Git remote : comment héberger vos documents et codes source sur un serveur
Le vôtre si possible

Notre dossier sur la maîtrise de Git et de ses plateformes :
Utiliser Git pour gérer les versions de vos données localement est une chose, mais on est souvent amené à travailler sur ses fichiers depuis différentes machines ou en équipe. Dès lors, comment faire ? Il suffit d'utiliser un dépôt distant via un service clé en main ou votre propre serveur.
Comme évoqué dans un précédent article consacré au gestionnaire de versions Git, l'un de ses points forts, qui a notamment fait son succès à ses débuts, est sa conception non pas décentralisée, mais distribuée.
En plus de ne pas dépendre d'un serveur central comme SVN (par exemple), chacun peut disposer du sien, le faire échanger avec n'importe quel autre, comme bon lui semble. Chaque utilisateur peut disposer de sa propre copie locale ou distante d'un dépôt, l'héberger sur le ou les serveurs de son choix.
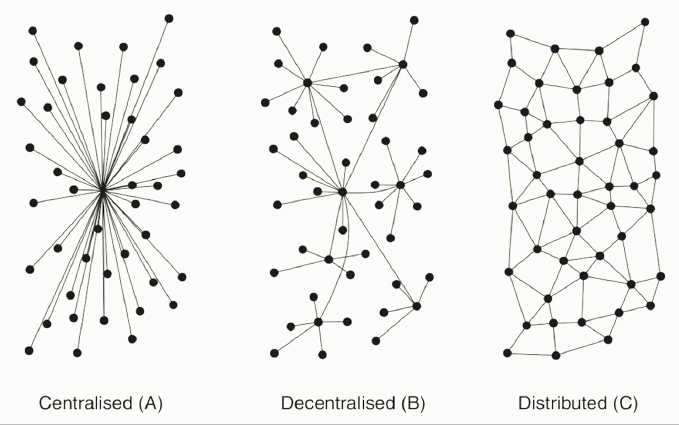
Un point souvent oublié avec l'utilisation courante de services en ligne tels que BitBucket, GitLab ou GitHub qui ont tendance à « recentraliser » l'utilisation de Git. C'est pourtant ce qui permet de travailler facilement seul ou à plusieurs sur de même données, que ce soit à travers un réseau local ou Internet.
En langage Git, un dépôt distant est nommé « remote ». Voyons aujourd'hui comment en créer un et l'utiliser, que ce soit sur un Raspberry Pi, un NAS ou chez un hébergeur. Si Git propose nativement une solution exploitable via la ligne de commandes, il existe des alternatives avec interface web simple à installer.
- Open source, libre et communs : contribuer ne nécessite pas de développer
- Apprenez à utiliser Git : les bases pour l'évolution d'un document
- Git remote : comment héberger vos documents et codes source sur un serveur
- Git : comment travailler avec plusieurs remotes
- Fork et pull request : la participation open source par l'exemple
- GitHub CLI 1.0 est disponible : comment l'installer et l'utiliser
Git remote : premier contact
Dans cet article nous partirons du principe que vous disposez des bases concernant les concepts de Git et que vous l'avez d'installé sur votre machine. Si ce n'est pas le cas, nous vous invitons à lire notre précédent tutoriel.
Pour comprendre ce qu'est un dépôt distant (ou remote), nous allons en utiliser un déjà existant : celui de notre article sur la création d'un site internet statique, hébergé sur la plateforme GitHub. L'action que nous allons effectuer est nommée « clone » en langage Git. Elle consiste à créer un dépôt local sur notre machine pour y placer le contenu d'un dépôt distant. Il sera alors automatiquement considéré comme son remote.

