On développe et entraine une IA, avec seulement 10 lignes de code !
Vous ne saviez pas quoi faire ce week-end ?

Les IA sont souvent présentées comme des boîtes noires, ce qui est partiellement vrai… et donc aussi partiellement faux. Plutôt que d’ouvrir la boîte et d'essayer de comprendre comment ça marche, prenons le problème à l’envers. Créons notre propre boîte noire intelligence artificielle. Pour y arriver, 10 lignes de code suffisent, même avec des dizaines de neurones et plusieurs couches. On vous détaille le principe, étape par étape.
Après avoir détaillé le fonctionnement d’un neurone artificiel, nous allons en utiliser plusieurs pour créer et entrainer une intelligence artificielle. C’est à la portée de tous, sans avoir besoin de connaissances ou d’installer des programmes en particulier. Une connexion à Internet et un navigateur sont suffisants.
Première étape : un notebook sur Google Colab
Dans le cadre de notre petite démonstration, nous utilisons Google Colab (Colaboratory), un compte Google sera donc nécessaire. Colab permet d’héberger sur les serveurs de Google des notebooks Jupyter. On peut y écrire du code Python et l’exécuter directement depuis son navigateur, sur les serveurs de Google. Le fonctionnement est très simple et vous pouvez aussi utiliser d’autres notebooks si vous le désirez.
Google Colab dispose de tout ce dont nous avons besoin pour nous lancer dans l’intelligence artificielle. Il permet aussi d’exécuter notre code, au choix, sur des CPU, des GPU ou des TPU (Tensor Processing Unit pensés pour l’intelligence artificielle).
Une fois sur le site de Google Colab, cliquez sur « New Notebook » pour arriver sur un notebook vierge où il suffit de copier/coller les lignes de code que nous allons vous donner et expliquer.
Tensorflow, keras et un jeu de données (MNIST)
Remarque très importante pour ce petit tuto : nous allons à peine effleurer le développement d’une intelligence artificielle, mais nous aurons l’occasion de rentrer davantage dans les détails par la suite. On s’est dit que commencer par la partie pratique avant de se pencher sur la théorie (les calculs de matrices, les dérivées…) pourrait vous permettre de directement mettre les mains dans le cambouis et de comprendre, dans les grandes lignes, comment fonctionne une IA.
Bien évidemment, nous allons nous appuyer sur des bibliothèques existantes pour créer notre IA, on ne part pas d’une feuille blanche. Première chose dont nous avons besoin : Tensorflow, un outil open source d'apprentissage automatique développé par Google. Deuxième élément qui va avec le premier : keras, une « API de haut niveau de TensorFlow permettant de créer et d'entraîner des modèles de deep learning ».
Enfin, il nous faut des données, un élément indispensable pour une intelligence artificielle, comme on le répète à longueur d’actu sur les IA. Par défaut, une intelligence artificielle ne sait rien faire. Nous allons en développer une capable de reconnaitre des chiffres de 0 à 9. Il faut donc d’abord lui donner des séries d’images étiquetées, c’est-à-dire avec une légende précisant quel chiffre se trouve dans l’image.
Nous utilisons pour cela la base de données MNIST (Modified ou Mixed National Institute of Standards and Technology). Elle comprend 60 000 images d'apprentissage et 10 000 images de test pour vérifier les performances de son programme. Les images sont en noir et blanc et de petite taille (28 x 28 pixels).
