De Git à Bitcoin en passant par IPFS : derrière la forêt de la décentralisation, les arbres de Merkle
Découpez, distribuez

Depuis 15 ans, les nouveaux services décentralisés se multiplient, facilitant le travail en équipe et le partage de fichiers, permettant de se passer d'une « autorité centrale ». Comme souvent dans l'informatique moderne, cela doit beaucoup à des travaux menés à la fin des années 70, dont les arbres de Merkle.
L'outil de gestion des versions Git a été créé en 2005 par Linus Torvalds. Le livre blanc décrivant Bitcoin a été publié par Satoshi Nakamoto en 2008. IPFS a été initié par Juan Benet en 2013. Outre leur volonté de décentraliser les usages et services, ces trois projets partagent un point commun : ils exploitent des arbres de hachage.
Ils sont loin d'être les seuls. Il y a bien entendu de nombreuses crypto-monnaies et systèmes de transferts pair-à-pair (P2P), mais on peut également citer les systèmes de fichiers Btrfs et ZFS, Apache Wave (ex-Google Wave), des gestionnaires de paquets, des bases NoSQL, etc. Tous les implémentent d'une manière ou d'une autre.
Selon Wikipédia, il s'agit d'une « structure de données contenant un résumé d'information d'un volume de données, généralement grand [...] le principe d'un arbre de hachage est de pouvoir vérifier l'intégrité d'un ensemble de données sans les avoir nécessairement toutes au moment de la vérification ».
Mais en pratique, comment ça fonctionne et en quoi cela change la donne ? On vous explique tout.
Au commencement était le hash
En cryptographie, un hash est le résultat d'un calcul désignant des données avec une taille fixe, de manière déterministe, unique et non réversible. C'est pour cela que l'on parle aussi d'empreinte en français. Par exemple, si vous téléchargez l'image ISO d'Ubuntu 21.04 Desktop (amd64), son empreinte SHA-256 est la suivante :
fa95fb748b34d470a7cfa5e3c1c8fa1163e2dc340cd5a60f7ece9dc963ecdf88
Cela veut dire que si vous téléchargez le fichier et que son contenu est 100 % conforme, calculer son empreinte SHA-256 donnera le résultat ci-dessus, elle est donc déterministe. Vous pouvez ainsi en vérifier simplement l'intégrité. Mais depuis cette seule empreinte, vous ne pouvez pas retrouver le contenu du fichier (non réversible).
De plus, si des « collisions » peuvent survenir (deux fichiers avec une empreinte similaire), une fonction de hachage doit répondre à quelques critères. Ces collisions doivent être rares et ne pas pouvoir être créées ou devinées. On ne doit ainsi pas être capable de générer un faux bloc de données ayant la bonne empreinte. De plus, le changement du moindre bit dans le fichier doit significativement modifier l'empreinte pour éviter de trouver des similarités. C'est en cela que l'empreinte d'un fichier est en général considérée comme unique.
L'arbre de hachage permet d'appliquer ces règles à l'échelle de petits blocs de données avec une hierarchie simple à parcourir. Ainsi, plutôt que d'avoir une seule empreinte par fichier, on en calcule pour de nombreuses portions. Cela permet de vérifier l'intégrité de chacune d'entre elles, mais aussi d'éviter les doublons, de comparer ceux qui ont changé entre deux versions d'un fichier. Tout l'enjeu étant d'y parvenir de manière efficace.
