

[Tuto] Intelligence artificielle : les dangers du surapprentissage, comment l’éviter
Quantité vs qualité !
![[Tuto] Intelligence artificielle : les dangers du surapprentissage, comment l’éviter](https://next.ink/wp-content/uploads/2024/09/Surentrainement.webp "[Tuto] Intelligence artificielle : les dangers du surapprentissage, comment l’éviter")
Au début de l’été, on s’était dit que c’était une bonne idée de vous donner un maximum de clés pour bien comprendre l’intelligence artificielle. Elle a fait un bond avec les IA génératives, on en parle souvent, mais on ne cerne pas toujours son fonctionnement.
Pour cela, rien de mieux que mettre les mains dans le cambouis. Cela tombe bien, développer et entrainer une IA ne demande pas plus de 10 lignes de codes. On a ensuite regardé l’influence de la quantité de données et des couches de neurones sur les performances de notre IA. Penchons-nous aujourd’hui sur un phénomène bien connu : le surentrainement ou surapprentissage.
- [Tuto] Intelligence artificielle : l’importance des données d’entrainement
- [Tuto] L’influence des couches de neurones sur l’intelligence artificielle
Petit rappel pour les retardataires. Nous utilisons le jeu de données du MNIST qui contient 60 000 images de 28 x 28 pixels représentant un chiffre. Chaque image est étiquetée : on sait à quel chiffre elle correspond. 10 000 images, également étiquetées, permettent ensuite de tester le modèle.
Comme nous l’avons déjà expliqué, lors de la phase d’entrainement nous faisons tourner notre algorithme plusieurs fois sur le même jeu de données – on parle d’epoch ou époques – pour améliorer ses performances. En l’occurrence, pour ajuster au mieux les (dizaines/centaines) milliers de paramètres – poids et biais – de chaque neurone.
Surentrainement, surapprentissage, surajustements… Késako ?
On pourrait être tenté de multiplier les époques pour affiner correctement le modèle, mais ce n’est pas un pari toujours gagnant. On arrive même parfois au résultat inverse avec un modèle qui devient « trop bon » sur les données d’entrainement, sans être capable de généraliser son résultat lorsqu’il est confronté à de nouvelles données.
C’est ça le surentrainement ou surapprentissage. La CNIL en donne la définition suivante : « Le surapprentissage entraîne un modèle qui correspond trop précisément à une collection particulière de données utilisées pour l’entrainement. Cette analyse risque de ne pas correspondre à des données utilisées en phase de production et donc de ne pas permettre une utilisation fiable du système d’IA ».
Amazon Web Services classe le surentrainement dans une famille plus grande de « surajustements ». On y retrouve également un jeu des données d’entraînement trop petit. Il y a aussi le fait que « les données d’entraînement contiennent de grandes quantités d’informations non pertinentes, appelées données bruyantes » et « la complexité du modèle [trop] élevée, de sorte qu’il apprend le bruit contenu dans les données d’entraînement ».
En faire plus n’est pas toujours synonyme de faire mieux
Pour mettre cette problématique en pratique, nous avons utilisé le programme suivant (toujours dans Google Colab, qui fonctionne sans avoir besoin de payer un abonnement ou des crédits) :
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test)= mnist.load_data()
x_train, x_test = x_train / 256.0, x_test / 256.0
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28,28]))
model.add(keras.layers.Dense(20, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
model.summary()
model.compile(loss="sparse_categorical_crossentropy", metrics=['accuracy'])
history = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=1000, verbose=0)
model.evaluate(x_test, y_test)
plt.plot(history.history['loss'], label='Perte entrainement')
plt.plot(history.history['val_loss'], label='Perte test')
plt.plot(history.history['accuracy'], label='Précision entrainement')
plt.plot(history.history['val_accuracy'], label='Précision test')
plt.legend()
plt.show()Oui, on « triche » un peu avec seulement 20 neurones sur la couche intermédiaire, afin de pouvoir bien mettre en lumière le phénomène de surentrainement. Avec plus de neurones, c’est bien moins visible. Petit changement dans la ligne « model.fit » avec une mesure de validation à chaque époque (qui sont au nombre de 1 000) sur les données de test. Le verbose=0 permet de ne pas lister dans le navigateur toutes les étapes de calculs.
