LLaMandement : l’IA générative de Bercy pour résumer 10 000 amendements en 15 minutes
Da l'AI Lama

Alors que les députés semblent juger que l'administration publique est en retard dans l'adoption des IA génératives, la Direction générale des finances publiques vient de rendre publique l'IA générative qu'elle a utilisé pour accélérer le traitement du projet de loi de finances.
Esther Mac Namara, déléguée à la transformation numérique de la Direction générale des finances publiques (DGFiP), raconte sur LinkedIn avoir mis en place, à l'automne dernier, une « solution qui affecte automatiquement aux bonnes équipes les amendements parlementaires reçus à l’occasion des lois de finances, et chargée d’en faire le résumé automatique par une solution d’IA générative ».
Elle renvoie à un article de recherche scientifique cosigné par 23 membres de la DGFIP, trois de la Direction de l'information légale et administrative (DILA) et deux de data.gouv.fr.
Ils présentent LLaMandement comme « un grand modèle de langage (LLM) à l'état de l'art, soumis à un fine-tuning par les agents du Gouvernement afin d'améliorer l'efficacité du traitement des travaux parlementaires français (dont notamment la rédaction des fiches de banc et les travaux préparatoires des réunions interministérielles) grâce à la production de résumés neutres des projets et propositions de loi ».

Un LLM soumis à un fine-tuning par les agents du Gouvernement
Disponible sur le compte ActeurPublic d'Hugging Face et le GitLab d'Adullact, l’Association des développeurs et utilisateurs de logiciels libres pour les administrations et les collectivités territoriales, il « permet aux agents de se concentrer sur la préparation de la partie politique de la réponse en leur libérant un temps précieux, dans un contexte d'urgence ».
Pour demander à LLaMandement de résumer les amendements, un prompt lui indique que « Tu es un juriste qui doit résumer un amendement. Ta tâche est de résumer l'amendement en 1 phrase maximum. Instruction : Résume l'amendement. Le résumé doit être neutre, il doit commencer par un verbe à l'infinitif, conserver un vocabulaire juridique et les chiffres importants ».
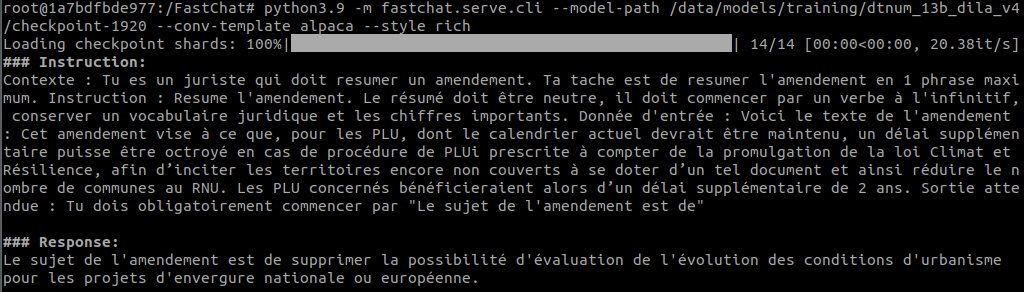
L'Usine Digitale précise que LLaMandement « s'appuie sur le modèle open source LlaMa-2 70B de Meta », et qu'il a été « soumis à un fine-tuning par les agents du Gouvernement » en utilisant 15 397 paires d'amendements et de résumés, des données issues de la plateforme Signale (Système interministériel de gestion numérique des amendements législatifs). Celle-ci a été développée par la Direction de l’information légale et administrative (Dila) pour « aider les ministères à traiter les amendements des parlementaires et à se préparer aux débats législatifs », souligne Acteurs Publics.
Résumer 10 000 amendements en 15 minutes
Cette solution, « aboutissement de travaux conjoints de direction de la Législation fiscale (DLF) – rattachée à la direction générale des Finances publiques (DGFiP) – ainsi que des équipes data scientists de la direction de la transformation numérique (DTNum) rattachée à la Direction générale des Finances publiques et la Dinum », permettrait de résumer 10 000 amendements en 15 minutes, et d'en tirer un résumé de trois lignes.
Interrogé sur les performances de l’outil par Acteurs Publics, le responsable du pôle Données des Impôts, Su Yang, indique que « LlaMandement a par exemple efficacement attribué 94 % des 5367 amendements de la première lecture à l'Assemblée nationale en seulement 10 minutes, avec un taux d'erreur de 5 à 10% ».
La DGFIP précise à Acteurs Publics que « sur la session parlementaire 2016 - 2017, marquée par des élections, à peine plus de 10 000 amendements ont au total été déposés sur différents textes au Parlement », alors que « leur nombre a bondi à près de 40 000 les deux années suivantes, et même frôlé avec la barre des 80 000 sur la session 2019 - 2020 ».
