IA : la déconstruction du mythe du « plus c’est gros, mieux c’est »
Tu sais ce qu'il te dit le cassis ?

Alors que Sam Altman a publié un billet promettant un avenir radieux grâce à une IA « requérant beaucoup d'énergie et de puces », les chercheuses Sasha Luccioni et Meredith Whittaker et leur collègue Gaël Varoquaux ont résumé les critiques d'une R&D de l'IA qui ne compte presque que sur l'augmentation de la puissance des machines pour avancer.
La semaine dernière, Sam Altman a publié un billet dans lequel il imagine un futur où le monde partage une « prospérité à un degré qui semble inimaginable aujourd'hui » et dans lequel « la vie de chacun pourra être meilleure que la vie actuelle de n'importe qui ». Ceci, évidemment, grâce à l'IA. Pour cela, affirme le CEO d'OpenAI, « nous devons réduire le coût du calcul et le rendre abondant (ce qui nécessite beaucoup d'énergie et de puces) ».
Mais il menace : « si nous ne construisons pas suffisamment d'infrastructures », donc si son industrie ne reçoit pas assez de financements, « l'IA sera une ressource très limitée qui fera l'objet de guerres et deviendra principalement un outil pour les riches ».
Dévitalisé de ses apparats prophétiques, ce discours s'inscrit dans une longue série de plaidoyers pour une Recherche & développement (R&D) de l'IA qui avancerait par de simples coups/coûts d'augmentation des performances des machines. Alors qu'on commence à connaître un peu mieux l'impact environnemental de l'IA générative, cette vision est dénoncée par trois chercheurs très connus dans le milieu : Sasha Luccioni qui travaille pour Hugging Face, Meredith Whittaker chercheuse à l'Université d'Australie-Occidentale mais aussi Présidente de la fondation Signal, et Gaël Varoquaux, chercheur à Inria.
Une prétendue corrélation vieille de 12 ans
Dans un article (un « position paper » titré « Hype, Sustainability, and the Price of the Bigger-is-Better Paradigm in AI ») mis en ligne sur arXiv deux jours avant la publication du billet de Sam Altman, ces trois chercheurs expliquent que cette idée s'est disséminée dans le milieu de l'IA depuis l'arrivée en 2012 d'une certaine architecture de réseau neuronal convolutif : « AlexNet a créé la recette de l'actuel paradigme "bigger-is-better" de l'IA, en combinant les GPU, les big data (du moins pour l'époque) et les approches s'appuyant sur les réseaux neuronaux à grande échelle ».
Et il est évident qu'AlexNet a eu une influence très importante dans le domaine, expliquent les trois chercheurs : ses auteurs ont démontré, en le décrivant, que les GPU étaient particulièrement efficaces face aux CPU dans le domaine du machine learning. C'est donc depuis cette architecture que les services de R&D se sont jetés sur les GPU et que, par la même occasion, NVIDIA est devenu l'un des rois de l'IA.
Depuis, selon Sasha Luccioni et ses collègues, cette vision du « plus c'est gros, mieux c'est » n'a cessé de se renforcer au point de passer d'un certain « récit » à « la norme ». Cette norme a logiquement infusé dans la presse, mais aussi dans les régulations de ces systèmes, comme l'AI act européen ou le décret que Joe Biden a publié sur le sujet en 2023, déplorent-ils. Dans leur article, les trois chercheurs s'efforcent de démonter cette prétendue corrélation du « plus c'est gros, mieux c'est ».
D'une journée d'entrainement sur une PlayStation 4 à plus de 24 h sur les meilleurs supercalculateurs
Mais ce qu'ils expliquent tous les trois, c'est que la taille des « modèles remarquables (très cités) a massivement augmenté au cours de la dernière décennie, sous l'effet d'une croissance super-exponentielle en termes de nombre de paramètres et de quantité de données et de calculs utilisés », mais que « cette croissance est beaucoup plus rapide que l'augmentation de la capacité du matériel à exécuter les traitements nécessaires à l'apprentissage et à l'ajustement des modèles ».
