fdorin
est avec nous depuis le 26 mai 2017 ❤️
Bio
Oups.
On dirait que quelqu'un ici aime garder ses petits secrets, comme si de par hasard il y avait quelque chose à cacher...
Désolé, ô lectrice de passage, cher lecteur égaré, pas de révélation sensationnelle pour le moment sur ce profil.
Repassez plus tard ?
1889 commentaires
iFixit démonte l’iPad Pro 13 et le Pencil Pro, qui en prend pour son grade
Le 20/05/2024Aujourd'hui à 14h 17
Je comprends. J'ai fait l'expérience d'un MacBook Pro il y a quelques années. Niveau matos, je n'ai rien à lui reprocher, il tient encore la route (bon, à l'époque, j'avais casqué, il faut l'avouer, mais c'était pour le boulot).
Par contre, j'ai pas eu de bol : une panne même pas au bout d'un mois d'utilisation (la RAM de la carte graphique qui était défectueuse, et l'utilisation d'une application utilisant la carte graphique avait tendance à afficher des glitchs à l'écran quand elle ne faisait pas planter le PC).
J'ai vécu ça comme une très mauvaise expérience :
- la machine neuve n'a pas été remplacée, elle a été réparée (à ce prix là, n'importe qui ferait un échange standard)
- la carte graphique est soudée à la carte mère, et le disque dur aussi. Donc changer la carte graphique revenait à changer tout l'intérieur (d'où le point précédant sur le changement de machine)
- pas de réparateur agréé dans mon coin : 1h de route aller / 1h de route retour pour le déposer
- 1 mois sans la machine (les choses ont peut être changé depuis, mais à l'époque, il n'était pas possible pour les centres agréés de commander les pièces, puis de dire elles sont arrivées, on peut faire la réparation. Ils ont des obligations de renvoyer directement les pièces défectueuses à réception des nouvelles pièces, sans doute pour éviter un marché parallèle de pièces détachées. Ils ne pouvaient lancer la commande qu'en ayant la machine a réparé dans les mains)
- 2e aller/retour pour aller chercher la machine.
Au total, j'ai perdu :
- 2 après-midi pour le trajet
- 1j entière pour les diagnostics (je ne compte plus le nombre d'appels à Apple où il fallait que je fasse ci, ou ça, que je fasse des vidéos, etc. avant d'obtenir un rdv)
- 1j pour tout réinstaller
Et 1 mois sans la bécane. Aucun geste commercial, pas même la proposition d'une machine de remplacement en attendant (heureusement que j'avais encore mon ancien PC fonctionnel).
Clairement, le MacBook Pro que j'ai tiens encore très bien la route. Mais plus jamais je ne prendrais chez Apple. Avec une machine classique, j'aurais gagné beaucoup de temps, et les délais auraient été beaucoup plus court.
Aujourd'hui, je voudrais faire évoluer la RAM ou le disque, et bien je ne peux pas. Le clavier papillon fait des siennes. J'ai préféré brancher un clavier USB que de le faire réparer ! Idem pour la batterie, qui ne tient plus que 20/30min.
IA générative : le ton monte entre l’Europe et Microsoft
Le 20/05/2024Aujourd'hui à 14h 02
Ah non, ça c'est pas vrai ! Nos politiques mentent sciemment, tandis qu'une IA ne fait que générer un contenu plausible
Copie privée : des reconditionneurs font condamner Copie France pour procédure abusive
Le 17/05/2024Hier à 15h 30
Si tu copies sans faire sauter la protection, tu es dans le cadre légal, mais il y a fort à parier que tes copies seront inutilisables.
Si tu copies en faisant sauter la protection, tu sors du cadre légal (contournement de DRM). Tu ne pourras pas te réfugier derrière l'exception de copie privée pour te protéger. Mais dans ce cas, il faudrait être détecté pour être inquiété. Si cela reste juste en local chez toi, juste pour le cas où le Blu-Ray serait rayé, j'ai du mal à voir comment cela pourrait être détecté... C'est pas une zone grise. Il n'y a pas vraiment de flou juridique à ce sujet (contrairement à l'abandonware).
Hier à 15h 22
J'apporte une petite nuance vis-à-vis des DRM.
Il est tout à fait possible de copier DVD ou Blu-Ray protégé par DRM, tant que le DRM n'est pas retiré. C'est l'aspect légal, accordé par la législation sous la forme d'une exception au droit d'auteur.
Le terme exception au droit d'auteur est ici extrêmement importante, car cela indique qu'il s'agit d'une tolérance consacré par la loi, pas un droit accordé à l'utilisateur. Autrement dit : il n'est pas possible d'attaquer une mesure qui empêcherait de réaliser une copie, car la copie n'est pas un droit, juste une exception. La loi stipule juste qu'une personne effectuant une copie dans le cadre de la copie privée ne peut pas être poursuivi pour violation du droit d'auteur ou contrefaçon (je simplifie hein, mais en gros, c'es ça).
Pour la copie, si le DVD reste chiffré (avec la protection CSS donc), la copie est légale. Idem pour le Blu-Ray avec la protection AACS. C'est légal, car il n'y a pas de contournement de la mesure de protection. Par contre, il faudra avoir un lecteur qui sache déchiffrer de tel contenu.
