NVIDIA annonce DLSS 2.3, le SDK Image Scaling open source et son outil de comparaison ICAT
Qui le cherche, le trouve

Face à la concurrence qui lui cherche des problèmes autour de son DLSS, NVIDIA réplique. L'entreprise met en avant la version 2.3 de son outil, facilite l'accès à un upscaling basique, ouvert et largement compatible, publiant en parallèle un outil de comparaison de la qualité de captures d'images et de vidéos.
Avec l'architecture Turing lancée en 2018, NVIDIA a lancé une fonctionnalité qui a su conquérir les joueurs et les développeurs (après des débuts difficiles) : le Deep Learning Super Sampling (DLSS). Pour faire simple, il s'agit de calculer une image dans une définition inférieure à celle de l'écran, puis de l'agrandir à l'aide « de l'IA ».
NVIDIA et DLSS : un précurseur, sous pression de la concurrence
Plus concrètement, NVIDIA entraine constamment un réseau de neurones à effectuer cette opération jusqu'à obtenir une image presque parfaite, parfois même meilleure que l'originale (moins de flou, d'effet d'escalier, etc.). C'est le fruit de cet entrainement qui est ensuite utilisé pour être appliqué dans les jeux.
Cette solution, qui n'est activable que si vous disposez d'une GeForce RTX équipée de Tensor Cores, qui n'a pour le moment pas été égalée. AMD a mis trois ans à aboutir à son FSR, une solution d'upscaling efficace et open source mais classique. Elle a l'avantage d'être largement compatible mais offre un rendu moindre en termes de qualité.
- FidelityFX Super Resolution (FSR) : utilisez la solution d'AMD pour améliorer n'importe quelle image
Intel, avec ses GPU ARC Alchemist, promet un XeSS reposant sur un dispositif similaire à NVIDIA, là aussi open source. Mais pour le moment, nous n'avons eu droit qu'à des promesses et des vidéos. Il faudra certainement attendre le lancement des premières cartes d'ici février/mars prochain pour avoir enfin droit à du concret.
Avec cette concurrence qui monte en puissance, NVIDIA a compris qu'il fallait passer la seconde. Depuis quelques mois, il a multiplié les partenariats et intégrations de DLSS dans les jeux (130 désormais). Cette solution nécessite en effet une implémentation en profondeur, exploitant des images antérieures à celle calculée pour affiner son résultat. Activable facilement depuis l'Unreal Engine ou Unity, on le trouve dans un nombre croissant de titres.
Aujourd'hui, de nouvelles étapes sont franchies à différents niveaux.


DLSS 2.3 est là
La première est l'annonce de la version 2.3 de DLSS qui apporte des améliorations dans le rendu, notamment « les détails des objets en mouvement, la reconstruction des particules, les images fantômes et la stabilité temporelle ». Les performances sont aussi améliorées promet le constructeur. Plusieurs jeux sont déjà concernés :
- Baldur's Gate 3
- Bright Memory : Infinite
- Cyberpunk 2077 (via un patch prévu ce jour)
- Crysis 2 Remastered
- Crysis 3 Remastered
- Deathloop
- DOOM Eternal
- Farming Simulator 22 (lancé le 22 novembre)
- Grand Theft Auto 3 Definitive Edition
- Grand Theft Auto Vice City Definitive Edition
- Grand Theft Auto San Andreas - Definitive Edition
- Jurassic World Evolution 2
- Marvel's Guardians of the Galaxy
- Rise of the Tomb Raider
- Shadow of the Tomb Raider
- Sword & Fairy 7
D'autres pourront suivre, le SDK DLSS 2.3 étant à disposition des développeurs.
ICAT : un outil pour comparer la qualité d'image (et de vidéo)
NVIDIA faisait face à un problème lors des tests de sa solution : il n'était pas toujours facile de permettre la comparaison d'image par les joueurs, qui ne maitrisent pas toujours GIMP et Photoshop, sans parler des comparaisons sous la forme de vidéos qui sont encore plus complexes à mettre en œuvre.
Son équipe a donc développé un outil dédié : ICAT. NVIDIA indique qu'il « permet de comparer facilement jusqu'à 4 captures d'écran ou vidéos à l'aide de curseurs, d'images côte à côte et de zooms sur les pixels. Alignez les comparaisons dans l'espace et dans le temps, examinez les différences et tirez vos conclusions ».

