À Bordeaux, IA et productivité au cœur des discussions chez les développeurs
IA qu'à demander

Lors de la conférence BDX I/O à Bordeaux, nous sommes allés à la rencontre de développeurs pour les interroger sur leur appréciation de l’IA. Dans cette première partie, nous nous intéressons aux gains de productivité et à ce que l’utilisation de modules comme Copilot de GitHub peut impliquer dans leur quotidien.
Depuis plusieurs années, l’intelligence artificielle est omniprésente. Nous la questionnons souvent, car en dépit d’avantages plus ou moins évidents et d’une célébration presque continue de sa puissance, ses usages laissent de nombreuses questions en suspens. C’est d’autant plus vrai que la thématique du numérique responsable se fait plus prégnante, face à un entrainement des modèles d’IA générative engloutissant des quantités faramineuses d’énergie.
Aussi la BDX I/O, qui s’est tenue le 8 novembre à Bordeaux, était-elle une excellente occasion d’aller faire un état des lieux : à quel point l’IA est-elle aujourd’hui utilisée par les développeurs ? Au-delà de l’intérêt qu’ils y portent dans leur production quotidienne, son utilisation leur pose-t-elle question ?

« L’IA ? Bien sûr ! »
Dans l’amphithéâtre A du Palais des Congrès de Bordeaux, le ton est rapidement donné. Les conversations perçues çà et là sont pratiquement toutes axées sur l’intelligence artificielle. Beaucoup disent s’en servir. D’autres indiquent que ce n’est pas encore le cas pour diverses raisons, parfois par manque de temps, plus rarement pour des questions de maitrise : « Pas encore, je préfère écrire mon propre code ». Mais dans presque toutes les conversations, la question de la productivité est centrale. Plusieurs personnes ont ajouté que leur société réfléchissait à la question.
Sitôt la présentation de l'évènement terminée, Marie-Alice Blete, ingénieure et première intervenante, monte sur scène. Elle rend compte de son expérience et indique avoir poussé l’utilisation du Copilot de GitHub dans son ancienne entreprise. La demande avait été accueillie avec un certain scepticisme, jusqu’à ce que de premières données chiffrées viennent rendre compte du gain de productivité.
Au travers des informations données par l’ingénieure pendant la présentation, on apprend ainsi que le gain moyen observé est de 26 %. Un chiffre conséquent, mais qui ne suffit pas. Cette question de la productivité est à mettre en parallèle d’autres aspects, dont la qualité, avec une légère baisse par exemple des compilations réussies.


Ce gain de productivité s’affiche surtout dans les suggestions de code. Marie-Alice Blete en profite d’ailleurs pour questionner la récente affirmation de Sundar Pichai, CEO de Google, selon lequel 25 % du nouveau code dans la multinationale serait généré par l’IA. Mais parle-t-on de code réellement neuf ou plus simplement d’une « super suggestion » ? L’ingénieure penche pour la seconde hypothèse. Elle ajoute – et c’est un avis que nous avons largement entendu au cours de la journée – que l’IA générative est surtout très forte pour accélérer les tâches rébarbatives.
Elle pointe également des cas spécifiques d’utilisation où l’IA montre tout son potentiel, dont la RAG (Retrieval Augmented Generation). La technique sert notamment à entrainer des modèles sur une documentation particulière, afin que l’on puisse ensuite poster des questions très précises sur celle-ci.
Accompagner le changement
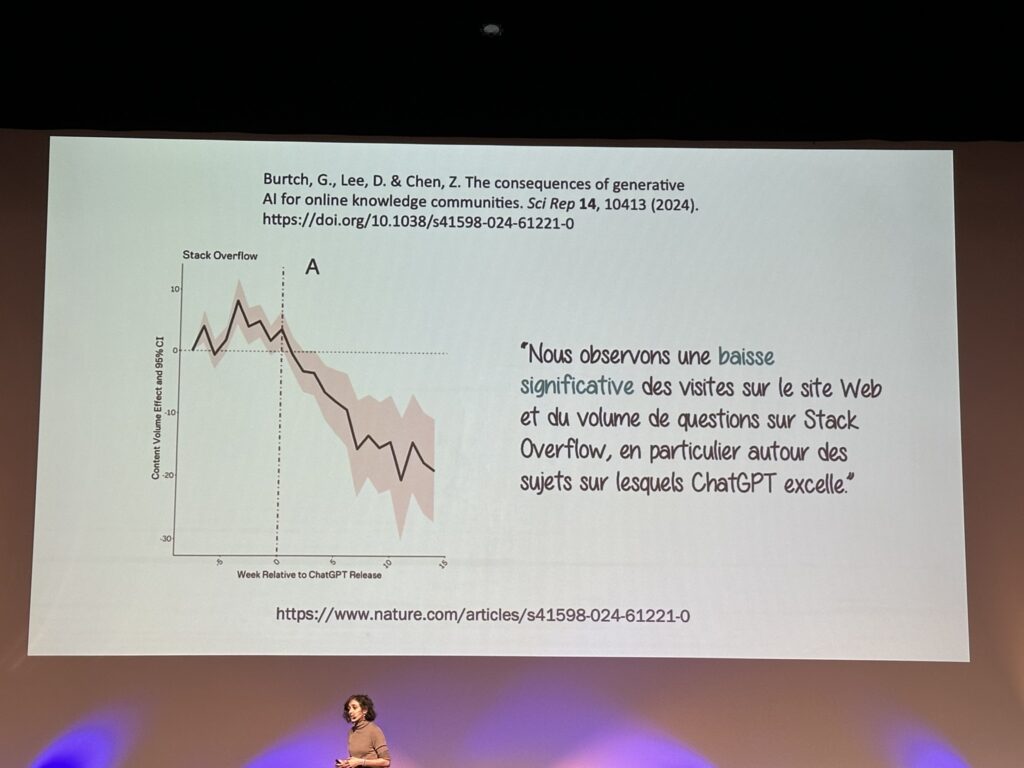