Pour les DVD, ce n'est pas trop un problème, la protection ayant été cassée depuis un certain temps. Cela reste légal aussi en France sous le couvert de l'interopérabilité.
Pour les Blu-Ray, c'est plus compliqué, puisque la protection est très différente (enfin la gestion des clés de chiffrement). Il n'y a pas, à ce jour et à ma connaissance, de solution open-source permettant de lire des contenus protégés. L'avis de la HADOPI (disponible ici sur le site de l'ARCOM) bottait effectivement en touche. De plus, une simple copie d'un Blu-Ray a de forte chance de ne pas être fonctionnelle, car le DRM utilise la technologie ROM Mark pour stocker un élément nécessaire à la détermination de la clé de déchiffrement (le VolumeID pour être précis). J'utilise le conditionnel car je ne sais pas si aujourd'hui, c'est toujours le cas et s'il existe ou pas des moyens d'extraire ce VolumeID.
On est donc la situation suivante :
- pour les DVD, une copie chiffrée est possible et sera fonctionnelle => autorisé
- pour les Blu-Ray, une copie chiffrée n'est pas possible. Le seul moyen d'avoir une copie utilisable est donc de contourner le DRM => interdit, et l'exception copie privé n'y change rien (car justement, c'est une exception, pas un droit).
Pour les Blu-Ray, il reste donc l'interopérabilité. Point sur lequel la HADOPI a justement botté en touche...
Le 17/05/2024 à 17h 32
Cf. mon commentaire #3.5.
Par contre, que se passe-t-il en cas de reconditionnement d'un produit déjà reconditionné ? La même pirouette ne peut plus être utilisée à mon sens. Mais bon, après, je ne suis pas juriste.
Le 17/05/2024 à 17h 30
Oui, mais justement, c'est ça qui est problématique sur le principe. Ce n'est pas à Copie France de faire sa loi, mais de s'y adapter. Ce qui n'est pas vraiment ce qui se passe... En taxant les appareils reconditionnés en dehors du cadre, elle était de facto, hors la loi.
La loi autorise Copie France à décider les types de supports éligibles (disque dur, GPS, téléphone, etc.), mais pas quand. Le quand, c'est la loi qui le fixe, et c'est à la mise en circulation.
Ce que j'ai compris, c'est qu'ils ont utilisé une pirouette juridique. En créant de nouveaux types de produit (téléphone reconditionné, tablette reconditionné, etc.), la vente d'un tel produit est une nouvelle mise en circulation, mais la première en tant que reconditionné. Du coup, ils arrivent à faire d'un produit identique un produit différent, justifiant ainsi leur ponction.
C'est en cela que je trouve que le jugement rendu est une victoire en demi-teinte, car cela vient entériné encore plus cet état de fait...
Le 17/05/2024 à 16h 24
Surtout quand on sait les sommes indues de la part des professionnelles qui n'ont pas été réclamées par une demande de remboursement...
Le 17/05/2024 à 16h 21
Ce qui n'explique pas pourquoi les reconditionneurs doivent
payercollecter la redevance depuis le 1er juillet 2021.Ou bien les produits reconditionnés sont des produits en tant que tel (tousse, tousse), et dans ce cas, c'est depuis le 15 novembre 2021, et pas avant, que les produits sont soumis à la RCP (il y aurait donc ici encore un angle d'attaque).
Ou bien les produits reconditionnés ne sont pas des produits en tant que tel (rappelé par Copie France en 2018 !), et dans ce cas, la RCP sur ces produits est indue.
Le 17/05/2024 à 16h 07
Pour moi, c'est une victoire en demi-teinte.
En effet, de part ce jugement, cela confirme donc, une fois encore, l'assujetissement des produits reconditionnés.
Pour rappel :
- la RCP est due lors de la mise en circulation d'un produit
- par définition, un produit ne peut avoir qu'une seule mise en circulation
- un produit reconditionné est le fait de remettre un produit qui a déjà été mis en circulation une première fois (il y a d'autres considérations pour le distinguer de l'occasion, mais qui importent peu ici).
Rappelons aussi que cette question avait été posée à Copie France en 2018 et qu'elle avait répondue que non.
Alors victoire oui, car Copie France se mange un méchant mur, mais victoire en demi-teinte...
666e édition des LIDD : Liens Intelligents Du Dimanche
Le 19/05/2024Hier à 13h 20
Ah j'avais cru comprendre que tu avais testé les services en ligne rapidement histoire de les comparer à des solutions plus locales (mais j'avais retenu que tu ne les utilisais pas au quotidien ;) )
Après, l'implémentation que j'ai donné utilise a priori un modèle de Stable Diffusion. Donc les résultats obtenus doivent assez proche, sauf à l'entrainer spécifiquement sur un nouveau concept précis.
Hier à 11h 15
Puisqu'on parle un peu IA ici, une question en rapport : certains ont-il testé l'IA de Nvidia nommé Perfusion ?
En gros : une IA générative de 100ko (oui oui, ko !!) par concept avec une durée d'apprentissage de 4min par nouveau concept.
Attention, ça ne veut pas dire que le modèle fait moins de 100ko. Il faut malgré tout un modèle préentrainé qui peut faire quelques Go. C'est juste que l'apprentissage d'un nouveau concept ce fait rapidement et pour un coût assez modique.
