

IA générative : quels modèles sont vraiment ouverts
IA ouvre toi !

Dans l’IA générative comme dans d’autres domaines du numérique, le mot « open » peut attirer avec ses promesses de transparence, de traçabilité, de sécurité ou de réutilisation possible. S’il est beaucoup utilisé de façon marketing, le nouvel AI Act européen prévoit des exemptions pour les modèles « ouverts ». Des chercheurs néerlandais ont classé 40 modèles de génération de textes et six modèles de génération d’images se prétendant « open » par degré d’ouverture réelle.
Dans un article (.pdf) présenté à la conférence scientifique FAccT 2024 cette semaine, deux chercheurs de l’université néerlandaise de Radboud se sont penchés sur les degrés d’ouverture des modèles d’IA génératives présentés comme « open » par leurs créateurs. Le moins que l’on puisse dire est que la notion d’ouverture n’est pas la même pour tout le monde.
Comme nous l’évoquions en septembre dernier, le mot « open » dans le milieu de l’IA générative est souvent utilisé de manière marketing et il est difficile de s’y retrouver. On voit, de fait, une tendance à ce que certains appellent de l’ « open washing » : utiliser le terme un peu partout pour qualifier des modèles qui sont parfois très peu ouverts.
À l’époque, le sociologue David Gray Widder et les deux chercheuses Sarah Myers West et Meredith Whittaker expliquaient que « certains systèmes décrits comme « ouverts » ne fournissent guère plus qu’une API et une licence autorisant la réutilisation, comprenant la commercialisation de la technologie ».
L’ « open » prend du poids avec l’AI Act
Mais pour les deux chercheurs néerlandais en traitement automatique des langues Andreas Liesenfeld et en linguistique Mark Dingemanse, la question est d'autant plus importante que l'AI Act européen permet des exemptions à des modèles qui seraient « ouverts ».
Ils citent notamment les passages de la législation sur l'intelligence artificielle selon lesquels :
-
- « les logiciels et les données, y compris les modèles, publiés dans le cadre d'une licence libre et ouverte grâce à laquelle ils peuvent être partagés librement et qui permet aux utilisateurs de librement consulter, utiliser, modifier et redistribuer ces logiciels et données ou leurs versions modifiées peuvent contribuer à la recherche et à l'innovation sur le marché et offrir d'importantes possibilités de croissance pour l'économie de l'Union »
-
- « [les modèles publiés sous licence libre et ouverte] devraient faire l'objet d'exceptions en ce qui concerne les exigences en matière de transparence imposées pour les modèles d'IA à usage général ».
Les chercheurs s'appuient sur la version du texte du 24 février dernier, mais les passages cités sont toujours présents dans la dernière version en date (pdf en anglais, pdf en français).
Dans cette dernière version, l'Union européenne définit comme « ouvert » un modèle s'il est fourni sous une licence « permettant de consulter, d'utiliser, de modifier et de distribuer le modèle, et dont les paramètres, y compris les poids, les informations sur l'architecture du modèle et les informations sur l'utilisation du modèle ».
Ces modèles « ouverts » sont exemptés par le texte de fournir au nouveau Bureau de l'IA de l'Union européenne (créé par l'AI Act) une documentation technique du modèle à jour y compris son processus d'entrainement, les processus de tests et les résultats des évaluations (avec des exigences détaillées).
Dans leurs conclusions, les deux chercheurs expliquent que l'AI Act risque de se lier à une « cible mouvante : celle de la définition de l'IA open source basée sur une licence qui elle-même évolue ». Et que cette définition fera l'objet de pressions des lobbies de l'industrie.
Un « open washing » industriel
Comme leurs collègues cités plus haut, ils dénoncent l' « open washing » d'une très grande partie du milieu.
« Un signe clé de l'open washing est l'augmentation de ce qu'on appelle la stratégie de la publication par billets de blog » expliquent-ils. « La plupart des modèles d'IA générative ouverts publiés l'année dernière ont été rendus publics pour la première fois dans un billet de blog ou un communiqué de presse promouvant leur ouverture », ajoutent les chercheurs.
« Par exemple, TII’s Falcon 70B a été présenté comme "le modèle d'IA open-source de premier rang", Stable Beluga de StabilityAI comme en "accès ouvert", Mistral a proclamé "nous avons les meilleurs modèles open source", Yi 34B Chat de 01.ai a proclamé être "la nouvelle génération de LLM open-source et bilingue" et Alibaba a revendiqué "nous opensourçons nos séries Qwen" » égrainent-ils.