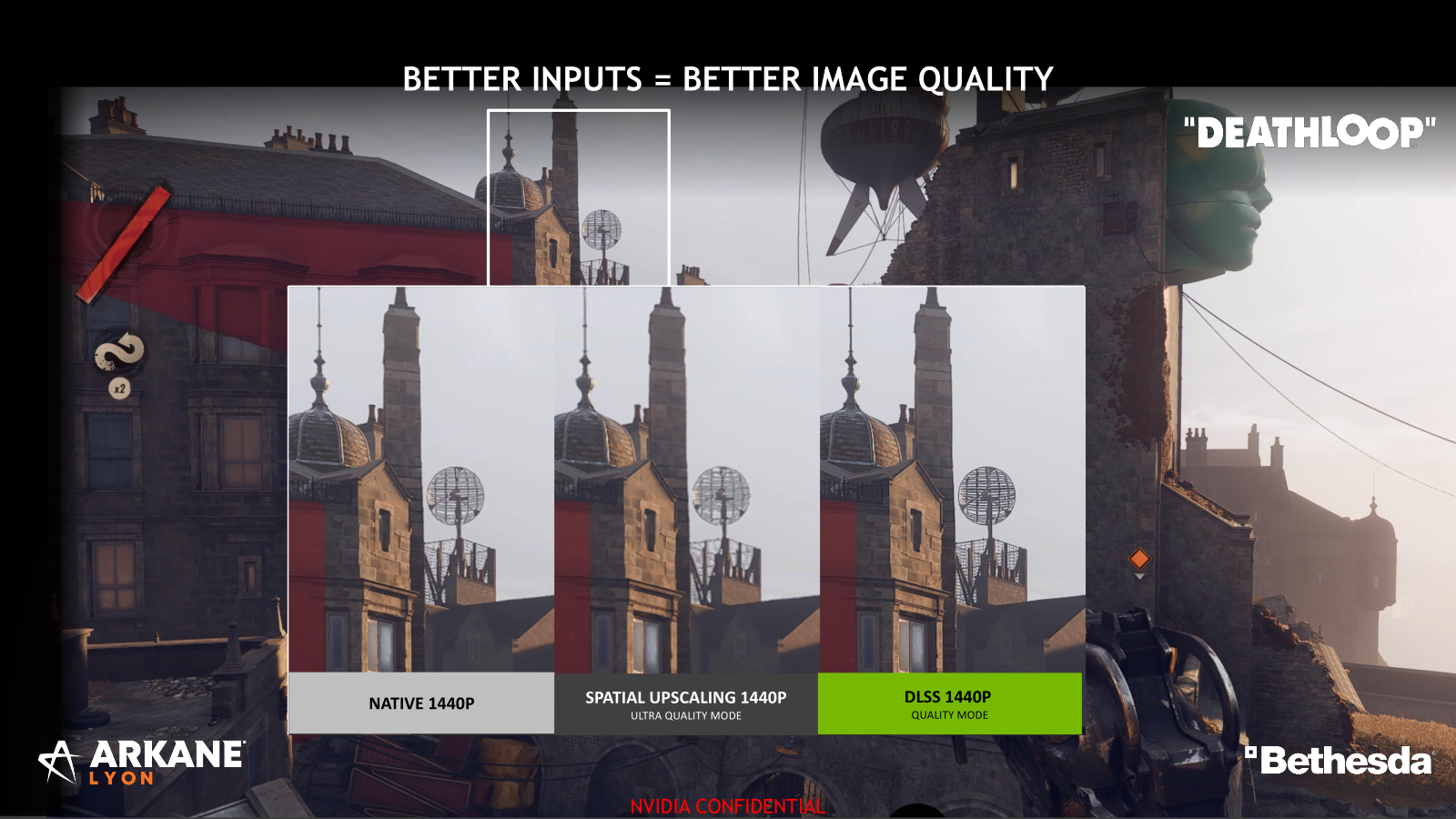

Interrogé, son développeur nous a indiqué qu'il n'était pas open source mais que rien ne s'opposait à son ouverture prochaine, bien au contraire. Facile à prendre en main, il permet de voir rapidement la différence entre deux réglages et nous permettra de partager des captures brutes, les lecteurs pouvant se faire leur avis par exemple.