Le papier : https://research.nvidia.com/labs/par/Perfusion/
Une implémentation : https://github.com/lucidrains/perfusion-pytorch?tab=readme-ov-file
@SebGF : un avis ? Je sais que tu as fait pas mal d'essais avec plusieurs IA de génération d'images ;)
Hier à 11h 07
J'avais raté le format "une". Maintenant, je sachons !
Pour la taille, le "bogue" est chez moi. Voir ma réponse à Ferd en #5.2
Hier à 11h 06
Effectivement. Voir ma réponse à Ferd en #5.2
Hier à 10h 59
Effectivement ! C'est à cause de mon extension
Ce qui est bizarre, c'est que je l'avais désactivé il y a un bout de temps maintenant, car je ne l'ai pas mise à jour suite à toutes les mises à jour du site. Et là, elle est de nouveau active. Une MAJ de chrome peut être...
Mea culpa
Hier à 09h 42
Sur la page d'accueil, c'est normal la mise en page particulière pour cet article uniquement ? Image centrée, texte en dessous, alors que les autres articles c'est image à gauche, et texte à droite ?
Hier à 09h 36
J'espère qu'ils mettent un gros encart en disant que le visage a été remplacé pour anonymisation, parce que sinon... une personne qui ressemblerait au visage utilisé pourrait se voir accuser du coup !
Pour ce type d'anonymisation (remplacer le visage), il serait pas mal d'utiliser tout le temps le même visage (ou un nombre restreint, en fonction du sexe et de la couleur de peau par exemple). D'une part, cela permettrait d'éviter l'écueil que j'énonce juste au dessus. D'autre part, à force, en voyant tel ou tel visage, il serait facile d'identifier le contenu comme un contenu anonymisé (flouté).
Pour les hommes, je propose Chuck Norris. Car personne n'ose s'en prendre là lui.
Hier à 09h 30
Justement, ce serait une erreur d'utiliser une IA pour avoir un résumé et/ou une traduction.
En fait, ça peut être pratique si tu veux générer un résumé d'un texte que tu connais, pour faire le gros du travail de rédaction et ne corriger que les parties problématiques. Mais si tu ne connais pas le contenu du texte d'origine, tu seras incapable de savoir si le contenu résumé est fidèle à la source ou pas. Un exemple, pour les plus curieux sur linuxfr, avec en particulier ce commentaire qui décrit les erreurs commises par l'IA (en l'occurrence, Bard)
Ensuite, un texte de 500 pages est bien trop long pour être résumé par les modèles actuels. Il faudrait le faire en plusieurs passes. Découper le texte initiale en différentes parties, puis résumer les parties, et faire un résumé des résumés (et potentiellement répéter le processus). Bref, je doute fortement de la qualité du résultat obtenu à la fin.
Le souci c'est que le résumé généré aurait une forme tout à fait correct. Mais le contenu peut être à des années lumières de ce qui est véritablement dit. Vérifier le contenu signifie... lire le document d'origine, et donc perdre tout intérêt du résumé !
Linux 6.9 améliore encore le support matériel, surtout les processeurs AMD récents
Le 17/05/2024Le 17/05/2024 à 22h 38
Marche aussi avec :
- avec les system d'init : init.d / systemd / sysvinit / upstart
- les éditeurs de texte : emacs / vim / nano / visual studio code
- les environements de bureau : KDE / Gnome / LXDE
- les langages : Java / Javascript / Python / C++ / C# / PHP / Perl, etc... (on a plus que le choix ^^)
- tout projet initié par Lennart Poettering
- Obi Wan Kenobi
Écoconception des services numériques : le référentiel est là, avec ses ambitions et limites
Le 17/05/2024Le 17/05/2024 à 14h 52
Il manque quand même une recommandation dans le guide : la désactivation de la publicité et des trackers.
Non parce que certains sites (je ne donne pas de nom, tant c'est facile à trouver) où on a déjà 50 requêtes de bloquées juste sur la page d'accueil (sans compter les requêtes qui auraient du être lancées si tous les fichiers avait été chargé), les pub vidéo, etc... ça en fait aussi de la bande passante supplémentaire pour rien.
Exemple pour un site sur le cinéma :
- avec ublock : 45 requêtes de bloqués, sur 183 au total. 5.1 Mo transférés
- sans ublock : 707 requêtes ! 9.1 Mo transférés.
Il y a de quoi optimiser aussi bien l'écoconception que l'expérience utilisateur sans grand effort (et on met en avance le premier ou second, en fonction de si on veut faire du greenwashing ou pas :p).
Autre effet désirable : comme il faut toujours du matériel plus puissant pour supporter toutes ces publicités, ne plus les avoir ne donnerait plus l'impression que le terminal sur lequel on est est lent. Impression de lenteur qui est souvent un des critères retenus pour le changement d'appareil (notamment les téléphones portables).
Donc au delà de consommer moins de bande passante, cela inciterait aussi certains à moins changer d'appareil. Cercle vertueux.
