Proxmox VE : créer un cluster, gérer la haute disponibilité et les migrations (live)
Bientôt en multi-cloud ?
")
Proxmox VE est un hyperviseur open source populaire, développé par une entreprise autrichienne, aux atouts nombreux. Parmi eux, la possibilité de regrouper et de gérer plusieurs machines au sein d'un cluster, afin de les faire travailler de concert. De quoi améliorer la disponibilité de vos services.
Nous avons déjà vu comment installer Proxmox VE sur un PC pour en faire un serveur capable de lancer des machines virtuelles (VM) ou des conteneurs LXC. Une solution parfaite pour les « Home Lab », mais aussi les petites et moyennes entreprises (PME) qui veulent gérer elles-mêmes leurs infrastructures et services.
- Proxmox VE 7.0 : installation sur un serveur et création d'une machine virtuelle
- Linux Containers (LXC) dans Proxmox VE 7.0 : installez simplement des distributions et services
- Proxmox VE 7.0 : comment ajouter du stockage via NVMe/TCP
Mais dans ce dernier cas, il faut s'assurer que tout peut continuer de fonctionner même en cas de panne ou simplement distribuer des VM et conteneurs sur des machines offrant un niveau de performance différent selon les besoins. Pour cela, Proxmox VE propose la gestion de clusters, permettant de regrouper différents serveurs.
Vous pouvez ainsi établir des règles de déploiement ou disposer d'une redondance automatique. On vous explique.
Créer un cluster dans Proxmox VE
Pour créer un cluster, il faut disposer d'au moins deux machines sous Proxmox VE (dans une version similaire si possible) et qu'elles soient capables de se joindre à travers le réseau auquel elles sont connectées. L'idéal est d'en avoir au moins trois : si l'une tombe, les deux autres disposent d'un « quorum » suffisant pour décider quoi faire.
Autre choix qui pourra avoir son importance par la suite : le système de fichiers. En la matière, ZFS dispose d'avantages puisqu'il permet une réplication efficace, pensez donc à l'utiliser (en RAID 0 si vous n'avez qu'un unique HDD/SSD au sein de la machine). Cela se décide au moment de l'installation.
Dans notre cas, nous avons opté pour trois serveurs différents : notre HPE ProLiant DL365 Gen10 Plus v2 à base de deux EPYC 7713 (Gemini) accompagné d'un second basé sur un Xeon E2388G, 4x 8 Go de DDR4 et la carte mère MX33-BS0 de Gigabyte (Tiny). Le troisième était une machine plus classique, composée d'un Core de 12e génération (Core i9-12900k, Alder Lake) sur une ROG Maximum Z690 Hero et 2x16 Go de DDR5 avec une carte réseau à 10 Gb/s (Newbie). Un débit utilisé pour ces trois machines reliées à travers le switch S5860-20SQ de FS.com.
Dans les paramètres du Datacenter de l'interface de Proxmox VE, la section cluster permet d'en créer un. Pour cela il suffit de lui trouver un nom et de déclarer les liens réseau utilisés. Par défaut c'est celui par lequel la machine est accessible, mais on peut en choisir d'autres qui prendront le relais en cas de problème (failover) et définir des priorités. Lorsque tout est validé, le cluster apparait, vous pouvez alors demander à voir ses « Join Information ».
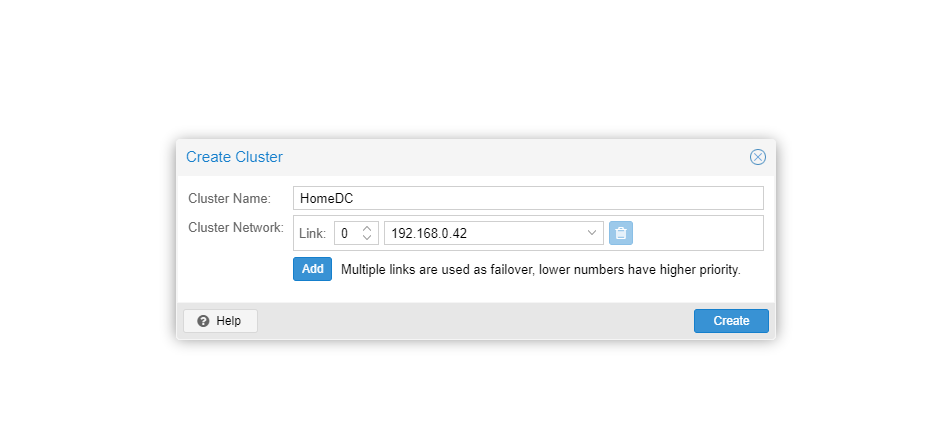



Elles prennent la forme d'une clé qui est une forme encodée de l'adresse IP du serveur et de son empreinte, utilisées pour la connexion. Dans l'interface des autres serveurs, on sélectionne Join Cluster et on peut simplement copier la clé pour remplir les champs automatiquement, ou le faire manuellement. Il faudra néanmoins connaitre le mot de passe administrateur (root) du serveur ayant initié le cluster pour finaliser la procédure.