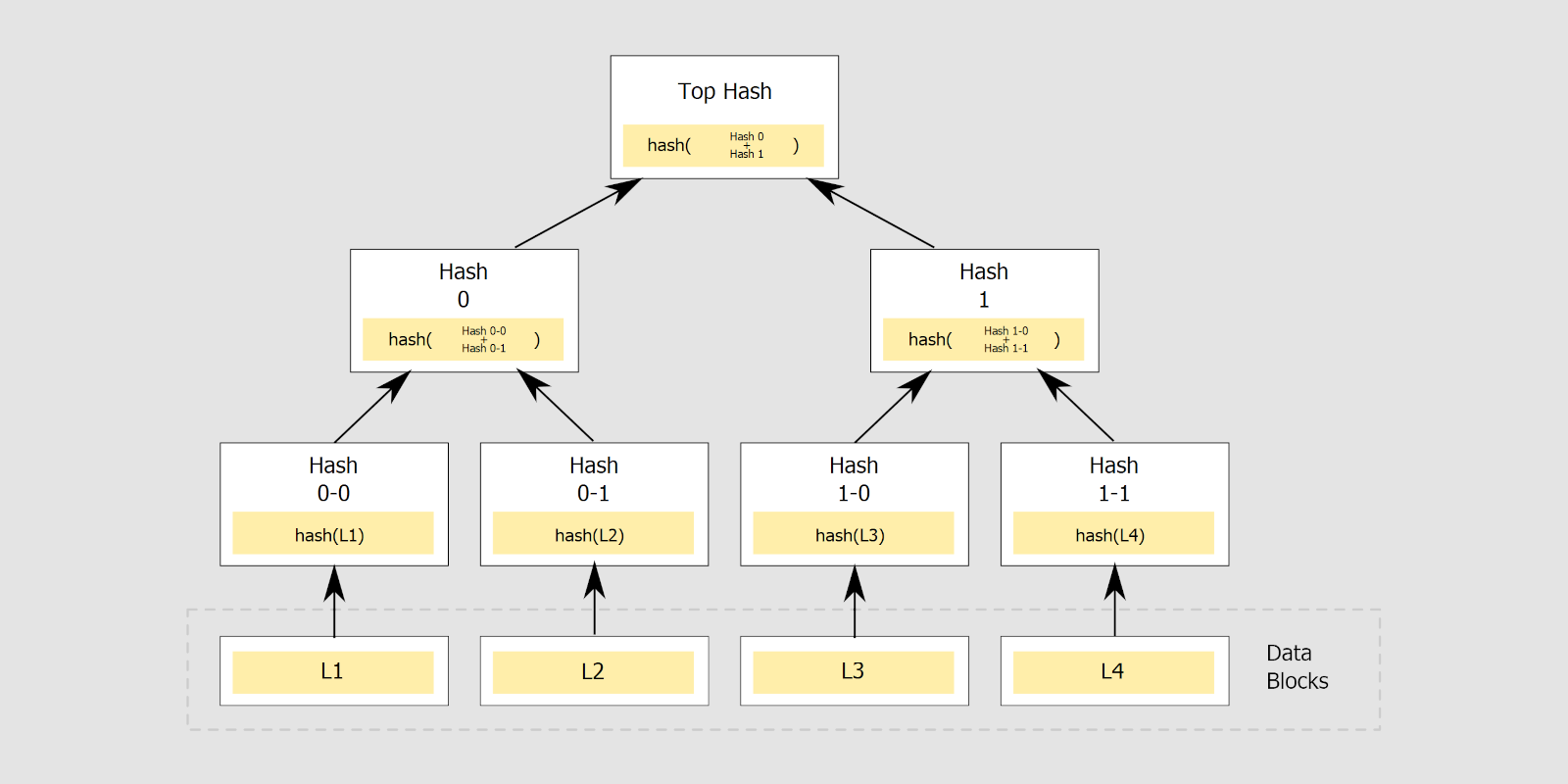
Un arbre de Merkle dit binaire : chaque élément dispose de deux nœuds maximum
Arbre des années 80...
C'est ce qu'a réussi Ralph Charles Merkle, célèbre cryptographe américain connu pour ses puzzles (pour l'échange de clé en vue d'une communication chiffrée) et la construction Merkle–Damgård utilisée dans la fonction de hachage MD5 (d'où les initiales), mais également dans de plus récentes comme SHA-1 et SHA-2.
En juin 1979, alors qu'il étudie à Stanford, il publie une thèse de 182 pages, fruit de 5 ans de travail : Secrecy, Authentication, and public Key Systems. On y découvre les « arbres d'authentification », qui font l'objet d'un dépôt de brevet (US4309569A) la même année, accordé en 1982, expiré en 1999.