Stack Overflow face à une révolte contre son accord avec OpenAI
Le 15/05/2024Le 17/05/2024 à 07h 32
Seul un tribunal peut trancher effectivement. Et encore faut-il que la décision soit applicable par la suite (exemple typique : Clearview AI condamné à plusieurs reprises en Europe)
Le 16/05/2024 à 16h 45
Ca ne l'empêche pas. Mais ça ne veut pas dire non plus qu'il s'applique. C'est une question épineuse, car s'il s'applique, il faudrait déterminer les conditions dans lesquelles il s'applique :
- est-ce que la personne était en France au moment de la rédaction de son contenu ?
- est-ce que l'IP enregistré pour la rédaction était une adresse IP française (je pense à l'utilisation de VPN)
- est-ce qu'il faut que la personne soit un ressortissant français ?
- est-ce que si la personne à la double nationalité française / américaine, est-ce que le droit français s'applique si la personne vit aux Etats-Unis ? Et si elle vit en France ? Et si elle est entre les deux ?
- est-ce qu'il faut que la personne soit un ressortissant français sur le sol français ?
- est-ce qu'il faut que la personne soit un ressortissant de l'Union Européenne sur le sol français ?
- et si c'est un français qui habite en Suisse, travaille en Italie pour le compte d'une société allemande ?
Et je n'ai abordé que le point de vue du rédacteur. On pourrait presque tenir le même raisonnement sur la société exploitante :
- est-ce que le site est en français ?
- est-ce qu'il y a un nom de domaine en .fr ?
- est-ce qu'il y a une succursale en France ?
Bref, je suppose que tu vois où je veux en venir. Les discussions relatives aux droits d'auteur sont complexes de base, alors quand on y ajoute un contexte international...
Le 15/05/2024 à 15h 14
Certes, mais est-ce que le droit français est applicable ici ?
Je m'explique :
- le site est uniquement en anglais,
- le site est uniquement disponible sur des .com
- la compagnie derrière Stack Overflow est américaine
- je ne suis même pas certains qu'il existe une filiale France qui pourrait faire que le droit français s'y applique d'une manière ou d'une autre.
Mais tu as tout à fait raison sinon. Ici, la question n'est donc pas de savoir si les droits moraux sont cessibles ou pas (puisqu'ils ne le sont pas en France), mais si le droit français peut s'appliquer. Si un juriste des questions internationales passe dans le coin ^^
A noter également qu'il existe au moins un pied dans la porte aux droits moraux en France : les développeurs salariés. Les logiciels sont soumis au droit d'auteur, mais l'auteur salarié du logiciel ne dispose d'aucun droit dessus, sauf accord (par exemple, dans le contrat de travail). Et si le salarié dispose encore des droits moraux dans ce cas ci (car ils sont incessibles), ils sont malgré tout amoindris. Exit le droit de divulgation. Exit aussi le droit au respect ou de retrait. Il ne reste guère que le droit de paternité.
L’histoire du BASIC, lancé il y a plus de 60 ans
Le 10/05/2024Le 14/05/2024 à 17h 09
Non, mais j'aurais bien voulu !
Le 13/05/2024 à 17h 59
Je viens de corriger mon message. Il fallait lire "GOSUB et RETURN" et non "GOSUB et GOTO"
Pour QBasic, je me souviens à l'époque d'avoir fait une bibliothèque, écrite en assembleur x86, qui prenait en charge :
- la correction du bogue sur l'émulation du calcul floatant (à l'époque, tous les processeurs n'avaient pas ce jeu d'instruction et donc il était en théorie émulé sur les architectures qui ne le supportait pas et utilisé pour les architectures qui le supportait. Mais en pratique, il était toujours émulé !
- routines graphiques (rien de bien méchant, mais des SetPixel, des DrawLine, etc. ultra performant par rapport à leur équivalent en BASIC)
- accès au mode graphique VESA (pour de plus hautes résolutions)
- gestion de la souris
Le plus drôle : j'ai retrouvé les sources la semaine dernière pendant le pont. Il faut que je creuse un peu pour voir si elles sont complètes et si ça passe sous DOSBOX. Si oui, c'est pas impossible que je mette ce petit moment de nostalgie totalement inutile sur github :)
Le 13/05/2024 à 10h 03
Pour ma part, j'ai souvent le regret de QBasic. L'IDE était d'une simplicité étonnante. Rapidité d'exécution. Il avait presque tout pour plaire :)
Navigation facile à prendre en main au clavier (pas comme vim).
Le 12/05/2024 à 15h 37
Merci pour ces précisions supplémentaires et les corrections.
 ).
).
Il faut dire que je suis arrivé bien plus tard, donc cette époque, je ne l'ai pas connu du tout.
Pour cette version du BASIC, tu as raison de souligner qu'il s'agit bien d'un compilateur et non d'un interpréteur. Mais c'est une spécificité de cette machine. La plupart des BASIC qui ont suivi l'ont été sous la forme d'interpréteur (ce que j'ai connu
J'avoue que je m'étais posé la question. Mais si c'était uniquement sur la taille des tâches que reposait le système de temps partagé, alors BASIC ou pas, le problème aurait été le même. L'avantage du BASIC, c'est que c'est un langage de haut niveau qui pouvait tout à fait abstraire ce genre de considération. D'où le fait que je sois parti sur l'idée d'un système multitâche coopératif. Après, ce n'est que mon hypothèse. Je n'étais pas la dans les années 60 pour confirmer xD (et je n'ai pas encore trouvé d'informations précises à ce sujet).