Et si on se lançait ? Trois lignes pour préparer le terrain
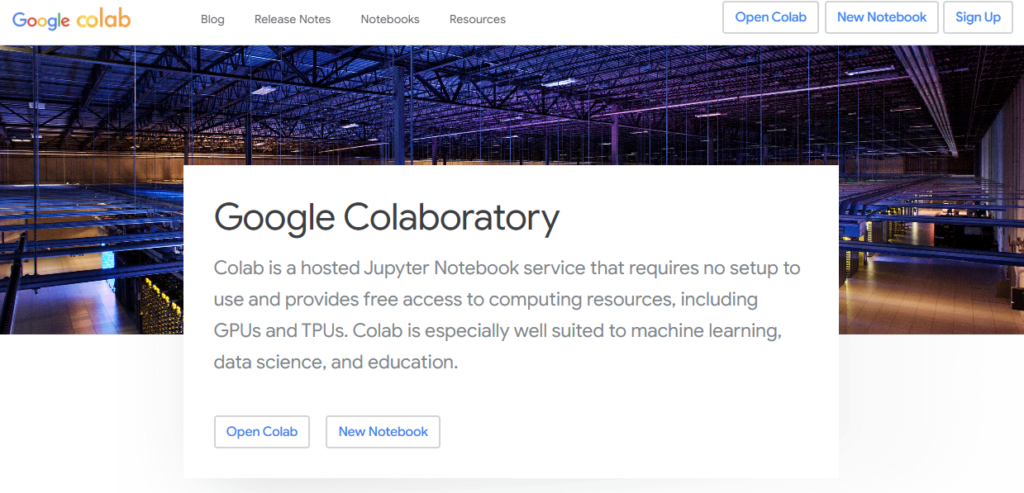
Dans un nouveau notebook de Google Colab, on commence par importer tensorflow dans notre notebook afin de pouvoir l’utiliser (on l’appelle tf pour simplifier le code par la suite). On récupère ensuite keras et le jeu de données MNIST. Les deux sont intégrés à Tensorflow, cela ne prend donc que trois lignes de code :
import tensorflow as tf
from tensorflow import keras
mnist = tf.keras.datasets.mnistUne ligne pour séparer les données test de celles d’entrainement
Les 70 000 images et le chiffre correspondant sont désormais rattachées à la variable « mnist ». Les concepteurs de cette dernière ont bien fait les choses et d’une seule ligne on peut récupérer et séparer les images d’entrainement de celles de test :
(x_train, y_train),(x_test, y_test)= mnist.load_data()Désormais x_train comprend les 60 000 images, y_train le chiffre correspondant à chaque image. X_train comprend donc 60 000 tableaux (array) de 28 x 28 (c’est-à-dire de la taille de l’image, avec une case par pixel) et y_train est un tableau de 60 000 entiers chacun compris entre 0 et 9. Avec x_test et y_test c’est la même chose pour les images de tests, une fois que notre modèle sera entrainé.
On ajoute d’ailleurs quelques lignes bonus (elles ne sont pas nécessaires pour développer notre IA), mais permettent de vérifier qu’on ne raconte pas que des bêtises :
print ('Que contient x_train : ',x_train.shape)
print ('Que contient y_train : ',y_train.shape)
print ('Que contient x_test : ',x_test.shape)
print ('Que contient y_test : ',y_test.shape)Vous pouvez les mettre dans votre notebook, les exécuter, puis les supprimer pour continuer notre tuto, cela n’a pas d’importance. Ce n’est que de l’affichage.
Un peu d’ASCII art pour la route
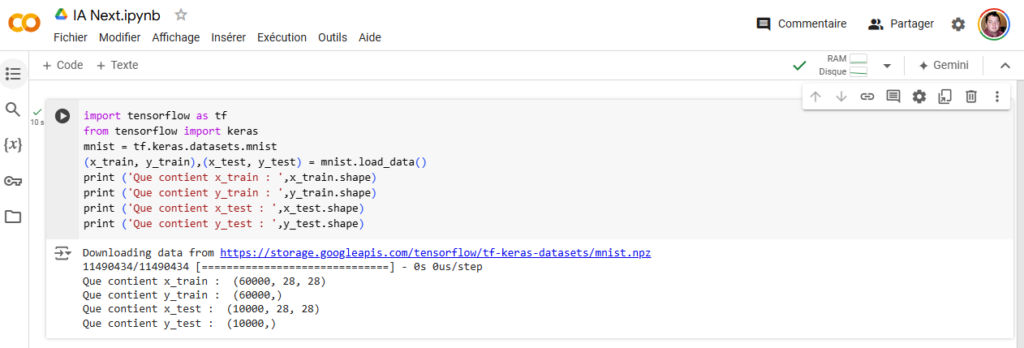
On peut aussi regarder ce qu’il se passe à l’intérieur d’un seul tableau. Deux lignes de code permettent de faire un peu d’ASCII art et de vérifier qu’on ne s’est pas trompé :
print ('Quel est le premier tableau x_train : ',x_test[0])
print ('Quel est le chiffre associé dans la base : ',y_test[0])Pour rappel, les tableaux en informatique commencent parfois/souvent à 0 (enfin ça dépend, les joies du code…) alors qu’un humain débute généralement à 1. Cela ne change rien, mais la variable x_test va de 0 à 59 999 et pas de 1 à 60 000.