Mais selon eux, « les revendications probablement les plus fortes pour étiqueter ses modèles open-source viennent de Meta et de ses modèles Llama et Llama 3. Les billets de blogs de l'entreprise ont présenté Llama avec les revendications suivantes » :
-
- « Aujourd'hui, nous présentons la disponibilité de Llama 2, la nouvelle génération de notre LLM open source »
-
- « Depuis plus d'une décennie, Meta place la recherche exploratoire, l'open source et la collaboration avec des partenaires universitaires et industriels au cœur de ses efforts en matière d'IA. »
-
- « Aujourd'hui, nous présentons Meta Llama 3, la nouvelle génération de notre grand modèle de langage open source à la pointe de la technologie. »
Mais pour les chercheurs, ces billets de blogs qui montrent très souvent des comparaisons (benchmarks) permettent de ressembler à du travail scientifique tout en évitant « l'examen par les pairs qui accompagnent les publications scientifiques proprement dites ». Ils alertent aussi sur le fait que les tableaux de comparaison proposent des degrés élevés de recours au « cherry-picking » (technique consistant à montrer les résultats qui nous arrangent et à cacher les autres).
Si ces chercheurs râlent sur l' « open washing », ce n'est pas seulement pour des questions de principe. Ils expliquent que celui-ci a des « conséquences considérables et touchent de multiples parties prenantes » : obstacles à l'innovation des petites entreprises du secteur, obstacles aux chercheurs qui ne peuvent réellement travailler sur des modèles ouverts, et obstacles à la compréhension de l'IA par le grand public « parce qu'il crée des artefacts conçus pour impressionner sans fournir aux gens les ressources nécessaires pour parvenir à une compréhension plus profonde de la technologie ».
Enfin, ils expliquent que l'« open washing » est un « audit washing ». C'est-à-dire que, comme l'expliquaient déjà en novembre 2022 les chercheuses Ellen P. Goodman et Julia Tréhu, « des audits sans standards clairs fournissent une fausse assurance de conformité ».
Une définition plus graduelle
Les deux chercheurs néerlandais plaident donc pour une définition beaucoup plus fine et graduelle de ce que serait un modèle d'IA ouvert. Et ils proposent tout un panel de critères de jugement pour savoir si un modèle est plus ou moins ouvert, rangés dans trois grandes catégories : la disponibilité, la documentation et l'accès.
Ils expliquent par exemple que concernant la disponibilité du code, « nous constatons que BloomZ met à disposition le code source pour l'entraînement, le fine-tuning et l'exécution du modèle, tandis que pour Llama, aucun code source du modèle n'est mis à disposition, seuls les scripts pour l'exécution du modèle sont partagés ».
Même chose avec la documentation. Puisque le code de Llama 2 n'est pas disponible, sa documentation l'est encore moins, alors que le code de BloomZ est « très bien documenté » et que sa documentation est « activement maintenue ». De même, l'architecture de BloomZ est décrite dans de multiples articles scientifiques accompagnés par un dépôt Github et des recettes sur HuggingFace, alors que l'architecture de Llama est décrite avec moins détails et « éparpillée sur les sites web de l'entreprise et un article scientifique en prépublication ».
Bref, après avoir défini des critères d'ouvertures, les deux chercheurs néerlandais proposent deux premiers classements des modèles d'IA ouverts (un pour les générateurs de textes et un autre pour les générateurs d'images).
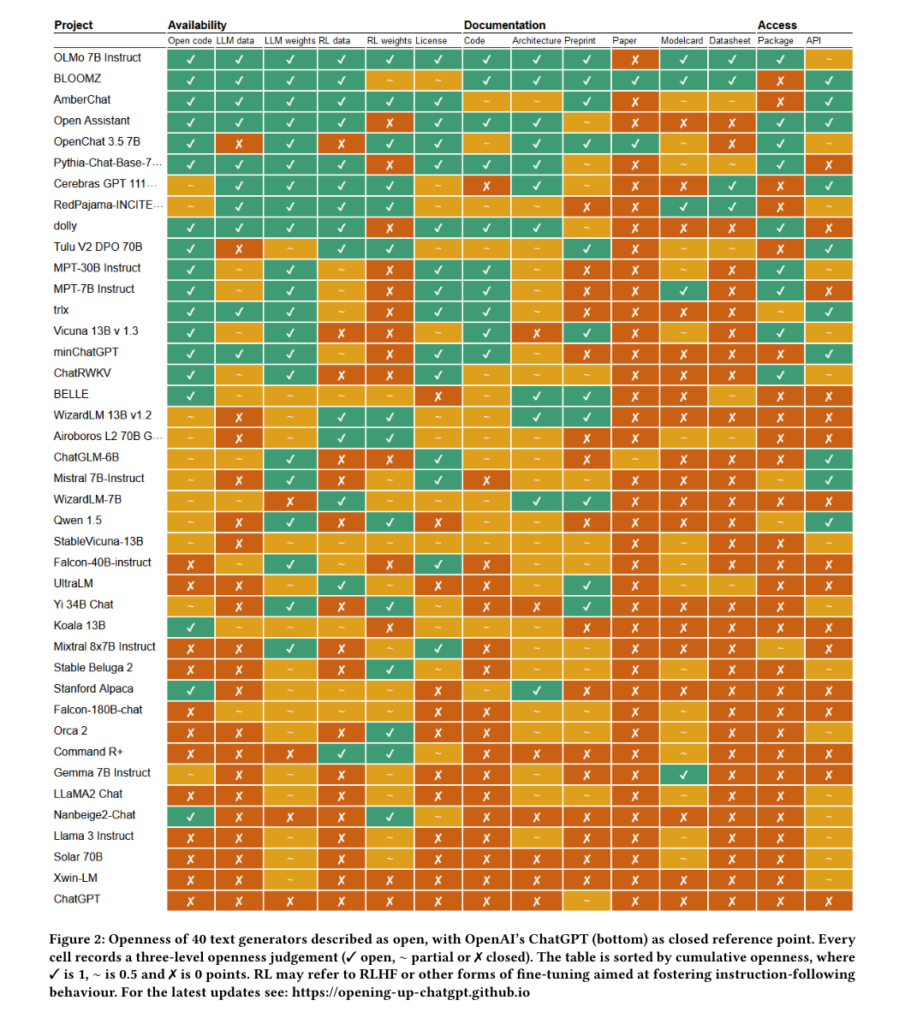
OLMo-7B-Instruct et BloomZ : les deux générateurs de texte les plus ouverts
Du côté de la génération de texte, OLMo-7B-Instruct et BloomZ sont clairement les modèles les plus ouverts : leurs codes sont disponibles, les données d'entrainement et les poids aussi. Ces deux modèles donnent aussi les données d'entrainement pour le réglage des instructions (RL data). Leur documentation permet une réelle réutilisation du code et du modèle et ils sont disponibles soit via un paquet, soit via une API.