Le 12/05/2024 à 10h 54
Pas tout à fait. A l'époque, un ordinateur, c'était plutôt ça :
 (source : wikimédia commons)
(source : wikimédia commons)
Le terminal, ce n'était que le clavier et l'écran.
La manière dont je le comprends, c'est qu'ils avaient réussi à connecter 2 terminaux au même ordinateur, et à les utiliser en même temps. Si le multitâche apparait une évidence aujourd'hui, c'était loin d'être le cas à l'époque. Même à l'époque du DOS, tout était monotâche (enfin quasiment, il pouvait y avoir du multitâche, mais c'était pas natif).
A l'époque, il n'y avait qu'un seul processeur et un seul coeur d'exécution. Faire du multitâche impliquait donc de pouvoir passer d'un programme à l'autre. A cette époque, cela pouvait se faire à la condition que les programmes aient été prévu pour, en mettant explicitement dans leur code des endroits où ils pouvaient être interrompus pour reprendre ensuite. C'est ce que l'on appelle le multitâche coopératif.
Aujourd'hui, le modèle le plus largement répandu, c'est le multitâche préemptif, c'est-à-dire que c'est le système d'exploitation qui va interrompre un programme (n'importe quand) pour permettre l'exécution d'un autre, qui sera interrompu ensuite pour permettre au premier de continuer son exécution et ainsi de suite.
Le multitâche préemptif nécessite d'avoir des processeurs qui le supporte, car il faut pouvoir sauvegarder le contexte d'exécution d'une tâche (pour faire simple : les registres du processeur) pour pouvoir le restaurer ensuite. Je ne suis pas certains que dans les années 60, ce type de processeur soit très courant.
Il reste donc le multitâche coopératif. Il faut donc que les programmes disent explicitement à l'OS "tiens, là, je peux être interrompu, si tu as une autre tâche à lancer, fait-le". La force du BASIC, c'est que c'est un interpréteur. L'interpréteur peut donc facilement, après chaque instruction BASIC interprétée, notifier à l'OS un moment préemptible. Mais le programme écrit en BASIC, lui, n'a pas cet effort à faire. C'est son interpréteur qui s'en occupe !
Du coup, un programme en BASIC était naturellement coopératif (si son interpréteur l'était), là où un programme écrit en assembleur (le C n'existait pas encore !) devait explicitement dire au système d'exploitation les endroits où il pouvait être interrompu.
On peut largement comprendre ce genre d'intérêt, surtout à l'époque. Un ordinateur coutait très cher et prenait énormément de place. Si on pouvait travailler à plusieurs dessus et en même temps, l'intérêt était tout évident !
Le 10/05/2024 à 18h 38
GOSUB et

GOTORETURN permettaient de sauter "temporairement" à un autre emplacement. Mais cela ne permettait pas de faire des procédures ou fonction tel que nous les connaissons aujourd'hui :- impossible de passer des paramètres
- impossible de faire du récursif
- impossible de les nommer (sauf à mettre un commentaire ^^)
Après, on pouvait quand même arriver à contourner ces différentes limitations, mais c'était loin d'être aussi facile et trivial qu'aujourd'hui (il fallait utiliser des variables globales, la notion de localité n'existant pas, et utiliser des tableaux et un index si on voulait simuler la récursivité)
Et je numérotais de 10 en 10 (enfin, c'est l'interpréteur BASIC qui le faisait par défaut ^^). Après, l'interpréteur du CPC savait renuméroter les lignes en un clin d'oeil si besoin était (et heureusement !!)
[edit] l'instruction qui permettait de renuméroter les lignes était
RENUM:- soit sans paramètre, et tout le programme était renuméroté de 10 en 10,
- soit en précisant 1 paramètre, qui sera le numéro de la première ligne, les autres avec un incrément de 10
- soit en précisant 2 paramètres, le premier qui sera le numéro de la première ligne, et le second, qui sera le numéro de la ligne à partir de laquelle commencer la renumérotation (pratique pour ne renuméroter qu'une partie du programme)
- soit en précisant 3 paramètres, les deux premiers comme le cas d'avant, et le 3e est l'incrément à utiliser
C'était la bonne époque, moi je vous le dit !!!
Le 10/05/2024 à 15h 37
Le BASIC. Mon premier amour.

Ma bible de l'époque : AMSTRAD CPC 6128 : manuel de l'utilisateur.
Nostalgeek, quand tu nous tiens
-- edit --
Pour compléter l'article, les premiers BASIC n'avaient pas de notion de procédure ou de fonction. Chaque ligne était numérotée, et on pouvait seulement dire saute à tel ligne (GOTO)
-- EDIT 2 --
Comme il s'agit d'un moment nostalgie, je ne peux m'empêcher de donner le lien vers cette vidéo cultissime, en tout cas pour les programmeurs QBasic (désolé, c'est en anglais)
-- EDIT 3 --
J'ai du changer mes edit, car cela rentre en conflit avec la syntaxe markdown et me génère des liens affreux !
6 mois, déjà
Le 29/04/2024Le 13/05/2024 à 10h 43
Une suggestion (c'est histoire d'écrire le 400e commentaire xD) : rajouter le nom de l'auteur des articles au niveau du fil d'actualité.