En pratique, un arbre de Merkle est constitué de blocs de données considérés comme ses feuilles (leaf nodes), situés dans la partie inférieure de la représentation en graphe. Pour chacun de ces blocs, on calcule une empreinte. Ils sont ensuite organisés en branches, chacune contenant les empreintes de ses feuilles, ce qui constitue de nouvelles données, dont on calcule l'empreinte. On remonte l'arbre jusqu'à obtenir l'empreinte racine.
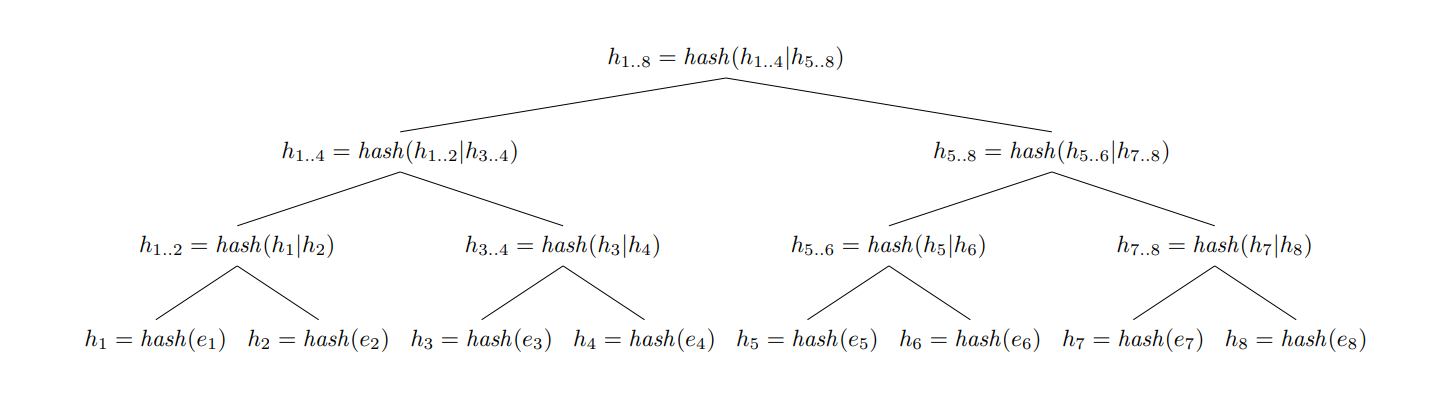
Chaque empreinte calculée est unique, comme celles de chaque branche ou de chaque feuille. On peut ainsi vérifier l'intégrité du fichier dans son ensemble ou de branches plus ou moins importantes selon le découpage opéré. Cette organisation permet d'ailleurs d'effectuer des vérifications même si l'ensemble de l'arbre n'est pas connu.
Cela permet aussi de moduler le besoin de confiance lorsque l'on récupère les données depuis une multitude de sources. On peut chercher à s'assurer de la fiabilité de l'empreinte principale par des moyens complexes en étant plus laxiste sur la composition de l'arbre et la récupération de ses données puisque l'on peut vérifier si elles sont conformes au résultat attendu et changer de source si ce n'est pas le cas, garantissant la sécurité de la procédure.
Comprendre les arbres de Merkle par l'exemple
Pour mieux illustrer l'intérêt de cette solution, prenons l'exemple d'un simple texte :
Hello, World !
Calculons son empreinte via la fonction SHA-256 (sous Linux) :
echo "Hello, World !" | sha256sum
114b850f2f0959c5f98664f3d8d9345742d713923bd24b2f049b6af66d4e31f6 -
Modifions maintenant un caractère et recalculons l'empreinte :
echo "Hello, Warld !" | sha256sum
5631e5f6bbd88e0093955bc303ba1f5a0acf6081b8d41fc47a9d6213c1716b64 -
La différence entre les deux empreintes nous permet de voir que les données sont différentes, sans pour autant savoir que 13 des 14 caractères de ce texte sont identiques, soit 93 % ! C'est là que l'arbre de Merkle entre en scène.
