Iris Xe MAX avec Deep Link, Server GPU, FlipFast, Xeon Ice Lake : Intel déploie sa roadmap
Du PC portable à l'Exascale

Lors de l'édition 2020 de son Architecture Day, Intel évoquait ses plans autour de l'architecture graphique Xe, introduite sous la forme d'une partie graphique intégrée à Tiger Lake, puis d'un premier GPU Iris Xe MAX. Elle doit peu à peu monter en puissance dans les mois à venir. Entre autres projets.
Si tout le monde se focalise sur l'arrivée d'Apple sur le marché des processeurs pour ordinateurs grand public avec son M1, la tête d'Intel est ailleurs. Certes, le constructeur sait déjà comment il va répondre à cette menace avec la mise sur le marché de Tiger Lake, de Rocket Lake puis d'Alder Lake l'année prochaine.
C'est d'ailleurs le retard de ce premier processeur hybride, gravé en 7 nm, qui lui cause tant de tracas pour s'opposer à ses nouveaux concurrents. Mais le CPU grand public, intégré ou vendu au détail, n'est pas le seul marché où Intel doit se positionner. Ces dernières années, la société s'est donné un objectif : diversifier son offre d'accélérateurs, unifier toute sa couche logicielle autour de OneAPI et devenir un acteur important du marché des GPU avec Xe.
Après les promesses et de premières annonces, voici venu le temps de passer à du concret.
Iris Xe MAX : un premier GPU pour PC portable... avec Deep Link
L'architecture graphique Xe, développée par Raja Koduri et les équipes d'Intel est pensée pour s'adapter du plus petit niveau d'intégration (au sein d'un CPU) à des puces pour supercalculateurs Exascale. Autant dire que cela fait un large panel, surtout lorsque l'on voit tous les espoirs mis par la société et les marchés d'ores et déjà visés.
La première brique était donc Tiger Lake, avec un IGP Xe-LP doté de 96 unités d'exécution (EU) au maximum, avec une fréquence maximale de 1,35 GHz, soit 2,07 TFLOPS environ. Suffisant pour passer devant les Renoir d'AMD, mais en retrait par rapport au M1 d'Apple (2,6 TFLOPS) et surtout des machines à petit GPU dédié.
Ce marché est le plus souvent délaissé par les fabricants de GPU qui y positionnent de vieux modèles, peu performants, sans toujours posséder les fonctionnalités de traitement vidéo dernière génération par exemple. C'est là qu'Iris Xe MAX (DG1) doit entrer en scène. Toujours basé sur Xe-LP, il mise sur une forte intégration avec son Deep Link.
En effet, Intel tente ce que d'autres ont essayé avant lui, sans réussir à trouver la solution gagnante : faire travailler de concert la partie graphique intégrée au CPU et un GPU dédié. Pour que cela fonctionne, la solution trouvée et de ne pas chercher à exploiter une telle solution pour la 3D, mais pour le calcul.
Dans le terme « MAX » il faut donc comprendre que c'est une version « augmentée » de Xe plus qu'un GPU réellement plus performant. Pas sûr que les clients le comprennent de la sorte au premier abord. Gare au risque de déception, une communication claire de la société sera ici plus que nécessaire.
Le lien est assuré entre CPU et GPU par quatre lignes PCIe 4.0.


Tiger Lake et Iris Xe MAX intègrent différents accélérateurs, Deep Link permet de les combiner
Les différents frameworks proposés par Intel, qui sont désormais presque tous agnostiques en termes d'accélérateur (CPU, GPU, NPU, FPGA, etc.) peuvent répartir la charge de travail sur les différentes unités présentes au sein de la machine, pour des traitements où l'IA entre en jeu, ou de la compression vidéo par exemple.
Chaque GPU disposant de son propre accélérateur en la matière, ils peuvent être combinés. Intel promet des performances presque doublées par rapport au NVENC de NVIDA des RTX de série 20 (et donc de série 30). Avec quel niveau de qualité ? Ce sera à vérifier, surtout que les différences peuvent être importantes.