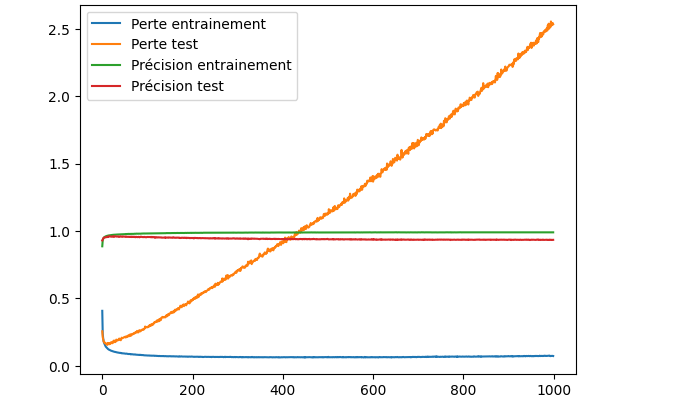
On récupère le tout à la fin pour afficher les résultats sous forme de graphique :

On peut voir que la perte sur les données de test (en orange) baisse assez rapidement, mais grimpe tout aussi vite au bout de quelques époques. C’est assez peu visible, mais la courbe de la précision sur les données de test est légèrement descendante alors que celle sur l’entrainement ne bouge pas d’une précision de 100 % au fil des époques.
Si on ne se base que sur les données d’entrainement, on a l’impression que le modèle s’améliore (la perte diminue, la précision reste à 100 %). Mais une fois mis en pratique face à de nouvelles données, c’est tout l’inverse.
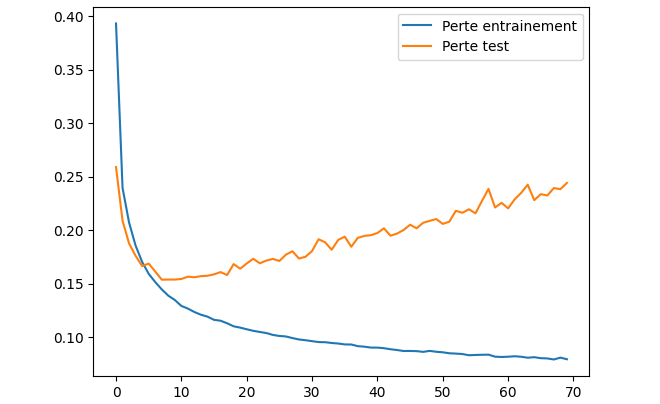
Dans ce cas précis, le nombre idéal d’époques pour obtenir le meilleur résultat sur notre modèle est assez faible, une dizaine (comme on peut le voir sur le graphique ci-dessous, avec seulement les pertes sur 70 époques). Nous allons y revenir juste après.
DropOut : de l’aléatoire dans l’activation des neurones
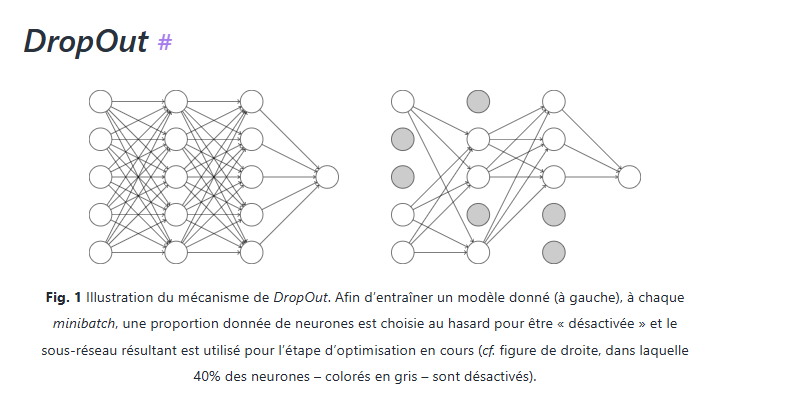
Il existe des solutions pour contourner ce problème. Citons, par exemple, la fonction DropOut. Son but est « d’éteindre certains neurones pendant l’apprentissage. Les neurones désactivés changent à chaque minibatch de sorte que, globalement, tous les neurones sont entraînés pendant tout le processus », explique Romain Tavenard, professeur à l’université de Rennes 2.