Si tout s'est bien passé, après avoir rechargé la page (et une reconnexion), tous les serveurs (nœuds) apparaissent dans chaque interface, au sein de la section Datacenter du menu de gauche. On peut alors les gérer de manière unifiée., depuis l'un ou l'autre membre du cluster, sans distinction. La section Summary affichera également les ressources de manière globale : stockage, mémoire, CPU, VM et conteneurs des nœuds y sont additionnés.
Pour supprimer un membre du cluster, seule une procédure manuelle est proposée.
Migration « live »
Une fois le cluster créé, on peut déplacer une machine virtuelle ou un conteneur d'un serveur à l'autre, on parle alors de migration. Elle peut être faite pendant que le système invité est fonctionnel (online) ou éteint (offline). Le premier cas est celui utilisé par défaut, sous conditions : il faut qu'aucun périphérique physique du serveur ne soit lié à la machine (carte graphique, réseau, périphérique de stockage, etc.).
Si vos nœuds utilisent des processeurs différents, il est aussi déconseillé d'utiliser le paramètre « host » pour le type de vCPU, qui déclare l'architecture physique comme étant celle utilisée au sein de la VM. En effet, la migration ne prendra pas en compte cette transition d'architecture et cela pourra poser des problèmes en pratique.


La gestion de la réplication se fait nœud par nœud et ressource par ressource
Notez que si vous disposez d'un système de fichier ZFS, la fonctionnalité de réplication pourra être activée (voir ci-dessus), effectuant une copie de sauvegarde du périphérique de stockage virtuel sur un serveur secondaire de manière régulière (toutes les x minutes, jours, à des heures précises, etc.). De quoi accélérer la migration.
Dans la pratique, nous avons ainsi pu passer une machine virtuelle Debian de Gemini à Tiny en quelques secondes, pendant qu'un benchmark OpenSSL tournait en boucle, avec un downtime de 90 ms seulement, invisible pour l'utilisateur, si ce n'est pour le faible impact observé sur l'un des tests :
Haute disponibilité et règles de groupe
Pour profiter de la gestion en cluster et de la migration, deux serveurs suffisent. On peut également se limiter à ce nombre pour les bases de la haute disponibilité (HA) et des groupes, accessibles dans les paramètres du Datacenter.
Les groupes permettent d'établir des règles communes à plusieurs nœuds du cluster avec des niveaux de priorité (sous la forme d'un entier). Si ces derniers sont définis, une machine virtuelle créée sur un serveur ira en priorité sur celui ayant la plus haute priorité, sauf exception. Chaque élément ajouté à la gestion de la haute disponibilité est vu comme une ressource, dont l'état doit être maintenu : démarré, arrêté, ignoré ou désactivé.
On indique combien de fois une tentative de redémarrage ou de relocalisation (migration offline) peut être effectuée (1 par défaut). Dans les options du Datacenter on choisit la politique d'arrêt d'un nœud. En le passant sur Migrate par exemple, les ressources seront déplacées dans un autre nœud avant que l'arrêt ne soit effectif.
Cela permet d'assurer une continuité de service lorsqu'une maintenance est programmée.