 GitHub, comme la plupart des services d'hébergement Git, indique l'URL à utiliser pour cloner un dépôt
GitHub, comme la plupart des services d'hébergement Git, indique l'URL à utiliser pour cloner un dépôt
Voici la commande à taper :
git clone https://github.com/davlgd/pwa-static-winget.git
Cela ne prend que quelques secondes, le projet étant assez léger. Un dossier nommé pwa-static-winget a été créé dans le dossier courant. Ce n'est pas simplement ses fichiers qui ont été récupérés, mais également tout leur historique. Outre le statut du dépôt, on peut demander à visualiser le graphique des commits par exemple :
cd pwa-static-winget
git status
git log --graph --oneline
On peut alors demander à obtenir les informations concernant les remotes du dépôt :
git remote -v
Le « -v » (verbose) est ici utilisé pour demander un affichage détaillé, qui permet d'obtenir les URL :
origin https://github.com/davlgd/pwa-static-winget.git (fetch)
origin https://github.com/davlgd/pwa-static-winget.git (push)
Le dépôt GitHub est nommé « origin ». Il s'agit d'une convention Git qui désigne en général le remote principal, utilisé par défaut. Il est ici utilisé pour deux actions différentes : fetch et push. Elles consistent à récupérer les fichiers depuis le dépôt ou à l'inverse d'envoyer le contenu du dépôt local au serveur. Nous y reviendrons plus loin.

Récupération d'un dépôt « nu »
Outre le fait d'être distant, quel est l'autre élément distinctif d'un remote ? Il s'agit d'un dépôt « bare » ou nu. La documentation de Git les définit comme « un dépôt qui ne contient pas de copie de répertoire de travail ». Pour voir ce qu'il en est en pratique, récupérons les données de notre projet GitHub dans un tel dépôt :
cd ..
git clone --bare https://github.com/davlgd/pwa-static-winget.git
Vous noterez une première différence : le dossier créé est nommé cette fois pwa-static-winget.git. Et si vous naviguez en son sein, vous ne verrez plus les données du dépôt directement exploitables. Elles sont organisées telles qu'elles sont utilisées par Git (objets, références, etc.) avec des fichiers de configurations et autres scripts.
