Avec o3, OpenAI dit se rapprocher d’une IA Générale… mais la route est encore longue
Le coût de la raison

OpenAI a présenté son nouveau modèle de « raisonnement ». Baptisé o3, il est capable dans une certaine mesure de contrôler la précision et la véracité de ses réponses. Pour l’entreprise, il s’agit d’une étape importante vers l’intelligence artificielle générale (IAG). Pour autant, le modèle n’est pas encore disponible.
La nouvelle famille de modèles o3 a été présentée dans le cadre de la conférence « 12 Days of OpenAI » qui, comme son nom l’indique, a duré la bagatelle de 12 jours. L’entreprise a d’ailleurs attendu la toute fin de son marathon pour annoncer ce qui était gardé en réserve comme clou du spectacle. Pour OpenAI, l’annonce est d’autant plus importante qu’elle permet de rebondir sur deux thématiques d’actualité : la fiabilité des réponses et la course à l’IAG.
D’ailleurs, pourquoi o3 et pas o2 ? Si l’on en croit The Information, OpenAI craignait un éventuel conflit avec l’opérateur O2 au Royaume-Uni. Selon TechCrunch, le CEO d’OpenAI en personne, Sam Altman, l’a confirmé à demi-mot vendredi. On s’étonne quand même que le nom o1 ait pu être choisi en sachant que o2 allait poser problème.
Qu’est-ce qu’o3 ?
La famille se compose pour l’instant de deux modèles, o3 et o3-mini. Ce dernier sera le premier à sortir. Il est attendu pour janvier, tandis que le modèle o3 standard doit arriver plus tard dans l’année, sans plus de précision pour l’instant.
On peut s’étonner de la proximité entre la sortie effective d’o1 il y a quelques semaines (en même temps qu’une offre ChatGPT Pro à 200 dollars par mois) et la présentation d’o3. Mais OpenAI avait beaucoup à dire sur son modèle, puisque o1 représentait une première étape vers le « raisonnement » et que les progrès ont été rapides, selon l’entreprise.
o3 est ainsi capable de se vérifier lui-même, dans une certaine mesure. Il utilise une technique baptisée « alignement délibératif », sur laquelle nous n’avons que peu d’informations. Elle doit permettre au modèle d’éviter une partie des pièges affectant les grands modèles de langage habituellement, dont leur relative incapacité à s’assurer de la fiabilité des informations.
Ces étapes de vérification entrainent une latence. Selon la requête, la réponse peut arriver avec quelques secondes à plusieurs minutes de décalage par rapport à un LLM classique. C’était déjà le cas avec o1, mais o3 intensifie cet aspect. En conséquence, le nouveau modèle doit se montrer plus fiable dans des domaines comme les mathématiques, la physique et plus généralement les sciences.
o3 fait donc une pause avant de répondre et prend le temps de la réflexion. Selon OpenAI, ce temps est consacré à des calculs sur des questions connexes, en expliquant (de manière interne) le développement de la réponse. La réponse proposée est alors un résumé de ce qu’o3 estime être la réponse la plus précise.
Les améliorations depuis o1
Annoncé il y a tout juste trois mois, o1 était le premier modèle de raisonnement d’OpenAI. Son entrainement avait été fait avec de l’apprentissage par renforcement (RL). o3 reprend cette idée, mais avec un renforcement nettement plus développé, même si là encore OpenAI ne donne aucun chiffre précis. « La force du modèle qui en résulte est très, très impressionnante », a déclaré sur X Nat McAleese, chercheur chez OpenAI.
Par rapport à o1, o3 permet également d’ajuster le temps de raisonnement, donc de la vérification des réponses. Trois crans sont disponibles : faible, moyen ou élevé. Plus on élève le niveau, plus les résultats sont précis et plus ils mettent de temps à s’afficher. À l’inverse, on peut rogner sur la précision pour obtenir des réponses rapides. Mais attention, car même avec une plus grande précision, OpenAI se garde bien de dire que son modèle ne fait pas d’erreur, simplement qu’il en fait moins qu’o1.
