Intelligence artificielle : l’explicabilité, cette notion « chiante »
Paf, amende

Dans un précédent article, nous nous sommes intéressés aux gains de productivité permis par l’intelligence artificielle chez les développeurs. Cette fois, nous nous penchons sur les notions d’explicabilité et d’interprétabilité. Liées à l’éthique et peu considérées jusqu’à présent, elles ont soudain été remises en avant par l’AI Act en Europe.
Lors de la BDX I/O, qui s’est tenue le 8 novembre au Palais des Congrès de Bordeaux, nous avons discuté avec bon nombre de développeurs. Il ressortait de leurs usages un recours massif de l’IA, sous forme d’assistants divers (principalement GitHub Copilot et Claude) pour gagner du temps, particulièrement sur les tâches rébarbatives.
Le même jour se tenait, parmi les présentations auxquelles nous avons assisté, une conférence de 45 min portant sur l’explicabilité et l’interprétabilité, par Cécile Hannotte, data scientist et ingénieure en mathématiques chez OnePoint. Une thématique « iceberg », car posant de nombreuses questions sur l’IA et les usages que l’on en fait.
Une question de confiance
De quoi parle-t-on ? Pour résumer, l’interprétabilité permet de comprendre ce que fait une IA, tandis que l’explicabilité consiste à savoir pourquoi elle a pris une décision spécifique. Ces deux thèmes étaient l’objet de la conférence et sont liés à de nombreux aspects pratiques de l’IA.
On s’en doute, les deux notions sont vectrices de confiance. L’ingénieure donnait un exemple. IBM avait présenté par exemple en 2016 une IA capable de détecter de manière efficace les cancers. L’IA ne s’est pas révélée par la suite à la hauteur des attentes. Mais, surtout, la réaction initiale des médecins qui l’avaient testée était le rejet : les conclusions et recommandations formulées n’étaient pas expliquées, en plus de patiner dès que l’on abordait des scénarios pourtant courants, comme les traitements de seconde intention.
Cécile Hannotte a ainsi détaillé le concept d’IA explicable, connue sous l’appellation XAI (qui existait bien avant qu’Elon Musk ne crée xAI). Elle est définie comme « un ensemble de processus et méthodes qui permettent aux utilisateurs humain de comprendre et de faire confiance aux résultats créés par les algorithmes ». La data scientist en plaisante : « Oui, c'est chiant, comme tout ce qui touche à l'éthique ».
L’explicabilité est, selon elle, appelée à jouer un rôle de plus en plus important à l'avenir. Actuellement, la course à la puissance et aux performances masque les autres facettes : il faut produire plus, plus vite, impressionner et être le premier, estime-t-elle. Mais avec l’arrivée de l’AI Act en Europe, les lignes vont bouger. L’explicabilité sera obligatoire selon les types d’algorithmes (sans même parler d’IA) et la nature des données sur lesquelles ces derniers agiront, en particulier sur les IA à haut risque amenées à manipuler des données personnelles. Des explications que réclament d'ailleurs les citoyens français.
Un calcul « simple », des décisions lourdes
Dans sa démonstration, Cécile Hannotte évoque le cas a priori simple d’une IA chargée de répondre rapidement sur la faisabilité d’un emprunt immobilier. Au-delà du fonctionnement, la thématique de l’explicabilité est au cœur du sujet, car le traitement implique des données sensibles (ici les informations financières d’un ménage).