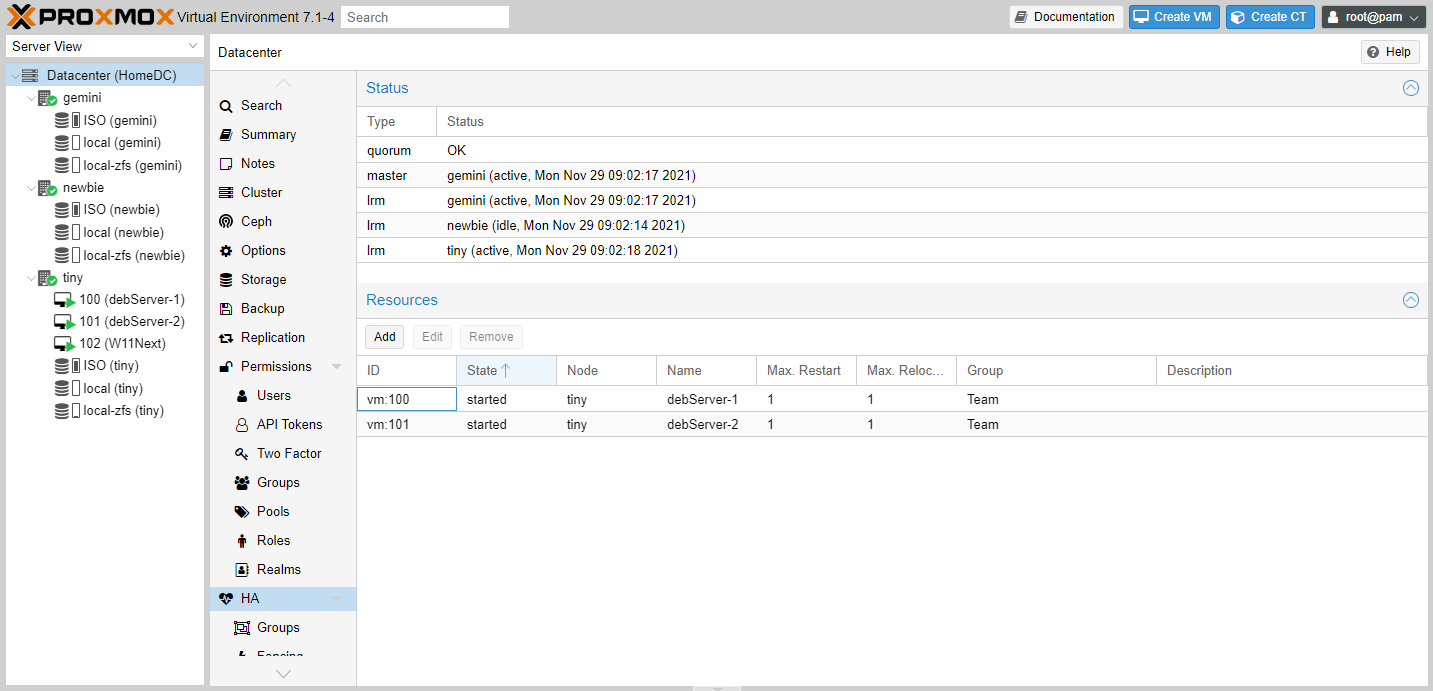
Création d'un groupe et sélection des nœuds (à gauche), vue de la haute disponibilité (à droite)
Et en cas de panne ? C'est là qu'il faut passer au moins à trois nœuds, puisqu'il faut constamment un « quorum » minimum au sein du cluster pour effectuer des migrations. Si une machine d'un cluster de deux tombe, il n'est plus atteint. Si une tombe sur un cluster de trois, c'est le cas. Nous avons donc ajouté un troisième nœud à notre cluster.
Nous avons placé trois VM sur Tiny : une répliquée sur Gemini, l'autre sur Newbie, la troisième sans réplication. Lorsque nous avons éteint Tiny, au bout de quelques minutes les machines virtuelles qui y étaient présentes se sont relancées automatiquement là où elles étaient répliquées. Pour celle qui ne l'était pas, c'était forcément plus compliqué et nous avons parfois rencontré des problèmes. L'idéal est donc d'avoir une réplication sur un noeud.
Une fois le serveur initial de retour, les ressources qui y étaient présentes pourront y être replacées ou non, cela dépendra essentiellement des règles de priorités définies au sein du cluster.
L'équipe de Proxmox VE précise que les fonctionnalités de HA sont des outils dans la recherche d'une meilleure disponibilité des services, mais ne sont pas les seules à mettre en place. Outre la multiplication des nœuds, il faut disposer de pièces de rechange pour réparer rapidement en cas de panne, avoir des équipes pouvant constamment intervenir, assurer une redondance du stockage, exploiter des services résilients par eux-mêmes là aussi par des mécaniques de type multi-instances, etc... Ou se reposer sur des tiers qui s'en occuperont pour vous.