Juste pour les articles, pas forcément pour les brèves. L'auteur est une information importante je trouve, chacun ayant son style et ses sujets de prédilection ;)
Le 13/05/2024 à 10h 39
Est-ce utile de refaire un message chaque jour pour ça ? Surtout que ta demande initiale est tombée pendant un pont !
Laisse quelques jours aux équipes de dev pour résoudre ce problème technique ;)
Et si vraiment ça t'importune à ce point, contacte les par mail et je suis certain qu'ils feront le nécessaire manuellement te concernant.
Le 09/05/2024 à 18h 32
Je vais essayer d'expliquer, histoire que les gens comprennent. Déjà, ce n'est pas un problème lié aux avatars, c'est un problème lié aux images en général. Et le problème ne vient pas de leur taille, mais de leur nombre.
Le site utilise une extension qui permet de gérer du lazy loading tout en utilisant une source externe (un CDN). Sur ce dernier point, Wordpress n'est pas très tendre car les images doivent impérativement être en local par défaut (enfin, pas toutes, mais certaines, comme les images illustrant les articles).
Et c'est dans cette gestion que se pose justement le problème. Le plugin repose sur une API permettant d'être notifié des modifications sur une page (pour les plus curieux et les plus téméraires, allez jeter un oeil à MutationObserver).
Cette API fait très bien son boulot. A chaque changement, elle envoie un tableau synthétisant toutes les modifications. De mémoire, au moment où j'ai diagnostiqué le problème, le tableau contenait plus de 7900 éléments. Il en contiendrait plus de 10000 aujourd'hui que cela ne m'étonnerait pas.
Ensuite, vient le plugin, et la manière dont il traite ce tableau :
- il parcours chaque élément, un à un
- chaque élément correspond à un noeud du DOM. Le DOM, c'est un arbre de noeuds qui représente une page HTML. Chaque élement (un texte, une image, un conteneur, etc.) est représenté par un noeud du DOM
- en utilisant jQuery, il recherche les images qui sont incluses dans le sous-arbre correspondant au noeud
- et ensuite, pour chaque image, vérifie s'il faut faire un lazy loading ou pas (via l'utilisation d'attribut personnalisé data-src notamment)
Le problème du plugin (dont on peut trouver une partie du code source ici), c'est qu'il est loin d'être optimisé (sans doute parce que le problème ne doit pas se présenter très souvent). Déjà, l'utilisation de jQuery (inutile aujourd'hui) et son implémentation plus qu'hasardeuse (aucune information n'est mise en cache) nécessitant un recalcul, parfois couteux, d'une manière tout à fait inutile.
Je n'ai rien contre jQuery de base. jQuery était une bibliothèque indispensable à une époque (quand les navigateurs avaient chacun leur propre API javascript non compatible) mais qui est devenu presque inutile aujourd'hui (car oui, les API de base sont maintenant bien compatible d'un navigateur à l'autre). De plus, jQuery est reconnu pour rencontrer des problèmes de lenteur dans certaines circonstances.
Alors même si le calcul est rapide (par exemple 1ms / noeud), le nombre de noeuds à traiter est tel que l'effet global se fait ressentir. 1ms * 7900, c'est près de 8s d'attente !
Mais pourquoi tant d'images ? Parce que les commentaires en regorgent ! Pour chaque commentaire, entre l'avatar, les réactions (et oui, ce sont aussi des images, quelles soient affichées ou non), les smileys cela fait une pléthore d'images pour chaque commentaire (et j'en oublie sans doute).
[edit]
dernière précision : l'exécution des scripts javascript d'une page est monotâche. Par page, il n'y a qu'un seul script qui s'exécute. Jamais d'exécution parallèle.
Du coup, puisque l'exécution du script dure longtemps (plusieurs secondes), absolument toutes les actions sur la page sont bloquées et mise en attente, le temps que le traitement se termine.
Le 09/05/2024 à 15h 57
Juste une précision : quand je parle de distinction, je ne parle pas de séparer les flux. Je parle juste de pouvoir distinguer d'un coup d'oeil l'un de l'autre (aujourd'hui, on sait que les articles sans images sont des brèves, mais il faut le savoir, ça ne coule pas de source).
 ) et les brèves ne reflètent absolument pas cette qualité. Il vaudrait mieux mettre en avant les articles gratuits pour ça je pense ;)
) et les brèves ne reflètent absolument pas cette qualité. Il vaudrait mieux mettre en avant les articles gratuits pour ça je pense ;)
C'était d'ailleurs le sens de ma proposition dans ce commentaire.
Maintenant, que d'autres sites ne le fassent pas, j'ai envie de dire que c'est leur problème. Cela existait du temps de Next INpact, cela existe sur Next, et il serait, à mon humble avis, dommageable de perdre cela.
Pour ma part, j'ai du mal à voir les brèves comme un produit d'appel, tant la différence entre une brève et un article est grande. Une brève se contente d'être un simple résumé d'une actualité ou d'une annonce, quand il ne s'agit tout simplement pas d'une traduction.
C'est tout le contraire d'un article, derrière lequel il y a un véritable travail de recherche, de pédagogie, etc.
