D’AWS Nitro à VMware Monterey : comment SmartNIC, DPU et IPU transforment les datacenters
La carte réseau est la nouvelle carte mère

Notre dossier sur la révolution des « SmartNIC » :
Lorsque l'on parle d'évolutions dans le domaine des serveurs et des datacenters, on pense souvent aux derniers CPU, GPU, cartes réseaux, switchs/routeurs ou encore aux systèmes de refroidissement. Mais depuis quelques années, bien d'autres révolutions sont en cours, notamment celle des « SmartNIC ».
Pour beaucoup, un datacenter, notamment dans le domaine des offres cloud, c'est un empilement de serveurs faisant énormément de bruit, reliés à des équipements réseau au sein de salles maintenues à une température fixe par les hébergeurs. Les faire évoluer revient à utiliser de nouveaux composants, des liens plus rapides, etc.
Des infrastructures en pleine mutation
Bien entendu, il y a aussi toute la couche logicielle pour le provisionnement, l'orchestration et le déploiement de tout ce petit monde : machines virtuelles (VM), différents services, etc. C'est d'ailleurs ce qui a favorisé la montée en puissance de « l'hyper convergence » ces dernières années, avec des serveurs à tout faire plutôt que des baies dédiées pour les différents besoins tels que la puissance de calcul, les fonctions réseau ou le stockage.
On l'oublie d'ailleurs souvent, mais une bonne partie de la valeur créée est dans le logiciel. Là aussi, les évolutions sont constantes, et en quelques années on a connu de gros changements à travers l'utilisation de plus en plus courante des conteneurs, de services comme kubernetes/docker, le serverless, etc.
Mais il ne s'agit là que des aspects les plus visibles de ce qui fait un datacenter. Et à y regarder de plus près, on distingue de multiples petites révolutions qui sont en train de changer les habitudes de l'ensemble du marché. Et ceux qui sauront prendre le mieux ces virages seront sans doute les gagnants de demain.
Mais si le passage progressif à des solutions ARM ou le recours de plus en plus massif aux GPU sont celles qui font le plus parler, la plus profonde est également la plus silencieuse : celle des SmartNIC qui bouleversent tout.
- D'AWS Nitro à VMware Monterey : comment SmartNIC, DPU et IPU transforment les datacenters
- VMWare ESXi pour ARM : le projet avance, Ampere Altra 2P et Jetson Xavier de NVIDIA gérés
- Fungible, GRAID, Kalray : dans le serveur, la guerre du stockage fait rage
Au commencement était AWS Nitro
Comme souvent, c'est Amazon qui a été l'un des acteurs les plus à l'initiative sur le sujet. Son service de cloud AWS travaille depuis 2012 sur un projet qui a commencé à prendre forme en 2013, désormais connu sous le nom de Nitro. L'objectif général est simple : gérer un nombre croissant de fonctionnalités de manière matérielle.
En effet, à l'époque, de nombreux éléments rattachés aux instances sont des briques logicielles liées à la couche de virtualisation, principalement le réseau, le stockage, la gestion même des VM, etc. Tout cela demande de la puissance de calcul prise sur le(s) processeur(s) du serveur, ne pouvant pas être mise à la disposition du client.
C'est d'ailleurs un « problème » qui s'est depuis généralisé, avec la montée en puissance des conteneurs et de leur orchestration en plus des classiques machines virtuelles. Il faut donc décharger le CPU (on parle d'offload).
Chez AWS, cela s'est fait petit à petit. Dans une vidéo publiée en décembre 2017, Anthony Liguori raconte d'ailleurs les étapes progressives qui ont mené au Nitro que l'on connait aujourd'hui. Cela a commencé en 2013, à une époque où Xen était encore l'hyperviseur maison, avec des instances comme CR1 où tout était encore logiciel.
Une montée en puissance progressive
Le premier élément qui a été déchargé du processeur central est la gestion du réseau. Une carte dédiée, un modèle commercial qui n'était pas propre à AWS à l'époque, a ainsi été ajoutée à tous les serveurs des instances EC2 (Elastic Compute Cloud) C3 lancées en novembre 2013. Elle gérait le partitionnement matériel via le standard SR-IOV.
Comme le montre le schéma ci-dessous, elle était reliée à la carte réseau du système via un câble externe. « C'était un peu fou, mais ça marchait très très bien » commente Liguorti. AWS parlait a l'époque simplement de réseau amélioré, évoquant un gain en bande passante de 20 % et une réduction de la variabilité des performances.