Découpons ce texte sous la forme d'un arbre composé de quatre feuilles contenant chacune quatre caractères, dont on calcule l'empreinte. On les regroupe par branches de deux feuilles, qui contiennent les deux empreintes l'une à la suite de l'autre. On calcule ainsi l'empreinte de la branche, puis de la racine.
Dans le cas du premier texte, cela donne le résultat suivant :
Racine -> 5108ad59f7bbcc22901e82a3940820724220566bb13339bd4987ae224333590e
Branche 1 -> 898b13a8313d2aec0235f64ed7a584b54cdd9b1f2ba05e5db1c35446b99fe4ea
Branche 2 -> 8241981d28e05664e291fbe5efb0b230ade095350f2639280cb722da091516f4
Hell -> 2e5b7961ede9dfdb4c69811a11b724c407530e50e2d4ee66edc1a8ba05990530
o, W -> b060fc7acde1f9081ab6960cac53e3c6cba13bac171aa1d56192f91aa0774e3c
orld -> af7e10710312284c829aa8a3f05f45b1ff11093754d9bb8b71479a391d734b0c
!-> a038c6a06dc31ebb67f8527c1aa3934147e9b364ea4e0bf5d41663427d7ff7af
On fait la même chose pour le second texte :
Racine -> 7e7af2183768a714d80a6e30902ffe2717d45fabc5e16986ff46c4b5918ab601
Branche 1 -> 898b13a8313d2aec0235f64ed7a584b54cdd9b1f2ba05e5db1c35446b99fe4ea
Branche 2 -> bf30dd5dca92e70108a4d6bc557cf4cc1a22641bd2c2120e6f1180685ee212bd
Hell -> 2e5b7961ede9dfdb4c69811a11b724c407530e50e2d4ee66edc1a8ba05990530
o, W -> b060fc7acde1f9081ab6960cac53e3c6cba13bac171aa1d56192f91aa0774e3c
arld -> 5bca745103e0fee105a03c0aa8900d92a9baa7f98b2fef39492aa713074b1c50
!-> a038c6a06dc31ebb67f8527c1aa3934147e9b364ea4e0bf5d41663427d7ff7af
En comparant les deux empreintes finales, on peut déduire que les textes sont différents comme on le faisait auparavant. On note au passage que l'empreinte calculée depuis le texte diffère de nos empreintes racines, ce qui est normal : ces dernières sont des empreintes d'empreintes d'empreintes, pas celle correspondant au texte.
En comparant les empreintes de branches on constate que la première est identique, mais pas la seconde. Via les empreintes de feuilles, on voit qu'un bloc sur quatre a changé.
Petites empreintes, gros avantages
Si l'on doit stocker ces deux textes au sein d'un système, on peut donc effectuer une déduplication, en ne stockant pas en double trois des quatre blocs de données. Pour de la gestion de version, on peut également stocker uniquement le bloc qui a été modifié et sa référence. Git a néanmoins adapté ce système à ses besoins.
Le gestionnaire de version développé par Linus Torvalds organise en effet ses données sous la forme d'objets dont des arbres (Tree) qui regroupent des fichiers (Blob). Tous sont identifiés par une signature (SHA-1) et organisés sous la forme d'arbres de hachage. Une organisation à ne pas confondre avec ceux des objets Commit, qui peuvent être reliés entre eux à travers le système de branches et forment plutôt un graphe orienté acyclique (DAG).


L'organisation des objets Tree (à gauche) et Commit (à droite) dans git
L'intérêt de cette méthode, est qu'elle permet une analyse et comparaison sur la base de simples empreintes, pouvant correspondre à de gros blocs de fichiers. Récupérer l'arbre de Merkle d'une image ISO de 5 Go sera très rapide. On pourra alors décider de la télécharger en intégralité ou non selon les blocs de données dont on dispose déjà localement, depuis différents serveurs selon les blocs dont ils disposent et leur débit par exemple.
Dans le cas de Bitcoin et d'autres crypto-monnaies, c'est différent. Les arbres de Merkle sont utilisés pour représenter et valider l'intégrité des blocs de transactions, mais aussi les relier entre eux. Ainsi, le header de chaque bloc contient diverses informations, dont l'empreinte racine du bloc précédent dans la chaîne.