La référence du tableau, tout en bas, est ChatGPT qui n'a d'ouvert quasiment que le mot « open » dans le nom de l'entreprise qui l'a créé.
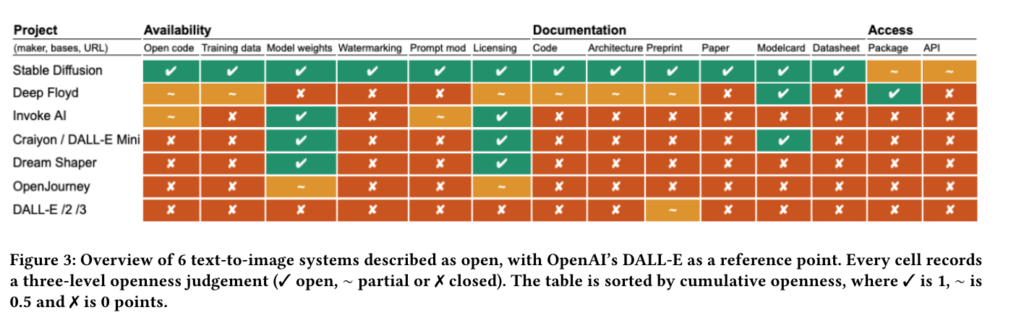
Stable Diffusion bien seule, côté de la génération d'images
Pour la génération d'images, la revendication de l'ouverture a moins de candidats. Les deux chercheurs en ont listés six avec Dall-E comme référence de fermeture. Et c'est Stable Diffusion qui coche seul quasiment toutes les cases de l'ouverture.
Alors que nous sommes confrontés à deux conceptions contradictoires de l'ouverture, pour ces chercheurs, « entre l'ouverture radicale et l'ouverture homéopathique se trouve l'ouverture qui a du sens ».
Dans leur article, les chercheurs pointent plusieurs limites de leurs travaux. La première est celle qui parait actuellement comme la plus évidente : ces classements ne prennent pas en compte des nouveaux modèles « multimodaux » comme GPT-4, Gemini et DeepFloyd (de Stability AI). Mais ils expliquent que les degrés évalués sont réfléchis pour qu'ils soient applicables à tout système d'IA générative.
Ils ajoutent aussi que pour tous les modèles, y compris les plus ouverts, les informations sur les données d'apprentissage sont « très superficielles » : la plupart ne partagent pas directement les données d'entrainement. Mais la procédure d'entrainement est aussi parfois complexe à décrire quand il s'agit d'expliquer concrètement quelles données ont servi à quoi.
Enfin, ils rajoutent un petit mot pour insister que l'ouverture n'est pas toujours bonne et que le huis clos est parfois nécessaire, citant par exemple le cas des données sur les violences pédocriminelles.

Commentaires (4)
Le 07/06/2024 à 17h53
Le 07/06/2024 à 18h04
Les modèles ont été entraînés avec un dataset qui était publiquement disponible, issu de l'organisme allemand LAION.
LAION-5B ayant servi à entraîner les modèles est toujours offline.
Les modèles de base de Stable Diffusion ont été entraînés avec trois sous ensembles issus de LAION-5B : LAION-2B EN, LAION High Resolution et LAION Aesthetics (pas retrouvé le repo précis).
Pour rappel, il fut désactivé en raison de contenus considérés comme problématiques identifiés dedans.
Dans tous les cas, les données sont issues de Common Crawl.
Le 08/06/2024 à 11h45
Modifié le 08/06/2024 à 21h44
Et alors la phrase finale est tellement blasphématoire que c'est jouissif.
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?