L'étape suivante a été de décharger la gestion du stockage, ce qui est arrivé en 2015 avec l'instance C4. Un moment important dans l'histoire de l'entreprise puisque c'est là qu'a commencé son travail avec Annapurna Labs, rachetée quelques années plus tard et qui est au cœur de ses solutions matérielles et des SoC Graviton désormais.



La solution qui intéressait AWS à l'époque permettait de gérer matériellement du stockage réseau tout en le présentant au système comme un périphérique NVMe local (NVMe-over-Fabrics, NVMe-oF). Mais l'équipe fait face à un autre problème à l'époque : son support n'est pas courant, dans les images système utilisées (AMI), elle décide donc de « cacher » son évolution matérielle derrière une couche logicielle permettant une plus large compatibilité.
« Du point de vue de l'utilisateur, l'instance C4 ressemblait fortement à une C3, si ce n'est qu'il y avait en réalité un offload matériel du stockage EBS ». Là aussi avec une réduction de la variabilité et une augmentation des performances. « Elle était si importante que nous avons pu fournir l'EBS optimisé par défaut, sans surcoût, ce qui est le cas de toutes les instances depuis C4 ». Dans son billet de blog public, l'entreprise annonce à l'époque effectivement l'intégration de cette fonctionnalité, promettant 500 à 4 000 Mb/s de débit « EBS optimisé » selon le type d'instance.
Avec l'instance X1, un premier ASIC
Avec l'instance X1 lancée en mai 2016, l'intégration d'Annapurna Labs commence à faire ses premiers effets et l'offre Nitro prend forme avec la création d'une puce spécialisée (ASIC) permettant de décharger le processeur de la gestion du réseau et du stockage, sans câble la reliant à une seconde carte physique cette fois.
