NVIDIA Digits : « le plus petit supercalculateur d’IA au monde », à poser sur votre bureau
Le digits à porté de mains

NVIDIA présente son projet Digits comme « le plus petit supercalculateur d’IA au monde » à poser sur votre bureau. Il propose une puissance d’un PetaFLOP avec une précision FP4 et peut, selon NVIDIA, exécuter en local de larges modèles d’IA avec 200 milliards de paramètres. Son prix : 3 000 dollars en tarif de base.
Une puce GB10 Grace Blackwell Superchip aux commandes
Comme chaque année, NVIDIA multiplie les annonces lors du CES de Las Vegas. Nous avons déjà détaillé les nouvelles GeForce RTX 50 qui promettent des performances doublées par rapport aux RTX 40 équivalentes. Ces cartes graphiques exploitent la nouvelle architecture Blackwell, comme le projet NVIDIA Digits dont il est aujourd’hui question.
Digits prend la forme d’un petit boîtier dans lequel on retrouve un SoC NVIDIA GB10 Grace Blackwell Superchip. Grace est le nom de la partie CPU du « Superchip », tandis que Blackwell correspond à la partie GPU. On retrouve exactement la même segmentation dans les puces GH200 et GB200, par exemple, avec H200 pour la génération Hopper de GPU et B200 pour Blackwell.
Partie CPU Grace : 20 cœurs ARM
Ce GB10 est, comme son nom le laisse facilement supposer, allégé par rapport aux GH200 et GB200. Sur la partie CPU, NVIDIA annonce seulement 20 cœurs ARM « optimisés pour l’efficacité énergétique », sans plus de précision.
Sur GH200 et GB200, on retrouve pour rappel 72 cœurs ARM Neoverse v2 dans la partie CPU Grace. NVIDIA précise que sa puce est développée en partenariat avec MediaTek.
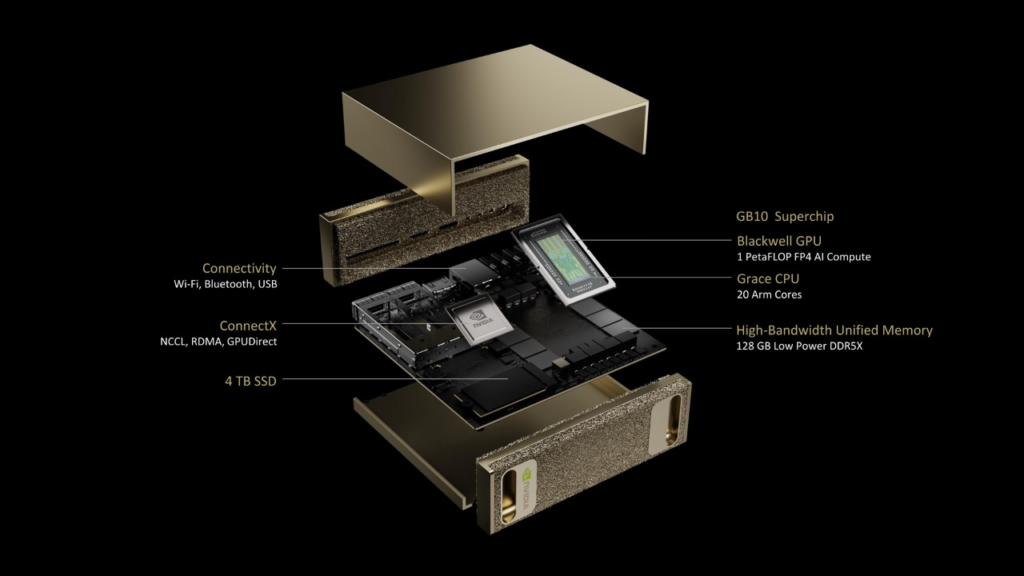
Partie GPU Blackwell : 1 PetaFLOP en FP4
Pour la partie GPU, NVIDIA annonce une puissance de calcul d’un PetaFLOP avec une précision FP4, soit vingt fois moins que le GPU Blackwell B200 à 20 PetaFLOP (ou 20 000 TeraFLOP).
Nous avions pour rappel détaillé le calcul de NVIDIA : B200 intègre deux GPU sur un même die et passe pour la première fois en FP4, qui permet de doubler les performances brutes par rapport au FP8, lui-même deux fois plus rapide que le FP16, etc. GB10 en FP8 est ainsi à 500 TeraFLOP.
- NVIDIA annonce son GPU Blackwell (B200) pour l’IA, jusqu’à 20 000 TFLOPS (FP4)
- Rapidité vs précision : deux experts nous expliquent les enjeux des GPU modernes sur les IA
De la LPDDR5X pour la mémoire, du stockage NVMe
NVIDIA ne donne pas beaucoup de détails sur la composition de sa GB10 et précise simplement qu’elle est « dotée d'un GPU NVIDIA Blackwell avec des CUDA Cores de dernière génération et des Tensor Cores de cinquième génération [bref, une architecture Blackwell, ndlr], interconnectés via NVLink-C2C au processeur NVIDIA Grace ».
Chaque DIGITS dispose de 128 Go de mémoire unifiée LPDDR5X et d’un maximum de 4 To de stockage en NVMe (PCIe). Le GPU n’aura donc pas de mémoire HBM (plus rapide que la DDR5X) comme c’est le cas sur les versions haut de gamme des GPU Blackwell pour l’IA.
Des LLM en local avec jusqu’à 200 milliards de paramètres
NVIDIA affirme que, grâce à son supercalculateur de bureau, « les développeurs peuvent exécuter de grands modèles jusqu'à 200 milliards de paramètres », à condition évidemment de les avoir préparés à une précision FP4. Le fabricant ajoute que, grâce à ConnectX, deux supercalculateurs DIGITS « peuvent être reliés pour exécuter des modèles jusqu'à 405 milliards de paramètres ».
Pour NVIDIA, le but est de cette puce GB10 Grace Blackwell est de permettre « aux entreprises et aux chercheurs de prototyper, affiner et tester des modèles en local sur des systèmes locaux avec le système d'exploitation NVIDIA DGX OS basé sur Linux, puis de les déployer de manière transparente sur NVIDIA DGX Cloud ». L’architecture matérielle et la partie logicielle restent les mêmes entre Digits et DGX (Blackwell) dans les datacenters.
Digits sera disponible en mai, pour un tarif débutant à 3 000 dollars. Le détail des configurations n’est pas indiqué.

Commentaires (7)
Abonnez-vous pour prendre part au débat
Déjà abonné ? Se connecter
Cet article est en accès libre, mais il est le fruit du travail d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles
Profitez d’un média expert et unique
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousAujourd'hui à 16h29
Aujourd'hui à 17h01
"RTX 5090: 32G VRAM" vs "DIGITS: 128G VRAM" c'est un monde de différence.
Par contre j'ai pas vu d'indication sur la conso (watt).
Aujourd'hui à 20h19
Pour te donner une idée, j'ai joué avec LLaMa 3 en local sur ma config. Sur le modèle à 8 Milliards de paramètres quantisé en 6 bits, qui tournait entièrement sur la VRAM de ma vieille carte graphique, une réponse un peu longue mettait 2-3 secondes à s'afficher en entier.
Sur le modèle à 70 Milliards quantisé en 3 bits, dont seulement 1/3 tenait sur ma VRAM et les 2/3 restants devaient être placés en RAM centrale, une réponse de même longueur mettait environ... 15 minutes.
Aujourd'hui à 19h13
Aujourd'hui à 20h22
Aujourd'hui à 19h28
Aujourd'hui à 20h12