L'identifiant de chaque bloc est une empreinte des informations contenues dans le header. Outre l'intégrité des informations et des transactions, on peut alors vérifier la position du bloc dans la chaîne grâce à son identifiant.
On pourrait aussi alléger la blockchain stockée (pruning) en ne retenant que certains blocs de transactions et leurs arbres de Merkle. Une solution évoquée dans l'article originel décrivant Bitcoin, mais pas implémentée telle que. Il en va de même pour la Simplified Payment Verification (SPV) qui permet d'effectuer des vérifications en ne stockant pas toute la blockchain mais uniquement les headers des blocs, bien plus légers.
 Le pruning, présenté par Satoshi Nakamoto pour économiser de l'espace pour le stockage de la blockchain Bitcoin
Le pruning, présenté par Satoshi Nakamoto pour économiser de l'espace pour le stockage de la blockchain Bitcoin
Commentaires (33)
Le 26/08/2021 à 09h18
Concis, claire et très intéressant. Merci pour cet article
Le 26/08/2021 à 09h46
D’habitude on hache les arbres là ce sont les arbres qui hachent
Sinon, quelle est la différence entre Hash et Cheksum ?
Le 26/08/2021 à 09h53
Non on met les hash dans les arbres !
Pour hash/checksum, pas de différence, c’est juste la traduction de somme de contrôle, qui revient au même que le calcul d’une empreinte ou d’un condensat
Le 26/08/2021 à 11h32
Pour pinailler, les checksums englobent aussi les méthodes qui calculent des empreintes sans pour autant avoir été pensées pour être non réversibles/bloquer les possibilités de calculer efficacement des collisions.
p.ex. CRC32 est une checksum mais n’est pas un hash.
Le 26/08/2021 à 11h41
En même temps je vois que Wikipedia référence les CRC comme fonctions de hachage avant de distinguer plus loin les fonctions de hachage cryptographique. Entre la traduction et l’usage, ça fait beaucoup pour que tout le monde tombe d’accord
Le 26/08/2021 à 11h57
Le 26/08/2021 à 09h55
Très intéressant, merci bien !
Le 26/08/2021 à 10h01
Merci pour beaucoup pour cet article très didactique qui présente les dessous de technologies très répandues. C’est toujours bien de savoir comment ça fonctionne.
Le 26/08/2021 à 10h18
Chapeau bas pour ce remarquable article, merci!
Le 26/08/2021 à 10h44
Pareil, bel article, rien à redire.

David, tu mets des points pour une défiscalisation de quelques poignées d’euros d’ici la fin de l’année.
Le 26/08/2021 à 10h59
Super article, j’espère qu’il y en aura d’autres du même type :)
Le 26/08/2021 à 11h11
Disons que c’est l’un de mes “petits cailloux pour un Master plan sans fin”
Le 26/08/2021 à 11h12
Super article en effet, merci !
Le 26/08/2021 à 11h36
Dans les deux cas, c’est un nombre plus ou moins grand qui est calculé à partir d’une donnée. La différence est dans la finalité.
Un checksum, ou somme de contrôle, sert à vérifier qu’il n’y a pas eu d’erreur dans la transmission d’une données. On va utiliser typiquement un CRC.
Un hash, ou fonction de hachage, sert à avoir un “raccourci” pour identifier une donnée, pour les insérer dans une table de hachage. On va utiliser typiquement des fonctions comme FNV-1a ou MurmurHash. Par rapport au checksum, ces fonctions sont souvent plus rapides, mais génèrent plus de collisions.
Après, tu as le hash cryptographique, qui est une fonction non-inversible (du moins, pas simplement), c’est-à-dire que connaissant un hash, il est très difficile de construire une donnée qui va avoir ce hash. Les collisions sont rarissimes (souvent, on en connaît zéro). Malgré le nom, on utilise ça pour de l’authentification plutôt que pour faire une simple table de hachage (quoiqu’en p2p, ça va souvent ensemble). Typiquement, ce sont les fonctions MD5, SHA-1, BLAKE, etc. On peut les utiliser comme checksum aussi si on veut, mais il faut savoir que c’est bien plus coûteux qu’un CRC.