Un produit nommé Elastic Network Adapter (ENA). De quoi booster une instance qui était déjà monstrueuse pour l'époque : 4 processeurs Intel Xeon E7 8880 v3 (Haswell) entre 2,3 GHz et 3,1 GHz en boost avec AVX 2.0 et AES-NI, 1 952 Go de mémoire, 2x 1 920 Go de SSD, une bande passante réseau de 10 Gb/s, identique à la bande passante EBS optimisé. 64 cœurs, soit 128 threads/vCPU étaient exploitables dans une instance. Elle était certifiée SAP HANA.

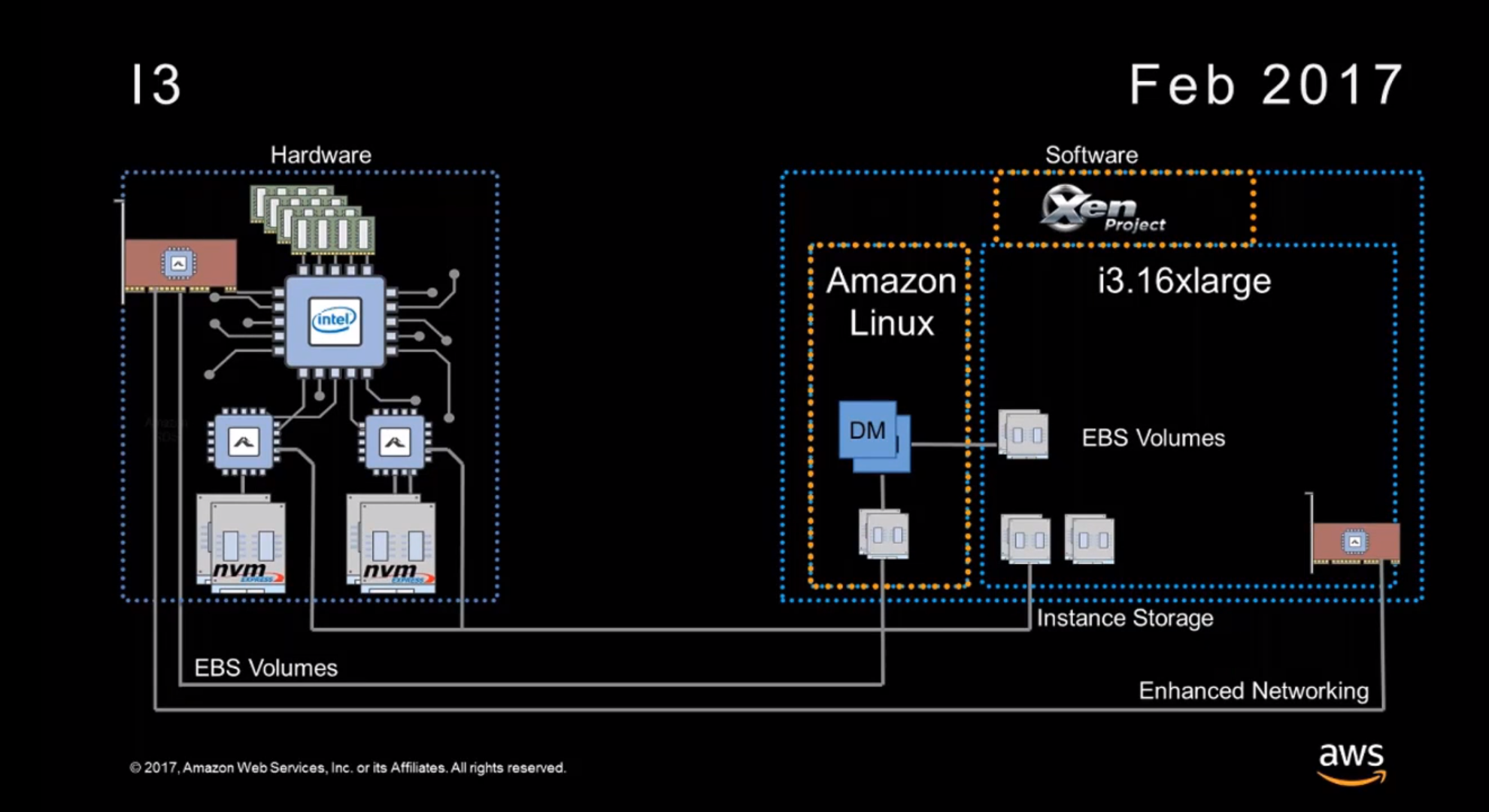
Il fallait alors utiliser une image (AMI) supportant l'ENA, un pilote open source étant mis à disposition, avec déjà à l'époque un support pour un projet d'Intel qui a également pris de l'ampleur depuis : le Data Plane Development Kit (DPDK) visant à accélérer le traitement des paquets par ses processeurs pour augmenter les performances dans des usages spécifiques comme le traitement réseau, les télécoms, etc.
Avec les instances i3 en février 2017, c'est au tour du stockage d'avoir droit à son ASIC, permettant à l'instance d'accéder directement aux SSD. Avec huit d'entre eux, on passe de 365 000 IOPS sur les instances i2 à 3,3 millions d'IOPS et un débit séquentiel maximal de pas moins de 16 Go/s. Plutôt pas mal pour l'époque.
Nouvelles instances C5 : le Nitro Hypervisor entre en scène
Mais c'est en novembre 2017 avec les instances C5 qu'une nouvelle révolution a été mise en place : AWS n'utilisait plus Xen, mais son propre hyperviseur léger Nitro, avec l'utilisation désormais de cette marque ombrelle.
« Lorsque vous voyez 72 vCPU dans une instance c5.18x-large, vous avez accès à tous les CPU physiques de la machine » et presque toute sa mémoire, précise Liguori dans sa vidéo publiée à l'occasion du lancement de cette offre. Comment est-ce possible ? Tout simplement parce que l'hyperviseur, basé sur KVM, déporte lui aussi une bonne partie de ses fonctionnalités sur un ASIC, ou plutôt sur « une carte Nitro ».
