IA : c’est quoi exactement un neurone (informatique), comment ça marche
C’est un truc qui fait des calculs
, comment ça marche")
Neurone… c’est un mot qui revient souvent quand on parle d’intelligence artificielle. Mais c’est quoi exactement un neurone artificiel ? Comment ça marche et à quoi ça sert ? On vous explique simplement, avec un petit détour dans les années 40 pour remonter à sa création.
Au cours des derniers mois, nous vous avons proposé un petit lexique des termes courants utilisés en intelligence artificielle. Le but : vous permettre de bien comprendre de quoi il en retourne et d’appréhender les changements majeurs que l’IA apporte actuellement.
AGI, modèles de fondation, prompt injection, empoisonnement, inférence, hallucination, paramètre, quantification, neurone… Tous ces mots ne devraient plus trop avoir de secret pour vous. Mais un élément mérite qu’on s’attarde davantage sur son fonctionnement : le neurone, qui est à la base des IA modernes.
Dessine-moi un neurone
Une fois n’est pas coutume, on va donner une présentation des plus simplistes du neurone, puis vous expliquer plus finement de quoi il en retourne. Un neurone, c’est simplement un outil mathématique qui réalise une somme pondérée de variables. Voilà, vous pouvez passer à autre chose… ou bien continuer à nous lire et en savoir bien plus.
On monte dans la DeLorean pour un retour dans le temps de 80 ans. On profite du voyage pour évacuer une question : quel rapport entre les neurones de nos cerveaux et ceux des ordinateurs ? Le mode de fonctionnement.
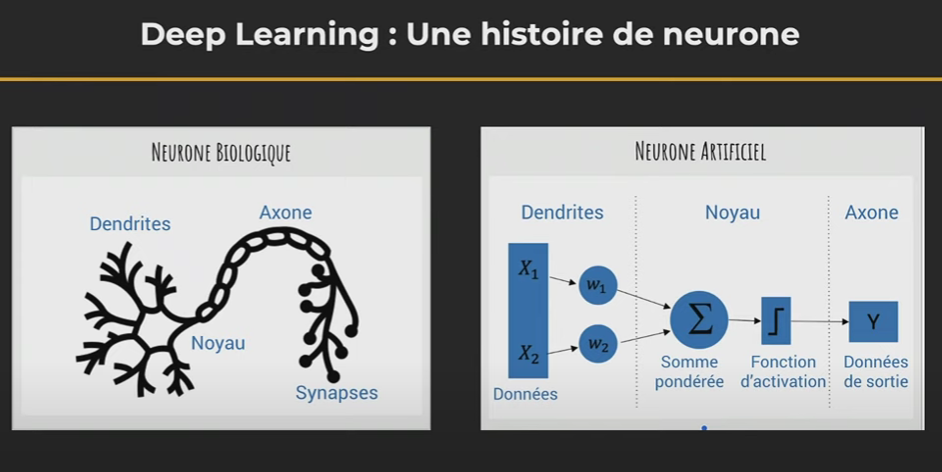
« Un neurone, ça capte de l’information par des dendrites. Ces informations vont arriver un peu de partout et être compilées dans le noyau de la cellule de votre neurone. Le noyau va ressortir un résultat qui est une information électrique dans votre cerveau. Il va être transmis à d’autres neurones par l’intermédiaire des synapses », explique Alexia Audevart, Google Developer Expert in Machine Learning, lors d’une conférence Devoxx en 2021.
Une précision sur la composition du cerveau humain par le CNRS : « il comprend environ 100 milliards de neurones connectés par des millions de kilomètres de « connecteurs » (axones) et de 10 000 à 100 000 milliards de « contacts » (synapses) ». Restons humble, étudions un seul neurone artificiel.
Le neurone artificiel commence sa vie dans les années 40
Sur le principe, le neurone artificiel va lui aussi récupérer des informations, les « tripatouiller » pour en sortir un résultat, puis le passer à d’autres neurones. Les ressemblances entre neurones artificiels et réels s’arrêtent là.
C’est dans les années 40 que commence l’histoire des neurones artificiels : « il y a des mathématiciens qui créaient des neurones artificiels avec un vecteur d’entrée d’informations. Ces informations sont pondérées […], on leur donne plus ou moins d’importance. Ça nous donne une somme, qui passe par une fonction d’activation », ajoute Alexia Audevart. Oui, un neurone, c'est un peu une calculatrice qui fait le même genre d’opérations à longueur de journée.