Bien entendu, il peut être utilisé sur n'importe quelle machine, quelle que soit sa carte graphique.
Image Scaling intégré à GFE, avec un SDK open source
Mais pour montrer tout l'intérêt de DLSS, encore fallait-il que NVIDIA propose un Super Sampling classique, à la manière du FSR d'AMD, en complément de DLSS. « C'est déjà le cas avec notre Image Upscaling » nous a indiqué le constructeur, qui admet néanmoins que la fonctionnalité méritait d'être peaufinée et mieux mise en avant.
Avec les pilotes mis en ligne ce jour ce sera le cas. Il bénéficie d'une mise à jour de son algorithme qui « utilise un filtre 6 points avec 4 filtres de mise à l'échelle directionnelle et d'accentuation adaptative pour améliorer les performances. Il accentue et met à l'échelle en un seul passage » précise le constructeur.
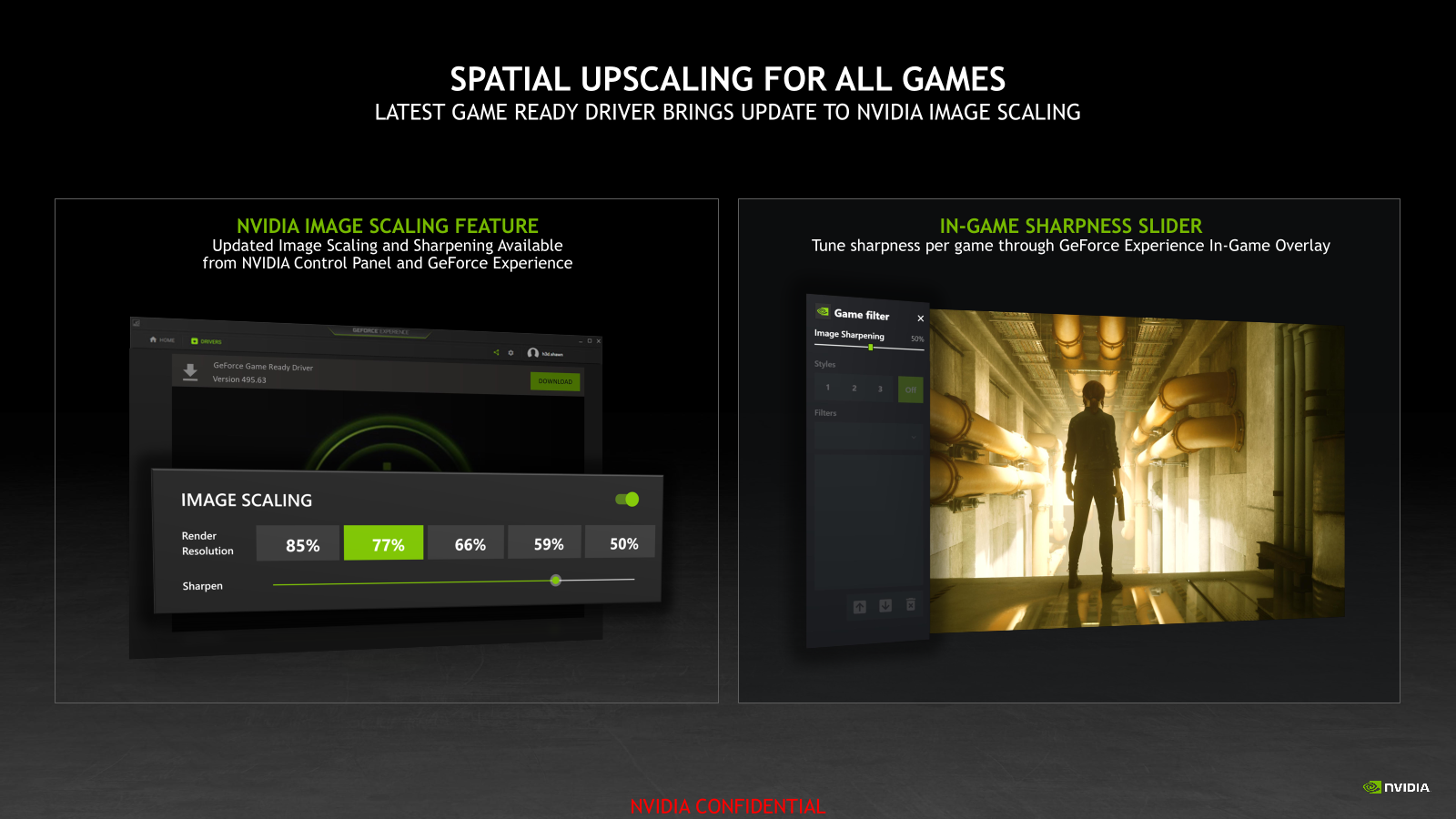

Malheureusement, contrairement à FSR, il ne peut pas (encore ?) être utilisé sous la forme d'une application CLI sur n'importe quelle image. Un SDK open source (licence MIT) est néanmoins proposé aux développeurs pour qu'ils s'en saisissent et l'intègre directement dans les paramètres de leurs jeux en complément de DLSS et/ou de FSR.