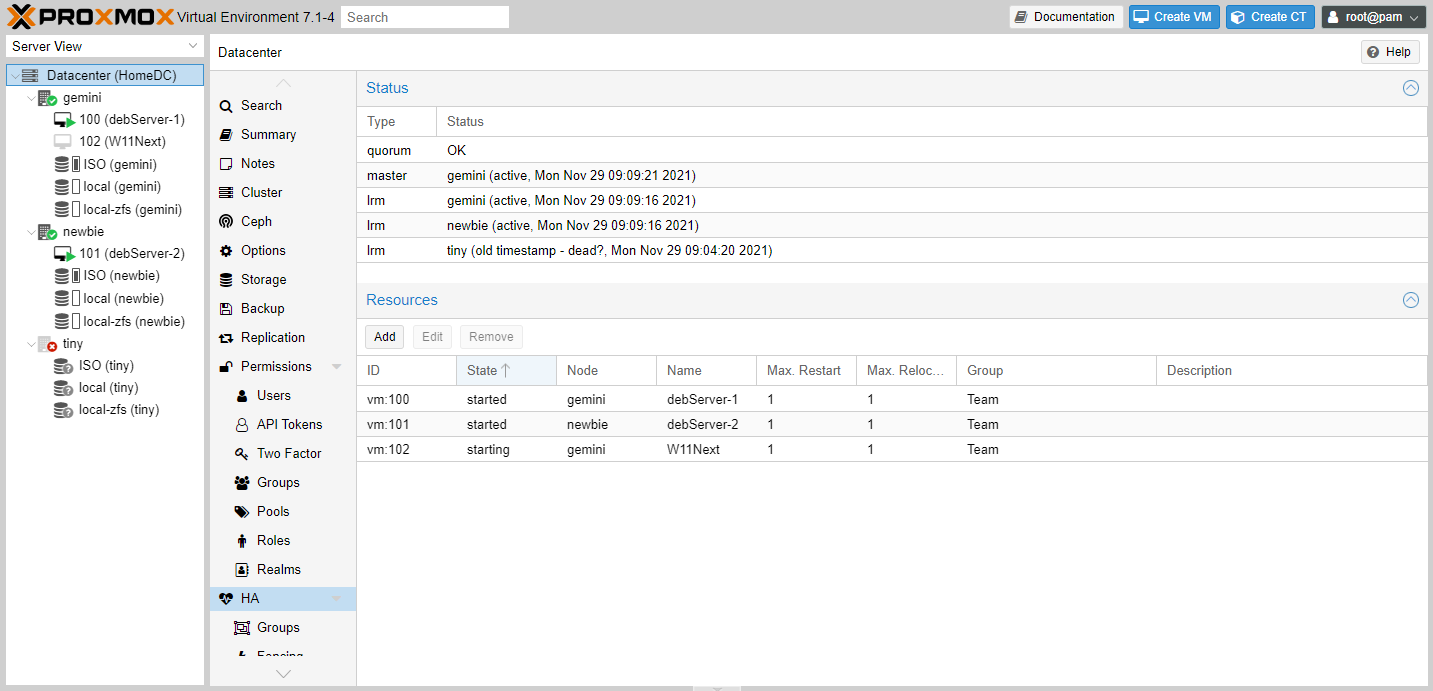 Après la panne, les VM ont lancées sur d'autres nœuds, celle non répliquée a posé problème
Après la panne, les VM ont lancées sur d'autres nœuds, celle non répliquée a posé problème



Commentaires (27)
Vous devez être abonné pour pouvoir commenter.
Déjà abonné ? Se connecter
Abonnez-vousLe 29/11/2021 à 08h44
Merci, très bien fait votre tuto :)
Concernant le stockage, vous aviez donc que des stockages locaux sur chaque serveur en ZFS, pourquoi ne pas avoir créer du CEPH pour avoir un stockage commun et se passer de la réplication pour le HA ?
Le 29/11/2021 à 08h47
Parce qu’on en parlera sans doute par la suite ;) Mais de manière plus générale, c’était surtout pour montrer comment ça pouvait être mis en place sans dépendre d’une solution spécifique côté stockage (autre que le système de fichiers à sélectionner).
Le 29/11/2021 à 09h14
Plusieurs années que je suis sous unRAID et la, j’ai plutôt envie de tout migrer sur Proxmox … J’dis pas merci ! :-)
Le 29/11/2021 à 09h25
Ceph s’est bien mais c’est aussi pas mal de contraintes HW en plus. Dont beaucoup de mémoire (4Go par disque). Sur du stockage simple ça bascule peut être un poil moins vite mais ça coûte bien moins cher.