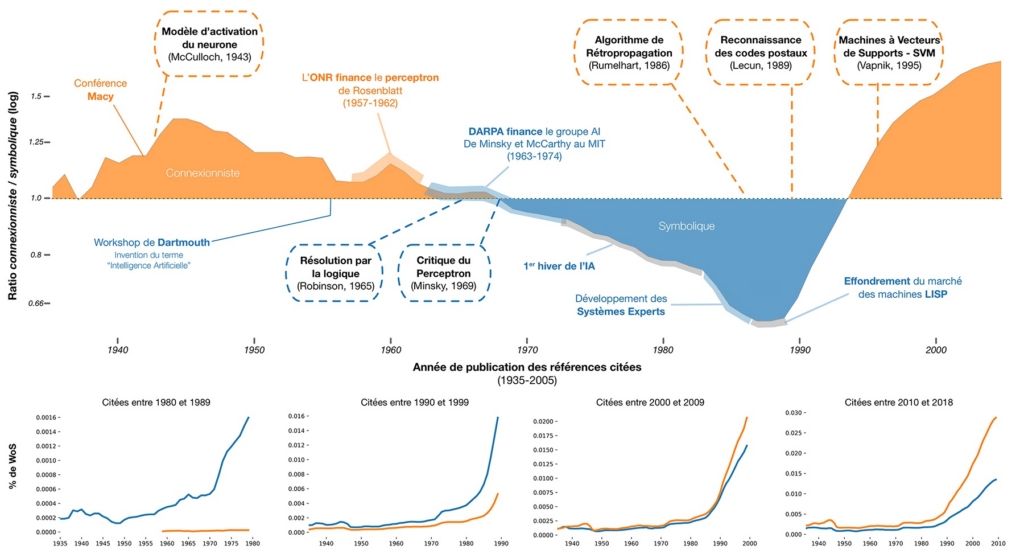
Le graphique ci-dessous retrace les grandes lignes de la découverte des neurones artificiels et de l’avancée de la recherche sur l’IA et les réseaux de neurones. Il est tiré de « La revanche des neurones. L’invention des machines inductives et la controverse de l’intelligence artificielle » de Dominique Cardon, Jean-Philippe Cointet et Antoine Mazières. Nous n’allons pas détailler l’ensemble du graphique, mais nous attarder sur quelques points. Il est dans tous les cas intéressants pour avoir une vue globale.
Détour par le perceptron et son neurone
Dans une vidéo, sur l’introduction au deep learning, les chercheurs Bertrand Cabot et Jean-Luc Parouty rappellent que c’est en 1957/1958 que Franck Rosenblatt a conçu « une première machine d’intelligence artificielle capable de classer des choses » : le perceptron.
« C’était un classifieur avec un seul neurone, mais qui fonctionnait. 1958 a été une année très importante, c’était la première fois qu’on avait une machine capable de reproduire un raisonnement, modeste certes mais qui fonctionnait », expliquent les scientifiques. Une manière de rappeler que le neurone n’est pas nouveau, loin de là.
Ensuite, on connait l’histoire avec le premier hiver de l’intelligence artificielle dans les années 70. De nouvelles recherches sont arrivées dans la fin des années 80, notamment avec les réseaux de neurones (avec des couches de neurones) et l’augmentation de la puissance de calcul en informatique.
Un neurone, c’est une addition et des multiplications
Pour en revenir à notre neurone, c’est donc en quelque sorte une fonction qui prend des valeurs en entrées et renvoie une sortie. Plusieurs neurones peuvent être « branchés » en parallèle sur les entrées, on parle alors de couche. Les neurones d’une couche ont tous les mêmes entrées, mais chacun avec ses propres coefficients.
Un réseau de neurones, ce sont des couches de neurones qui s’enchainent les unes aux autres. Les sorties d’une couche sont les entrées de la couche suivante (on n’est pas obligé d’avoir le même nombre de neurones dans chaque couche), une opération que l’on peut répéter autant que nécessaire.