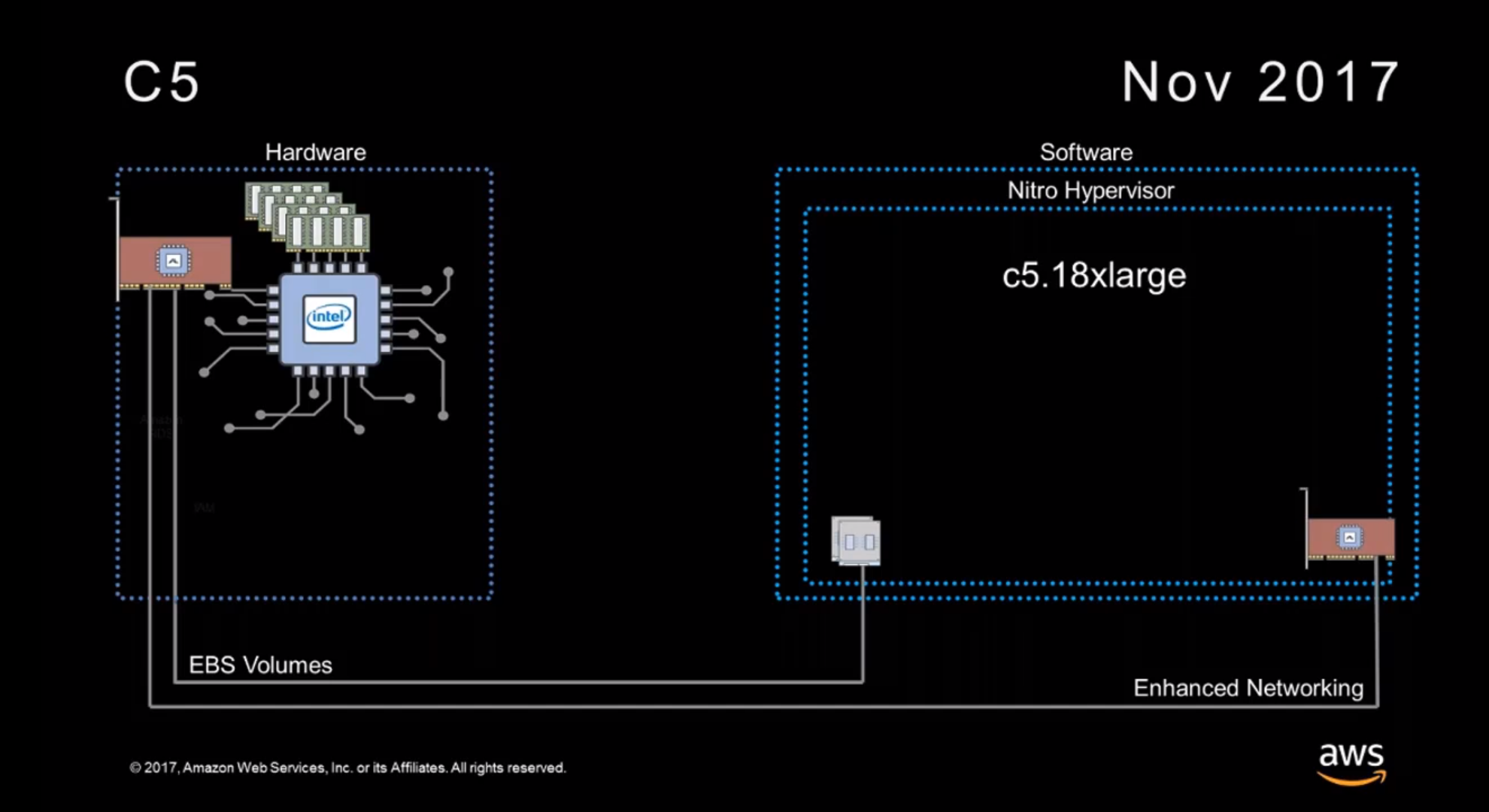


Depuis, AWS a expliqué qu'elles exploitent toutes le même ASIC, mais un PCB et une connectique différents, adaptés selon les besoins : stockage, réseau, gestion. La société a d'ailleurs ajouté une corde à son arc peu après la création de C5 : le processeur de sécurité Nitro, intégré à la carte mère, permettant de traiter toutes les fonctionnalités de sécurité matériellement, et donc de proposer des instances bare metal exploitant Nitro.
Depuis, le Nitro System prend de plus en plus de place au sein des différentes instances EC2, AWS ayant récemment annoncé une nouvelle offre : les enclaves Nitro (en accès préliminaire). Elles sont destinées à exécuter des opérations sensibles, avec uniquement un accès sécurisé spécifique, à la durée de vie pouvant être très courte.
Du SmartNIC aux DPU de NVIDIA
Cela a bien entendu donné des idées à d'autres acteurs du marché. Depuis plusieurs années on voit apparaître chez différents constructeurs des « SmartNIC », un terme en général utilisé pour définir une carte réseau disposant d'une solution programmable permettant d'effectuer des traitements sans passer par le CPU.