Après un peu de remise en page pour un affichage plus agréable à regarder, voici ce qu’on obtient :
Actuellement, le niveau de gris de chaque pixel correspond à un nombre, compris entre 0 et 255, soit 256 valeurs possibles. On pourrait aussi l’écrire sous la forme 2⁸ et ainsi voir que cela correspond à un octet ou huit bits.
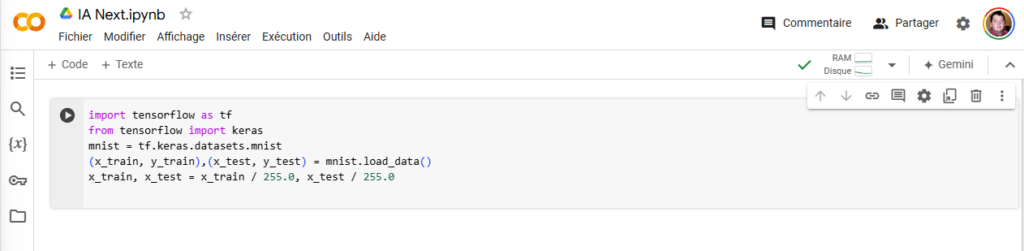
Une ligne de plus pour normaliser les variables
Pour que les systèmes d’entrainement des IA fonctionnent au mieux, il vaut mieux avoir des valeurs entre 0 et 1. Nous allons donc les normaliser, avec une méthode simple et rapide, même si ce n’est pas la plus efficace, mais c’est une autre histoire :
x_train, x_test = x_train / 255.0, x_test / 255.0Dans nos tableaux x_train et x_test on divise simplement le chiffre associé à chaque pixel par 255. Ainsi, chaque valeur du niveau de gris se trouve désormais entre 0 et 1. Si vous déplacez la ligne de code « print ('Quel est le premier tableau x_train : ',x_test[0]) » en dessous de l’étape de normalisation des données, vous verrez que toutes les valeurs sont comprises entre 0 et 1.
On ne dirait pas, mais toute la phase préparatoire est terminée. On est déjà à la moitié du chemin.
Créons notre modèle avec deux couches de neurones
Passons maintenant à la création de notre modèle d’entrainement pour notre intelligence artificielle. Cela ne demande qu’une seule ligne de code. Le mode séquentiel signifie que toutes les couches sont reliées entre elles de manière séquentielle. Chaque couche, pour rappel, n’a pas obligatoirement le même nombre de neurones, mais tous les neurones d’une couche sont reliés aux neurones de la couche précédente.
model = keras.models.Sequential()On ajoute ensuite notre première couche de neurones qui fait office d’entrée pour notre modèle. La commande Flatten permet de remettre l’image à plat : au lieu d’avoir un tableau de 28 x 28 on a une seule ligne de 784 éléments (28 x 28 = 784).