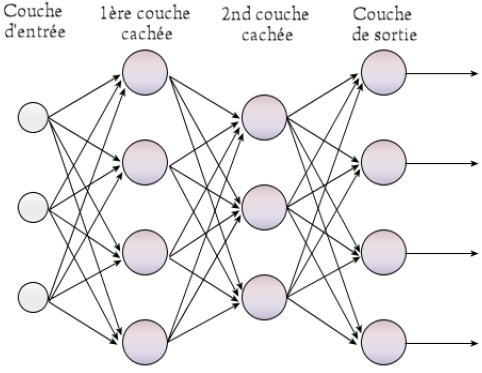
Avec un neurone, on peut avoir des centaines/milliers d’entrées, chacune avec donc son propre coefficient. Tous les neurones reçoivent les mêmes données en entrées, mais tous ont des coefficients différents. Imaginez un réseau de 50 neurones avec 150 données en entrée, cela nous donne 7 500 paramètres.
Le travail d’entrainement d’une IA consiste justement à trouver les meilleurs coefficients possibles pour chaque neurone. On peut également ajouter un biais, qui est une valeur ne dépendant d’aucune variable. D’une certaine manière, cela permet de « décaler » la fonction. De 7 500 paramètres dans notre exemple, on arrive donc à 7 550 paramètres à ajuster.
Un peu de math pour la route
Appelons le biais a0. On a ensuite les données en entrée x1, x2,…, xn, leur coefficient a1, a2 jusqu’à … an. Un neurone fait simplement un calcul :
f(x1, x2,…, xn)= a0+ a1x1+ a2x2+…+ anxn. Pour ceux que les formules rebutent, on additionne simplement les valeurs en entrée pondérées de leur coefficient respectif et on ajoute le biais. De 1958 à nos jours, le principe du neurone reste le même.
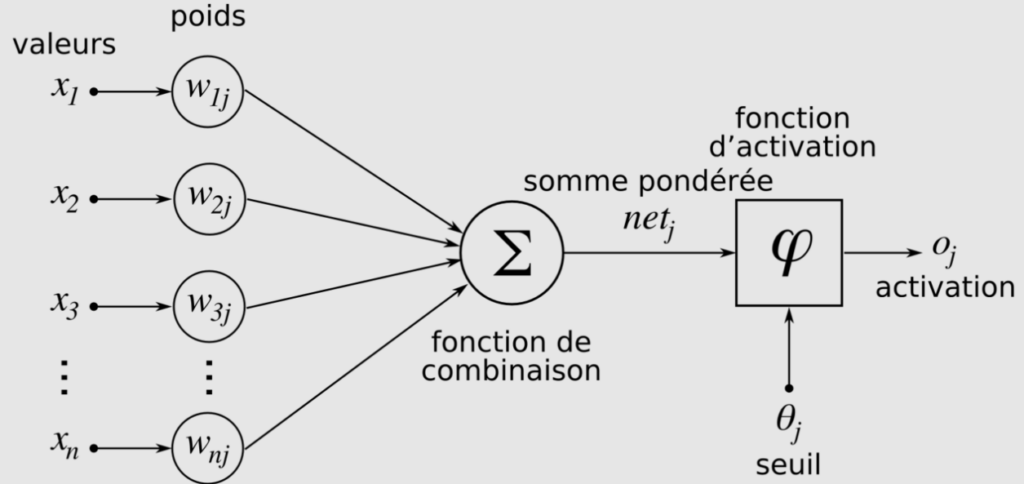
La fonction d’activation juste avant la sortie
Une fois le calcul terminé, le résultat passe à la moulinette d’une fonction d’activation. Elle ne dépend plus directement des entrées ou des coefficients, mais d’une nouvelle opération. Il en existe plusieurs, trop pour toutes les détailler.
Commençons par l’une des plus simples : la marche de Heaviside. Si le résultat du calcul du neurone est négatif, alors la fonction d’activation renvoie 0. Dans le cas contraire, elle renvoie 1. La sortie du neurone vaut donc 0 ou 1 en fonction des valeurs en entrées et des poids associés. Simple, mais sans granularité.
Signalons aussi ReLU (Rectified Linear Unit ou Unité Linéaire Rectifiée) qui retourne 0 si le résultat est négatif et le résultat sans modification dans le cas contraire. Pour ceux qui aiment les formules, c’est donc max (0,x) ou x est le résultat de la fonction du neurone.