L'une des entreprises qui s'est fait remarquer dans le secteur est Mellanox avec ses I/O Processing Unit de la gamme BlueField. Elle s'est depuis faite racheter pour devenir NVIDIA Networking, le géant américain venant d'annoncer la disponibilité de BlueField2, avec SoC ARM et divers accélérateurs pour la sécurité.
Ce dernier parle désormais de DPU (Data Processing Unit) pour éviter la confusion avec les IPU de GraphCore qui est l'un de ses concurrents dans le domaine des calculs pour l'IA. Il présente également ces solutions comme une « Datacenter Infrastructure on a chip », pouvant être connectée à du stockage et même intégrer un GPU.
C'est le cas des BlueField2X et prochaines BlueField3X, mais cela devrait changer d'ici quelques années avec BlueField4 qui intègrera un SoC comprenant à la fois les cœurs CPU ARM, le GPU et les accélérateurs.
Côté logiciel, NVIDIA propose son DOCA SDK comprenant des briques pour la gestion du stockage, du réseau (SDN), l'orchestration, différentes bibliothèques et pilotes. Sa version 1.0 vient d'être finalisée. La société mise fort sur des usages comme la détection de menaces pour intéresser les opérateurs et hébergeurs, le framework Morpheus ayant notamment été créé pour répondre facilement à de tels besoins.
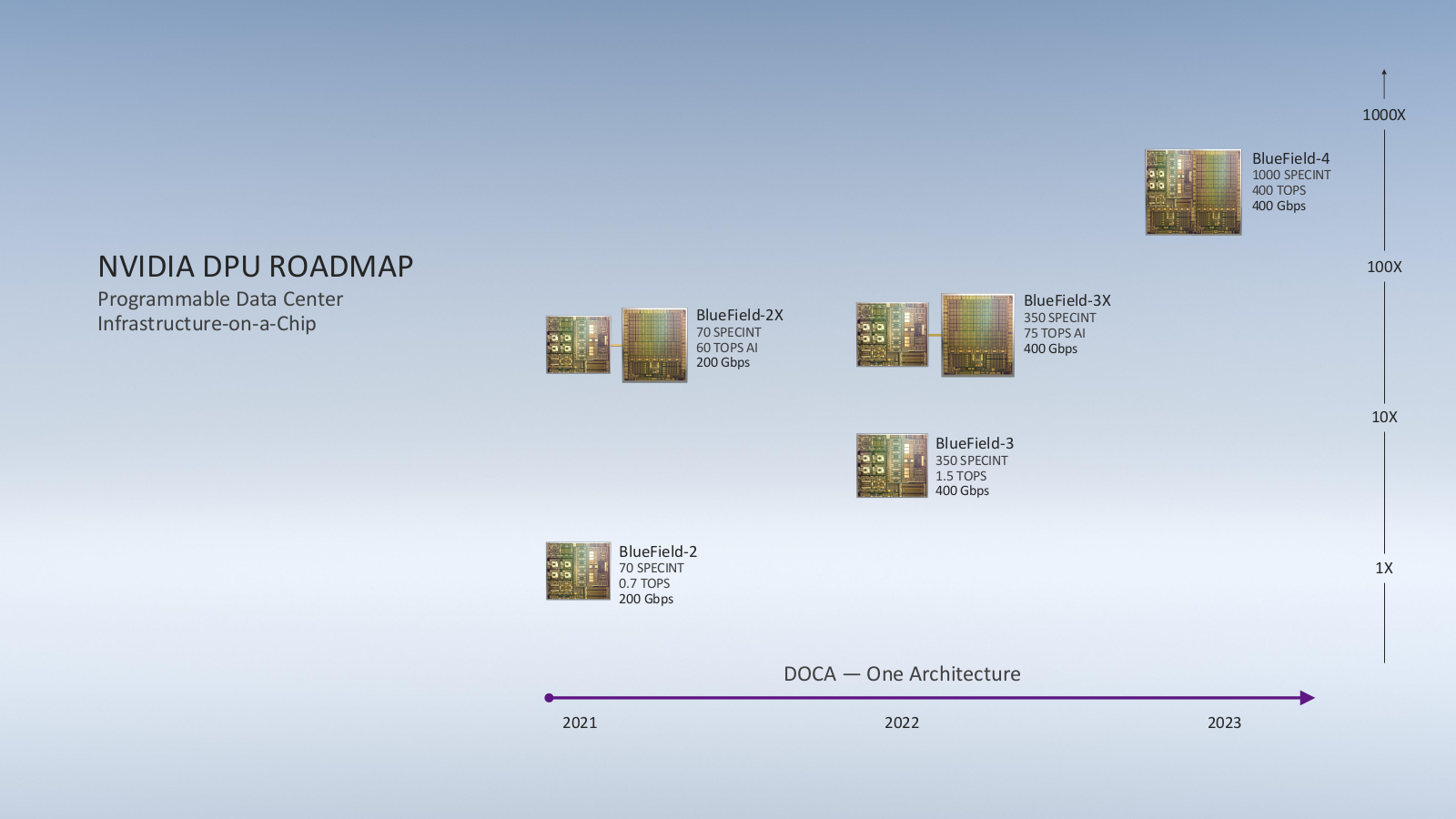

Elle vante également sa capacité à prendre en charge matériellement tout ce qui touche au réseau ou au stockage (SR-IOV, RDMA, trafic réseau), mais pourrait trouver un intérêt dans le projet Monterey de VMware. Il s'agit ici de pouvoir utiliser l'hyperviseur depuis un SmartNIC/DPU, notamment ceux à base de SoC ARM, pour décharger le processeur et arriver à des solutions équivalentes au Nitro d'AWS. Nous en reparlerons dans un prochain article.
