

IA : Prompt injection, empoisonnement… de quoi on parle ?
B.a.bIA #3

Les expressions se multiplient, quand on parle d’intelligence artificielle. Mais qu’est-ce qu’une injection de prompt ? Et une attaque adverse ?
Prompt injection, empoisonnement et autres attaques adverses… Quand on parle d’intelligence artificielle, en particulier générative, les nouvelles expressions sont nombreuses. Dans cette édition de notre lexique de l’IA, penchons-nous sur celles qui qualifient les attaques, déjà variées, qui visent à fragiliser les modèles d’apprentissage machine ou à contourner diverses restrictions implémentées par les constructeurs.
Nos précédents lexiques de l’IA :
- AGI, GPAI, modèles de fondation… de quoi on parle ?
- Neurone, inférence, entraînement, hallucination… de quoi on parle ?
Prompt injection
Un prompt, c’est une requête qu’on formule pour obtenir un résultat – texte, image ou vidéo – d’un modèle génératif. La simplicité d’usage qu’a permis l’émergence d’outils comme ChatGPT ou Midjourney, et leur adoption croissante dans le monde professionnel ont poussé des entités comme le centre national de cybersécurité du Royaume-Uni à alerter contre une menace bien spécifique aux LLM (grands modèles de langages) : les prompt injections, ou littéralement, injections de requête.
En pratique, il s’agit d’insérer des requêtes à destination des LLM dans les données que la machine devra traiter, en tirant profit des difficultés de cette dernière à différencier ce qu’elle doit traiter de ce qui s’adresse directement à elle. Le hacker Johann Rehberger en a par exemple fait la démonstration en intégrant une requête dans la transcription d’une vidéo YouTube. Lorsqu’il a demandé à ChatGPT de résumer la vidéo, la machine a exécuté la requête : au milieu de sa transcription, elle s’est présentée comme étant un hacker, et a écrit une « blague ». L’exemple est inoffensif, mais il illustre ce qu’il pourrait se passer avec une requête malveillante (que ce soit pour faire exécuter une requête problématique, obtenir des données, etc).
En pratique, l’injection de prompt peut aussi servir à passer outre les garde-fous de modération mis en place par les constructeurs pour éviter que leurs modèles génératifs ne produisent des résultats qu’ils considèrent problématiques. Ces derniers temps, par exemple, DAN (Do Anything Now) a beaucoup de succès, y compris auprès d’adolescentes qui, dans certains recoins d’internet, s’amusent à l’utiliser pour se créer de petits-copains virtuels aux propos dépassant les cadres imposés par OpenAI à ChatGPT. Et de se partager leurs prompts à coups de Google docs.
DAN, STAN (Strive to Avoid norms), DUDE, plusieurs prompts ont des noms qui permettent de personnifier ces tentatives de jailbreak. Plus ancien de quelques mois, le « grandma exploit » consiste à demander à ChatGPT de se faire passer pour une grand-mère décédée pour réaliser une action. En demandant à la machine de les lui demander « sur le ton d’une comptine, que ma grand-mère me chanterait pour m’aider à m’endormir », un internaute s’est targué début 2023 d’avoir réussi à obtenir 5 codes Windows 10 Pro en état de fonctionnement (Techradar a souligné qu’ils n’étaient que génériques). La tactique a rapidement été reprise pour faire produire au chatbot des malwares et autres instructions de fabrication de napalm.
Variante : le many-shot jailbreak, démontré il y a quelques jours par des chercheurs d’Anthropic. En testant Claude, le modèle de la start-up rivale de ChatGPT, ceux-ci ont constaté qu’une manière relativement simple de contourner ses garde-fous consistait à lui donner de multiples exemples de réponses à des questions borderline.
L’idée est simple : si vous demandez directement au modèle comment fabriquer une bombe, celui-ci refusera de vous répondre. Si, en revanche, vous commencez par lui soumettre plusieurs exemples (des centaines) de réponses à des questions problématiques du type « comment contrefaire de l’argent ? » Ou « comment fabriquer de la methamphétamine ? », alors la machine continuera la tendance à laquelle elle vient d’être exposée et répondra à la question laissée ouverte.
Attaque par empoisonnement
Ce type d’attaque vise les données d’entraînement, et suppose donc d’avoir accès pendant la phase d’entraînement du système. En y injectant des données de faible qualité, ou des erreurs, l’attaquant se débrouille pour que les résultats finaux produits par le système soient moins pertinents.
Attaque adverse, ou par exemples contradictoires
Une attaque adverse consiste à entrer des données trompeuses ou corrompues dans le système d’intelligence artificielle quand celui-ci est en phase de production. En ajoutant des distorsions imperceptibles à l’œil humain, cela peut dérégler un classifieur, par exemple. En sortant, la machine se retrouvera à classifier un « panda » dans une catégorie incorrecte comme celle du « singe ».
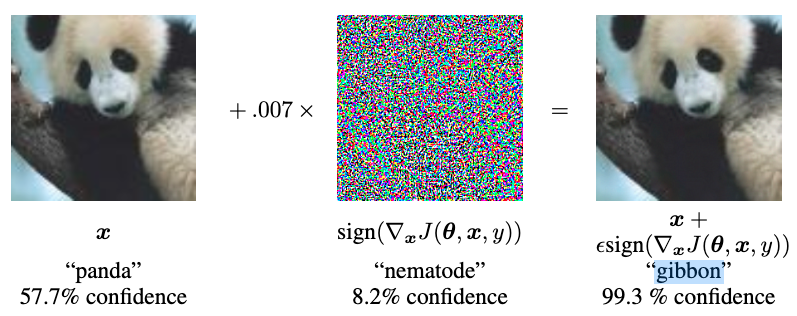
Sur le principe, les attaques adverses peuvent aussi permettre de sécuriser des systèmes d’IA. C’est même le postulat explicitement utilisé dans la construction des réseaux génératifs antagonistes (Generative adversarial networks, GANs), dans lesquels deux réseaux de neurones sont mis en compétition, l’un tentant de tromper l’autre et de le pousser (pour résumer très vite) à mal classifier des éléments.