Nous avons également sigmoïde et tangente hyperbolique que l’on pourrait comparer à la marche de Heaviside, mais avec une marche plus douce sous la forme d’une courbe. Suivant les besoins, on utilise une fonction d’activation ou un autre.
Wikipédia propose une liste de fonctions d’activation, avec les graphiques, les équations et d’autres informations associées. On se rend assez facilement compte de leur fonctionnement :

Dans un prochain article, nous vous expliquerons comment programmer et entrainer une intelligence artificielle capable de reconnaitre des chiffres avec seulement une dizaine de lignes de code.

Commentaires (13)
Le 14/06/2024 à 19h41
Merci pour cette synthèse
Le 14/06/2024 à 21h12
Le 14/06/2024 à 22h32
Le 14/06/2024 à 22h57
- Les GPU ont beaucoup de petits coeurs pour faire du traitement graphique, et ca tombe bien car on a besoin de beaucoup de petits processeurs pour paralléliser efficacement les fonctions d'activation et de combinaisons
- les fonctions mathématique qu'on vois sur le dernier schéma, ça ressemble également des fonctions utilisés dans certains traitement graphique (dans Photoshop le mode seuils, ou les différents rendu Sombre, Multiplier, Overlay, Brulure, Diff, Exclusions...)
Merci beaucoup pour cette série d'articles !!
Le 15/06/2024 à 09h03
Le 15/06/2024 à 09h22
Faire des produits matriciels à la chaine ne sert à rien, car il est possible de résumer cette suite d'opération en une seule, exactement comme faire des multiplications les unes à la suite des autres, il est possible de résumer ceci en une seule opération. Il faut donc ajouter une opération non linéaire entre deux opérations linéaires.C'est le rôle de la fameuse fonction d'activation.
Il est intéressant de voir ça comme une suite de transformations géométriques d'un espace de n dimension vers un espace à m dimension. Un produit matriciel répond à certaines règles (les points restent alignés, les proportions des segments restent les mêmes, le zéro reste en zéro). L'opération non linéaire permet de casser ces règles et de déformer l'espace. Au final, j'avais bien aimé la représentation des réseaux de neurone comme quelqu'un qui prend une feuille avec des points (les données) dessus et qui plie cette feuille dans tous les sens pour faire en sorte que les points s'organisent bien.
Le 15/06/2024 à 14h50
Le 16/06/2024 à 00h22
Des quelques introductions que j'ai lu, celle que l'on retrouve dans le livre "Deep Learning With Python" par François Chollet est surement l'un des plus simples et pourtant précises. Après, le mec, il est aussi auteur de la bibliothèque "Keras", ce qui laisse à penser qu'il a les idées claires dans le domaine.
Il est intéressant de signaler que l'on peut voir les réseaux de neurones selon 3 angles différents :
- l'angle biologique, celui qui voit des neurones qui sont organisés en couche
- L'angle arithmétique, qui voit que des opérations mathématiques, mais derrière ouvre la voie vers le 3ième angle et aussi vers les études les plus poussées.
- L'angle géométrique. Celui-là, je l'aime bien, car on arrive, sur des MLP (multi layer perceptron, et dans une moindre mesure les CNN (convolutional neural network) et les RNN (recursive neural network), à visualiser les transformations successives des données.
Souvent, on présente les réseaux de neurones par l'angle biologique, mais je trouve que c'est celui qui explique le moins bien ce qui se passe réellement.
Le 15/06/2024 à 17h14
Déjà, le perceptron. Son origine, et ce qu'il arrive à "imiter", ce sont les insectes, avec une intelligence limitée, basé uniquement sur la perception (d'où son nom). Par exemple, vous avez une voiture jouet électrique. Vous lui mettre un détecteur de présence à l'arrière, que vous relier au moteur. Quand une main (ou quoi que ce soit) s'approche, le moteur se déclenche, et la voiture avance pour "fuir". Il ne s'agit pas d'intelligence en tant que tel, mais ça imite parfaitement un insecte qui fuit dès que quelque chose s'approche de lui. Et il n'y a qu'un neurone : l'entrée (la distance à l'objet 'x') est pondéré (du genre 'ax+b' par exemple, pour a,b,x ∈ ℝ), et et émet une sortie binaire, déclenchant le moteur ou non. Ca peut également contrôler le moteur analogiquement : plus quelque chose est proche, plus le moteur va vite, simulant une fuite lente quand on est loin et une fuite rapide quand on est proche.