Il s'agit en réalité du contenu du dossier (caché) .git que l'on trouve dans les dépôts classiques. L'ensemble occupe donc moins d'espace : 144 ko pour 52 fichiers (41 dossiers) contre 264 ko pour 71 fichiers (50 dossiers).
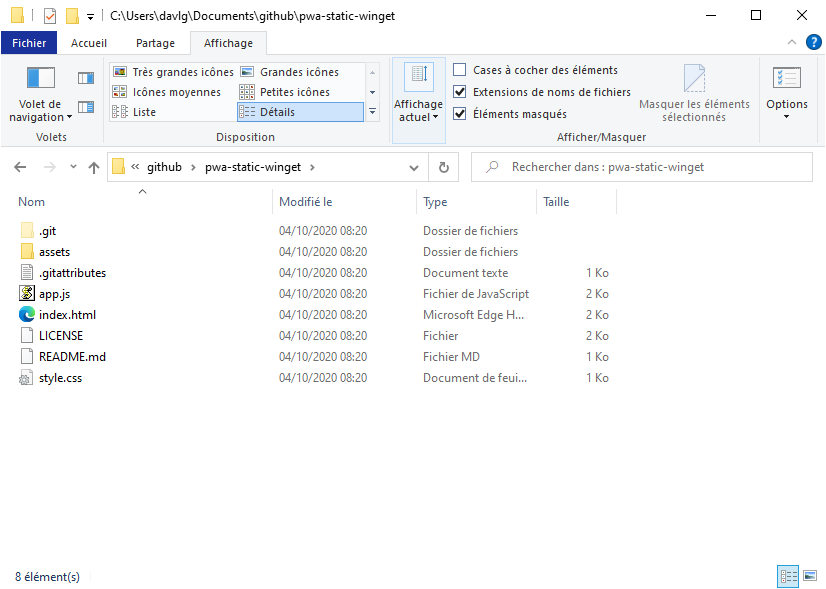
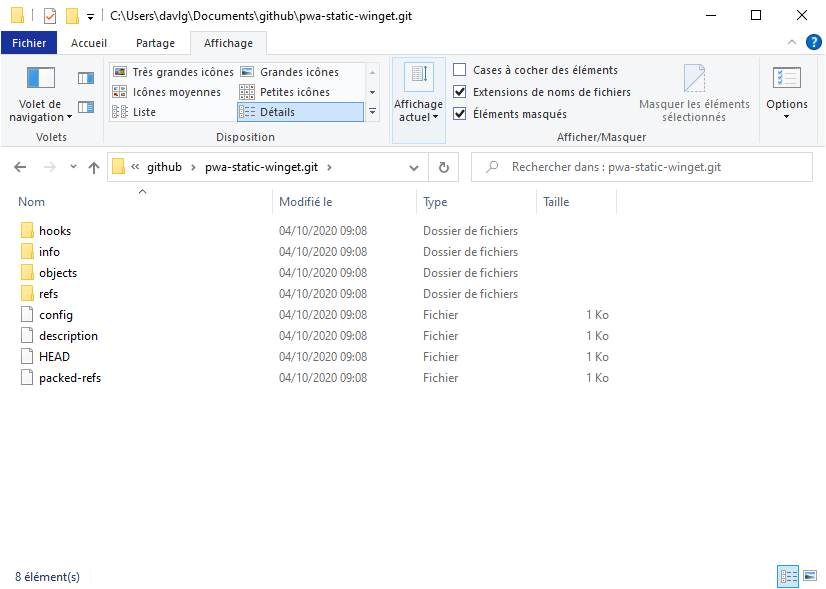
À gauche le dépôt classique avec fichiers de travail et techniques (.git), à droite le dépôt nu avec seulement les données techniques
Installation de Git sur votre serveur
Il faut donc voir un dépôt nu comme un simple outil technique, qui n'a pas vocation à être utilisé directement mais seulement comme source/destination pour d'autres dépôts. Comment en mettre un en place dans la pratique ? C'est finalement assez simple. Vous pouvez le faire sur votre machine locale et même l'utiliser comme remote, mais cela n'aurait que peu d'intérêt. Nous allons le faire sur un serveur distant (sur votre réseau local ou via Internet).
Pour cela, installez Git sur un serveur comme un Raspberry Pi, un NAS ou chez un hébergeur. Dans tous les cas, il vous faudra un accès au terminal de la machine, via le protocole SSH par exemple. Pour un Raspberry Pi, vous pouvez suivre l'un de nos guides d'installation de Raspbian OS, Manjaro ou Ubuntu.
S'il n'est pas présent par défaut, installez Git. Par exemple via APT sous Debian ou ses dérivés :
sudo apt install git
N'oubliez pas que vous pouvez faciliter l'accès en utilisant une paire de clé publique/privée plutôt qu'un mot de passe. Cela peut même être renforcé par une clé de sécurité physique. Tout est détaillé dans un précédent tutoriel. Pensez également à créer les comptes des utilisateurs devant avoir accès à votre serveur et leurs dossiers.
Une pratique courante est de créer un utilisateur/groupe nommé « git ». Vous pouvez alors l'associer à différentes clés SSH permettant à des tiers de s'y connecter ou créer plusieurs utilisateurs appartenant au groupe git. Aucune méthode n'est meilleure qu'une autre, tout dépend de la façon dont vous voulez opérer.
Sur un NAS, l'accès SSH s'active en général dans les paramètres, Git étant le plus souvent proposé à l'installation sous la forme d'un paquet dans la boutique applicative. Par exemple dans Synology DSM 7.0 :
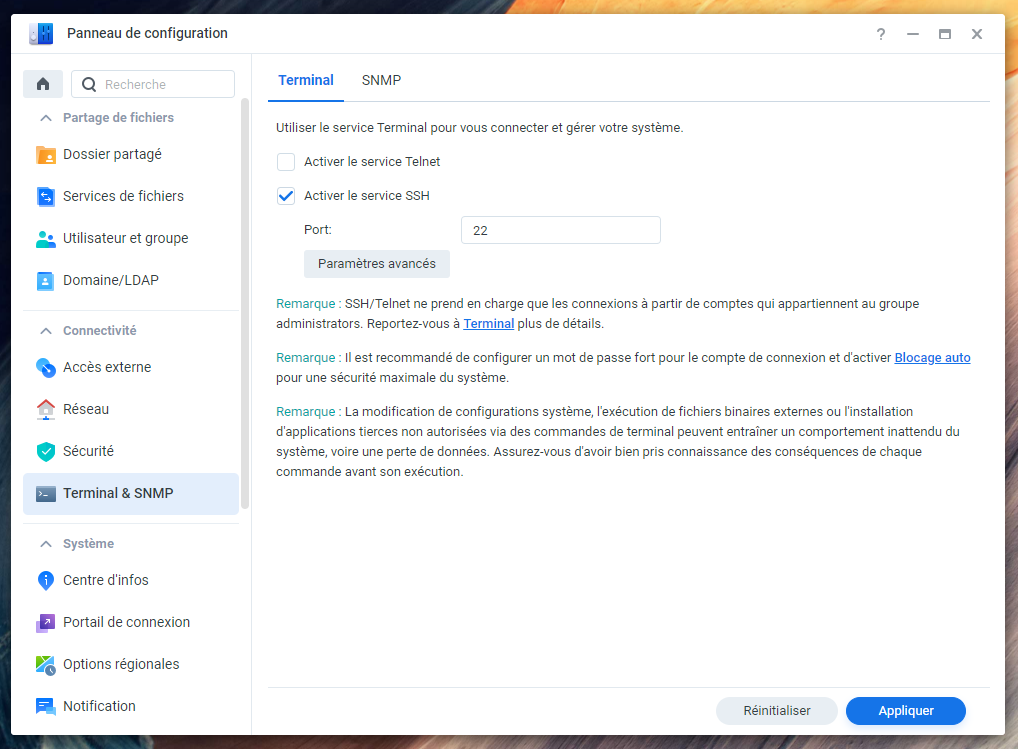
Activation de l'accès SSH et de l'accès d'un utilisateur au serveur Git