Upscaling classique oblige, cette fonctionnalité n'est pas limitée aux GeForce de NVIDIA et pourra donc être utilisée même sur d'autres GPU si elle est activée dans les jeux. Sinon, elle est accessible depuis le panneau de configuration et l'overlay de GeForce Experience, ce qui sera le plus simple en pratique.


Commentaires (27)
Vous devez être abonné pour pouvoir commenter.
Déjà abonné ? Se connecter
Abonnez-vousLe 16/11/2021 à 14h05
PS : certains des liens ne sont pas encore actif, ça va venir
Le 16/11/2021 à 14h11
Pour ceux que ça intéresse voici un exemple du DLSS 5.0 : YouTube
YouTube
Le 16/11/2021 à 15h09
Je regrette de ne pas avoir de CG qui me permette de profiter de cette magie (faudrait déjà que j’ai un PC fixe).
Le 16/11/2021 à 15h18
Bluffant…
Le 16/11/2021 à 15h19
On peut faire tourner cette techno sur les premiers Pixar ?
Le 16/11/2021 à 15h26
J’avais tendance à ne pas utiliser DLSS lorsqu’il était en 1.x mais depuis la 2.0 je trouve cette technologie pertinente : elle me permet souvent de passer sur la résolution au-dessus tout en conservant un bon niveau de performance.
Par contre je n’ose pas imaginer la complexité qui se cache derrière cette techno…
Le 16/11/2021 à 15h26
Non seulement c’est bluffant mais en plus il faut bien comprendre que les deux moteurs ne fonctionnent pas de concert. Tu peut donc t’attendre à 10 fois mieux quand le moteur de rendu 3d sera optimisé pour ce genre d’ia.
Le 16/11/2021 à 15h32
Il y a pas si longtemps on se marrait bien devant les séries “d’experts” qui augmentent la résolution des caméras de surveillance ^^
Le 16/11/2021 à 16h02
Attention à un biais tout de même : ça reste de l’IA, elle “devine” les détails (d’où le terme inférence). D’une certaine manière, elle les invente aussi. Du coup pour de l’usage trivial ça n’est pas forcément un problème. Pour de la vidéo surveillance et de la lecture de plaque par exemple, c’est autre chose
Le 16/11/2021 à 16h03
Et ça ne serait sûrement pas valable, dans une enquête tu veux une “vraie” personne, or avec ça la “personne” n’existe pas réellement, et tant qu’on ne pourra pas “prouver” la marge d’erreur ça a peu de chance de servir dans une chasse à l’homme.
Le coup de la plaque d’immatriculation, si l’IA te met une image net avec un V à la place d’un U et que tu vas arrêter la mauvaise personne tu fais quoi ?
Le 16/11/2021 à 16h52
Dsl, mais ça n’arrive toujours pas à la cheville de Blade Runner et de sa “photo” 3D a angle de vue libre et interpolation.