model.add(keras.layers.Flatten(input_shape=[28,28]))Ensuite, nous ajoutons une couche de 25 neurones avec la fonction d’activation « relu ». Si vous êtes un peu perdu, on vous conseille une lecture de notre article sur les neurones artificiels. Et soyons joueur, ajoutons une seconde couche de 10 neurones qui sera la dernière. Le nombre de neurones en sortie (10) n’est pas choisi au hasard : il correspond au nombre de cas à identifier pour notre IA : les chiffres de 0 à 9 (et donc 10 possibilités).
model.add(keras.layers.Dense(25, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))Pour la dernière couche, on utilise la fonction d’activation « softmax », parfaitement adaptée puisqu’elle donne un résultat entre 0 et 1, avec en plus la somme de toutes les sorties égale à 1. Notre IA sortira donc la probabilité qu’une image corresponde à un chiffre. On prendra simplement la sortie la plus élevée comme résultat probable.
Le détail de notre modèle et son nombre de paramètres
Vous savez quoi ? Notre modèle est terminé. Avant de passer à la phase d’entrainement, une dernière vérification avec la commande suivante :
model.summary()Nous avons ainsi un résumé de notre modèle : une première couche d’entrée mise à plat (flatten) avec 784 valeurs, ensuite une couche dense de 25 neurones avec… 19 625 paramètres. Chaque neurone est relié à chaque entrée pour rappel, soit 25 x 784 poids à calculer, et 25 variables de plus pour le biais de chaque neurone, soit 19 625 au total, le compte est bon.
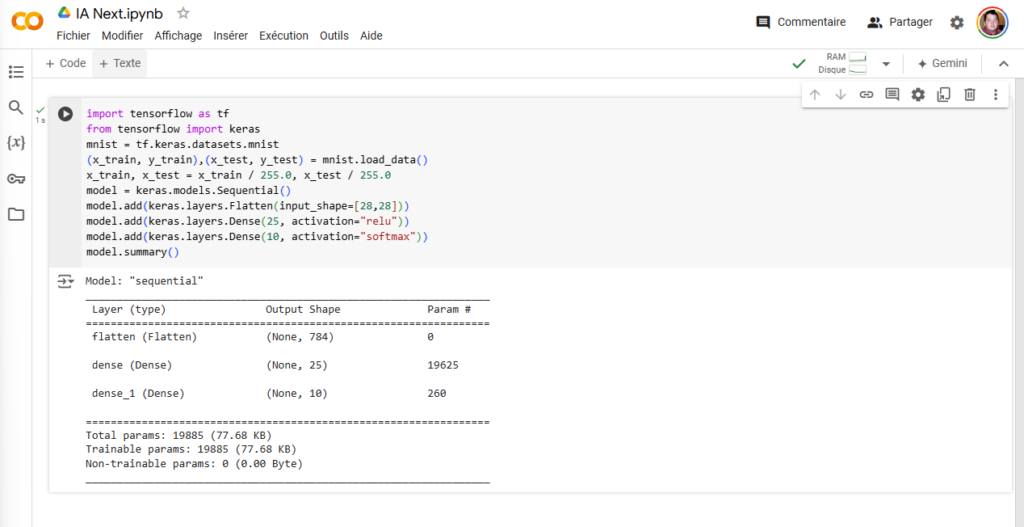
Nous avons ensuite une seconde couche de 10 neurones, avec 260 paramètres. Chaque neurone est encore une fois relié à tous les neurones précédents (10 x 25, soit 250) et on ajoute 10 paramètres pour les biais, soit un total de 260.
On est donc à quasiment 20 000 paramètres pour une IA avec deux couches de neurones ne traitant que des images de de 28 x 28 pixels avec des niveaux de gris.
Cette ligne de commande n’est pas nécessaire pour le bon fonctionnement de notre programme, vous pouvez la supprimer.
Allez hop, place à l’entrainement
Passons à la création de notre modèle d’entrainement – c’est-à-dire le compiler en langage informatique – avec les paramètres à utiliser lors de son apprentissage. C’est la fonction model.compile () et nous reviendrons juste après sur les paramètres.