Plusieurs applications sont d'ores et déjà compatibles : Handbrake, Gigapixel AI, OBS, XSplit, etc. D'autres arrivent comme Blender ou les solutions de Cyberlink promet Intel :
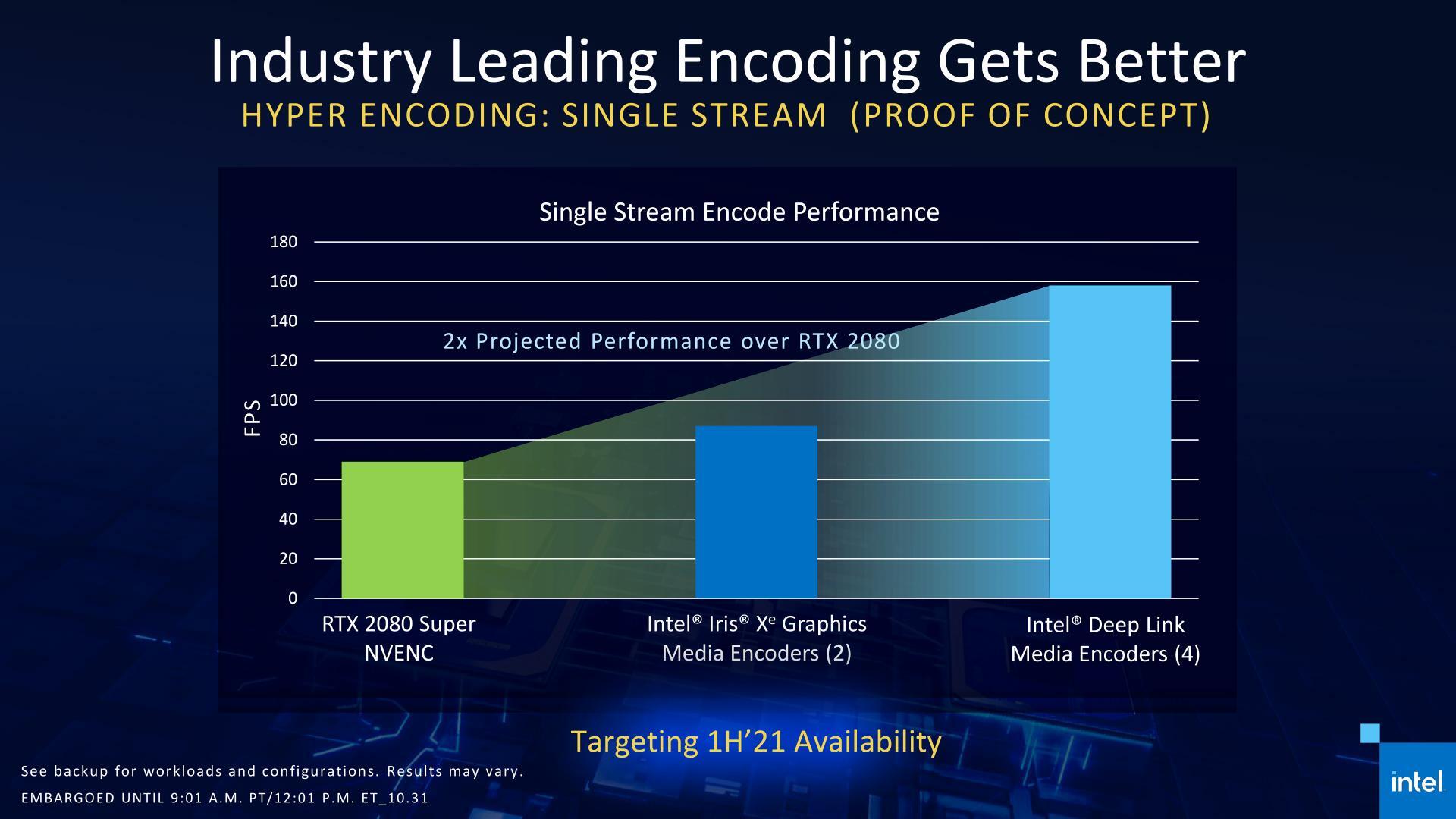

Bien entendu, la gestion de la puissance consommée et du TDP est également unifiée. Intel promet une répartition dynamique permettant de privilégier CPU et/ou GPU selon les besoins. Xe-LP oblige, on retrouve dans Iris Xe MAX l'IGP de Tiger Lake à 96 EU et son moteur vidéo, mais à une fréquence supérieure : 1,65 GHz, soit 2,53 TFLOPS.