Dans le cas des arbres de Merkle, comme le hash identifie réellement la donnée et ne sert pas simplement pour du binning dans une table de hachage qui gérerait les collisions par ailleurs, on utilise un hash cryptographique.
Le 26/08/2021 à 11h57
Je rajouterai qu’es les checksum peuvent dans certains cas être réversibles.
Dans le cas d’un raid5 sur 3 disques par ex, 2 disques contiennent les donnes, et le 3e la checksum qui n’est rien d’autre qu’un XOR des 2 disques de données. Ça permet en cas de corruption d’un disque de le reconstruire par XOR des données valides et de la checksum ;)
D’ailleurs si je dis pas de conneries NTFS comporte des zones de checksum permettant de reconstruire les donnes d’un secteur corrompu.
Le 26/08/2021 à 12h51
La décentralisation, c’est comme la voisine du 8ème de Renaud: le hash, elle aime !
Le 26/08/2021 à 14h03
Hum, il m’avait semblé que GIT stockait les blob sous un élément unique (eg: SHA1 -> BLOB) au contraire par exemple de SVN qui opère par delta.
D’ailleurs, j’ai bien l’impression que c’est ce qui se passe :
On se retrouve avec 3 SHA1:
deadbeefcalculé à partir du contenu du fichier, et de méta données (sa taille, etc)beefdeadcorrespondant à la racine contenant grosso modo pour chaque nom du dossier une référence vers le blob (ex: T -> deadbeef) ou un autre arbre.et enfin le commit.
beef1337ayant une réf surbeefdeadAlors après je sais que la commande git gc peut optimiser un repo et créer des fichiers *.pack
Est-ce de ça dont il s’agit ?
Le 26/08/2021 à 14h31
Très bon article 👍
Juste petite précision :
Non, ce n’est pas le critère pour désigner une fonction de hachage, il est evident que d’autre fichier peuvent avoir la même empreinte, on passe d’un nombre aléatoire d’octet (1 Mo, 10Go, 1000To, …), à 256 bits, donc forcément il y’a des collisions, ce qui est par contre important c’est qu’elles ne soient pas prédictible et surtout qu’on ai une dispersion important (si un octet n’est pas bon dans le fichier alors l’empreinte est “très” différente).
Le 26/08/2021 à 14h34
Git ne fait effectivement aucune optimisation au niveau des fichiers qu’il stock. Un fichier = un objet = un hash. Si un fichier de 5 Go est mis a jour avec très peu de dispersion on aura bien deux objet avec deux hash différents et donc deux fois 5 Go à télécharger pour récupérer l’historique.
La technique de Merkle n’est pas appliqué sur le objet mais sur les tree.
Le 26/08/2021 à 14h45
Si on pinaille:
Dans l’utilisation:
Le 26/08/2021 à 16h21
Si on pinaille, ta définition est pour les fonctions de hachage cryptographiques, pas pour les fonctions de hachage standard (FNV, MurmurHash, Jenkins, etc.) que l’on utilise pour les tables de hachage. Cette utilisation est quand même un tout petit peu importante, puisque le nom vient de là.
Le 26/08/2021 à 18h20
Merci pour la confirmation :)
Le 26/08/2021 à 19h02
Oui dans Git le bloc de données (objet blob) est forcément un fichier, mais le fonctionnement reste le même, seul le découpage change. C’est aussi l’intérêt des arbres de Merkle, on peut les adapter à différentes pratiques (dont l’exploitation en complément de DAG comme Git ou d’une certaine manière IPFS qui va un peu plus loin dans la composition de ses blocs comme on le verra plus tard)
Le 27/08/2021 à 06h13
Pour revenir sur le sujet, ce n’est pas tant une question de pinailler ou pas, mais de ce que l’on opère comme segmentation. C’est ce qui explique sans doute qu’il n’y a pas toujours un fort consensus sur le sujet. Sur le fond et comme le fait remarquer Alex.d, in fine, on calcule toujours une sorte d’empreinte qui permet d’effectuer une vérification sur un bloc de données.