« En effet, alors que la taille des grands modèles, mesurée par le nombre de paramètres, double actuellement tous les cinq mois, le coût d'un gigaoctet de mémoire est resté pratiquement constant pendant une décennie », font-ils remarquer :
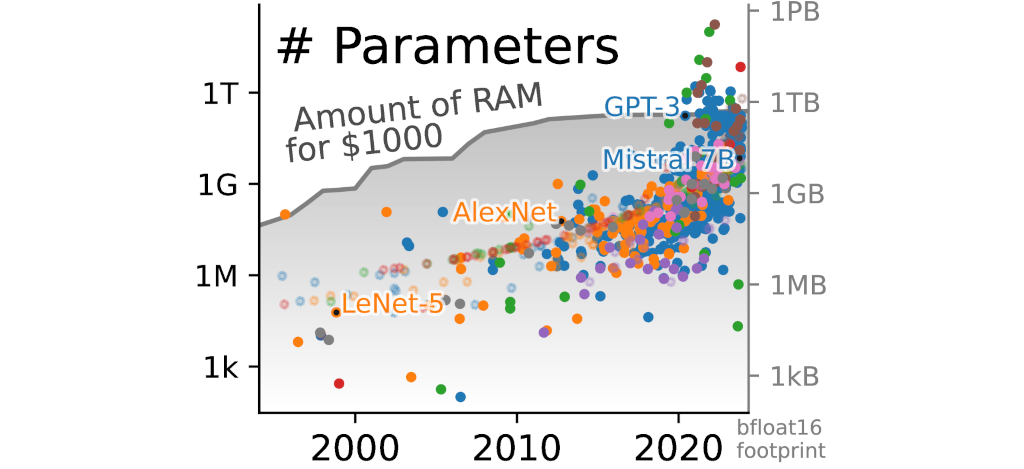
Pour appuyer leur argument, ils expliquent que le calcul utilisé pour entrainer un modèle d'IA est passé d'une simple journée sur une PlayStation 4 (en 2013) à plus d'une journée pour certains modèles sur les plus grands supercalculateurs de la planète (en 2020) :
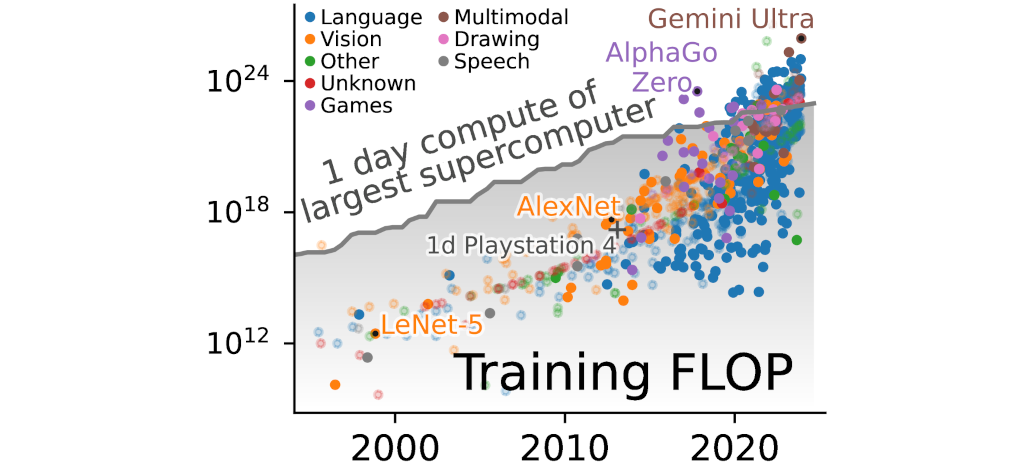
Pour étayer leur point de vue, ils s'appuient sur d'autres travaux scientifiques. Par exemple, le chercheur du MIT Neil C. Thompson et ses collègues ont fait, en 2022, une méta-analyse de 1 527 articles scientifiques dans le domaine du machine learning pour étudier les efforts qu'il faudrait effectuer afin de les rendre plus performants. Ceux-ci alertaient déjà sur les « coûts matériels, environnementaux et financiers » nécessaires pour améliorer les modèles qui « seraient prohibitifs ».
En exemple, ils expliquaient que, « même dans le modèle le plus optimiste, il faudrait 567 fois plus de calculs pour atteindre un taux d'erreur de 5 % » dans le test de référence (« benchmark » en anglais) ImageNet. « Une réorganisation fondamentale est nécessaire pour réduire l'intensité des calculs afin que la mise à l'échelle de ces problèmes devienne moins onéreuse », affirmaient-ils.
Et Sasha Luccioni et ses collègues font remarquer que « beaucoup d'architectures qu'ils ont étudiées, comme celle des modèles Transformers, dont les Vision transformers, sont encore celles qui sont utilisées en 2024 ».
Pas le meilleur outil pour tout
Mais leur critique ne s'arrête pas là. En prenant divers exemples dans la littérature scientifique, ils expliquent que l'approche « plus c'est gros, mieux c'est » ne produit pas « non plus systématiquement les meilleurs modèles » et qu' « après un certain temps, elle présente même des rendements décroissants ».
Ils citent notamment l'exemple de l'utilisation de l'IA sur des données présentées en tableaux « du type de celles qui sont couramment produites dans les entreprises ». S'appuyant sur les travaux de Gaël Varoquaux et de ses collègues d'Inria, ils expliquent que, pour ce genre de tâche, « les modèles d'arbres de décision produisent de meilleures prédictions et sont beaucoup plus rapides (et donc moins coûteux et plus accessibles) que les approches fondées sur les réseaux neuronaux ».
