Microsoft se lance tardivement à l’assaut des « hallucinations » de ses IA
Modèle de Langage Sans Défaut ?

L'entreprise de Redmond lance un outil appelé « Correction » censé identifier et proposer des réécritures de textes générés par des IA. Cet outil s'appuie lui aussi sur des modèles de langage. L’outil arrive tard, alors que le doute s’installe dans une partie des entreprises sur la confiance à accorder aux IA génératives.
Comme l'avoue maintenant Microsoft dans sa vidéo de promotion de son nouvel outil « Correction », « les "hallucinations" des IA peuvent avoir des conséquences sur la précision, la confiance de l'utilisateur et la crédibilité de votre application ».
Jusqu'à récemment, les entreprises d'IA génératives ont massivement diffusé ce genre d'outils sans se préoccuper de ces conséquences. Pourtant, ces « hallucinations » – ou plutôt des erreurs dans lesquelles le système produit du texte ou des images incohérents – étaient présentes depuis les débuts de l'utilisation publique des grands modèles.
Des rustines pour éviter les hallucinations
Ces entreprises commencent à proposer quelques rustines pour combler les erreurs de leurs modèles. Il semble aussi, alors que les milieux financiers parlent de plus en plus d'une bulle de l'IA, qu'elles doivent montrer aux investisseurs que leurs systèmes peuvent être améliorés. En juin, OpenAI annonçait son CriticGPT pour proposer des corrections sur des erreurs de code générées par GPT-4. Fin juin, Google a aussi proposé son propre système.
Ici, avec Correction, Microsoft assure pouvoir proposer un outil qui peut détecter et réécrire des contenus incorrects générés par n'importe quelle IA générative. « Il est essentiel de donner à nos clients les moyens de comprendre les contenus non fondés et les hallucinations et d'agir en conséquence, d'autant plus que la demande de fiabilité et d'exactitude des contenus générés par l'IA ne cesse d'augmenter », explique l'entreprise.
Microsoft propose cet outil aux utilisateurs de son API Azure AI Content Safety qui peuvent s'en servir sur du texte généré par n'importe quel modèle.
Interrogé par TechCrunch, Microsoft affirme que « Correction est alimenté par un nouveau processus d'utilisation de petits et grands modèles de langage pour aligner les sorties sur des documents donnés ». L'entreprise ajoute : « nous espérons que cette nouvelle fonctionnalité aidera les créateurs et les utilisateurs d'IA générative dans des domaines tels que la médecine, où les développeurs d'applications déterminent que la précision des réponses est d'une importance significative ».
Des modèles pour corriger d'autres modèles
Elle redirige aussi vers un article mis en ligne récemment par les chercheurs de Microsoft sur arXiv. Comme le remarque TechCrunch, « le document omet des détails essentiels, tels que les ensembles de données utilisés pour entrainer les modèles ».
Cet article propose un enchainement de deux modèles de langage pour analyser la phrase générée par le modèle testé. Le premier modèle de Correction, un petit modèle, va classer la phrase en tant qu' « hallucination » ou pas. Si la phrase est catégorisée comme telle, un autre modèle, plus gros, est utilisé pour générer une explication de cette catégorisation. Si ce modèle considère que la phrase générée n'est pas une « hallucination », un mécanisme de retour d'information affine les résultats du premier modèle.
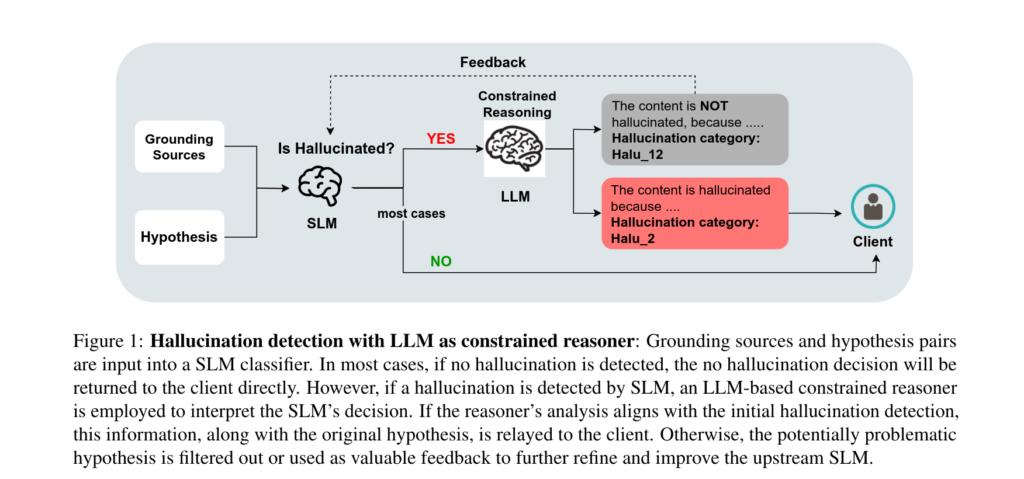
Le système de Microsoft, qui utilise la génération augmentée de récupération (RAG, retrieval-augmented generation), a besoin de s'appuyer sur un ensemble de documents donné par l'utilisateur comme « base de raisonnement ».