Si on peut désigner des limites claires dans les potentielles finalités, en pratique c’est un peu moins simple. Par exemple, la clé d’un RIB ou d’un numéro de sécurité sociale peut être considérée comme une somme de contrôle et on comprend qu’on la distingue de SHA-256.
Pour autant, est-ce que la finalité est différente si je transfère ce même numéro avec son empreinte SHA-256 pour permettre de vérifier qu’il est correct ? La finalité est dans les deux cas de vérifier l’intégrité, mais on le fait de manière et avec des propriétés différentes.
D’ailleurs, certains considèrent CRCx comme une somme de contrôle, alors que si on en revient aux fondamentaux de ces distinctions, ce n’est pas une somme, donc cela ne peut donc elle ne peut pas être considérée comme telle. Et là on peut commencer à couper les cheveux en 4 et mettre chaque algo dans sa petite case à lui tout seul ou presque
Du coup, il est à mon sens plus intéressant d’effectuer des distinctions selon ces éventuelles propriétés. Celle commune est en général la réduction de l’information à un résultat de taille fixe en permettant sa vérification. Ensuite, il y a des solutions qui produisent un résultat réversible ou non, plus ou moins unique, là on peut effectuer un classement.
Il y a forcément des usages qui impliquent de refuser certaines solutions, c’est notamment pour cela que l’on distingue l’usage des empreintes de manière général et dans le domaine de la cryptographie puisqu’elle implique de fait le besoin d’unicité (collision, préimage) et de non réversibilité (j’avais précisé d’ailleurs que je me plaçait dans ce contexte dans l’article pour éviter d’avoir à préciser la granularité d’informations ci-dessus ).
).
Merci ;)
Oui tu as raison, l’abus de vulgarisation est parfois un défaut, j’ai précisé le passage
Le 27/08/2021 à 06h32
Super intéressant, merci !
Le 27/08/2021 à 07h07
Merci pour le complément d’information.
Par contre, je me disais que le nom (Merkle) avait une forte proximité avec celui de la chancelière allemande - Angela Merkel - ben ça n’a pas loupé : https://www.google.com/search?hl=fr&q=arbre+de+merkel&nirf=arbre+de+merkle&sa=X&ved=2ahUKEwi9sZX-0dDyAhVGxhoKHdt0BNUQ8BYoAXoECAEQNw&biw=1707&bih=794&dpr=1.5 :)
Le 27/08/2021 à 07h44
Oui ça arrive souvent, c’est typiquement le genre de terme où je fais un check spécifique en fin d’écriture pour éviter de faire la connerie
Le 27/08/2021 à 08h15
J’imagine que s’il y a un article sur sed tu pourras ajouter cette commande :
sed -E -e s/Merkel/Merkle/gi -i article.md:PLe 27/08/2021 à 13h17
Tu confonds hash et hash cryptographique. Une fonction de hachage au départ c’est pour obtenir un condensat et accélérer des traitements. Par exemple, gzip utilise une fonction de hachage pour construire une table avec les hash, pour accélérer les comparaisons de chaînes de caractère (on commence d’abord par chercher dans les hash le hash de la chaîne considérée).
Non, un CRC32 peut très bien être utilisé comme fonction de hachage.
Le 30/08/2021 à 09h16
Super merci !
A quand une partie 2 plus étoffé ? :)
Le 30/08/2021 à 11h19
Plus étoffée sur quels points ? On parlera d’usages des MKT/DAG dans la suite
Le 31/08/2021 à 13h15
Bonne question n’ayant pas énormément de connaissance approfondie sur le sujet…
J’aurais bien aimé avoir des plus gros parallèles sur le bitcoin/git/DB, mais cela aurait sans doute dépassé le cadre original de cet article ;)
Le 31/08/2021 à 17h05
Leur vrai point commun ce sont les MKT justement. Pour le reste, les objectifs, usages et pratiques diffèrent pas mal.