Ce qui fait dire à la DGFiP que le projet « représente une avancée technologique significative, en proposant une solution permettant de dépasser l'efficacité et la capacité d'adaptation des agents administratifs à la réalisation d'un travail toujours plus conséquent et de plus en plus difficilement réalisable dans une durée limitée par un humain, tout en offrant la fiabilité et la précision d'un rédacteur spécialisé ».
L'administration en Europe qui produit le plus de données
Acteurs Publics souligne que la DGFiP ne compte pas s'arrêter là, et qu'elle « expérimente d'ores et déjà l'IA générative pour anonymiser certains documents, extraire les informations des déclarations de succession ou encore pour répondre aux millions de questions des contribuables ».
L'un des auteurs de LLaMandement précise sur Reddit que la DGFIP « est l'administration en Europe qui produit le plus de données, incluant, mais pas que, tous les flux monétaires de l'État français, tant en entrée qu'en sortie ».
Il souligne aussi que « bien que les experts en ML soient présents à la fois à Bercy et à Data.gouv.fr, c'est à Bercy que résident les experts fiscaux qui ont contribué à toutes les étapes du développement du projet… Car ils en sont également utilisateurs finaux », et renvoie à une vidéo de 3h20 de leur dernier séminaire au sujet de l'IA générative.
Pour Esther Mac Namara, « la DGFIP offre ainsi une transparence totale sur son approche en IA générative ». Elle ajoute que « nous avons la conviction que cette ouverture favorisera la confiance et la collaboration avec les citoyens, les institutions académiques et les partenaires industriels, en permettant une évaluation externe de nos outils et méthodes ».
Commentaires (11)
Le 14/02/2024 à 16h08
J'ai quand même l'impression que l'administration française est comme les shadocks : elle génère plein de textes, met en place une IA pour les traiter plus rapidement, comme ça elle peut en générer encore plus ...
Le 14/02/2024 à 17h45
Je ne serai pas étonné qu'ils mettent aussi en place une IA pour générer les amendements...
Le 14/02/2024 à 17h48
Dans le cas du travail législatif, l'obstruction parlementaire via le dépôt de très nombreux amendements (parfois pour une virgule dans un texte) est une technique rodée et utilisée peu importe l'affinité politique. Cette stratégie n'ayant que pour seul objectif de faire durer la session parlementaire et ralentir l'adoption d'un texte. C'est aussi un use case pertinent pour évaluer chaque amendement, surtout si jamais la tournure est tarabiscotée.
Ce serait d'ailleurs aussi un bon cas d'usage d'avoir un LLM qui résume les CGU inutilement longues, rédigées de manière à dissuader de les lire, ou d'une façon incompréhensible. Synthétiser, reformuler ou extraire de l'information dans un texte est une des finalités de ce genre d'outil justement.
Le 14/02/2024 à 18h55
Le 14/02/2024 à 19h11
Modifié le 14/02/2024 à 19h25
Même avec un bon prompt on ne couvrira pas toutes les subtilités possibles et si ça se développait,nul doute que les rédacteurs de CGU en tiendraient compte et spécialiseraient subtilement leur rédaction pour passer au travers.
Le 14/02/2024 à 20h00
L'analyse de texte ou encore émotionnel, ça marche très bien. De même qu'ils arrivent de mieux en mieux à percevoir les tournures et styles d'expression du type humour, ironie, etc. Perso ça fait désormais un an que je pratique l'usage de ces outils. Ca m'a appris à ne pas sous-estimer leurs capacités tout en évitant de trop en attendre, un exercice d'équilibriste qui n'est pas simple.
Le 15/02/2024 à 14h37
Si les cas d'erreur de résumé peuvent conduire à l'inclusion d'amendements non pris en compte dans le résumé, cela peut donner des dérives non négligeables, surtout quand on parle de textes à centaines d'amendements où plusieurs dizaines passeraient entre les mailles.
Peut-on imaginer un amendement qui corrompt le sens initial du texte, ou ajoute un cas d'usage spécifique qui du coup ne serait pas du tout analysé du fait de l'utilisation de cette IA et serait donc aveuglément inclus dans le texte de loi final ?
Modifié le 15/02/2024 à 15h19
Aussi le nom est totalement nul et introduit 2 grosses fautes d'orthographe : les 2 L à la suite qui n'existent pas en début de mot en français, et bien sûr le deuxième A de amandement qui est normalement un E (sinon c'est un fruit sec).
Le 16/02/2024 à 15h47
Le 16/02/2024 à 20h24