4 Go de LPDDR4X (68 Go/s) lui sont dédiés. La puce est gravée en 10 nm SuperFin et son TDP ne devrait pas dépasser les 25 watts. On reste donc sur une solution d'entrée de gamme, comparée par Intel à une MX350 de NVIDIA. Plutôt adaptée à du jeu entre 30 et 45 ips en 1080p qu'à de hautes performances.
Trois partenaires devraient mettre leurs machines sur le marché d'ici peu : ASUS et son VivoBook TP470EZ que nous vous avons déjà présentés, l'Acer Swift 3x et le Dell Inspiron 15 (7000, 2-en-1). Elles bénéficieront d'un bundle logiciel spécifique (250 dollars de licences), un autre étant proposé pour le CPU (500 dollars de licences).


Server GPU, H3C XG310 et virtualisation du GPU
Cette volonté de faire travailler ensemble différentes puces au sein d'un même système ne s'arrête bien entendu pas aux PC portables. On pense notamment au projet SG1 dévoilé cet été, basé sur quatre GPU DG1 et visant tant des usages de type cloud gaming et autres solutions de compression vidéo à bon rapport performances/prix.
Il est désormais finalisé et à un nom définitif : H3C XG310. Il s'agit donc d'une carte PCIe 3.0 x16. Elle embarque quatre « Server GPU », qui est le petit nom de Xe-LP et ses 96 EU, adapté à ce marché. On retrouve donc la même puce, mais avec quelques spécificités. La fréquence est ainsi entre 0,9 et 1,1 GHz pour un TDP de 23 watts.
Elle est surtout accompagnée de 8 Go de LPDDR4 à 2,13 GHz (128 bits, 68,25 Go/s). L'ensemble est pensé pour fonctionner dans un environnement contraint comme un serveur. L'alimentation se fait par un connecteur PCIe à huit broches. Plusieurs cartes peuvent fonctionner en simultanée.
Cette plateforme a déjà été vendue à Ubitus et Tencent Games pour des services de cloud gaming de jeux Android. Intel évoque d'ailleurs au passage son projet FlipFast qui permet d'utiliser ses GPU au sein d'une machine virtuelle sous Linux avec des performances au plus proche d'une exécution native. On attend de pouvoir tester.
Un Server GPU est donné pour 20 utilisateurs au maximum (720p, H.264), soit 80 par carte et 160 avec deux :
Pour ce qui est de la compression vidéo, Intel dit pouvoir gérer entre 60 et 72 flux HEVC 1080p30 en compression simultanée selon le niveau de qualité. Plus de détails sont donnés sur cette page. Le tout se repose bien entendu sur la suite open source Media SDK qui gère HEVC, AVC, MPEG-2, JPEG et VP9 en compression matérielle.
Le pilote Linux s'améliore, OneAPI finalisé en décembre
Si Intel est connu pour être un très gros contributeur aux projets open source, il en est de même pour ses pilotes. Mais lorsqu'elle a décidé de se relancer sur le marché graphique, un constat était clair : il fallait effectuer un travail en profondeur. Car seuls 10 % du code était réutilisé, rendant la maintenance difficile. Pour 60 % des performances sous Windows.
Désormais, l'équipe menée par Lisa Pearce indique que 60 % du code est commun pour des performances en 3D à 90 % de celles sous Windows, 100 % pour ce qui est du calcul. Un site est désormais consacré à l'installation de toute la couche logicielle nécessaire sous Linux, un nouveau pilote étant diffusé régulièrement.
Trois distributions sont officiellement supportées : Red Hat, SUSE et Ubuntu.