L’entreprise a quand même donné une série de résultats pour comparer le nouveau modèle à l’ancien sur certains benchmarks :
- ARC-AGI Semi-Private Evaluation : 75,7 %
- EpochAI Frontier Math : 25,2 % de problèmes résolus, contre 2 % pour « les autres modèles »
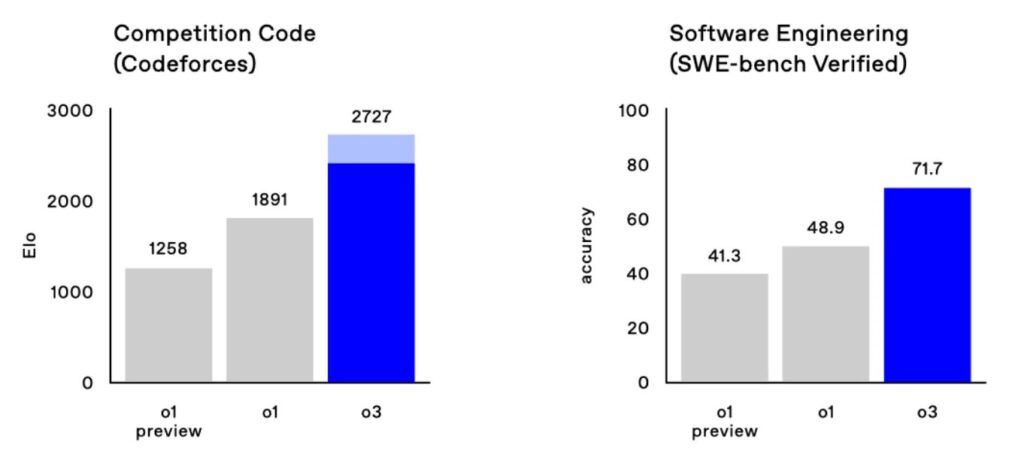
- SWE-Bench Verified : 71,7 points, contre 48,9 pour o1
- Codeforces : score Elo de 2 727
- AIME 2024 : 96,7 %, contre 83,3 % pour o1
- GPQA Diamond : 87,7 %, contre 78 % pour o1
« Une avancée significative »
Dans un tweet vendredi, François Chollet, créateur de Keras et ARC-AGI, a indiqué qu’o3 « représente une avancée significative dans l'adaptation de l'IA à de nouvelles tâches ». Il a précisé que le score de 75,7 % était en mode de calcul faible, soit un coût de 20 dollars par tâche de calcul. Dans le niveau le plus élevé, la note grimpe à 87,5 %, mais le calcul représente alors « des milliers de dollars par tâche ».
ARC-AGI a été créé pour évaluer dans quelle mesure un système d’intelligence artificielle peut acquérir de nouvelles compétences hors des données sur lesquelles il a été entrainé.
Dans un billet dédié, l’association ARC Prize insiste sur l’étape importante que représente o3 et donne quelques éléments de comparaison. Il a ainsi fallu quatre ans pour passer d’un score de 0 % avec GPT-3 en 2020 à 5 % avec GPT-4o. ARC Prize ambitionnant d’être « une étoile polaire vers l'IAG », elle note que les prochains tests devront tenir compte d’o3.
La version 2025 du benchmark se voudra donc plus difficile. Elle ajoute que les performances d’o3 prouvent « que l'architecture est essentielle », car GPT-4 n’aurait pu atteindre ces résultats en augmentant simplement la puissance. « Il ne suffit pas de mettre à l'échelle comme nous faisions de 2019 à 2023 », ajoute ARC Prize.
Et la suite ?
La présentation d’o3 a été faite trois mois après celle d’o1. D’après OpenAI, ce rythme devrait être préservé. La question est de savoir cependant si l’entreprise pourra affiner son modèle de manière à garder la même marge de progression.
Plus important encore, peut-on dire qu’o3 est une étape marquante vers l’intelligence artificielle générale ? Ce n’est pas si évident. D’un côté, les résultats et performances du modèle semblent clairement pointer dans cette direction. D’un autre côté, ce type de modèle représente-t-il nécessairement l’avenir ? Car si la précision franchit une étape, l’apprentissage par renforcement et l’inférence sont autrement plus couteux qu’avec des LLM plus classiques comme la série des GPT.
Ces derniers ne sont pour l’instant pas nécessairement dépassés. Même si les modèles o ont l’avantage de la précision, GPT garde l’avantage du coût et de la faible latence. Il est difficile cependant d’en tirer des généralités, car seul le modèle o1 est effectivement disponible. Il faudra attendre janvier pour voir arriver o3-mini, et on verra alors les premiers résultats « réels », puisque seuls ceux d’OpenAI sont fournis pour l’instant.
Enfin, rappelons qu’OpenAI n’est pas seule sur le marché des modèles de « raisonnement ». Google a présenté, il y a moins de deux semaines, son Gemini 2.0 Flash Thinking Experimental, que l’on peut tester via AI Studio. Quelques jours plus tard, une entreprise chinoise faisait de même avec un modèle baptisé DeepSeek-R1.
L’un des aspects les plus intéressants de cette nouvelle vague est qu’elle vient confirmer le mur de la complexité pour les LLM, dont nous avions discuté avec la data scientist Cécile Hannotte. Ajouter des couches de calcul et des GPU n’est pas suffisant, il faut d’autres approches. Les modèles de raisonnement en sont une, mais pas nécessairement une étape aussi marquante vers l’IAG qu’OpenAI le dit. L’évolution des performances sera donc à surveiller de près.

Commentaires (3)
Abonnez-vous pour prendre part au débat
Déjà abonné ? Se connecter
Cet article est en accès libre, mais il est le fruit du travail d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles
Profitez d’un média expert et unique
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousModifié le 23/12/2024 à 14h35
Bah, ça reste du développement logiciel. À un moment, la scalabilité horizontale et/ou verticale atteint ses limites et c'est bel et bien le logiciel qu'il faut optimiser.
Aujourd'hui à 15h49
Aujourd'hui à 14h57
Si o3 coûte 1500$ la requête dans sa version complète, on est encore loin d’une IA qui sait raisonner et qui remplace les humains…
Et je me demande toujours si ça arrivera un jour ou si la bulle spéculative financière autour de l’IA crashera (pour le meilleur), et où on pourra enfin passer à autre chose que des produits bullshit remplis d’Ia partout.