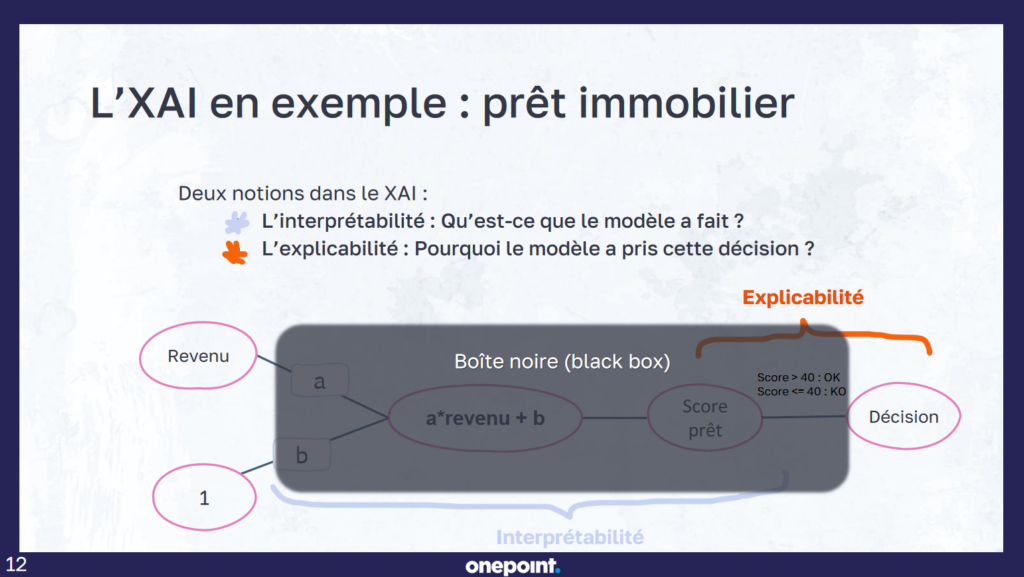
Il faut donc pouvoir fournir des explications aux usagers afin qu’ils comprennent pourquoi un algorithme a pris cette décision. Il s’agit non seulement d’établir une confiance, mais également d’éviter le phénomène de « boite noire ». L’explicabilité a aussi de l’intérêt dans la progression technologique, car elle permet de comprendre ce qui ne fonctionne pas. Par exemple, une photo de chat égyptien prise en extérieur peut faire dire à une IA qu’il s’agit d’un chien. Pourquoi cette erreur ? Parce que la plupart des photos de chats fournies à l’entrainement ont été prises en intérieur. Il y a donc la question des données en entrée, mais également de la pondération des différents critères qu’applique l’IA au moment de prendre une décision.
Cependant, l’explicabilité progresse lentement. S’ll y a des signes encourageants et que l’AI Act la rend obligatoire pour les traitements sensibles, elle reste pour l’instant reléguée au second plan, comme souvent avec les questions éthiques. Cécile Hannotte évoque un profil par plateaux dans la progression, quand les progrès de l’IA suivent – pour l’instant en tout cas – une courbe exponentielle. Pourquoi un tel écart ? À cause de la complexité des modèles.
Des barrières tangibles
Les démonstrations faites par Cécile Hannotte étaient volontairement simples, pour faire comprendre à l’audience le fonctionnement des IA, avec des paramètres que l’on pouvait compter sur les doigts d’une main. Mais les modèles utilisés aujourd’hui, particulièrement en IA générative, en comptent des milliards. Comment promouvoir l’explicabilité face à l’explosion des modèles actuels ? N’est-elle pas considérée comme un frein à l’innovation pour des entreprises comme OpenAI, Anthropic ou Mistral ?
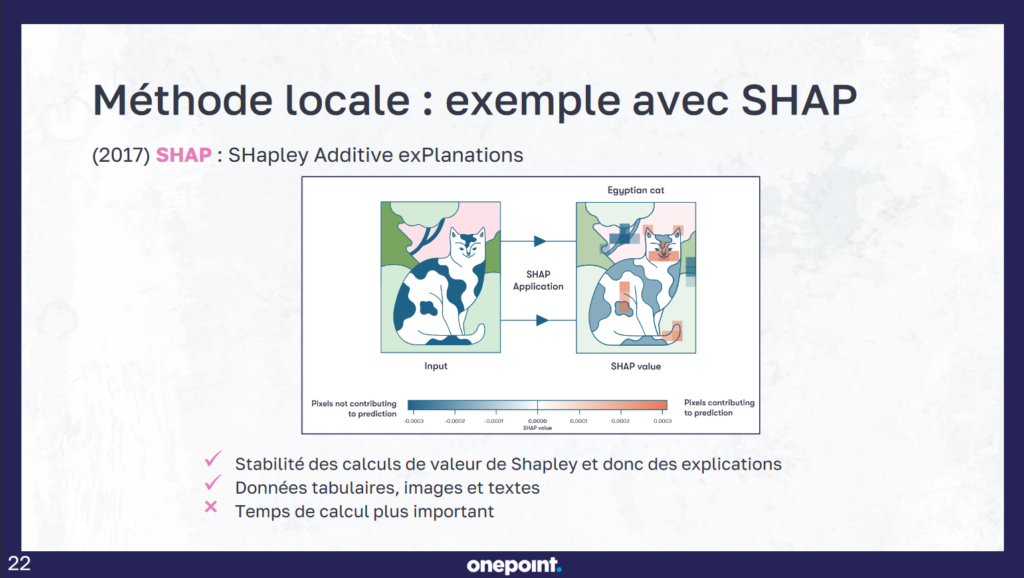
« Ça va même plus loin que ça », nous répond Cécile Hannotte. « Pouvoir expliquer une IA a un coût, qui n’est pas négligeable. Même dans un cas simple, il faut le multiplier par le nombre de prédictions, c’est d’autant plus un frein, car on applique des méthodes par-dessus d’autres méthodes ». Cette explicabilité peut être globale (pour tout le modèle) ou locale (pour un individu), s’appliquer à tout type de modèles (agnostique) ou au contraire spécifique à l’un d’eux. Certaines de ces méthodes étaient exposées durant sa présentation, dont LIME (Local Interpretable Model-Agnostic Explanations) et SHAP (SHapley Additive exPlanations).