La deuxième ligne de code model.fit () lance justement la phase d’entrainement à proprement parler, en se basant sur le jeu de données MNIST et les variables d’entrainement que nous avons normalisées. Le nombre d’epoch (époque en français, vous l’avez ?) correspond au nombre de fois où le modèle va s’entrainer sur la totalité du jeu de données.
10 epoch cela signifie repasser 10 fois les 60 000 images pour affiner les paramètres de notre IA (les poids et biais de chaque neurone).
model.compile(loss="sparse_categorical_crossentropy", metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10)Deux explications avant d’aller plus loin. loss, c’est la fonction de coût, c’est-à-dire la manière dont le programme va calculer l’erreur entre le résultat obtenu et celui attendu. Mathématiquement, il y a plusieurs manières de calculer la performance du modèle.
Pour la classification (comme dans notre cas), sparse_categorical_crossentropy est généralement bien adapté. On peut y ajouter un optimiseur pour améliorer encore le résultat : optimizer=keras.optimizers.SGD(lr=0.001) et optimizer='adam' sont des paramètres que l’on retrouve souvent dans les exemples. Pour de plus amples détails, consultez la documentation de keras.
Comme son nom l’indique, metrics permet d’obtenir des données sur des informations que le modèle devra évaluer au cours de son entrainement. Nous demandons la valeur accuracy afin d’avoir la précision du modèle.
Notre programme est terminé !
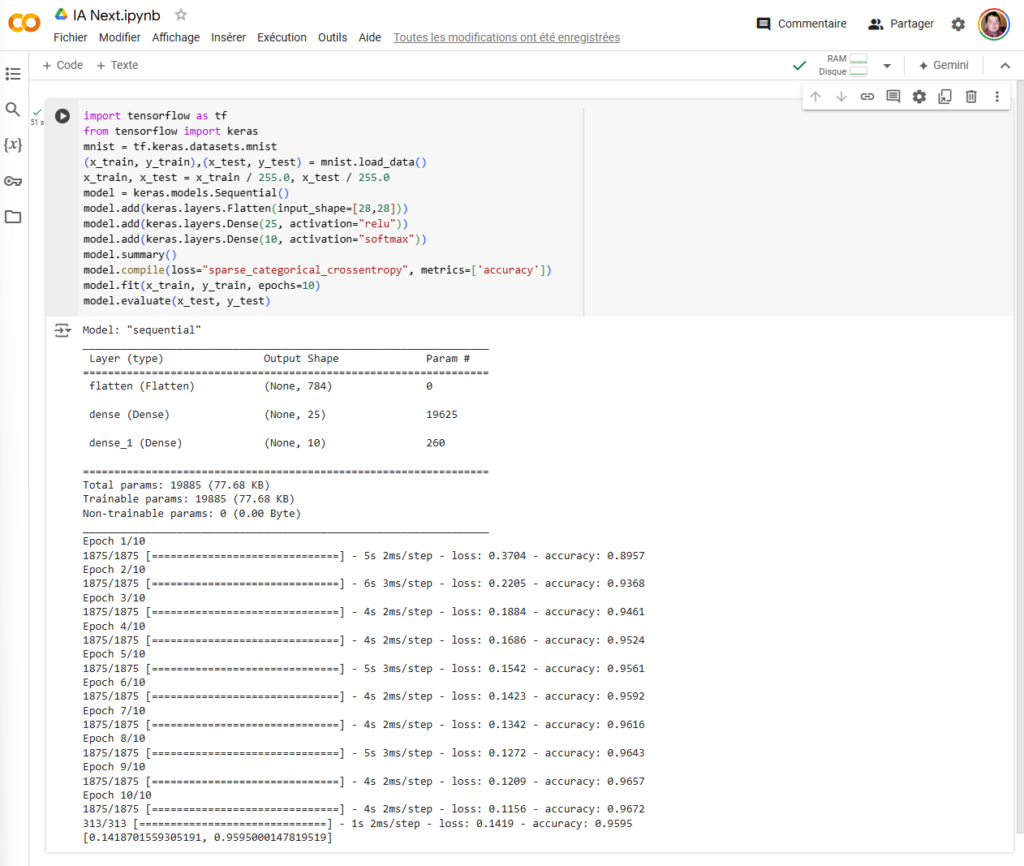
Si maintenant on exécute l’ensemble des lignes de notre programme, on arrive au résultat suivant :
import tensorflow as tf
from tensorflow import keras
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test)= mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28,28]))
model.add(keras.layers.Dense(25, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
model.summary()
model.compile(loss="sparse_categorical_crossentropy", metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10)Alors oui, notre programme fait 12 lignes et pas 10, mais c’est parce que nous avons ajouté model.summary() (bien pratique pour voir notre modèle d’IA) et une seconde couche de neurones. Nous pourrions tout mettre sur une seule ligne, mais cela nous semble un peu moins lisible et facile à comprendre d’un coup d’œil :
model = keras.models.Sequential([keras.layers.Flatten(input_shape=(28, 28)),keras.layers.Dense(25, activation='relu'),keras.layers.Dense(10, activation='softmax')])Et maintenant ?