Intel passe des SmartNIC aux IPU
Un acteur de l'importance d'Intel ne pouvait bien entendu pas passer à côté de telles opportunités. La société propose d'ailleurs depuis quelques années des SmartNIC qui intègrent différents types d'accélérateurs selon les besoins : un processeur Xeon, un FPGA ou un ASIC, issus de son très vaste catalogue.
Là aussi il était au départ surtout question de proposer un traitement des flux réseau sans avoir à passer par le CPU, mais sous l'impulsion du marché et avec le retour de Pat Gelsinger (ancien patron de VMware), elle vient d'annoncer un changement qui est plus stratégique que technique avec ses Infrastructure Processing Unit (IPU).
Elles sont présentées comme une autre manière de concevoir le data center, en plaçant cette fois ces solutions au centre de l'infrastructure plutôt que ne les exploiter que pour du réseau. Là aussi, il est surtout question de décharger le CPU de ses tâches de gestion des machines virtuelles et autres conteneurs, notamment.
Nous aurons l'occasion de revenir sur le sujet plus en détail dans la suite de ce dossier.






Commentaires (14)
Vous devez être abonné pour pouvoir commenter.
Déjà abonné ? Se connecter
Abonnez-vousLe 21/06/2021 à 11h55
He ben merci pour cette article, ça fait peur a quel point y’a de l’innovation dans tout les sens
Le 21/06/2021 à 13h03
Ouaf, ouaf !
Ils sont en train de ré-inventer le mainframe des années 60.
Une carte pour le CPU, une carte pur les I/O disque, une carte pour les I/O réseau, et un bus pour les relier tous.
Bon, à l’époque, c’était une armoire pour le CPU, une armoire pour le disque, une armoire pour le réseau.
D’ailleurs pour le réseau, on appelait ça un contrôleur de communication.
Donc il y a du progrès.
Quand je pense qu’on disait le mainframe moribond.
Le 21/06/2021 à 14h05
Merci pour l’article, tres interessant en effet ! En plus, ce sont des technos plus originales qu’on n’a pas l
‘habitude de voir.
Le 21/06/2021 à 14h19
Autant je pense qu’on peut faire certains // entre le tout cloud et les mainframes, autant comparer ce qui est fait ici avec ce type d’infrastructure, c’est passer un peu à côté du sujet ;)
Oui ça reste un peu sous les radars (ou alors des reprises de CP quand tel ou tel truc est annoncé). C’est intéressant de se plonger un peu dans ce genre dévolutions de fond et comment elles sont implémentées par différents acteurs
Le 21/06/2021 à 15h51
D’accord, ce ne sont pas des mainframes, pas encore…
Un mainframe était composé, à l’époque, de plusieurs unités de contrôle dédiées à des types d’opérations bien précises. Autour du CPU, il y avait une unité dédiée aux I/O Disque, une unité dédiée aux bandes, une unité dédiée aux communications, le tout connecté via un bus à grande capacité.