Les neurones actifs ou désactivés changent de manière aléatoire à chaque époque. À chaque apprentissage, le modèle apprend donc avec une configuration de neurones différente, évitant ainsi à notre IA d’apprendre « le bruit ».
Une illustration du principe de fonctionnement :
Ok, mais comment ajouter ceci à mon programme ? Facile, avec une ligne supplémentaire sous la couche de neurones sur laquelle (ou lesquelles) on veut ajouter un peu de fantaisie de hasard dans l’activation des neurones. Dans l’exemple ci-dessous, la probabilité est de 10 % :
model.add(keras.layers.Dropout(0.9))EarlyStopping : stop ou encore ? C’est une métrique qui décide
Une autre approche est d’utiliser la fonction EarlyStopping. Comme son nom l’indique, elle permet d’« arrêter le processus de formation plus tôt si une certaine condition est remplie », explique l’EITCI (Institut européen de certification des technologies de l’information).
On évite ainsi le surapprentissage si la métrique surveillée ne s’améliore plus au bout d’un certain nombre d’époques. « Un arrêt précoce peut économiser des ressources de calcul et empêcher le modèle d’apprendre des modèles spécifiques aux données d’entraînement mais qui ne se généralisent pas bien aux données invisibles ». On économise donc de l’énergie et du temps, tout en ayant de meilleures performances. Combo gagnant.
Voilà un exemple d’intégration dans l’entrainement du modèle. Il faudra remplacer le « x » de la première ligne par le nombre d’époques pendant lequel notre métrique (val_loss, soit la perte sur les données de validation) ne s’améliore plus :
early_stopping_callback = keras.callbacks.EarlyStopping(monitor=’val_loss’, patience=x)
history = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=50, callbacks=[early_stopping_callback])
Avec « patience=3 », notre entrainement s’arrête au bout de 14 époques sur les 50 prévues normalement pour l’entrainement.
ModelCheckpoint : comme dans les jeux, il y a des points de sauvegarde
Par ailleurs, il y a également le ModelCheckpoint. Cette fois-ci, le logiciel enregistre « le meilleur modèle pendant le processus de formation ». Là encore, on peut surveiller une métrique spécifique, comme la perte ou la précision.
Point intéressant : cette fonction permet « d’enregistrer les poids du modèle chaque fois que la métrique surveillée s’améliore. Ce rappel est particulièrement utile lors de la formation de modèles de deep learning, car il nous permet de conserver le modèle le plus performant et d’éviter de perdre la progression en cas d’interruptions ou de surajustement ».
Voici aussi un exemple, où « best_model.h5 » est le nom du fichier avec les paramètre et monitor la métrique à surveiller :
checkpoint_callback = keras.callbacks.ModelCheckpoint(filepath=’best_model.keras’, monitor=’val_loss’, mode=’max’, save_best_only=True)
history = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=50, callbacks=[checkpoint_callback])

Commentaires (6)
Le 20/09/2024 à 11h17
"Je vous donne un exemple : Je vous dis Laurel vous me répondez Hardy
...
Le 20/09/2024 à 11h34
Le 20/09/2024 à 12h43
J'avais lu "Quand la machine apprend" de Yann Le Cun (très intéressant aussi d'ailleurs) mais là on rentre dans des finesses de l'apprentissage qu'il n'y aborde pas. (peut-être d'ailleurs parceque non pertinente à l'époque du livre?)
Le 20/09/2024 à 19h57
J’ai jamais lu ce livre, je vais mettre sur ma todo si c’est intéressant :)
Le 21/09/2024 à 12h51
Il n'y a aucun doute que Yann LeCun connaisse le surapprentissage. Il faut voir si c'était pertinent dans le contexte du livre. Je n'ai pas lu le bouquin, je ne sais pas ce qu'il y a dedans. Mais s'il aborde les réguarisasion L1 (lasso), L2 (ridge), dropout et early stopping par exemple, implicitement, il considère le surapprentissage.
Le 20/09/2024 à 13h31
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?