Les hallucinations sont intrinsèques aux modèles de langage
Interrogé par TechCrunch sur ce système, Os Keyes, doctorant à l'université de Washington, explique qu' « essayer d'éliminer les hallucinations de l'IA générative, c'est comme essayer d'éliminer l'hydrogène de l'eau ».
Pour Mike Cook, chercheur à l'université Queen Mary, cette correction au fil de l'eau et sans transparence pourrait donner un faux sentiment de disparition des hallucinations. « Microsoft, comme OpenAI et Google, ont créé cette situation problématique dans laquelle on se fie aux modèles dans des scénarios où ils se trompent fréquemment » explique-t-il à TechCrunch. Mais pour Mike Cook, « Microsoft répète maintenant l'erreur à un niveau plus élevé. Disons que cela nous fait passer d'une sécurité de 90 % à une sécurité de 99 % – le problème n'a jamais vraiment été dans ces 9 %. Il se situera toujours dans le 1 % d'erreurs que nous ne détectons pas encore ».
Une perte de confiance des clients
Problème pour Microsoft et ses concurrents, les « hallucinations » commencent à miner la confiance de leurs utilisateurs dans leurs nouveaux outils. Nos collègues de The Information expliquaient début septembre que certains clients de Microsoft n'utilisent plus l'IA d'Office censée les aider. Fin juillet, Business Insider racontait qu'une entreprise de l'industrie pharmaceutique a abandonné au bout de six mois son accord avec Microsoft concernant Copilot, car les outils proposés n'étaient pas assez performants pour justifier l'investissement.
Interrogés par le cabinet de KPMG, six responsables de la tech du Royaume-Uni sur dix considèrent que les hallucinations sont les plus gros problèmes lorsqu'on adopte des outils d'IA générative.

Commentaires (8)
Vous devez être abonné pour pouvoir commenter.
Déjà abonné ? Se connecter
Abonnez-vousLe 30/09/2024 à 09h01
Et cette fameuse base de raisonnement ? En quoi est elle différente de celle du modèle génératif au départ ? J'avoue ne pas bien comprendre.
Le 30/09/2024 à 10h22
Modifié le 30/09/2024 à 10h39
L'usage de petit modèle pour évaluer les réponses semble intéressant. Un petit modèle implique forcément qu'il sera moins précis, mais ça peut suffire à évaluer une génération de texte pour voir si celle-ci est cohérente avec le prompt.
Pour le problème des hallucinations, tout est une question de besoin en réalité. Si on considère l'IA générative comme une base de données qui doit retourner une clé / valeur cohérente, alors on a tout simplement rien compris. Autant dans ce cas monter une base de données documentaire avec un index qui cherchera dedans.
À l'inverse, si le but est de demander une synthèse des documents, de croiser des sources, et lister l'origine des réponses, le LLM est pertinent mais nécessite un minimum de supervision. Là dessus, une approche du type AutoGPT (qui est un peu la même idée que celle de MS ou OpenAI pour le coup) est pertinente, mais nécessite forcément plus de ressources car elle fera tourner en concurrence plusieurs modèles.
Après, l'autre point qui est souvent difficile à mettre en oeuvre, c'est le system prompt. Mal rédigé, il peut lui aussi amener le modèle à dériver et partir en HS. Donc outre les progrès à faire sur le plan technique, il y a aussi tout un apprentissage autour de la techno qui est balbutiant.
Modifié le 30/09/2024 à 11h31
Le 30/09/2024 à 12h19
Le 30/09/2024 à 14h06
Le 30/09/2024 à 15h35
Plus c'est gros et plus çà passe. Ou les gens ne savent plus lire.
Le 30/09/2024 à 19h08