Raja Koduri et son équipe en ont profité pour donner des nouvelles de OneAPI, dont la spec 1.0 est finalisée depuis septembre dernier. La version « Gold » est attendue pour décembre. Les développeurs peuvent d'ores et déjà l'exploiter pour du code bas niveau (via Data Parallel C++) ou via les frameworks et outils maison.
L'objectif est pour rappel de développer une fois du code pouvant être exécuté sur des CPU, GPU, ou autres accélérateurs divers. L'intégration se fait aussi via des applications tierces, Intel donnant l'exemple de FFMPEG qui exploite OneVPL qui peut ainsi tirer partie de la compression vidéo matérielle de ses CPU et GPU (ou les deux).
Comme précédemment, la société précise qu'elle a également travaillé sur un outil de migration de code CUDA. Enfin, elle peaufine nombre de ses outils avec les équipes avec qui elle travaille sur certains projets de recherche : le laboratoire national d'Argonne, l'université de Stockholm, le TCBG d'Illinois, etc.
2021 : une montée en gamme extrême d'Xe
La prochaine étape est donc la montée en puissance de Xe. Si Intel déploie actuellement la version LP, Xe-HPG qui se destine aux PC fixes pour joueurs est annoncé comme fonctionnel. Il est pour rappel gravé par un prestataire externe pour Intel, qui n'a pas souhaité le produire sur son process 10 nm SuperFin.

 Le statut des différents GPU Xe en août, puis il y a quelques jours
Le statut des différents GPU Xe en août, puis il y a quelques jours
Ce sera par contre le cas de Xe-HP, qui aura droit à une déclinaison améliorée de cette finesse de gravure. Il se destine pour sa part à une utilisation professionnelle, plutôt orientée calcul. Annoncé comme fonctionnel, il est actuellement testé par le laboratoire national d'Argonne. Une sorte de travail préparatoire.
Car viendra ensuite Xe-HPC qui est un assemblage de puces exploitant divers process, visant le calcul haute performance. C'est notamment cette architecture qui est au cœur du projet Ponte Vecchio (avec Sapphire Rapids), qui sera utilisé par le supercalculateur Aurora du laboratoire national d'Argonne. Elle est encore en développement.
Des solutions qui feront face aux A100 (jusqu'à 80 Go) de NVIDIA et Instinct MI100 d'AMD, mais aussi leurs déclinaisons plus abordables, visant grand public et professionnels. Un match à trois qui s'annonce passionnant.
Ice Lake dans les serveurs, de nouveaux accélérateurs
La société en profite pour annoncer que la version serveur d'Ice Lake (Xeon Scalable de 3e génération) approche (enfin) de la commercialisation. Ses performances sont annoncées comme meilleures à 32 cœurs que la concurrence avec 64 cœurs, sans doute dans des cas profitant de différentes optimisations/accélérations.
AMD ne devrait d'ailleurs plus tarder à répondre en annonçant ses EPYC Zen 3, eux aussi attendus pour 2021.
D'autres annonces ont été faites, comme l'Open FPGA Stack (OFS) pour simplifier le travail des développeurs. On apprend également l'arrivée de l'eASIC N5X qui passe du 28 au 16 nm, avec 88 millions d'équivalent porte logique, des débits et quantité de mémoire augmentés, un processeur 4x ARMv8 étant désormais embarqué.
Ce produit vise une intégration dans les plateformes 5G, mais aussi des besoins plus larges l'IA et les charges en périphérie de réseau (edge). Pour rappel, cette gamme est le fruit du rachat d'eASIC et ses ASIC structurés où l'on peut aisément porter un développement effectué sur FPGA au départ.
Une manière de réduire les coûts et la consommation, tout en simplifiant le développement.
Commentaires (2)
Le 18/11/2020 à 07h41
Je note que la mémoire est de la LPDDR4, pas de la GDDR5 par exemple. J’imagine que c’est moins cher? Apple et Intel montrent qu’on peut avoir des perfs plus qu’honorables en vidéo avec de la mémoire moins couteuse en ce moment.
Le 18/11/2020 à 08h46
La DDR et la GDDR ne sont pas optimisées de la même manière, d’où peut être leur choix?
ps: GDDR5 est basée sur DDR3 et GDDR6 basée sur la DDR4