HPE corrige un bug critique entraînant une panne des SSD après 32 768 heures d’utilisation
Binaire jusqu'au bout de la panne

HPE informe ses clients d'une mauvaise nouvelle : les SSD présents dans plusieurs gammes de serveurs cessent de fonctionner après 32 768 heures (près de quatre ans) et les données qu'ils contiennent sont perdues. Des correctifs sont d'ores et déjà disponibles, d'autres arrivent.
Il y a quelques jours, HP Entreprise déployait une mise à jour de sécurité « critique » pour plusieurs séries de SSD. Elle porte le numéro de version HPD8.
Face à la gravité de la situation, le fabricant demande à ses clients de l'installer dès que possible. Le problème entraîne en effet rien de moins qu'une panne avec une perte de l'ensemble des données après 32 768 (2^15) heures de fonctionnement, soit 3 ans, 270 jours et 8 heures.
La société alerte donc clairement ses utilisateurs : « en ignorant cette notification et en n'effectuant pas la mise à jour recommandée, le client accepte le risque de subir les problèmes en découlant ». Elle ne s'étend par contre pas davantage sur les raisons techniques de ce bug.
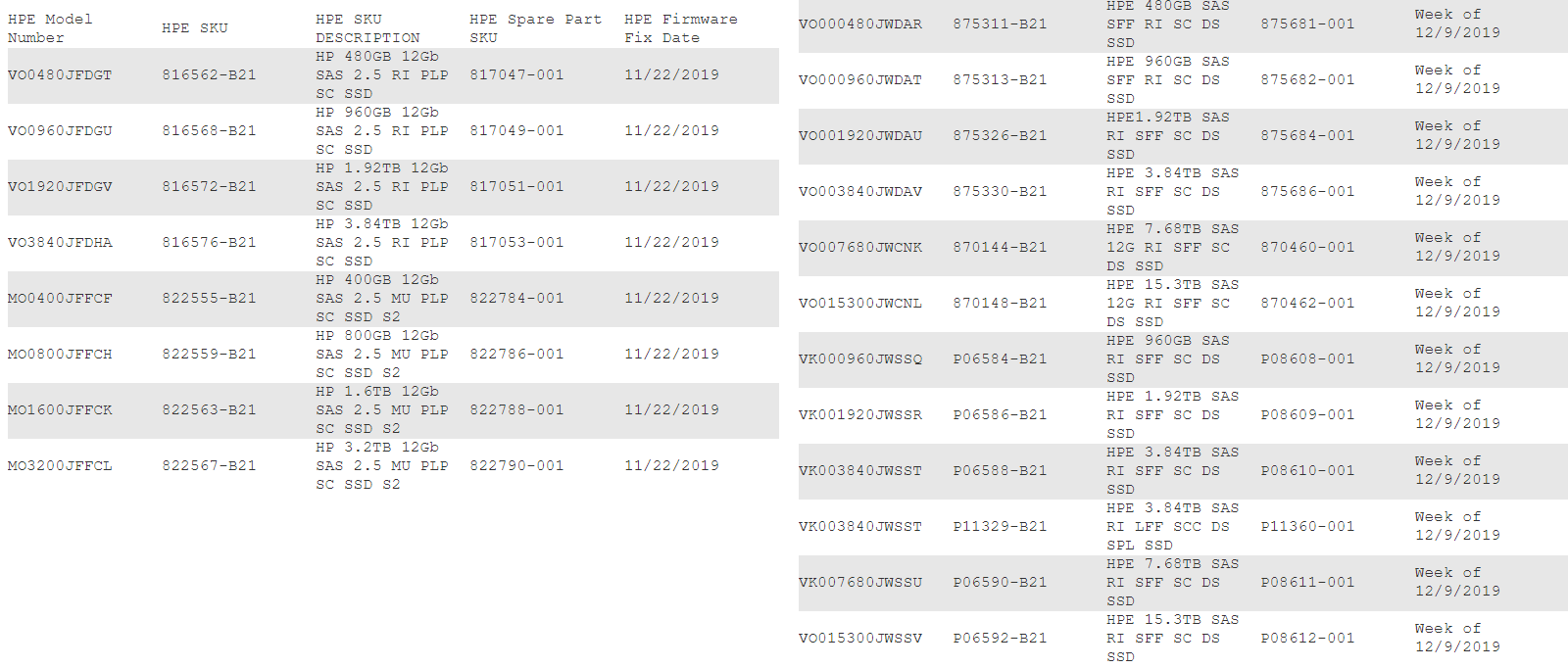
La liste des SSD touchés est disponible par ici. On les retrouve notamment dans des serveurs ProLiant, Synergy, Apollo, JBOD D3xxx, D6xxx, D8xxx, MSA, StoreVirtual 4335 et StoreVirtual 3200. Huit références ont d'ores et déjà droit à un correctif, tandis que 12 autres devront attendre la semaine du 9 décembre.