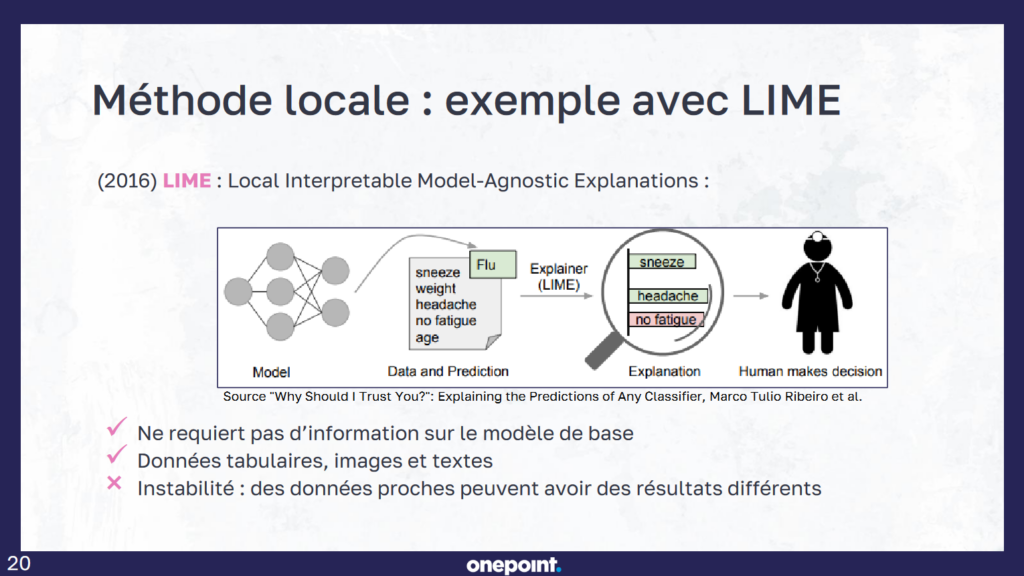
La première est une méthode locale et consiste en une forme de rétro-ingénierie. Par exemple, sur la base d’un modèle conçu pour établir un diagnostic de santé sur la base de symptômes, on fait entrer dans le modèle des données proches de celles de personnes réelles dont les informations ont déjà servi à établir des diagnostics. Puis on examine ce qui se passe. Au fur et à mesure, LIME va affiner les résultats et déduire progressivement le modèle en établissant une « boite blanche » (par opposition à la boite noire). Mais on ne sera jamais totalement sûr, l’approche étant empirique. En outre, comme pointé par Cécile Hannotte, la méthode peut se révéler instable, car des données proches peuvent avoir des résultats différents.
SHAP, plus complexe, a l’avantage de la stabilité des résultats. La méthode consiste à comprendre le poids des informations dans un modèle et n’hésite pas à supprimer certaines valeurs pour observer le comportement, jusqu’à modifier la prédiction cible. L’opération est cependant lente, car SHAP va calculer les valeurs de Shapley pour chaque caractéristique de cette prédiction cible.
Dans les deux cas, comme l’expliquait l’ingénieure, ces calculs consomment de la puissance et du temps, donc ont un coût. « Pas étonnant que peu d’entreprises le fassent », ajoute-t-elle.