Je suis sans doute biaisé car j'adore la qualité de certains articles (même si ceux de Marc Rees me manquent, Marc, si tu lis ce message, reviens stp !!!!
Le 09/05/2024 à 11h 14
Aujourd'hui, un des critères majoritairement admis pour la lisibilité retenu pour un site, c'est que ce dernier soit aéré. Mais je trouve ce critère est loin d'être le plus pertinent.
Si on considère effectivement l'aération comme critère de lisibilité, alors la version actuelle de Next est supérieure à celle de Next INpact.
Par contre, si on considère d'autres critères, comme les aspects fonctionnels et l'accessibilité (comprendre ici, la facilité d'accès à l'information), alors entre les deux captures, je dois dire que je préfère objectivement la version provenant de Next INpact :
- différence claire entre brief / article avec séparation des flux
- organisation des articles en actualités / dossiers /guides / etc.
- image plus petite qui ne vient pas manger la place
- présence d'une description de l'article
- présence de la date au niveau de l'article (et pas plus haut), rendant la consultation d'un encadré de l'article auto-suffisant.
En moins (toujours par rapport à la version de Next) :
- absence de la catégorie
- les signets (mais fonctionnalité non existante d'après mes souvenirs à l'époque de Next INpact)
Actuellement, si la version de Next est plus aérée, je trouve qu'elle souffre encore de défauts. Toutefois, comme il y a encore des essais en cours, je ne jette pas le bébé avec l'eau du bain ^^ :
- je trouve que les images prennent trop de place au niveau de la description de l'article
- manque d'une description
- il manque la date (même si cela fait une répétition, quand on farfouille dans les jours précédents, c'est bien agréable d'avoir la date directement au niveau de l'encadré, et pas plus haut.
- visuellement, on fait une distinction assez net entre brief et article. Mais il faut connaitre la subtilité pour comprendre ce que c'est. J'ai présenté la version à 2 personnes non informaticiennes qui ne connaissent pas Next et qui n'ont absolument pas compris la différence entre les deux.
Je comprends l'idée de fusionner les flux. Mais du coup, je trouve dommage que des articles, qui nécessitent du temps et de la recherche et qui sont d'une qualité bien supérieure, soient inclus au milieu de brèves, beaucoup plus succinctes et qui relèvent plus de la reprise d'une dépêche de l'AFP que d'un travail d'investigation poussé.
Maintenant, je ne tire pas de conclusion hâtive. Nous avons la chance d'avoir une équipe qui est à l'écoute de ses lecteurs. La recherche d'une nouvelle identité prend du temps. Rien que ces derniers jours, elle a beaucoup évolué ! Et je n'oublie pas non plus que tous les lecteurs ne pourront pas être satisfaits (c'est statistiquement impossible !). J'essaie d'être le plus constructif possible sans être trop biaisé par une résistance au changement (mais c'est pas toujours évident).
Le 07/05/2024 à 15h 36
Je viens de faire un essai pour mettre une petite distinction entre article et brève (surtout à destination des nouveaux). Voici ce que cela donnerait :
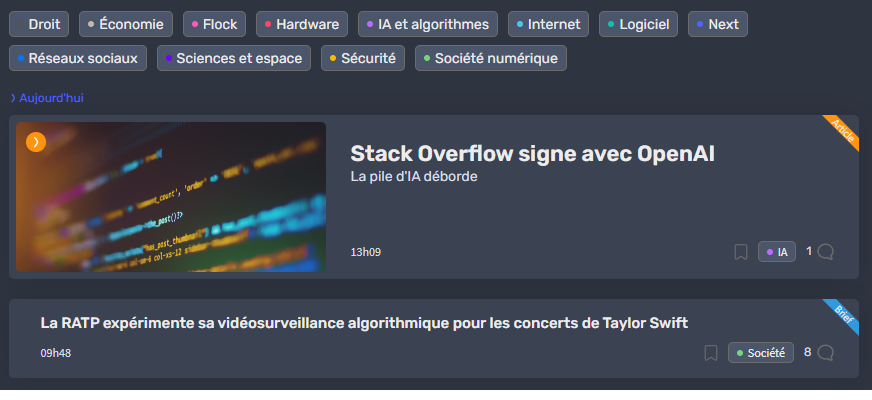
Vos avis ? (c'est bien entendu perfectible, c'est pour expliquer le principe hein !)
Le 02/05/2024 à 10h 11
Un coucou de la part d'un lecteur à qui tes articles manquent

Tu reviens quand sur Next ?
Vague de faux signalements sur Waze ce week-end
Le 13/05/2024Le 13/05/2024 à 09h 50
Parfois les maires prennent des mesures symboliques ;)
Ca me rappelle un maire qui avait son cimetière plein et n'avait pas possibilité d'en faire un autre ou de l'étendre. Il a donc pris un arrêté... interdisant de décéder sur sa commune !
Le 13/05/2024 à 09h 46
Sur l'instant oui. A terme, ça peut inciter des gens à délaisser Waze à cause des faux signalements justement, surtout si le problème persiste.
Le 13/05/2024 à 09h 01
Il serait intéressant de savoir si cette vague de faux signalements n'est pas une sorte de protestation coordonnée contre Waze.
En effet, de nombreuses petites communes en ont ras le bol de voir un afflux de véhicules passer d'une route nationale à la traversée d'une commune ou de petites routes de campagne, tout ça pour gagner 1min.