Serveurs Git prêts à l'emploi : Gitea, Gogs et compagnie
C'est également le cas chez Asustor, dont l'App Central propose de nombreuses solutions prêtes à l'emploi : GitBucket, Gitea ou encore Gogs. Seule cette dernière est maintenue directement par ses équipes. Il s'agit d'outils open source permettant d'accéder à des dépôts Git via une interface web à installer, sur son propre serveur.
Ils sont en général intéressants, car légers et simples à installer, dans votre NAS ou même un Raspberry Pi. Ils reprennent le plus souvent les mécaniques de GitHub, bien connues. Gitea vante pour sa part ses atouts face à ses concurrents, précisant être également simple à maintenir, gérant la double authentification, etc.
Attention tout de même : chez QNAP il n'existe par exemple aucune solution basique pour installer Git. Le constructeur renvoie plutôt à sa Container Station pour de tels usages. On a du mal à comprendre pourquoi il faut en passer par un conteneur pour installer un simple outil de gestion de versions pesant 30 Mo...
C'est une solution également promue par Synology pour les outils plus complexes cités ci-dessus. La Community Edition de GitLab est ainsi proposée dans la boutique applicative mais passe par Docker. Pour les autres, tels que Gitea ou Gogs, il faudra chercher dans le registre DockerHub. Et donc posséder un NAS gèrant les conteneurs. Malheureusement, ce n'est pas le cas de tous. L'entrée de gamme n'a pas toujours l'application nécessaire.
Autre solution : passer par un hébergeur et son offre de cloud public. Scaleway propose par exemple GitLab et Gogs sous la forme d'images clé en main (Instant Apps). Même chose pour OVHcloud avec GitLab. Vous pouvez aussi simplement monter une instance et y installer Git pour l'utiliser comme serveur distant.

 Gitea installé sur un NAS Synology via Docker
Gitea installé sur un NAS Synology via Docker
Création d'un dépôt distant et clonage local
Maintenant que notre serveur est configuré, passons à l'action. Nous indiquerons ici des commandes pour un NAS Synology mais elles peuvent être utilisées avec n'importe quel serveur. Il faudra simplement adapter l'IP de la machine, le nom de l'utilisateur et le dossier. Dans notre cas : 192.168.1.42, david et /volume1/gitServer/.