Bonne question, on a un modèle, il est entrainé, et donc c’est terminé ? Oui, mais avant de vous laisser profiter de votre week-end, on regarde ses performances sur le jeu de test de la base de données MNIST.
Une seule ligne de code suffit :
model.evaluate(x_test, y_test)
Après entrainement, on a donc un model avec une précision (accuracy) de 0,9595, soit environ 96 % sur les données de test. On peut voir que lors de la première epoch la précision sur les données d’entrainement était de 89 % puis qu’elle est doucement montée jusqu’à 96 %.
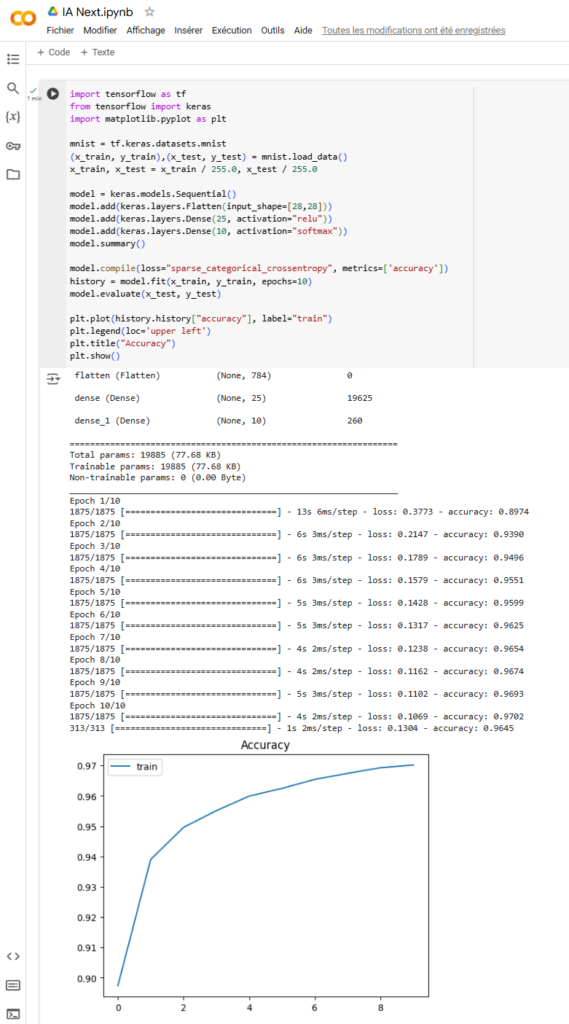
Un graphique pour la route ?
Avant de vous laisser partir pour de bon, voici quelques lignes pour ajouter un graphique avec l’évolution de la précision sur les différentes « epoch ».
Au début, on ajoute une ligne pour importer la bibliothèque matplotlib.pyplo. Sur la ligne model.fit on va associer le résultat à une variable afin de pouvoir réutiliser les résultats. On l’appelle history. Les dernières lignes permettent d’afficher la courbe de la précision de chacun de nous epoch.