Le 16/11/2021 à 16h59
Note que NVIDIA a déjà des modèles pour extrapoler le changement d’angle de visage depuis une capture 2D (qui est utilisé pour “redresser” dans une vidéo conférence par exemple)
Le 16/11/2021 à 17h13
Si seulement ils pouvaient utiliser le DLSS sur leur fréquence de production de GPU ^^
Le 16/11/2021 à 17h26
Est-ce que l’on sait si des technologies comme le DLSS sont envisagée pour le cloud gaming/computing avec l’upscaling coté client?
Je verrais bien Shadow streamer l’image basse résolution du jeu et utiliser une carte graphique spécialisée juste pour de l’inférence (e.g., Coral) upscaller tout ça.
Le 16/11/2021 à 17h29
À ce que j’en comprend le dlss utilise les données 3D pour faire ses calculs, pas l’image finie, c’est plus compliqué qu’un upscale, c’est pour ça que ça ne peut pas fonctionner sur une photo par exemple
Le 16/11/2021 à 17h39
Tu peux déjà le faire via la Shield non ?
Le 16/11/2021 à 20h23
L’ia perçois des choses que nous ne pouvons percevoir même avec beaucoup d’entrainement. Même 4 pixel il est possible de déterminer si c’est un V ou un U. Les pixels n’auront pas tous la même valeur.
Portrait robot ?
Le 16/11/2021 à 20h35
Petite mise à jours : YouTube
YouTube
Le 16/11/2021 à 20h39
Pour résumer comment ça fonctionne Il fait comme un artiste à qui on donne une image sur un timbre poste et qu’on lui demande d’en faire un poster A3. C’est un réseau de neurone artificiel (un algo d’apprentissage automatique), il va analyser l’image en entrée, va essayer de prédire ce qu’il voit, et va ensuite dessiner une nouvelle image plus grande collant à ce qu’il a compris de l’image et en rajoutant les détails qu’il lui semble le plus probable.
Pour le DLSS, niveau techno, on est sur ce qui se fait actuellement au niveau des réseaux de neurone artificiel. Ce qui est assez balaise, c’est que c’est fait en temps direct, c’est donc un réseau de neurones surement assez réduit et très optimisé. NVidia a sa petite recette, je n’ai pas trouver beaucoup d’info. Tout ce que je sais c’est que depuis DLSS 2.0, ils utilisent des infos des frames précédentes (ce qui me fait penser au TAA/temporal anti aliasing).
Sur le Shield, ce n’est pas du DLSS à proprement parlé, mais un upscaling adapté à un flux vidéo. A priori, c’est plus fait pour une utilisation général “vidéo” que pour les jeux. On n’est pas exactement sur les même objectifs ni les même les même moyens (DLSS a accès à des données intermédiaires et non compressé).
On peut imaginer un auto-encoder qui transmet un flux compressé par un réseau de neurone (l’encoder) et décompresser de l’autre par un autre réseau de neurone (le decoder). Mais je n’ai pas vu une tel utilisation de l’auto-encoder.
Mais sinon, je pense que la qualité de la donnée doit jouer un rôle important, et dans le cas d’une vidéo, malheureusement, c’est compressé avec perte de donnée et balancer un truc non compressé, ça perdrait tout l’intérêt.
Le 17/11/2021 à 04h07
Oui, un upscaling exploitant un modèle, appliqué en bout de chaîne et donc sur l’affichage à l’écran, soit exactement ce qui était demandé dans le commentaire auquel je répondais ;)
Le 17/11/2021 à 08h40
Oui, je ne dis pas que ça ne servira pas, ça sera très utile, mais je ne pense pas que ce soit une “bonne idée” de considéré que l’image de sortie est “LA” personne de l’image d’entrée…
Un portrait robot ça sert à retrouver “plusieurs” personnes ayants ce profil, puis enquêter dessus pour déterminer si le bon est dedans et qui est-ce, c’est tout le risque avec des images trop belle/net et quand on arrive plus faire la différence entre une image “truquée” et la “réalité”.
Le 17/11/2021 à 09h12
J’aime bien, ça me rappelle quand même le traitement vidéo appliqué par des TV plates Thomson au début de ce siècle. Pour avoir une plus belle image sur les DVD en grand écran, elle ajoutait du bruit. Un grain. Et ça marchait: on avait l’impression de voir plus de détails!
Non. L’IA est entraînée et extrapole à partir de ce qu’elle connaît. Donc oui, l’IA peut avoir plus d’expérience qu’un individu sur un traitement spécial. Non, elle n’a pas toujours juste et peut largement se tromper.