Connectez-vous en SSH à la machine :
ssh [email protected]
Nous avons créé un dossier partagé repositories, on y créé le dossier de notre premier dépôt Git :
mkdir -p /volume1/repositories/repoTest.git
cd /volume1/repositories/repoTest.git
On initialise alors un dépôt nu et on ferme la connexion :
git init --bare
exit
Notez que si votre dépôt doit être partagé entre plusieurs utilisateurs d'un même groupe la commande devient :
git init --bare --shared
exit
On se place dans le dossier local où les données doivent être placées et on clone le dépôt :
git clone [email protected]:/volume1/repositories/repoTest.git
cd repoTest
Une alerte vous indiquera que le dépôt est vide. Vous pouvez vérifier que tout s'est bien passé :
git status
On peut effectuer un premier commit local :
echo "# Hello, World !" > README.MD
git add README.MD
git commit -a -m "Premier commit"
git log
Si tout s'est bien passé vous verrez le résultat de votre commit apparaître avec ses métadonnées. Vos modifications faites, vous pouvez les « pousser » au serveur avec la commande suivante :
git push
Comme nous aurons l'occasion de le voir plus tard, cette commande courte revient à utiliser des paramètres par défaut. Ainsi, bien que ce ne soit pas précisé, on pousse la branche master vers le remote origin. Selon les cas, il vous sera éventuellement demandé de vous identifier. Les données sont désormais sur le serveur !
Travail sur plusieurs machines ou en équipe
Imaginons maintenant que vous vouliez travailler à plusieurs ou sur une machine différente. Quelle sera la marche à suivre ? Pour le simuler, nous allons cloner une seconde fois le dépôt distant. Vous pouvez aussi le faire depuis un second PC présent sur le même réseau local pour rendre l'expérience plus réaliste :
cd ..
git clone [email protected]:/volume1/repositories/repoTest.git repoTest2
cd repoTest2
git log
Ici on précise un nom de dossier cible, celui utilisé par défaut existant déjà. On voit bien que l'ensemble des données ont été récupérées et que l'information du premier commit est affichée.
Modifions maintenant le fichier README.MD en ajoutant une seconde ligne de texte :
echo "## Ceci est un sous-titre" >> README.MD
On effectue le commit puis on pousse les modifications sur le serveur :
git commit -a -m "Ajout d'un sous-titre"
git push
On retourne alors dans le précédent dépôt. Les données sont inchangées. Avant de les modifier, il faut vérifier que le serveur n'a pas déjà de nouvelles données (ce qui est le cas) avec un pull :
cd ../repoTest
git pull
Cette commande agit comme un fetch (récupération des données) suivi d'un merge (fusion avec celles déjà en place). Une fois cette action effectuée, vous pouvez à nouveau modifier le fichier README.MD et passer d'un dépôt à l'autre. Cette façon de faire explique le besoin de travailler dans des branches différentes lorsque l'on est plusieurs à modifier un document ou un code source. Puis de les « réconcilier », parfois via une pull request (PR).
Dans la suite de ce dossier, nous vous expliquerons comment travailler avec plusieurs remotes. Notamment pour modifier vos fichiers sur un serveur local « privé », puis le partager régulièrement sur un service en ligne public.

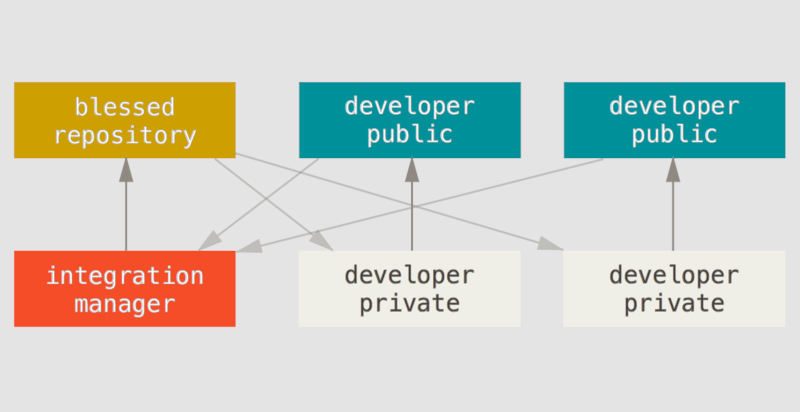 Deux manières différentes de travailler en équipe selon la documentation Git
Deux manières différentes de travailler en équipe selon la documentation Git





Commentaires (15)
Vous devez être abonné pour pouvoir commenter.
Déjà abonné ? Se connecter
Abonnez-vousLe 05/10/2020 à 06h56
Au risque de spoiler ( ), une approche comme certains projets de logiciels libres qui ont leur propre repository Git et publient en parallèle sur Github en lecture seule pour bénéficier de la visibilité de ce dernier ?