De même en santé, où les travaux scientifiques utilisant des grands modèles sont abondants en ce moment, mais avec des données plus « rares » que dans d'autres champs et les réelles avancées aussi, selon (PDF) Gaël Varoquaux et Veronika Cheplygina. Les trois chercheurs prennent l'exemple de la prédiction de l'épilepsie et expliquent qu'une étude ne constate « aucune différence de performance de prédiction entre la régression logistique, les arbres boostés [boosted trees, en anglais] ou l'apprentissage profond, même si ces approches diffèrent considérablement en termes de ressources requises ».
Ils citent aussi le domaine de l'IA en éducation. Nous en avons déjà un peu parlé ici avec la fameuse MIA de Gabriel Attal dont le ministère ne nous a toujours pas envoyé les sources bien que la CADA se soit prononcée positivement au sujet de notre demande. Une étude de 2019 suggère (PDF) qu' « une intégration aléatoire de la séquence d'apprentissage de l'élève est plus performante que des modèles profonds ou bayésiens optimisés et plus gourmands en ressources ».
Enfin, les trois chercheurs critiquent aussi la manière dont sont utilisés les tests de référence (« benchmarks » en anglais) dans le milieu de l'IA. Ils expliquent que s'ils sont adaptés à la recherche universitaire, ces tests ne sont pas faits pour « remplacer les mesures de performance en contexte ». Ils soulignent que l'utilisation de ces tests « s'accompagne souvent de pratiques peu recommandables », citant une étude [PDF] sur le sujet publiée aussi en 2019.
Ils encouragent donc la recherche sur les petits modèles, en affirmant que « la petite taille peut aussi être belle ».
Du point de vue du développement, ce qu'on peut retenir de tout ça, c'est qu'avant d'utiliser en production un très grand modèle de langage, vu l'énergie qu'ils dépensent, il faudrait d'abord vérifier qu'un autre outil n'existe pas ou qu'un petit modèle pourrait faire l'affaire.
On peut le voir comme une situation où on aurait, dans son garage, un énorme spot de lumière digne d'être installé dans un stade de foot. On ne va pas l'utiliser n'importe comment. Certes, en le branchant dans un bureau, il éclairerait toute la pièce, mais il va consommer énormément et il est possible qu'il nous éblouisse plus qu'il nous rende service.
Dans son billet, Sam Altman dit : « je pense que l'avenir sera si brillant que personne ne pourra lui rendre justice en essayant de l'écrire maintenant, l'une des caractéristiques de l'ère de l'intelligence sera la prospérité massive ». Mais, en plus de consommer une énergie phénoménale, son IA ultra puissante ne risque-t-elle pas d'aveugler tout le monde, à la façon de notre spot de stade installé dans un garage ?

Commentaires (11)
Abonnez-vous pour prendre part au débat
Déjà abonné ? Se connecter
Cet article est en accès libre, mais il est le fruit du travail d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles
Profitez d’un média expert et unique
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 02/10/2024 à 12h15
Le 02/10/2024 à 13h03
Le 02/10/2024 à 13h14
Le 02/10/2024 à 13h14
Le 02/10/2024 à 14h33
Le 02/10/2024 à 13h33
Moi aussi tiens :
Je pense que l'avenir s'étendra devant nous avec une lumière si éclatante que tenter de le décrire aujourd'hui serait insuffisant, presque dérisoire. L'ère de l'intelligence ne sera pas seulement marquée par des avancées techniques, mais par une prospérité aussi vaste que les rêves que nous n'osons encore formuler. L'humanité, portée par une intelligence qui transcende l'imagination, se dressera dans une ère où les limites de la création s'évanouiront, et où chaque esprit pourra toucher l'infini."
Eh oui ça vient de chatgpt aussi 😅
Le 02/10/2024 à 14h33
Le 02/10/2024 à 13h10
Un jour, quand vous aurez le temps et que vous serez super-relax, ce serait bien de faire le point sur les méthodes et technos alternatives au DL citées dans l'article :
Bon, je sais, faire de la vulgarisation, c'est d'un vulgaire ! Mais comme dirait Coluche, "C'est pas grossier" !
...A moins que ne ce soit le contraire ?
Le 02/10/2024 à 13h24
"Si toi faire grande offrande beaucoup beaucoup sous-sous à grand Dieu AI, alors grand Dieu AI très content (et moi aussi) et bénir les enfants des enfants de tes enfants!
Mais attention, si offrande pas assez grande, alors grand Dieu AI très fâché! Grands malheurs s'abattre sur ta tribu sur trente générations!
Alors, toi donner grande offrande beaucoup beaucoup sous-sous ??? "
Modifié le 02/10/2024 à 14h18
Un peu plus d'explications (en Anglais, un peu ch..., lues par une voix hem... reptilienne) par ici
Autre source, Stargate Omnipedia
Voilà voilà... à part ça, je suis pas du tout fan de cette série... Nan nan nan...
Le 02/10/2024 à 20h44