Compte tenu du délai de près de quatre ans avant que la panne ne survienne et leur date de commercialisation, le constructeur affirme que ces SSD « ne sont PAS susceptibles » d'y être confrontés d'ici là.
Commentaires (16)
Vous devez être abonné pour pouvoir commenter.
Déjà abonné ? Se connecter
Abonnez-vousLe 28/11/2019 à 14h22
Petite typo ici, non ?
“le risque d’engendrer de subir” ?
(vous pouvez supprimer ce commentaire ensuite :) )
Le 28/11/2019 à 14h35
Signed short powah !
Le 28/11/2019 à 14h45
Même non signé, ça aurait été assez décevant !
Le 28/11/2019 à 15h07
Ce qui est beau c’est que ceux qui se croient à l’abri avec leur RAID homogènes vont avoir toute la grappe qui tombe de façon parfaitement synchronisée.
Au moins ils apprendront qu’un RAID n’est pas une sauvegarde.
Le 28/11/2019 à 16h04
32768 ça peut être un dépassement d’un mot de 16bit signé (32767) ?
Le 28/11/2019 à 16h23
On ne serait pas sur de l’obsolescence programmée là ?
Le 28/11/2019 à 16h27
Il voulait faire de l’obsolescence programmée, et il se sont rendu compte que 32768 heures, c’était peut être un peu trop visible
Le 28/11/2019 à 17h39
@Zerdigham
Normalement, sur un RAID professionnel, tu mixes les marques et les âges de tes disques pour éviter justementuune panne généralisée synchronisée.
@Nextinpact, je n’arrive pas à répondre ou mentionner sur mon mobile (même en affichant la version ordinateur de la page).
Le 28/11/2019 à 18h16
Monter une grappe RAID avec des disques venant de la même série est toujours une mauvaise idée car ils vont claquer en même temps. Toujours avoir des fabricants différents ou à défaut des modèles différents dans les grappes RAID.
Le 28/11/2019 à 18h33
Normalement, sur un RAID professionnel, tu mixes les marques et les âges de tes disques pour éviter justement une panne généralisée synchronisée.
@Nextinpact, je n’arrive pas à répondre ou mentionner sur mon mobile (même en affichant la version ordinateur de la page).
@Nextinpact on ne peut plus modifier ou supprimer ses propres commentaires ??
Le 28/11/2019 à 21h38
Euh pas vraiment, car beaucoup de marques (hpe par exemple) ne propose pas autre chose que du Seagate rebrandé.
Le 29/11/2019 à 07h38
Il va falloir que je contrôle mon nouveau Proliant. Quelqu’un sait comment je peut voir le modèle de SSD sur un raid depuis Windows ?
Le 29/11/2019 à 11h14
Le plus simple est de check depuis l’iLo de ton serveur.
Le 29/11/2019 à 11h28
Avec iLo effectivement et sinon HPE SSA (smart storage administrator) le permet également si je ne m’abuses. (téléchargeable sur le site de support HPE)
Le 29/11/2019 à 15h43
Effectivement, c’est via l’ILO que j’ai pu voir. Merci.
Le 29/11/2019 à 16h02
Le pire, c’est que ce truc a dû être non seulement fait par un ingénieur mais également vérifié par un ou plusieurs autres ingénieurs avant d’aller en prod et que personne n’a tilté … )
)
(Ceci dit on peut rien dire, nous on a eu le même souci avec une DB où on a dû passer les ID d’int en bigint, mais c’est passé dans les maj de maintenance aussi