Le point de vue de Marie-Alice Blete est que l’IA est désormais là et qu’elle ne s’en ira pas. En revanche, elle nuance cette révolution par un certain nombre d’interrogations. Certaines sont provoquées par l’évolution des pratiques. Par exemple, une désertion grandissante de Stack Overflow, les développeurs se tournant beaucoup plus volontiers vers l’IA quand ils ont une question, alimentant un « chacun dans son coin avec son Copilot ». Cela pose également la question de l’entrainement des modèles sur de nouvelles techniques, Stack Overflow ayant largement servi à alimenter l’IA actuelle. Si les développeurs partagent moins leur travail, il existe en effet un risque.
Ce changement pose également la question d’une tendance égalisatrice. Comme on l’a vu dans le cas des faux positifs dans certains devoirs rendus par les étudiants, les IA proposent à peu près toujours le même type de solution, comme c’est le cas dans les recommandations d’écriture. Dans le cas du code, Copilot fait également une « moyenne » des solutions trouvées par les développeurs à un certain type de problème et la propose donc quand on y est confronté.
Marie-Alice Blete rappelle cependant que l’IA reste une technologie nouvelle, dont l’évolution est très rapide. Parallèlement, les développeurs s’habituent et il semble prématuré aujourd’hui de définir un axe clair d’évolution. Elle évoque ainsi une « réalité moins magique que prévu » et plaide pour une approche plus pragmatique. L’ingénieure ajoute que de nombreux projets aujourd’hui sont bâtis sur des technologies qui n’existaient pas il y a deux ans.
Un risque d’uniformisation des pratiques ?
Nous nous sommes entretenus avec Marie-Alice Blete sur plusieurs sujets, dont le risque d’uniformisation des pratiques. A-t-elle déjà observé ce phénomène ? « Non, je pense que ça se verra plus tard. Les recommandations que l’on voit aujourd’hui sont basées sur des données d’entrainement qui ont déjà plusieurs mois ou années », explique l’ingénieure. En tout cas pour le code.
Dans d’autres domaines, on pourrait voir arriver le problème plus rapidement : « On pourrait voir ça bientôt dans les images. Aujourd’hui, quand on fait une recherche dans Google Images, on trouve un nombre croissant d’images générées par l’IA. Et on sait que les prochains entrainements des modèles sur les images risquent de reprendre celles déjà générées par IA. On risque donc d’avoir une vraie perte de qualité », estime Marie-Alice Blete.
Sur les gains de productivité, elle confirme également que l’IA lui fait gagner du temps. Mais lui en fait-elle perdre aussi parfois ? « Globalement, je gagne du temps. Mais c’est vrai que des fois, elle me génère un code complètement faux. C’est plus compliqué quand elle oublie parfois une virgule dans mon code et que je ne m’en rends pas compte. Je teste mon code, ça ne marche pas, je suis obligée de chercher la cause », nous répond l’ingénieure.
On en vient vite à évoquer la supervision : l’IA ne fait véritablement gagner du temps que si l’on est capable de vérifier rapidement que le code proposé correspond non seulement à la situation, mais également qu’il est correct. Marie-Alice Blete nous confirme ainsi avoir observé que les modules d’aide de type Copilot engendrent des difficultés pour les jeunes développeurs, quand le manque de pratique et d’expertise ne permet pas de cerner ce qui est proposé.
Si l’IA l’aide dans son quotidien, elle nous explique aussi qu’elle n’est véritablement efficace que sur de petites parties. « Aujourd’hui, j’ai du mal à imaginer que l’IA puisse prendre le relai sur des projets beaucoup plus importants, parce que le taux d’erreur augmente très vite. Mais il faut rester humble, car il est difficile d’imaginer de quoi l’IA sera capable demain ».