), une approche comme certains projets de logiciels libres qui ont leur propre repository Git et publient en parallèle sur Github en lecture seule pour bénéficier de la visibilité de ce dernier ?
Sinon j’aime bien l’image qui explique la différence entre centralisé, décentralisé et distribué. Je n’avais jamais vu cette modélisation et c’est simple et très clair. (notamment les deux derniers qu’on peut avoir tendance à confondre)
(notamment les deux derniers qu’on peut avoir tendance à confondre)
Le 05/10/2020 à 06h59
Pourtant elle est connue (certains en ont même fait un t-shirt de mémoire ). Pour les remotes multiples, ça peut être une solution, d’autres publient sur GitLab et GitHub en //. In fine, chacun fait un peu comme il le souhaite, c’est tout l’intérêt de l’outil.
). Pour les remotes multiples, ça peut être une solution, d’autres publient sur GitLab et GitHub en //. In fine, chacun fait un peu comme il le souhaite, c’est tout l’intérêt de l’outil.
Le 05/10/2020 à 15h39
C’est pas la première fois que je louperais un truc “hyper connu”
Ou alors j’ai probablement du le voir sous une autre forme, notamment sur les sujets liés au Fediverse où la notion de décentralisé / distribué peut parfois se confondre.
Le 05/10/2020 à 07h09
En plus de Gogs et Gitea, on pourra aussi mentionner Gitbucket qu’on utilise à mon taf (Ne pas confondre avec Bitbucket !!!). Ne connaissant pas du tout les 2 premiers, je serais bien incapable de les comparer.
Le 05/10/2020 à 07h12
Il est mentionné dans l’article
Le 05/10/2020 à 12h10
hello David,
y a un moyen de retrouver l’ensemble des articles sur git ? d’habitude pour les dossiers, y un “paragraphe” rapide avec l’ensemble des articles liés, mais pour git c’est pas systématique (meme si certains liens sont dans le texte).
Possible d’avoir d’une manière ou d’une autre ce type d’accès rapide ?
Le 05/10/2020 à 07h21
Oups ! désolé j’ai lu trop vite
Le 05/10/2020 à 07h27
perso j’utilise gitolite ça permet de gérer les accès via ssh (et d’avoir des scripts de déploiement après des push)
super ces articles
Le 05/10/2020 à 11h30
Je me pose la question de l’utilité d’avoir un remote hébergé chez soi, et d’un autre chez Github ou Gitlab. Quitte à envoyer son code chez ces derniers, pourquoi héberger un serveur chez soi?
Le 05/10/2020 à 12h04
histoire de ne pas être dépendant d’un changement de politique ?
Le 05/10/2020 à 13h19
Comme dit dans l’article, tu peux très bien avoir un dépôt local et un remote “interne” et ensuite utiliser ces plateformes comme un outil de diffusion public.
L’avantage c’est que tu peux garder toute le travail (commits, etc.) visible, mais ne décider de le publier que quand bon te semble (pour une release particulière par exemple).
Mais c’est comme tout, c’est une possibilité : tu n’en a pas l’utilité, ne l’utilise pas. Cela ne veut pas dire que ce ne sera pas utile par la suite ou à d’autres.
Oui je dois juste l’ajouter mais il faut que je revois un point dans l’organisation du dossier
Le 05/10/2020 à 14h49
Merci je n’avais en effet pas pensé à cette situation. Pour le coup, j’en vois bien l’intérêt désormais. Je vais réétudier la question.
Le 05/10/2020 à 22h04
Personnellement, c’est parce que je ne veux pas aller nourrir les ricains et leur besoins de télémétries, et également contribuer à une utilisation frugale / sobre d’internet. C’est aussi toute la démarche de posséder un NAS chez moi.
Le 06/10/2020 à 09h07
Ma question n’était pas sur le fait d’héberger son propre serveur Git. Ça je le conçois très bien, notamment pour la vie privée comme tu le dis. Je m’interrogeais sur le fait d’avoir un serveur local ET remote. David m’a très bien répondu.
Le 05/10/2020 à 18h59
Au boulot je maintiens du code sur Solaris. Tout le monde était très content d’utiliser git en mode centralisé. Et là je suis arrivé et j’ai dit
Puis là j’ai découvert
git upload-packet les collègues ont ricané