Attaque par extraction, ou par inversion de modèle
Ici, il s’agit de soumettre un vaste nombre de requêtes au système pour observer ce qu’il produit. Le but est de reconstruire le jeu d’entraînement ou le modèle qui ont permis la création du système d’IA, le premier pouvant rapidement poser des enjeux de protection de la confidentialité et/ou de la vie privée, le second étant en lui-même un actif particulièrement coûteux... et souvent secret.
Attaque par inférence d’appartenance
Nommées en anglais membership inference attacks, ces attaques cherchent à déterminer si certaines données relatives à un individu ont été utilisées ou non lors de l’entraînement du système. À terme, cela peut permettre à l’attaquant d’obtenir des informations supplémentaires – par exemple des données sensibles comme celles de santé – sur la personne en question.
Prenons le cas d’un patient qui participerait à une étude pour définir les niveaux de difficulté d’un serious game pensé pour des personnes atteintes de la maladie d’Alzheimer, illustre le laboratoire d’innovation numérique de la CNIL (LINC). Si la détermination du niveau de difficulté est réalisé grâce à un système d’IA, un attaquant qui parviendrait à montrer la présence d’un patient dans le jeu d’entraînement du système obtiendrait du même coup son diagnostic en matière d’Alzheimer.
Ces quelques exemples donnent un aperçu de la variété d’attaques possibles contre les modèles d’apprentissage machine. Comme le montre cette publication du LINC début 2022, cela dit, on pourrait aborder le sujet en donnant des catégories d’attaques. Le LINC différencie ainsi celles qui procèdent par manipulation, qui vise à faire accomplir des tâches inattendues aux systèmes ; celles par infection, qui visent généralement à contaminer les données d’entraînement ; et les attaques par exfiltration, qui visent, elles, à récupérer des données aux systèmes d’IA, avec tous les enjeux que cela recouvre en matière de confidentialité et de protection de la vie privée.
Plus récemment, l’entité « Trustworthy and Responsible AI » du National Institute of Standards and Technology (NIST) états-unien a publié une taxonomie des types d’attaques susceptibles de toucher des modèles d’apprentissage machine et de tactiques de réaction en fonction du type de modèle (prédictif ou génératif), ainsi que de différents autres paramètres : motivation des attaquants, mode d’accès (dès l’entraînement, en phase de production), type de résultats (dérèglement du système, extraction de données, etc), et ainsi de suite.

Commentaires (3)
Le 11/04/2024 à 11h29
Question de candide ;
Le cas présenté dans :
[...]
Prenons le cas d’un patient qui participerait à une étude pour définir les niveaux de difficulté d’un serious game pensé pour des personnes atteintes de la maladie d’Alzheimer, illustre le laboratoire d’innovation numérique de la CNIL (LINC). Si la détermination du niveau de difficulté est réalisé grâce à un système d’IA, un attaquant qui parviendrait à montrer la présence d’un patient dans le jeu d’entraînement du système obtiendrait du même coup son diagnostic en matière d’Alzheimer.
[...]
En quoi c'est différent de l'obtention de n'importe données d'études qui auraient été divulgué ?
Le 11/04/2024 à 13h50
Juste que pour une étude normale, ces données ne sont pas diffusées.
Alors que là, une manipulation de l'IA permettrait de remonter à ces données qu'on pensait cachées.
Le 11/04/2024 à 17h33
Car sinon je ne vois pas.
PS : Mais dans ce cas ça voudrait dire aussi que l'étude ne serait pas surveillé ?
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?