Voici le code que nous avons désormais :
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test)= mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28,28]))
model.add(keras.layers.Dense(25, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
model.summary()
model.compile(loss="sparse_categorical_crossentropy", metrics=['accuracy'])
history = model.fit(x_train, y_train, epochs=10)
model.evaluate(x_test, y_test)
plt.plot(history.history["accuracy"], label="train")
plt.legend(loc='upper left')
plt.title("Accuracy")
plt.show()
Et le résultat :
Amusez-vous !
Vous pouvez maintenant modifier des variables comme bon vous semble, et vérifier en direct les conséquences sur votre modèle. Vous pouvez ajouter des couches de neurones, changer le nombre de neurones par couche, les fonctions d’activation des neurones, le nombre d’epoch, la fonction de coût, ajouter un optimizer, etc.
Notez que si vous lancez deux fois de suite exactement le même entrainement, vous n’aurez pas à chaque fois le même résultat. La raison est simple : les paramètres sont fixés de manière aléatoire lors de la première époque, puis s’affinent ensuite.
Voici un dernier résultat avec une couche d’entrée, puis trois couches de 200, 100 et 10 neurones, le tout avec 25 epoch. Le temps est bien plus long, avec plus de 178 000 paramètres à ajuster. Notre précision sur les données d’entraînement est bien meilleure, comme la précision finale sur les données de test.

Commentaires (26)
Le 21/06/2024 à 17h31
Mais désolé, vous avez ainsi créé une boîte noire : comment comprendre ce que l'IA a appris ? Comment savoir l'influence de tel paramètre sur sa méthode ?
Le 21/06/2024 à 17h48
Comme indiqué au début, c’est ici un cas pratique pour une première approche.
Dans la suite du dossier on va pouvoir détailler un peu plus la gestion des paramètres (poids et biais) et le travail des epoch, etc. (à voir si je me lance dans les dérivées, descente de gradient, minimum local…)
Le 21/06/2024 à 18h05
En tout cas,
Le 21/06/2024 à 18h32
Marre de filer des données à Google.
Le 21/06/2024 à 18h39
Le 21/06/2024 à 20h18
Le 22/06/2024 à 06h02
Juste une petite remarque sur "Pour rappel, les tableaux en informatique commencent à 0" pas d'accord, cela dépend du langage utilisé :)
C'est d'ailleurs une source fréquente d'erreur avec les jeunes qui n'ont appris que le JAVA par exemple.
Le 22/06/2024 à 13h29
VB6, tu me manques pas.
Tes tableaux qui commencent à 1 et tes collections à 0 ...
Le 22/06/2024 à 13h46
P'tain y a des jours où je suis bien content d'avoir changé de métier ^^
Le 22/06/2024 à 13h31
Mais pour modérer ton tacle, y a pas que les jeunes de java hein, les "seniors" qui jonglent entre les langages font aussi la bourde dans un sens ou dans l'autre ;) En tout cas moi ça m'est arrivé plus d'une fois!
(Entre ça les noms de type de variables qui ne désignent pas la même chose suivant les langages..
Le 22/06/2024 à 16h06
un "senior" aura plus facilement une réponse genre "rha c'est vrai j'ai oublié" alors que le jeune c'est souvent "ha bon ça commence pas à 0 ?"
Le 22/06/2024 à 19h45
Le 23/06/2024 à 19h14
Mais dans les languages les plus utilisés actuellement (https://www.statista.com/statistics/793628/worldwide-developer-survey-most-used-languages/), dans ceux qui font plus de 10%, je ne vois que SQL qui utilise des tableaux basé à 1. Et encore, SQL n'est pas considéré par tout le monde comme un langage de programmation.
Dans les 20 premier de ce tableaux, on ne trouve que lua à la 17e place.