L’IA déjà très présente dans les habitudes
Au travers des multiples conversations durant cette journée, il devenait évident que l’IA était déjà très présente chez les développeurs. Dans l’immense majorité des cas, elle est utilisée comme module de « super suggestion ». Les éléments mis en avant par Marie-Alice Blete dans son intervention se retrouvent ainsi dans presque chaque conversation : oui, l’IA permet de gagner beaucoup de temps sur les tâches répétitives et devient rapidement la source privilégiée de renseignement, devant les sites web classiques.
Interrogés sur des thématiques liés comme le choix de données à l’entrainement, la consommation d’énergie ou encore l’aspect boite noire de la plupart des modèles, quasiment tous les développeurs ont botté en touche.
Dans la prochaine partie, nous verrons que cet aspect éthique, tout particulièrement l’explicabilité, semble loin des considérations actuelles.
Commentaires (12)
Abonnez-vous pour prendre part au débat
Déjà abonné ? Se connecter
Cet article est en accès libre, mais il est le fruit du travail d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles
Profitez d’un média expert et unique
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 21/11/2024 à 11h46
Hâte de lire la prochaine partie, j'ai l'impression qu'il y a de beaux angles morts, en effet.
Le "Fear Of Missing Out" pousse tant le management et les collègues à se ruer là-dessus un peu trop aveuglément, à mon goût. Une fois que la "hype" sera passée, et que les coûts réels seront appliqués, qu'en restera-t-il?
Le 21/11/2024 à 14h05
Le 21/11/2024 à 15h03
Le 22/11/2024 à 16h46
Et pour te trouver une source, je viens de tomber sur ça : https://blog.jetbrains.com/ai/2024/11/jetbrains-ai-assistant-integrates-google-gemini-and-local-llms/
(modèle large hébergé en local, je ne sais pas ce que ça vaut)
Et ce dont je parlais : https://blog.jetbrains.com/blog/2024/04/04/full-line-code-completion-in-jetbrains-ides-all-you-need-to-know/
Le 21/11/2024 à 16h16
Si personne ne partage ses connaissances concernant la résolution de NOUVEAUX problèmes, ceux-ci ne trouveront aucune solution dans les IA.
Et c'est bien la, l'un des principaux problèmes derrière l'IA: elle ne créée rien, elle ne fait que simplifier la démarche de recherche de solutions PARTAGEES par des personnes réelles.
Le 21/11/2024 à 16h35
Pour le premier, c'est l'essence même de l'informatique : le traitement automatique de l'information. L'informatisation a toujours été faite en ce sens et cette techno encore jeune (comme souligné par l'intervenante) est en plein développement.
Le 21/11/2024 à 19h29
Question pour ceux qui utilise l'IA générative pour les aider dans leurs développements : Avec des données d'entrainement "vieilles", avez-vous déjà obtenu des suggestions obsolètes ou ne mettant pas à profit les nouvelles fonctionnalités de votre langage préféré ?
Modifié le 21/11/2024 à 21h04
Même si GitHub enrichi régulièrement le modèle de Copilot, le P (et donc par extension le T) de GPT reste sa grande faiblesse à ce niveau.
Par contre, en mode RAG (analyse de code), il restait pertinent à priori.
Edit : précision importante, l'étude avait été faite à l'époque sur Copilot normal (Chat était seulement annoncé). Celui-ci était basé sur Codex, un LLM basé GPT 3.5 fine-tuned sur du code. Copilot Chat était passé à GPT 4 peu de temps après sa sortie et je suppose qu'il suit les évolutions du LLM d'OpenAI depuis.
Le 22/11/2024 à 09h21
Le 22/11/2024 à 15h21
Le 22/11/2024 à 20h13
Une compilation réussie ne préjuge en rien que le résultat attendu du programme soit celui qui sera produit.
Cela ne préjuge pas non plus que le code sera maintenable et ne coûtera pas plus cher sur la durée faute de facilité à le maintenir.
Je ne comprends toujours pas comment on peut croire qu'un outil qui s'appuie sur des statistiques pour produire du code peut produire du code correct.
Le 26/11/2024 à 17h53
Là où j'ai gagné du temps personnellement, ce n'est pas tant sur la génération de code mais plus sur la partie RAG.
La combinaison indexation sémantique/formattage de réponse est surprenamment efficace quand il s'agit de piocher dans une doc éparpillée/lacunaire pour répondre à des questions concrètes. Des trucs comme "quelles requêtes HTTP sous jacentes sont générées quand on exécute la commande bidule de l'utilitaire truc".
C'est devenu de plus en plus difficile pour moi de trouver des infos pertinentes via google ou stack overflow ou les moteurs locaux basés sur des mots-clefs quand tous les termes sont généraux et quand mon use case est inhabituel, à moins d'avoir du bol et de tomber sur une formulation exacte.
Alors qu'un pipeline RAG bien fichu va sortir la réponse (ou une inférence raisonnable) et ses sources. Faut toujours vérifier, mais ça me prend généralement moins de temps que devoir éplucher doc et code de zero.