Les routes ne sont pas dimensionnées pour de tel afflux, sans compter le risque d'accident qui augmente drastiquement dans certains coin (par exemple, à proximité des écoles).
Plusieurs communes font donc des tentatives pour dévier la déviation de Waze, en abaissant la limitation de vitesse, en ajoutant des feux tricolores pour ralentir le trafic, ou encore, interdire purement et simplement l'accès à certaines zones aux non riverains et aux non travailleurs à certains horaires ! (mais j'avoue que je ne sais pas comment ils s'y prennent dans ce dernier cas).
Fuite de données clients chez Dell
Le 10/05/2024Le 12/05/2024 à 11h 06
Vu le potentiel de revente, est-ce que ça vaut vraiment le coup de se déplacer et de prendre le risque de faire un vol avec effraction ?
Ou tu peux savoir où il y a un ordi à 4 k€ qui a été acheté. Vu le prix de l'ordi, on est en droit de supposer que cette personne a des moyens financiers et dispose donc sans doute d'objets de valeur. Ce n'est pas pour rien qu'une part assez importante des homejacking cible des influenceurs : ils ont souvent affiché des objets de valeur directement sur les réseaux sociaux (montre de valeur, maroquinerie de luxe, etc.)
Tout à fait. Des arnaques style "le paiement est incomplet" ou "il y a un trop perçu, on a besoin de votre carte bleu pour vous rembourser". S'il y a des paiements en X fois, un attaquant peut aussi envoyer des courriers pour tenter de faire changer le compte cible (notre compte a changé, le nouveau RIB c'est XXX).
Ou pourquoi pas envoyer un mail avec un virus, en le faisant passer pour un programme corrigeant une faille de sécu sur l'ordinateur (suite à votre commande XXX d'un ordinateur Dell bidule muche, nous avons corriger une faille de sécurité qui nécessite votre intervention en téléchargent ZyVaHackMoiStp.exe à l'adresse suivant : https://dell.pirate.fr)
Les possibilités sont multiples.
Le 10/05/2024 à 15h 45
Phobique administratif, Thomas Thévenoud approuve
 .
.
#Flock : Chic, c’est l’Ascension !
Le 11/05/2024Le 11/05/2024 à 14h 23
La chanson de circonstance : https://www.youtube.com/watch?v=l4n6x24RRM4
 Merci Flock pour ce bon moment de poilade :)
Merci Flock pour ce bon moment de poilade :)
inutile de me chercher, je suis déjà dehors
Plus de 170 000 Français victimes d’un réseau de faux sites marchands chinois
Le 10/05/2024Le 10/05/2024 à 11h 44
Bientôt, on aura un clone de Next disponible sur https://suivant.encre xD
Plantage des Core i9 (13e et 14e gen) : réactions et recommandations officielles d’Intel
Le 03/05/2024Le 06/05/2024 à 21h 14
Tu as raison, mais il faut bien comprendre la nuance autour du terme "overclocking" entre un fondeur et fabricant de carte mère :
- pour le fondeur : l'overclocking consiste à faire tourner le CPU a une cadence supérieure à la cadence conseillée (si j'ose dire : par défaut) tout en restant dans les spécifications. A ce niveau, les risques principaux sont notamment la surchauffe et une durée de vie moindre du processeur
- pour le fabricant de la carte mère : l'overclocking consiste à faire tourner le CPU a une cadence supérieure à la cadence conseillée, au risque d'une instabilité.
J'attends donc de voir la suite de "l'enquête", car a priori, la piste serait une utilisation inadéquate (comprendre : hors spécification) de la configuration du processeur.
Le 06/05/2024 à 10h 51
Ce n'est pas le fondeur qui propose un processeur overclockable, ce sont les constructeurs de carte mère qui proposent d'outrepasser les limites du processeur. C'est un poil différent.
Si les configurations problématiques sont en dehors des conditions d'utilisation spécifiées par le fondeur, la responsabilité incombe au fabricant de la carte mère (ce qui semble être le cas ici).
Chang’e 6 fait route vers la Lune, avec l’instrument français DORN
Le 06/05/2024Le 06/05/2024 à 21h 05
Oui, car ma tête est dans les étoiles
Le 06/05/2024 à 20h 54
Punaise, j'ai cru qu'on parlait de moi en gros titre C'est ça de lire trop vite
C'est ça de lire trop vite 

J'ai lu "françois DORIN" au lieu de "français DORN"
Jack Dorsey n’est plus membre du conseil d’administration de Bluesky et fait le ménage sur X
Le 06/05/2024Le 06/05/2024 à 11h 07
X supporte les homophones ? Depuis quand X est une source d'enrichissement culturel


App Store et sideloading : Apple revoit sa copie sur les commissions
Le 03/05/2024Le 03/05/2024 à 11h 33
A ce rythme là, il faudra bientôt passer un doctorat pour comprendre la tarification d'Apple.

Ou avoir été commercial chez Oracle
Mineurs : le régulateur britannique Ofcom ouvre une enquête sur OnlyFans
Le 02/05/2024Le 02/05/2024 à 11h 33
Tu as l'air de très bien connaitre le sujet. C'est quoi ton compte ?