Le 29/11/2021 à 09h32
Merci pour cet article, il tombe à pique.
Petite question :
Merci par avance !
Le 29/11/2021 à 09h36
Très intéressant le test de migration avec des CPU différents (et même de constructeurs différents).
Ca nécessite tout de même de faire gaffe au niveau de compatibilité au niveau des flags CPU activés/activable côté VM non si les gen sont trop éloignées ?
Le 29/11/2021 à 09h39
L’idéal c’est d’avoir un quorum externe (possible cf un article que j’ai écris à ce sujet https://blog.zwindler.fr/2019/10/11/un-cluster-proxmox-ve-avec-seulement-2-machines/).
Dans le cas où tu as pas de majorité, je sais pas si tu peux mettre en place la HA… En tout cas je le conseillerais pas.
Hors HA, quand les machines hôtes proxmox se voient plus, elles se “bloquent” niveau configuration partagée. On peut couper des VMs mais plus en allumer.
Le 29/11/2021 à 09h43
Tu peux quasi désactiver le quorum, ce que je fais sur un cluster de 4 machines. L’idée est que je m’en fous des trucs live bidule qui copie mes vm à la volée, je veux surtout partager du stockage plus facilement ou déplacer des vm.
Le 29/11/2021 à 09h48
Il existe un CPU kvm64 qui est compatible inter-cpu. Mais… tu auras des emmerdes si tu mélanges du Intel et du AMD. Dis toi que c’est pareil chez la concurrence payante (vmware).
Cependant c’est embêtant que si tu fais une migration de la vm entre host physique en live. L’astuce c’est d’éteindre la vm avant de la déplacer puis de la rallumer. Là tu auras aucun souci.
Le 29/11/2021 à 09h50
Cela rajoute aussi une grosse pression sur le réseau et donc du SPOF supplémentaire. C’est un calcul à faire. A quel point tu as besoin d’un stockage partagé ?
Le 29/11/2021 à 10h01
Il n’y a pas que les contraintes HW, pour le stockage avec un nombre de replica minimum, il faut quasi le double de serveur, sinon :
1°) grosse perte de perf
2°) en cas de perte trop importante d’OSD = perte de données
CEPH ne permet pas d’utiliser des partitions, il faut utiliser un disque entier, ça aussi c’est une contrainte qui ne permet pas de faire ce que l’on veut facilement.
Selon moi il aurait été vraiment bien de pouvoir installer Proxmox sur de petites machines, qui ne seront pas dédié à la virtualisation, mais à Ceph et au Quorum lorsqu’il y a besoin de nouveau noeud uniquement sur la partie stockage + gestion de la HA.
Le 29/11/2021 à 10h01
Ton article est parfait ! J’ai un petit bout de vm de disponible chez un ami, il va faire office de quorum, merci :)
Le 29/11/2021 à 10h06
Cela peut dépendre des paramètres, mais les ressources sont remises en place dès que le nœud revient
Comme dit dans l’article, si les architectures sont différentes ils vaut mieux utiliser un profil similaire (genre kvm64 comme évoqué plus haut). On peut perdre en perf, mais ça évite pas mal de souci (notamment openssl ne migrait que dans un sens avec un profil “host” entre EPYC/Xeon.
Le 29/11/2021 à 10h07
Oui, il y a plein d’autres contraintes avec Ceph. Mais c’est une bonne solution quand on commence à atteindre une certain taille. Et quand tu commence à réellement en avoir besoin avoir un réseau dédié ceph ou ne pas utiliser de partition ne sont pas les soucis principaux :)
Le 29/11/2021 à 10h18
Oui c’est une bonne solution, le CERN l’utilise depuis bien longtemps, mais ce que je veux dire par là c’est que financièrement parlant CEPH est un gouffre financier pour obtenir de la redondance et de la performance.
Si par exemple tu souhaite utiliser CEPH avec des serveurs dédiés que tu loue dans des centres de données, financièrement parlant ça revient très chère, ou alors c’est que tu gagne bien ta vie, même dans un environnement pro (me concernant) ce n’est pas rentable…
Tu peux utiliser CEPH dans un réseau d’entreprise local si tu as assez de machine, un cœur de réseau minimum à 10Gbps, etc.. etc..
Le 29/11/2021 à 10h21
Je dirai même plus qu’il faut également avoir un peu d’expérience pour toucher à du CEPH en production sur des sujets sensibles. Une fois planté, ca demande un petit peu de compétence spécifique pour debugger et éviter de tout casser définitivement.