Le mur de la complexité
On touche rapidement au cœur du problème en abordant la course actuelle à l’IA générale, qui saurait tout faire : « Je ne l’ai pas dit pendant la conférence, mais l’explicabilité, même si elle progresse, est forcément limitée par la complexité. On ne peut pas créer des boites noires qui expliquent des boites noires. Ce qu’on veut, c’est comprendre humainement, et il y a une limite à ce que l’on peut comprendre ».
Cécile Hannotte estime que l’explicabilité pourrait pourtant devenir un facteur de différenciation pour les entreprises qui se pencheraient réellement dessus, et donc un argument commercial. Le choix des données est crucial, mais ce n’est pas le seul élément. Elle prend pour exemple les systèmes d’IA que l’on voit arriver dans les processus de recrutement et les biais qui en découlent : les données posent problème, mais leur traitement aussi.
La thématique est d’autant plus vaste que de nombreux modèles d’IA aujourd’hui sont « auto-entraînés ». Les données sont ingérées par les modèles, qui déterminent d’eux-mêmes les critères importants. Au début de l’entrainement, l’IA commence par affecter des valeurs arbitraires à ces critères, puis va itérer avec une approche statistique. Lorsque l’on parle d’interprétabilité et d’explicabilité, les notions recouvrent ainsi l’ensemble des « choix » opérés par le modèle, y compris la pondération des différents paramètres.
La data scientist y voit d’ailleurs une forme d’avantage : « L’IA ne sait pas faire semblant, dans les grandes lignes elle fait ce qu’on lui a dit de faire. Si on estime que ses résultats posent problème, il faut s’interroger sur nos propres erreurs ». Et il faut encore savoir de quoi on parle quand on aborde la notion d’erreur : « Ce n’est pas simple, car l’éditeur peut s’être trompé dès les données fournies à son modèle. On peut se retrouver avec des erreurs qui sont plus à chercher du côté de l’overfitting (surapprentissage), quand le modèle a trop travaillé sur des données d’entrainement ou sur des données pas assez réalistes ».
L’explicabilité devrait ainsi gagner en importance, quand « la magie sera retombée », comme nous l’indiquait Marie-Alice Blete. Sans même parler des progrès explosifs des dernières années avec l’arrivée en fanfare de l’IA générative, cette notion permet de jeter un œil éthique et critique sur les traitements, en plus de comprendre ce qui a été fait. Avec des résultats aussi intéressants que, parfois, inquiétants. En 2017 par exemple, des chercheurs avaient créé un algorithme d’apprentissage profond capable de déterminer l’orientation sexuelle d’une personne à partir d’une photo de visage, avec une très grande précision : 94 % pour les hommes et 83 % pour les femmes. « Nos résultats mettent en évidence une menace pour la vie privée et la sécurité des hommes et des femmes homosexuels », notaient quand même les chercheurs.

Commentaires (14)
Abonnez-vous pour prendre part au débat
Déjà abonné ? Se connecter
Cet article est en accès libre, mais il est le fruit du travail d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles
Profitez d’un média expert et unique
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 22/11/2024 à 18h12
Le 22/11/2024 à 18h29
Le 22/11/2024 à 18h57
Modifié le 23/11/2024 à 10h58
Il faut aller vite, maintenant, tout de suite. Et c'est un mouvement qu'on rencontre partout en entreprise.
Petit feedback personnel : dans une organisation A en entreprise, plein de monde se plaint que c'est lent et lourd parce qu'il y a des process de qualité à respecter (surtout quand tu viens la fleur au fusil en espérant tout outrepasser sans rien préparer). Un scandale pour les PO car Saint TTM est impacté par tout une bureaucratie inefficace. Dans l'organisation B, on donne l'outil et l'autonomie aux projets pour qu'ils délivrent rapidement.
Constat réalisé par mon expérience sur ce genre d'organisation :
Dans A : on avait un minimum de documentation sur les produits, car le process qualité exigeait un doc d'architecture, une liste de critères de sécu, et des workflows de delivery qui intègrent des tests unitaires, qualité et sécurité (sans oublier la revue de code). Ca demandait juste un peu de préparation côté projet, mais quand on maîtrise son sujet (ce qui est rarement le cas des projets métier, hélas), ça va vite.