L’histoire a montré que les ‘minis’ et les ‘micros’ ont été plébicités au détriment des mainframes, désavantagés, il est vrai, par leur taille et leur coût , avec en corollaire, la gestion par le processeur central de toutes les I/O. D’ailleurs, IBM, même s’il n’en a pas été l’inventeur, a quand même créé le marché du PC.
Mais, l’apparition de cartes sur lesquelles sont déportées une partie (pour l’instant) de la gestion des I/O montre que l’utilisation d’unités de calcul dédiée pour la gestion des I/O n’est pas une idée dépassée.
Avec la fin de la loi de Moore, le meilleur moyen d’augmenter la célérité des serveurs passera sans doute par l’abandon, au moins partiel de la gestion des I/O par le processeur central.
Le 21/06/2021 à 16h10
Tu oublies que l’informatique se résumait aux mainframes à l’époque on en est loin aujourd’hui. Ces solutions sont utilisées pour le cloud, qui centralise en partie (c’est le but). Mais tu peux avoir une approche multi-cloud, l’intégration matérielle est là pour libérer des performances, etc. Bref, rien à voir.
PS : “la fin de la loi de Moore” est une stratégie de comm’ de NVIDIA.
Le 21/06/2021 à 16h50
Merci pour la présentation. Je ne connaissais pas cet usage des ASIC.
Les ASIC existent depuis longtemps mais j’ai l’impression que le codage en hardware de fonctionnalités habituellement traité par le CPU ce fait de plus en plus. Serais-ce grâce à la démocratisation des FPGA ?
Le 21/06/2021 à 17h11
Non, c’est juste que quand une boite à un besoin d’offload qui devient industriel (et à l’échelle d’AWS ça l’est), l’ASIC est une bonne solution, surtout qu’Annapurna a été acheté pour ça.
Le FGPA c’est surtout quand ce besoin doit être programmable et peut évoluer dans le temps ou qu’on doit pouvoir se reposer sur du matériel pouvant être utilisé à diverses fin (Intel proposant aussi ses eASIC entre les deux). C’est aussi moins coûteux sur une plus petite échelle.
L’idée derrière les SmartNIC avec SoC/GPU étant d’aller vers des solutions entièrement programmables via des outils ayant pignon sur rue (un développeur CUDA étant plus simple à trouver qu’un développeur FPGA ) pouvant répondre à des besoins très divers.
) pouvant répondre à des besoins très divers.
Ce sont des solutions intéressantes à l’échelles de CSP par exemple, qui peuvent les utiliser pour leur propres besoin ou les mettre à disposition des clients, sans avoir à viser des usages trop précis par exemple (c’est aussi pour ça qu’on retrouve souvent du GPU chez les CSP mais rarement du GraphCore trop spécifique pour ce type de client).
Le 22/06/2021 à 06h33
Et c’est pour ce genre d’article (entre autre) que je suis content d’être abonné. Merci!
Le 22/06/2021 à 06h38
Le 22/06/2021 à 06h40
David : “Là aussi il était au départ surtout question de proposer un traitement des flux réseau sans avoir à passer par le GPU,”
GPU c’est sur ? Pas CPU ? (même si on parle de Nvidia)
Le 22/06/2021 à 06h42
Oups (fixed, mais on a une fonction pour signaler les erreurs en évitant de passer par les commentaires, ce qui va souvent plus vite
(fixed, mais on a une fonction pour signaler les erreurs en évitant de passer par les commentaires, ce qui va souvent plus vite  )
)
Le 22/06/2021 à 06h46
Mes excuses, je n’avais pas vu ;)
Le 23/06/2021 à 09h14
Comme dit David ce n’est pas le même contexte d’usage mais effectivement ça fait penser à ça ainsi qu’à l’AS400 avec son hyperviseur et ses processeurs d’I/O.
Globalement sauf rupture technologique (réseau quantique trucs dans le genre, processeurs carbone ou optiques qui auraient des capacités physiques modifiées, retour des ordinateurs ternaires… que sais-je ) les solutions orientées perfs vont toujours tourner autour d’une recherche d’équilibre entre du code souple sur processeur généraliste peu performant et de l’exécution sur matériel dédié plus rapide mais figé.
) les solutions orientées perfs vont toujours tourner autour d’une recherche d’équilibre entre du code souple sur processeur généraliste peu performant et de l’exécution sur matériel dédié plus rapide mais figé.
Beaucoup “d’innovation” est en fait du recyclage ou de l’actualisation de solutions anciennes.