Le 29/11/2021 à 11h05
En résumé, il te faut un vrai service IT et pas un sysops tout seul pour utliser du CEPH en production. ;)
Le 29/11/2021 à 11h22
C’était une limitation par le passé mais on peut depuis quelques versions utiliser un volume LVM mais ça peut probablement avoir quelques impact au niveau performance.
Le 29/11/2021 à 11h55
Je pense que tu n’as pas trop regardé le coût des autres solutions pour dire cela hihihi. Des solutions comme Ceph qui te permettent de s’étendre à la volée, se réparer à la volée, sans être liée à un fournisseur de matériel que ce soit en serveur ou en disque, ça ne court pas les rues.
Ceph est un monstre. S’en servir en se disant “c’est simple”, c’est une erreur qui mène à une perte de données totale.
4go par serveur +1go de ram par disque, ok. Mais 4go par disque, ça me parait énorme… Où as-tu vu ça s’il te plait?
C’est fou qu’n logiciel système ai besoin d’un service IT de nos jours

Mais je crois que tu as mis le doigt sur quelque chose
Le 29/11/2021 à 13h28
C’est les recommandations officielles. Un OSD sur les versions récente utilise jusqu’à 4Go de mémoire par défaut.
https://docs.ceph.com/en/latest/start/hardware-recommendations/#ram
Pour des grosses boites qui ont leur datacenter c’est pas du tout abusé comme système. Il y a aussi pas mal de constructeur qui font du ceph ou équivalent dans leur solutions en ajoutant une surcouche. Il y a un monde entre une PME/Startup qui loue dans un DC et le CERN qui a un des plus gros cluster Ceph du monde…
Et il y a plein d’autres solutions de stockage distribué.
Le 29/11/2021 à 23h45
Stp ne déforme pas mes propos et ne pense pas à ma place, je connais très bien CEPH techniquement et l’ai utilisé plusieurs mois pour faire mes propres bench, l’évaluer dans tout les sens, je n’ai jamais dit que l’utiliser “c’est simple”, ma propre expérience m’a fait comprendre que si tu as 3 serveurs de virtualisation il t’en faut presque le double pour assurer la redondance des OSD convenablement tout en ayant des performances correctes, et ce n’est qu’une partie de ce qu’il faut pour le faire fonctionner correctement… quand tu commence à toucher à CEPH t’a surtout intérêt à avoir des sauvegardes fiables de tes VM et un plan B en cas de gros pépin.
Par contre, une entreprise qui possède localement plusieurs bonnes machines et un bon réseau 10Gbps (ou plus) sur des interfaces réseaux dédiés, c’est royal et moins ouf à gérer que plusieurs serveurs en centre de données dans des régions/pays différents/éloignés.
Le 30/11/2021 à 06h59
Une remarque, Proxmox n’est pas une entreprise allemande, mais autrichienne, basée à Vienne.
Le 30/11/2021 à 07h07
My bad, je confonds toujours, merci c’est modifié
Le 30/11/2021 à 11h02
Effectivement utiliser CEPH peut s’avérer compliqué, autant pour trouver la config matérielle qui va bien que pour “maîtriser la bête” .
Mais tant qu’on parle de Proxmox c’est probablement l’implémentation CEPH la plus simple à mettre en oeuvre et il est tout à fait possible d’utiliser des hôtes proxmox dédiés à CEPH et de fournir le stockage à d’autre Proxmox de compute.
Pour peu qu’on ai quelques (au moins 2) ssd par noeuds CEPH pour faire le wal et la db des osd il est tout à fait possible d’avoir des performances très correctes (on peut découper les ssd en LV pour ce faire).
Le 30/11/2021 à 19h11
Concernant la partie CPU, j’ai eu l’agréable surprise récemment de m’apercevoir que je pouvais migrer (en fonctionnement donc) une VM configurée avec 4 CPU vers le “maillon faible” de mon cluster, équipé d’un simple cpu dual core.
Côté perf, c’est évidemment pas très recommandable, mais ça permet d’avoir une souplesse supplémentaire quand on utilise proxmox sur un cluster de test perso hétérogène, comme c’est mon cas.
Le 01/12/2021 à 15h17
Top, c’est pour cela que je suis abonné. Merci pour le boulot.
Le 02/12/2021 à 20h17
Ah c’était donc toi cet article ! Ça m’a bien aidé pour monter mon cluster proxmox@home ! J’ai le quorum qui tourne sur mon pc qui fait NAS !