Dans B : pas de doc, pas de test unitaire, pas de check sécurité, un test rapide sur un bac à sable de dev et go prod. Ça délivre de la feature à tout va et dès qu'on parle de sécurité ou qu'on commence à demander comment ça marche, y'a plus personne. Dès qu'on creuse un peu sur comment ça a été fait, on hurle. Et, évidemment, quand Jean Michel Dev est parti, la boîte a perdu sa connaissance métier.
Bref, on est dans la mouvance standard du moment. Généralement, quand l'entreprise se prend un mur (souvent financier) parce que le YOLO a engendré un piratage ou un crash métier, ça fait revoir les priorités.
C'est effectivement l'une des trois méthodes de machine learning : le supervisé, le non supervisé (celui cité ici), et le renforcement. Dans le premier, on lui donne un jeu de données déjà qualifié et il apprend dessus. Dans le second, il apprend à étiqueter par lui-même. Dans le troisième, il se trouve dans l'environnement (cas des véhicules autonomes) et apprend par l'expérience avec récompense / pénalité.
Pourquoi j'y vois de la physiognomonie 2.0 ?
En tous cas, merci pour ce compte rendu. Les propos sont super intéressants :)
Le 23/11/2024 à 14h41
Je retiens cette phrase frapante d'un client : "peu importe que l'on ai crée de la dette technique inextricable si dans un mois on est plus là car on a pas avancé assez vite".
Le 23/11/2024 à 16h09
Le 25/11/2024 à 22h00
J'ai réactualisé mon CV, un bon quart du service est déjà parti.
Le 26/11/2024 à 08h10
Modifié le 23/11/2024 à 20h02
https://www.darpa.mil/program/explainable-artificial-intelligence
"Explainable Artificial Intelligence (XAI) (Archived)"
https://onlinelibrary.wiley.com/doi/10.1002/ail2.61
"DARPA's explainable AI (XAI) program: A retrospective"
---------------
"Defense Advanced Research Projects Agency (DARPA) formulated the explainable artificial intelligence (XAI) program in 2015 with the goal to enable end users to better understand, trust, and effectively manage artificially intelligent systems. In 2017, the 4-year XAI research program began. Now, as XAI comes to an end in 2021, it is time to reflect on what succeeded, what failed, and what was learned. This article summarizes the goals, organization, and research progress of the XAI program."
----------------
Et la raison est simple:
il est hors de question de payer des milliards de $ pour envoyer des systèmes autonomes (i.e non contrôlés par un être humain) faire des conneries sur un champs de bataille sans pouvoir comprendre pourquoi = la capacité de 'débriefer' une IA comme on debrieferai n'importe quel soldat ayant fait une operation speciale en ukraine par exemple :)
Donc effectivement, le besoin de précipitation et d'innovation pour briller dans les salons se heurte toujours aux exigences de personnes responsables qui n'ont pas le même sens de l'humour que les (grand ?) patrons de la tech :)
Le 23/11/2024 à 21h37
1 - Une IA sera toujours une boîte noire selon moi, sinon il faut tester tous les scénarios possibles et les réponses obtenues, ce qui est rapidement impossible.
2 - Lire qu'une décision peut être prise par une IA me fait bondir. Une IA peut apporter de l'aide à décision mais il ne faut pas la laisser avoir le dernier mot.
Le 23/11/2024 à 22h51
La décision doit rester chez l'humain de mon point de vue.
Pour faire un parallèle, c'est comme porter un projet devant un comité. Les chefs n'auront pas forcément la capacité de comprendre tous les détails, et c'est pas ce qu'on leur demande. Ce qu'ils attendent, c'est une explication sur les enjeux, le coût, le ROI attendu, le risque à faire, à ne pas faire, etc, pour prendre une décision. Ici, le rôle de l'IA est de fournir ces éléments de prise de décision, pas de donner le "go projet".
Hélas, il y a encore trop de fantasmes dans le domaine pour utiliser ces outils de manière intelligence. Et quand je vois le nombre de personnes dans l'IT qui boivent les paroles de ChatGPT sans comprendre le fonctionnement ou les limites de l'outil, je me dis qu'on a pas le cul sorti des ronces.
Le 25/11/2024 à 10h12
Modifié le 24/11/2024 à 08h56
Le 25/11/2024 à 14h03