des PC ou autres appareils qui sont nativement compatibles SMB/CIFS mais qui ne savent pas faire de points de montage S3 par défaut.
Un exemple tout bête pour un usage perso, mais sur Kodi ou android on peut accéder à du SMB nativement, mais pas beaucoup plus.
Le 05/06/2020 à 14h12
Faut aller plutôt regarder du côté des papiers iSCSI là du coup " />
" />
Le 05/06/2020 à 14h52
Je n’y connais (encore) rien à S3 mais quand je vois “compatible S3”, je me demande toujours ce que ça inclus maintenant. Car j’ai voulu faire de l’object lock chez Scaleway et ils m’ont dit que leur service n’était pas encore compatible (sans roadmap).
Le 05/06/2020 à 16h27
Oui ça reste le souci, la compatibilité est toujours partielle, mais en général documenté. Chez Scaleway tu as le détail ici
Le 08/06/2020 à 09h36