Bref, oui, c'était un raccourci de langage de dire que les tableaux comment à 0, mais dans la vie de tout les jours, c'est globalement le cas, sauf dans les banques et pour les scientifiques.
Le 24/06/2024 à 08h24
Merci de vos retours !
Le 22/06/2024 à 10h20
Juste une remarque pour le dev du site, est-il possible d'avoir les blocs de code en mono et la coloration ? C'est plus facile de lire du code. Surtout que ce n'est pas très compliqué il y a pleins de libs pour ça. 😅
Le 23/06/2024 à 15h31
https://fidle.cnrs.fr/w3/whatsup.html
Le 23/06/2024 à 18h57
Le faire entièrement à la main permet de comprendre comment les choses fonctionnent à l'intérieur de la boite. Là, tout se fait tout seul dans la boite, juste avec une commande.
Ca peut même être fait avec sur papier, dans la même veine : reconnaissance des chiffres sur une grille de 3x5, ou même juste 7 neurones d'entrés, représentant un afficheur 7 segments. Faire le réseau complet, et plusieurs epoch à la main, avec le calcul des poids et tout, ça, ça permet de comprendre en détail comment ça fonctionne.
Cet article est utile après : mettre derrière deux commandes ce qu'on sait déjà faire.
Le 23/06/2024 à 21h20
Le 24/06/2024 à 17h40
Parce que là, je pense que personne ne sait ce qu'est la descente de gradient :)
Tu t'es attelé à une tâche compliquée, c'est ta faute aussi
Le 24/06/2024 à 21h53
Le 27/06/2024 à 17h41
Le 27/06/2024 à 18h40
Le 26/06/2024 à 11h39
J'aime bien présenter la descente de gradient ainsi :
Imaginez-vous une machine. Cette machine, elle prend des valeurs en entrée et donne une valeur en sortie. On affiche à côté de cette valeur en sortie, la différence (l'erreur) entre la valeur que la machine a donnée et celle que l'on souhaite qu'elle donne.
Sur cette machine, il y a plein de potentiomètre que l'on peut tourner dans un sens ou dans l'autre. En ce faisant, ça change la valeur de sortie, et donc l'erreur.
On teste chaque potentiomètre, seul, pour savoir dans quel sens il faut les tourner pour baisser l'erreur, et à quelle vitesse elle fait baisser l'erreur, et on les remet à leur position d'origine. Une fois fait, on tourne tous les potentiomètres dans le sens qui fait baisser l'erreur et d'un pas correspondant à la vitesse de sa diminution.
Et on recommence ça jusqu'à estime que c'est bon.
Le 27/06/2024 à 17h41
Ce que je décris, c'est plus donner un sens de ce qui se passe, et le faire manuellement pour comprendre pourquoi, à la fin, dans la vie réelle, c'est une boite noire. Se rendre compte qu'avec 7 entrées, une couche intermédiaires de 7 neurones, et 10 sorties, c'est déjà extrêmement compliqué 1. de le faire à la main, et 2. on a pas la moindre idée de pourquoi, à la fin, tel poids a une valeur quelconque.
Ce que je veux dire, c'est que la précision de l'explication importe moins que donner un sens, une intuition, de ce qui se passe, tant que les personnes en sont conscientes.
J'avais utilisé l'exemple d'une course de véhicule dans le désert dans le précédent article, mais ton exemple est plutôt bon. Le truc, c'est que pour moi (et je suppose donc, pleins de gens), tester soit même cette machine (ou, faire sur le papier, ou avec du code simple la même chose "manuellement", permet plus de comprendre que juste avec l'explication de comment fonctionne cette machine.
Bref, c'est pour ça que je trouve que passer directement à l'utilisation des APIs est dommageable. Mais en même temps, on pourrait voir ça comme "maintenant qu'on a vu ce que ça pouvait faire, rentrons dans le détail de comment ça fonctionne". C'est juste que ça me parait pas être l'ordre logique, c'tout :)
Le 28/06/2024 à 15h54
Le 24/06/2024 à 08h34