Le coup des lunettes sur ta vidéo, ça marche bien, mais:
1 - les lunettes extrapolées sont inventées, doc il ne faut pas s’y fier! La mode peut avoir changé et les lunettes être totalement différentes
2 - si on part d’une image 64x64, un petit maquillage bien placé sera extrapolé (des sourcils, un gros nez, …)
Le 17/11/2021 à 13h11
Surtout il ne faut jamais oublier un truc sur les démos : ça ne vaut rien tant que l’on a pas soi-même testé sur des données qui ne font pas partie de l’entrainement. Parce que montrer un résultat époustouflant quand le modèle a été entrainé sur la photo utilisée, c’est facile. Sur une photo random… ;)
Le 17/11/2021 à 14h17
Sur une photo différente du set le résultat sera limité. Forcément.
Mais cela n’enlève pas la pertinence d’utiliser ces outils pour appuyer l’analyse manuelle et faire la manip de rendu (sur photoshop ça marche pas trop mal, la CAO globalement a fait d’énormes progrès avec ces technos).
Il y a aussi des cas où la base d’entrainement peut être complète et les apprentissages mixés, comme pour la reconnaissance faciale… ou le cas du DLSS qui justement a accès à des bouts probants de la scène 3D avant d’envoyer l’image.
Pour moi la limite c’est qui a travaillé et prend sa responsabilité car si on se contente de ne plus rien contrôler en personne on va vite s’ennuyer dans cyberpunk 2084. Les metteurs en scène ne serviront plus à rien, les experts non plus et l’IA gouvernera le monde et…
Le 17/11/2021 à 15h15
Comme déjà dis, les algos d’apprentissage automatique vont générer ce qu’il a estimer de plus probable. Donc l’image générée sera l’image la plus probable selon l’outil (cela peut changer selon le modèle utilisé) et les données d’apprentissages (on connais déjà bien les biais de la base d’apprentissage).
Dans ton exemple, il va peut être estimer que c’est un V à 50%, un U à 35%, un O à 8% (techniquement, il calcule plus un score)…. comme c’est le V qui est le plus probable, il mise tout sur le V quand bien même il y a une marge d’erreur importante.
Il faut voir ça comme une interprétation statistique. Ce n’est pas la réalité, c’est juste ce qui parait le plus probable.
Je pinaille peut-être un peu. DLSS et “AI-Enhanced” uspcaling de la Shield, même si c’est tout deux de l’upscaling, n’utilisent pas les même donnée et n’ont pas totalement le même but.
Le DLSS a pour but de produire un rendu vidéo 3D à partir des donnée d’un rendu 3D de plus faible résolution.
L’IA-enhanced Upscaling quant-à lui va augmenter la résolution d’un flux vidéo et NVidia met plus en avant l’utilisation de cette techno pour les film et les service de VOD.
Si j’en reviens au commentaire d’origine, même si la solution qu’il propose s’approche de la seconde (upscaling d’un flux vidéo), son but était plutôt la première (upscaling d’un rendu vidéo 3D) et plus exactement ici on est même sur une 3ième solution, un rendu vidéo 3D à partir d’un flux compressé.
Le 17/11/2021 à 15h42
Tu ne pinailles pas, tu mets trop de côté la question de départ. L’idée était de savoir si on pouvait appliquer un DLSS like en bout de chaine. C’est ce que fait le mode AI de la Shield.
Et comme elle le fait en bout de chaine, elle le fait sans accès aux données temporelles ou qui seraient internes à un moteur de rendu par exemple. Ce n’est pas juste deux upscaling, tous deux utilisent un modèle d’IA. Mais ils le font à un niveau différent, avec donc des données différentes (mais c’est ce qui était demandé).
Que ce soit de la vidéo ou un jeu n’y change rien (c’est une succession d’images, donc la même chose). Pour un modèle d’IA, ce qui fait la différence c’est la typologie des images. Upscaler un film, une série animée, un jeu réaliste ou du Minecraft, c’est autant de cas différents à maîtriser.
Le 22/11/2021 à 12h29
Punaise. Merci pour l’info, je ne savais pas que c’était possible.