De la même manière, vous pouvez mettre deux détecteur de présence, un a l'arrière droite l'autre à l'arrière gauche, déclenchant le moteur de la roue de son côté, pour ajouter une rotation en plus de la fuite. Si on rajoute deux détecteur de lumière à l'avant, branchés sur les roues opposées (détecteur avant gauche sur moteur avant droit) "l'insecte" va simuler une attirance vers la lumière.
Ainsi, avec quelques capteurs et quelques neurones "directs", on pourrait simuler presque parfaitement le fonctionnement d'un insecte.
(ces voitures s'appellent des véhicules de Braitenberg, voir pages 36 à 41 de ce PDF pour des illustrations de ce que je décris http://cqcb.mm.free.fr/cours/M2S1/ASI/cours1b_2007.pdf)
Les réseaux de neurones, c'est la même chose, mais multiplié par beaucoup. Notre cerveau fonctionne de la même façon : chaque neurone reçoit en entrée des données pondérés, les additionne, et si ça dépasse un seuil spécifique au neurone, transmet l'information au neurone suivant.
Ca a l'air simple comme ça, mais c'est vraiment comme ça que fonctionne notre cerveau, et les réseaux de neurones informatiques.
Mais le plus important, c'est la remontée du gradient : quand au final, le résultat donné par le réseau est faux, on baisse la pondération de tous les neurones ayant contribué à ce résultat. Quand le résultat est bon, on augmente tous les poids qui ont contribué au résultat. Et on recommence le même calcul. Encore et encore et encore. Puis on change légèrement une variable d'entrée, et on réessaye jusqu'à ce que ça fonctionne à nouveau, et on revient à la première pour vérifier que ça fonctionne encore, et on recommence, encore et encore. C'est cette partie qui est désignée comme l'apprentissage d'un réseau de neurones, faussement appelé IA.
Pour donner un exemple concret. Imaginez que vous êtes dans le désert, et une course automobile va avoir lieu. Il y a trois lieux de départ, un pour une voiture, un pour un camion, un pour une moto. Et une seule arrivé, avec des routes qui se chevauchent. Vous voulez tricher, et vous assurer que les véhicules arrivent dans l'ordre que vous souhaitez. Pour cela vous aller tout d'abord faire une course, voir quel est l'ordre d'arrivé. Suivant cela, vous aller peut-être bouger une dune, adoucir une pente, bref, modifier légèrement le terrain. Vous allez relancer une course, et voir ce qui a changé par rapport à la précédente, et modifier à nouveau le terrain. Encore et encore et encore. Jusqu'à ce que le résultat souhaité soit atteint.
C'est ça, l'apprentissage d'un réseau de neurone : c'est extrêmement complexe et surtout demande énormément de calculs, parce qu'il faut utiliser des millions de fois le réseau de neurone à chaque phase de l'entraînement. Et c'est aussi une boite noire : personne ne sait pourquoi une dune est à un endroit plutôt qu'à un autre. C'est aussi extrêmement fragile : remplacer la moto par un quad par exemple invaliderait totalement le processus d'apprentissage, et rendrait tout ces efforts inutiles.
Bref, un réseau de neurones peut faire beaucoup de choses, mais c'est pas une panacée, et il faut savoir l'utiliser avec discernement. Par exemple, dans le cas de la course dans le désert, il aurait été plus efficace et moins cher de corrompre les pilotes que d'essayer d'arranger des dunes ;)
(pour ceux qui veulent en savoir plus, je recommande la lecture de ce PDF http://cqcb.mm.free.fr/cours/M2S1/IA/livre_touzet.pdf)
Je suis ouvert à toutes les questions que vous pourriez avoir sur l'IA.
(note : ce post est libre de droit, excepté les PDFs liés)
Le 15/06/2024 à 23h42
Le 16/06/2024 à 09h55
L'axone ne sert qu'à transmettre l'information électrique, mais c'est à la synapse que ce fait la conversion électrique chimique.
Où alors j'ai manqué quelque chose...
Le 16/06/2024 à 20h25
Le 17/06/2024 à 08h53